✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
基于大数据的全国饮品门店数据可视化分析系统是一套采用Hadoop+Spark大数据框架构建的综合性数据分析平台,主要针对全国范围内的饮品行业进行深度数据挖掘与可视化展示。系统运用Spark SQL进行大规模数据处理,结合Pandas和NumPy进行数据清洗与科学计算,通过Django/Spring Boot架构后端支撑,配合Vue+ElementUI+Echarts前端技术栈,实现了饮品品牌竞争力分析、品类市场格局研究、价格与规模关联性探索等核心功能模块。平台整合了全国主要饮品品牌的门店数量、平均价格、品类分布等关键指标,运用K-Means聚类算法对品牌进行科学分类,通过散点图、柱状图、饼图、词云图等多种可视化手段,为饮品行业从业者、投资决策者和市场研究人员提供直观、准确的数据洞察支持,助力理解行业发展趋势、竞争格局和市场机遇。
选题背景
近年来,饮品行业在消费升级的推动下呈现出蓬勃发展的态势,各类茶饮、咖啡、乳饮品牌如雨后春笋般涌现,市场竞争日趋激烈。从传统的街边奶茶店到现代化的连锁品牌,从平价的大众饮品到高端的精品咖啡,整个饮品市场呈现出多元化、差异化的发展格局。然而,在这个快速变化的市场环境中,品牌方、投资者和从业者往往缺乏全面、系统的数据支撑来了解行业整体状况。传统的市场调研方式存在数据分散、更新滞后、分析维度单一等问题,难以满足现代商业决策对于数据精准性和时效性的要求。同时,饮品行业的价格策略、门店扩张模式、品类定位等关键商业要素之间存在复杂的关联关系,需要借助大数据技术进行深入挖掘和科学分析,这为构建专业的饮品行业数据分析系统提供了现实需求和技术基础。
选题意义
本系统的开发具有重要的实际应用价值和理论研究意义。从商业实践角度来看,这套系统能够为饮品行业的各类参与者提供科学的决策支持工具,帮助品牌方更好地理解自身在市场中的定位,为新品牌的市场进入策略提供数据参考,为投资机构评估饮品项目提供量化分析基础。通过价格与规模的关联性分析,可以揭示不同商业模式的可行性,为创业者制定合适的定价策略和扩张计划提供指导。从技术层面来说,本系统将大数据处理技术与具体的行业应用场景相结合,展现了Hadoop+Spark技术栈在实际商业数据分析中的应用价值,为相关技术的推广和应用提供了良好的示范案例。从学术研究角度而言,通过对饮品行业数据的深度挖掘,能够为消费经济学、零售业态研究等领域提供新的数据支撑和分析视角。虽然作为毕业设计项目,系统规模相对有限,但其展现的数据驱动分析思路和技术实现方案,对于推动传统行业的数字化转型具有一定的参考价值。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的全国饮品门店数据可视化分析系统界面展示:
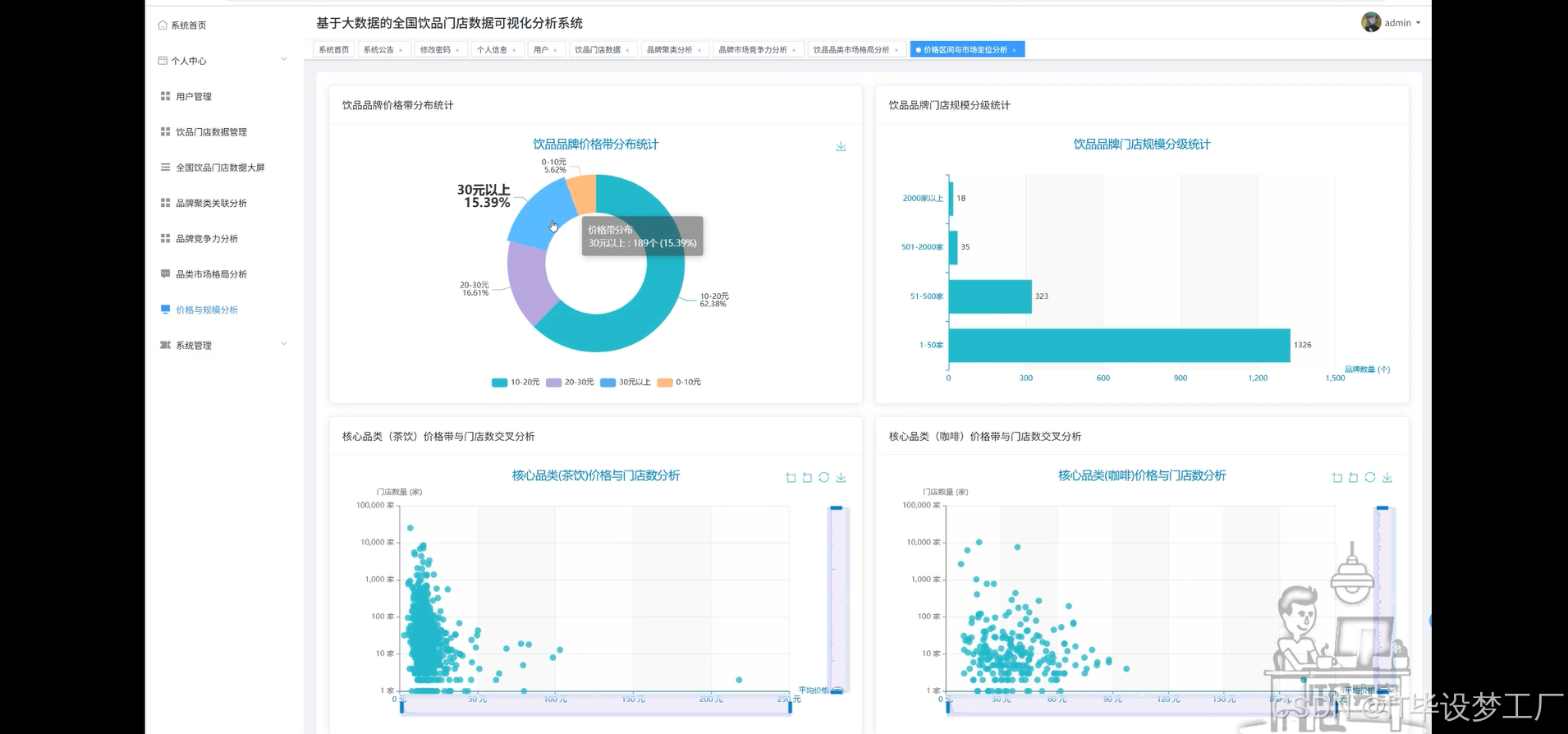
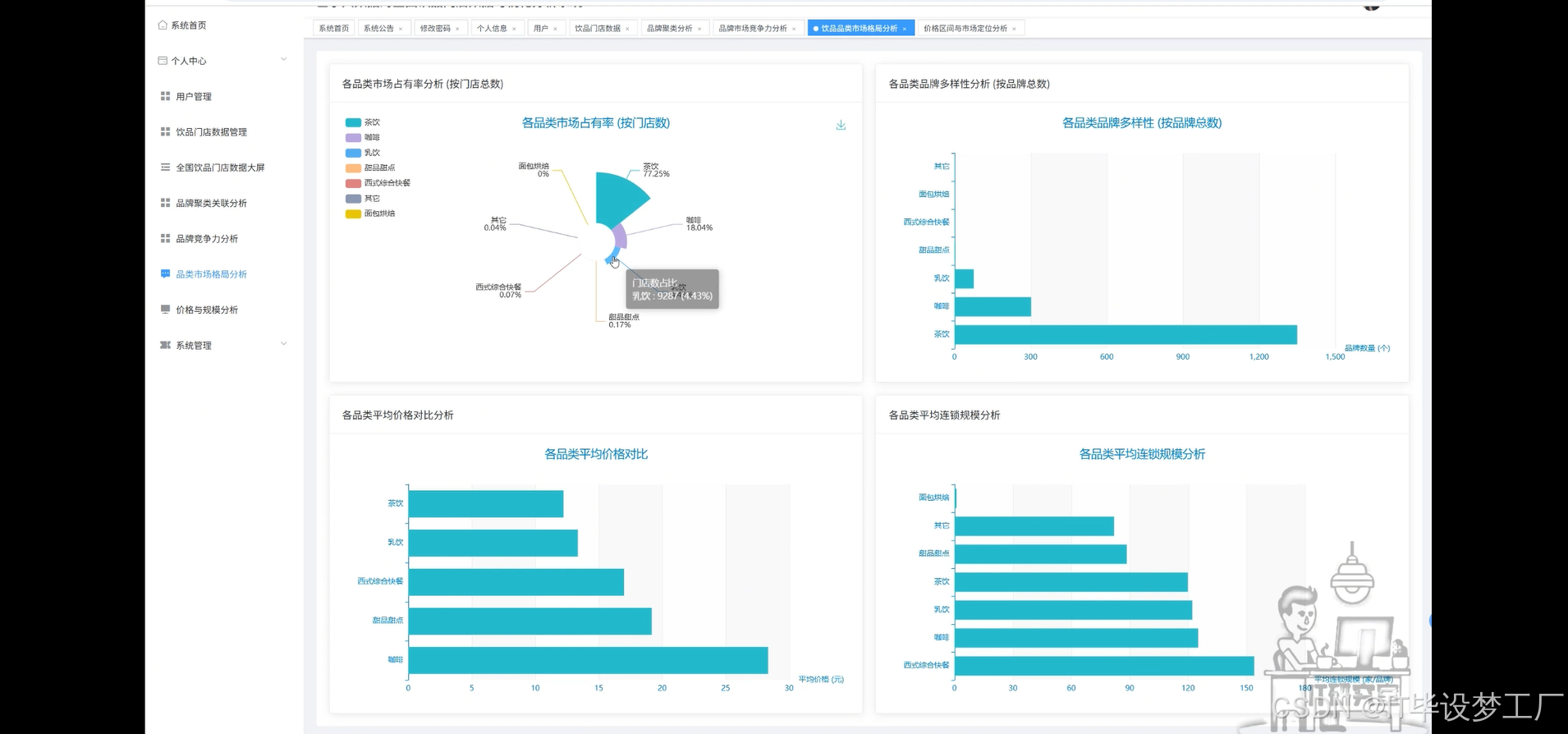
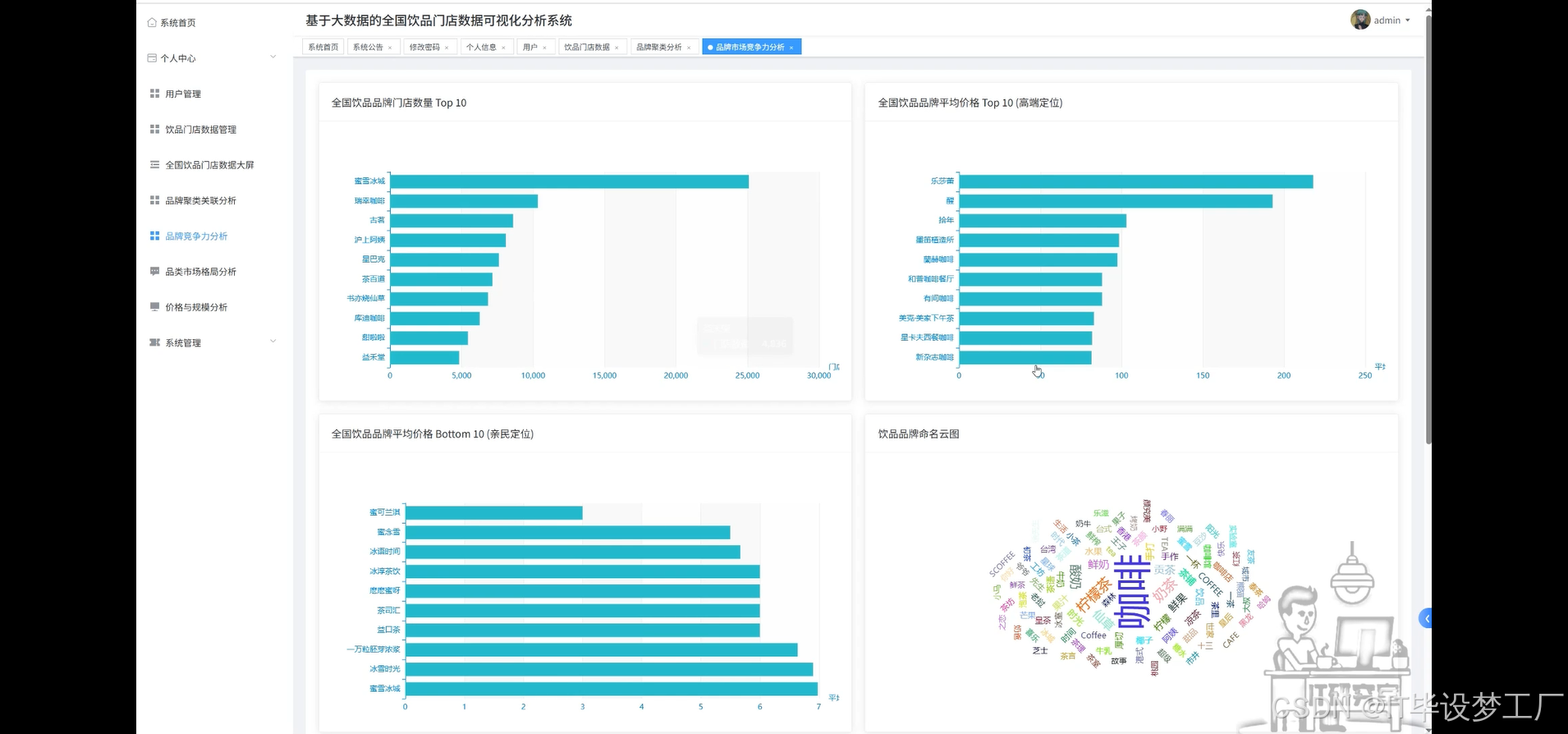
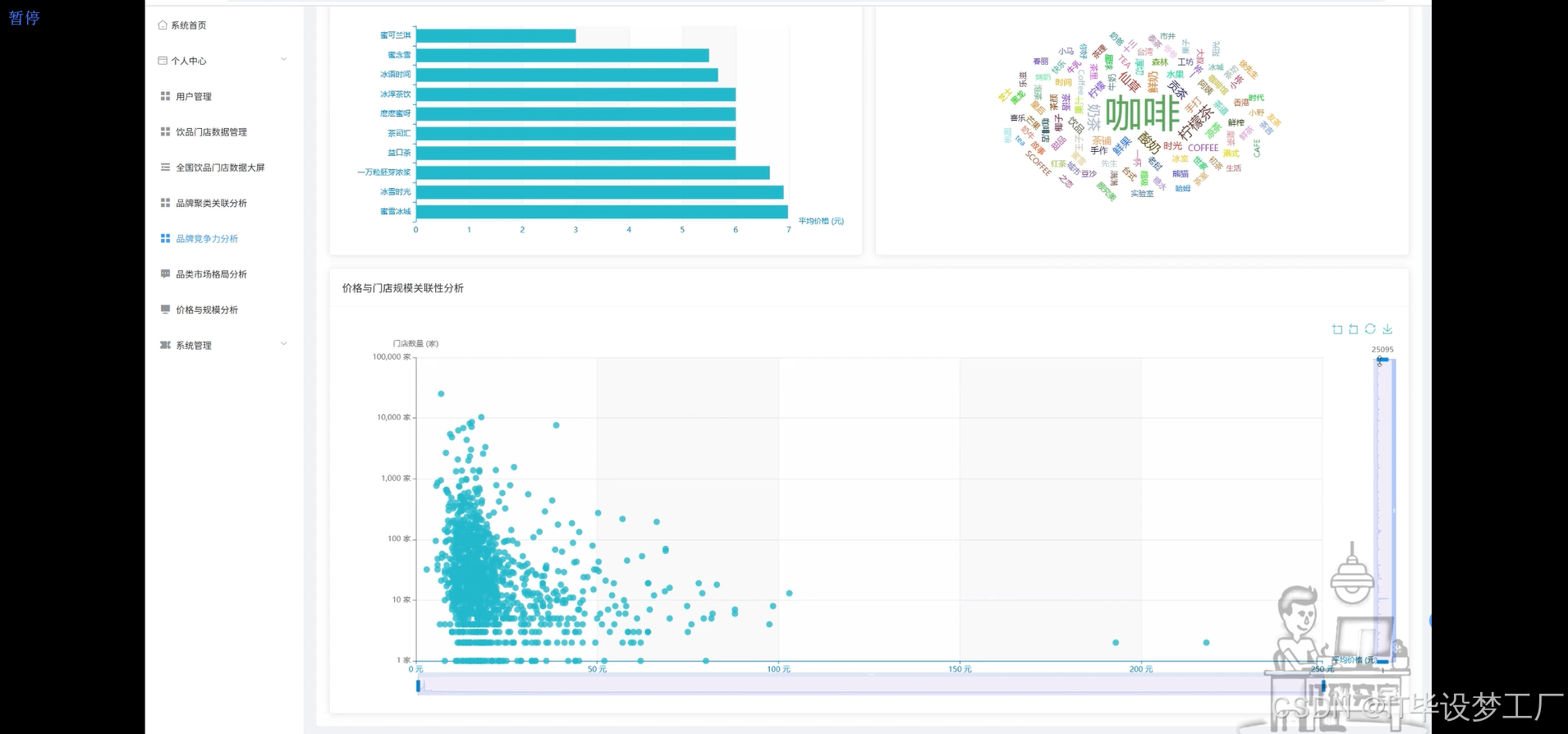
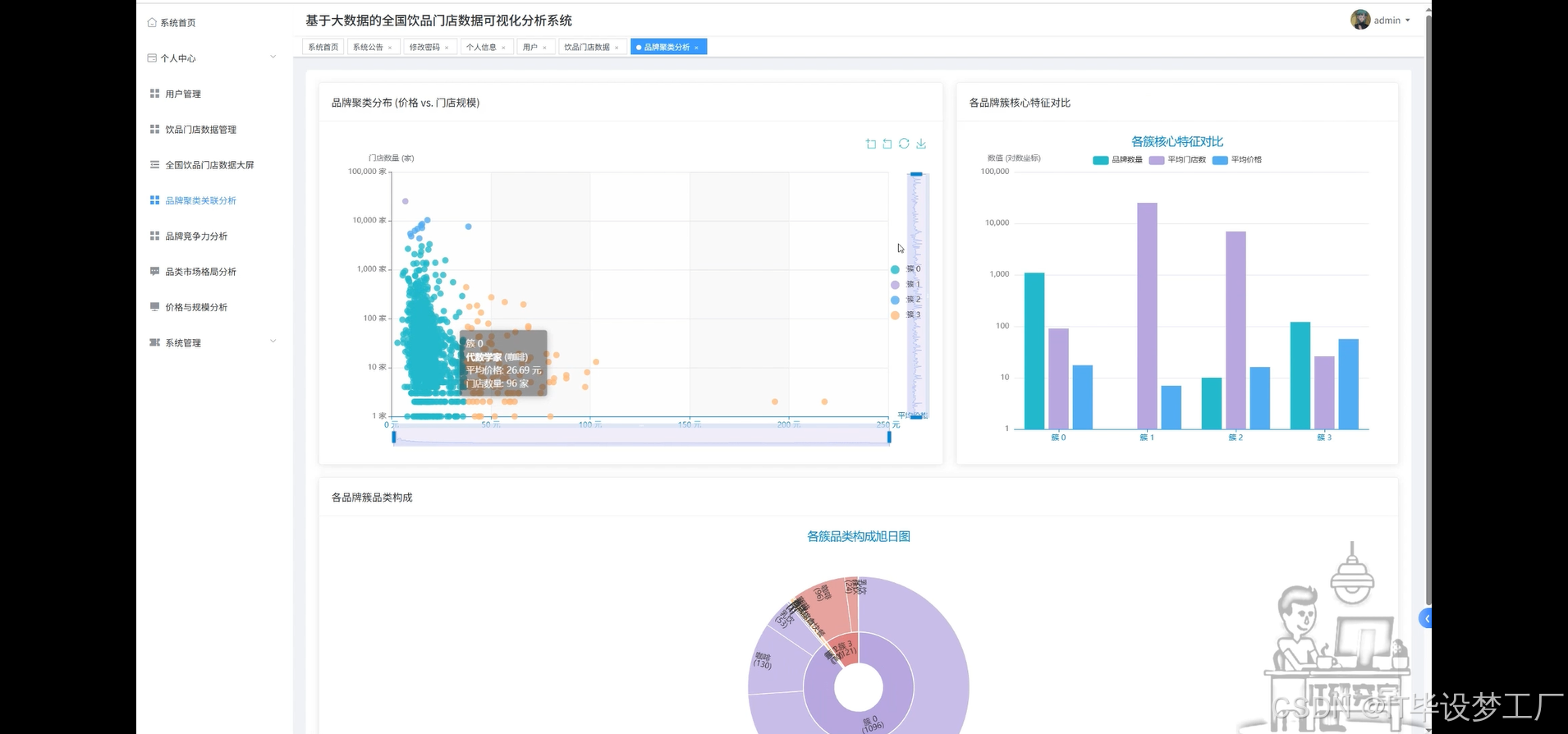
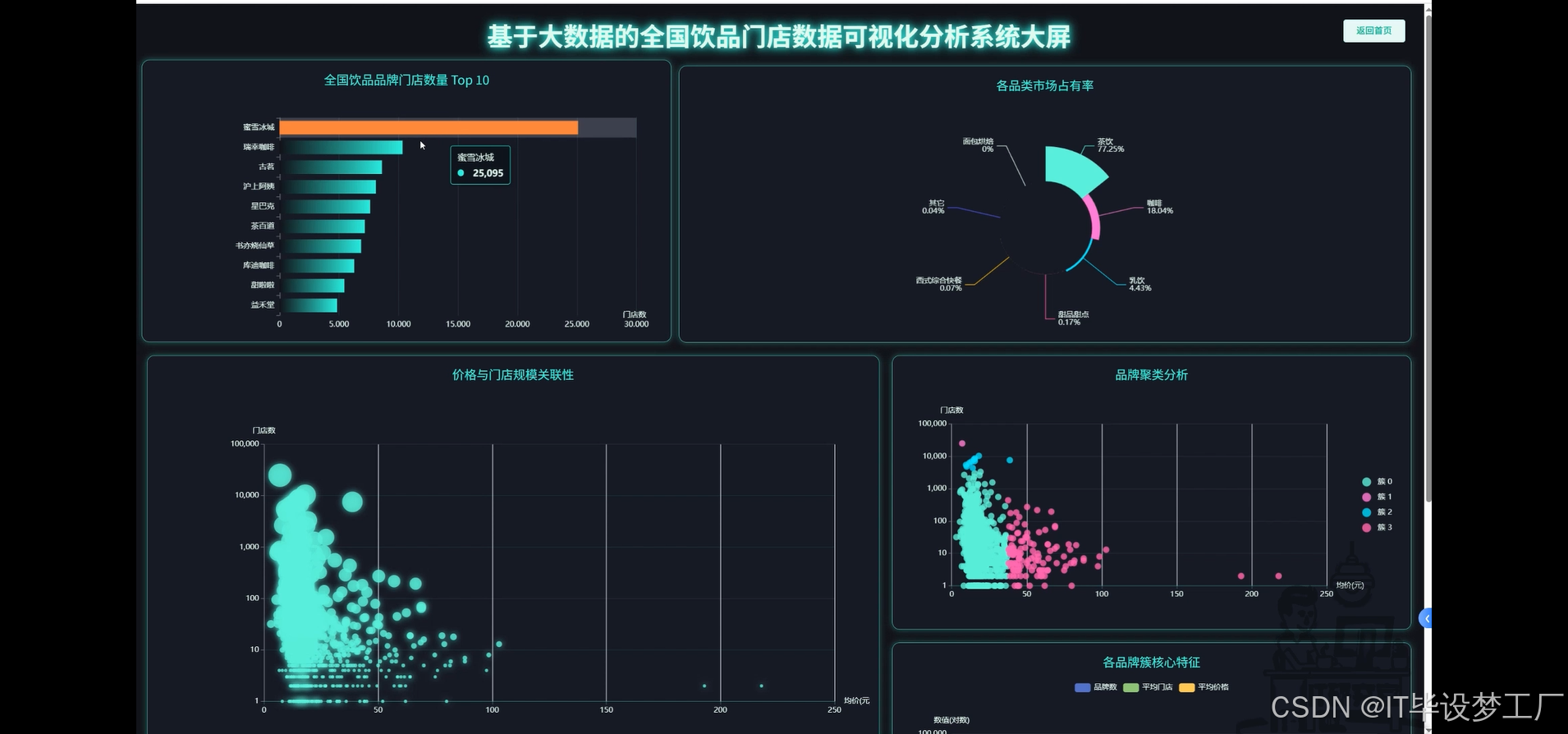
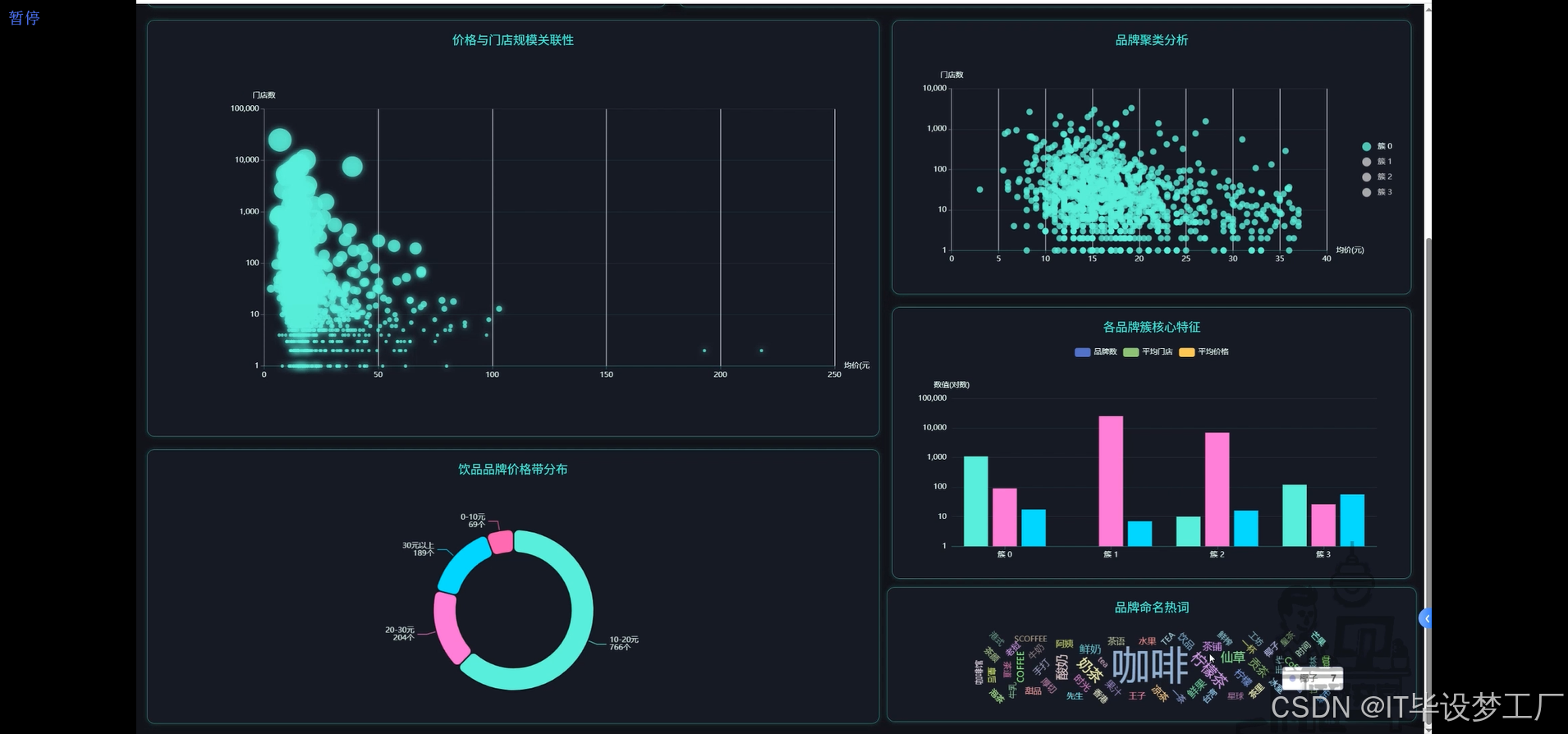
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
import jieba
from collections import Counter
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("DrinkStoreAnalysis").config("spark.sql.adaptive.enabled", "true").getOrCreate()
def brand_competition_analysis(df):
"""品牌竞争力分析 - 核心功能1"""
store_ranking = df.select("名称", "门店数").orderBy(col("门店数").desc()).limit(10)
store_ranking_list = store_ranking.collect()
price_ranking_high = df.filter(col("平均价格") > 0).select("名称", "平均价格").orderBy(col("平均价格").desc()).limit(10)
price_ranking_high_list = price_ranking_high.collect()
price_ranking_low = df.filter(col("平均价格") > 0).select("名称", "平均价格").orderBy(col("平均价格").asc()).limit(10)
price_ranking_low_list = price_ranking_low.collect()
brand_names = df.select("名称").rdd.map(lambda x: x[0]).collect()
all_words = []
for name in brand_names:
words = jieba.cut(name)
all_words.extend([word for word in words if len(word) > 1])
word_freq = Counter(all_words)
top_words = word_freq.most_common(50)
price_store_correlation = df.select("平均价格", "门店数").filter((col("平均价格") > 0) & (col("门店数") > 0))
correlation_data = price_store_correlation.toPandas()
correlation_coefficient = correlation_data['平均价格'].corr(correlation_data['门店数'])
scatter_points = correlation_data.to_dict('records')
analysis_result = {
"store_ranking": [{"name": row["名称"], "count": row["门店数"]} for row in store_ranking_list],
"high_price_ranking": [{"name": row["名称"], "price": row["平均价格"]} for row in price_ranking_high_list],
"low_price_ranking": [{"name": row["名称"], "price": row["平均价格"]} for row in price_ranking_low_list],
"word_cloud": [{"word": word, "freq": freq} for word, freq in top_words],
"price_store_scatter": scatter_points,
"correlation": correlation_coefficient
}
return analysis_result
def category_market_analysis(df):
"""品类市场格局分析 - 核心功能2"""
category_store_share = df.groupBy("类型").agg(sum("门店数").alias("总门店数")).orderBy(col("总门店数").desc())
total_stores = df.agg(sum("门店数").alias("total")).collect()[0]["total"]
category_share_list = category_store_share.collect()
share_data = []
for row in category_share_list:
percentage = (row["总门店数"] / total_stores) * 100
share_data.append({"category": row["类型"], "store_count": row["总门店数"], "percentage": round(percentage, 2)})
category_brand_count = df.groupBy("类型").agg(count("名称").alias("品牌数量")).orderBy(col("品牌数量").desc())
brand_diversity_list = category_brand_count.collect()
brand_diversity_data = [{"category": row["类型"], "brand_count": row["品牌数量"]} for row in brand_diversity_list]
category_avg_price = df.filter(col("平均价格") > 0).groupBy("类型").agg(avg("平均价格").alias("平均价格")).orderBy(col("平均价格").desc())
avg_price_list = category_avg_price.collect()
price_comparison_data = [{"category": row["类型"], "avg_price": round(row["平均价格"], 2)} for row in avg_price_list]
category_avg_scale = df.filter(col("门店数") > 0).groupBy("类型").agg(avg("门店数").alias("平均门店数")).orderBy(col("平均门店数").desc())
avg_scale_list = category_avg_scale.collect()
scale_comparison_data = [{"category": row["类型"], "avg_scale": round(row["平均门店数"], 0)} for row in avg_scale_list]
tea_analysis = df.filter(col("类型") == "茶饮").select("名称", "平均价格", "门店数").filter((col("平均价格") > 0) & (col("门店数") > 0))
tea_data = tea_analysis.toPandas()
coffee_analysis = df.filter(col("类型") == "咖啡").select("名称", "平均价格", "门店数").filter((col("平均价格") > 0) & (col("门店数") > 0))
coffee_data = coffee_analysis.toPandas()
market_analysis_result = {
"category_market_share": share_data,
"brand_diversity": brand_diversity_data,
"price_comparison": price_comparison_data,
"scale_comparison": scale_comparison_data,
"tea_category_detail": tea_data.to_dict('records'),
"coffee_category_detail": coffee_data.to_dict('records')
}
return market_analysis_result
def brand_clustering_analysis(df):
"""品牌聚类分析 - 核心功能3"""
clustering_data = df.select("名称", "平均价格", "门店数", "类型").filter((col("平均价格") > 0) & (col("门店数") > 0))
feature_cols = ["平均价格", "门店数"]
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
feature_df = assembler.transform(clustering_data)
kmeans = KMeans(k=4, seed=42, featuresCol="features", predictionCol="cluster")
model = kmeans.fit(feature_df)
clustered_df = model.transform(feature_df)
cluster_centers = model.clusterCenters()
cluster_summary = clustered_df.groupBy("cluster").agg(
avg("平均价格").alias("avg_price"),
avg("门店数").alias("avg_stores"),
count("名称").alias("brand_count")
).orderBy("cluster")
cluster_summary_list = cluster_summary.collect()
cluster_characteristics = []
for i, row in enumerate(cluster_summary_list):
center = cluster_centers[row["cluster"]]
characteristics = {
"cluster_id": row["cluster"],
"avg_price": round(row["avg_price"], 2),
"avg_stores": round(row["avg_stores"], 0),
"brand_count": row["brand_count"],
"center_price": round(center[0], 2),
"center_stores": round(center[1], 0)
}
cluster_characteristics.append(characteristics)
cluster_category_composition = clustered_df.groupBy("cluster", "类型").agg(count("名称").alias("count")).orderBy("cluster", "类型")
composition_list = cluster_category_composition.collect()
category_composition = {}
for row in composition_list:
cluster_id = row["cluster"]
if cluster_id not in category_composition:
category_composition[cluster_id] = []
category_composition[cluster_id].append({"category": row["类型"], "count": row["count"]})
clustered_brands = clustered_df.select("名称", "平均价格", "门店数", "类型", "cluster").toPandas()
clustering_result = {
"cluster_characteristics": cluster_characteristics,
"category_composition": category_composition,
"clustered_brands": clustered_brands.to_dict('records'),
"cluster_centers": [{"price": round(center[0], 2), "stores": round(center[1], 0)} for center in cluster_centers]
}
return clustering_result五、系统视频
- 基于大数据的全国饮品门店数据可视化分析系统-项目视频:
大数据毕业设计选题推荐-基于大数据的全国饮品门店数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的全国饮品门店数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇