本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
你有没有纳闷过,为什么你的 RAG 系统总是返回一堆无关的结果,或者漏掉显而易见的答案?你不是一个人!很多开发者一开始用 vector search,然后一脸懵地发现,他们的"智能"AI 连一个简单的产品代码都找不到。

如果你试过搭建一个 Retrieval-Augmented Generation (RAG) 系统,可能也撞过我一样的南墙。你的 chatbot 有时候回答得很棒,但有时候完全答非所问,返回一些概念上相似但实际没用的信息。
问题出在哪儿?大部分 RAG 教程只关注那些酷炫的东西------embeddings、vector databases 和 LLMs,却忽略了一个朴实无华的真相:搜索其实很难,而 relevance 才是王道。
今天,我要带你一步步打造一个在生产环境中真正好用的 RAG 智能体。我们会聊聊不同的搜索策略,什么时候用哪种,以及怎么组合它们来达到最高准确率。

RAG 现实检查:为什么单靠 Vector Search 不够
先讲个可能你也觉得眼熟的故事。
我第一次建 RAG 系统时,用的是标准套路:把文档切块,用 OpenAI 生成 embeddings,存到 vector database,检索 top-k 相似块。看起来优雅又现代。
然后我问它:"P0420 错误代码的解决办法是什么?"
系统回了三段关于排气系统和排放的文字------技术上有点相关,但完全没提到 P0420。而我需要的那个具体公告,埋在第47个 chunk 里。
这就是 vector search 的陷阱。语义相似不等于 relevance。
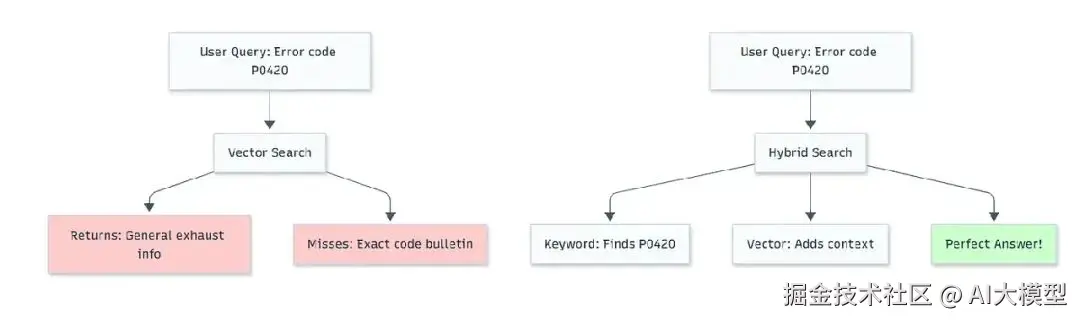
完整的搜索策略工具箱

我学到的经验是:不同的问题需要不同的搜索策略。来逐一拆解什么时候用哪种方法。
1. Keyword Search:精准的冠军
是什么:传统的文本匹配,用像 BM25 这样的算法。想象一下2005年的 Google 搜索。
什么时候用:
- 搜索具体术语、代码或 ID
- 法律文档这种需要精确措辞的场景
- 用户知道具体术语的时候
用例:比如"查找安全公告 SB-2024-003"
ini
# 简单关键词搜索实现
def keyword_search(query, documents):
query_terms = query.lower().split()
scored_docs = []
for doc in documents:
score = sum(1 for term in query_terms if term in doc.lower())
if score > 0:
scored_docs.append((doc, score))
return sorted(scored_docs, key=lambda x: x[1], reverse=True)注意:它很"死脑筋"。你搜"car repair",它不会找到"automobile maintenance"。
2. Vector Search:语义侦探
是什么:把文本转成高维向量,捕捉语义。相似的概念会在向量空间里聚在一起。
什么时候用:
- 开放式问题
- 用户的措辞和文档不完全一致时
- 知识库内容风格多变
用例:比如"怎么修车上怪响?" → 能找到关于引擎故障排查的文档
ini
import chromadb
from chromadb.utils import embedding_functions
# Vector search 设置
client = chromadb.Client()
embedding_fn = embedding_functions.OpenAIEmbeddingFunction(
api_key="your-api-key",
model_name="text-embedding-3-small"
)
collection = client.create_collection(
name="knowledge_base",
embedding_function=embedding_fn
)
defvector_search(query, top_k=5):
results = collection.query(
query_texts=[query],
n_results=top_k
)
return results["documents"][0]注意:有时候会返回"相关"但没用的结果。recall 高,precision 低。
3. Hybrid Search:两全其美
是什么:结合 keyword 和 vector search,然后合并结果。
什么时候用:
- 生产系统,不能漏掉任何关键信息
- 查询类型混合(有的很具体,有的很开放)
- 准确性比简单性更重要
秘诀:用 Reciprocal Rank Fusion (RRF) 合并排名:
python
def reciprocal_rank_fusion(keyword_results, vector_results, k=60):
"""用 RRF 算法合并两个排名列表"""
scores = {}
# 给关键词结果打分
for rank, doc inenumerate(keyword_results, 1):
scores[doc] = scores.get(doc, 0) + 1 / (k + rank)
# 给向量结果打分
for rank, doc inenumerate(vector_results, 1):
scores[doc] = scores.get(doc, 0) + 1 / (k + rank)
# 按综合得分排序
returnsorted(scores.items(), key=lambda x: x[1], reverse=True)4. Database Search:事实核查员
是什么:对结构化数据进行 SQL 查询。
什么时候用:
- 当前价格、库存、用户数据
- 需要精确、实时的数字
- 结合文本搜索给完整答案
5. Graph Search:关系专家
是什么:查询知识图谱,找相关联的信息。
什么时候用:
- "谁是 Alice 的上司的汇报对象?"
- 复杂多跳推理
- 关系比内容更重要
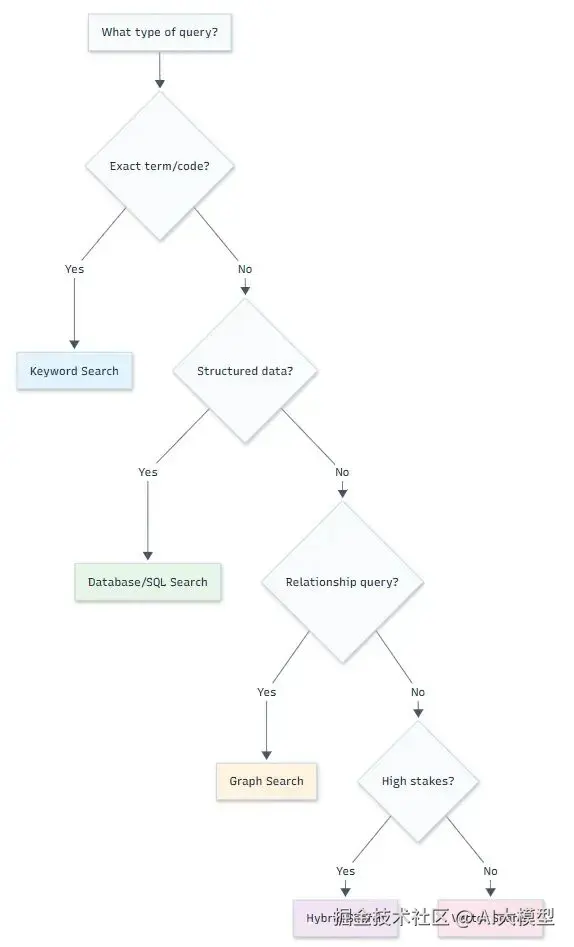
这里有个决策流程图帮你选:
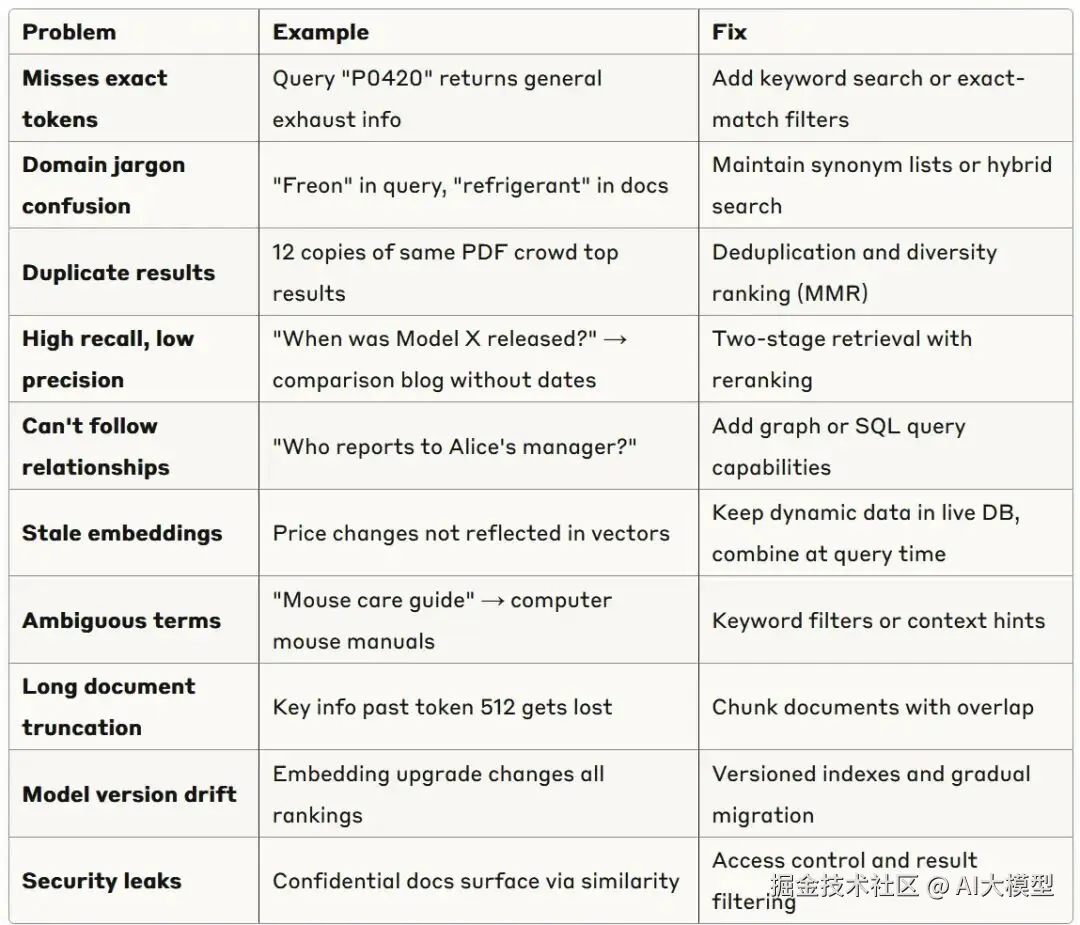
Pure Vector Search 的隐藏问题

在建智能体之前,先看看会出什么问题。我遇到过的十大失败模式:
打造生产级 RAG 智能体

现在来实战。我会教你怎么用 ChromaDB 做 vector search,加上 reranking,用《回到未来》电影剧本作为知识库。
步骤 1:设置知识库
python
import chromadb
import openai
import tiktoken
from pathlib import Path
from typing importList
# 智能切块函数
defsmart_chunk(text: str, max_tokens: int = 200) -> List[str]:
"""按语义切分文本,限制 token 数"""
tokenizer = tiktoken.get_encoding("cl100k_base")
words = text.split()
chunks = []
current_chunk = []
for word in words:
# 检查加这个词会不会超 token 限制
test_chunk = " ".join(current_chunk + [word])
iflen(tokenizer.encode(test_chunk)) > max_tokens:
if current_chunk: # 不加空块
chunks.append(" ".join(current_chunk))
current_chunk = [word]
else:
current_chunk.append(word)
# 加最后一块
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks
# 加载并处理剧本
script_text = Path("back_to_the_future.txt").read_text(encoding="utf-8")
chunks = smart_chunk(script_text, max_tokens=200)
print(f"从剧本创建了 {len(chunks)} 个块")步骤 2:创建向量存储
ini
from chromadb.utils import embedding_functions
import uuid
# 初始化带持久化的 ChromaDB
client = chromadb.Client(chromadb.config.Settings(
persist_directory="./movie_knowledge_base"
))
# 设置 embedding 函数
embedding_fn = embedding_functions.OpenAIEmbeddingFunction(
api_key=openai.api_key,
model_name="text-embedding-3-small"
)
# 创建或获取集合
collection_name = "bttf_script"
try:
collection = client.get_collection(collection_name)
print("找到已有集合")
except:
collection = client.create_collection(
name=collection_name,
embedding_function=embedding_fn
)
print("创建新集合")
# 如果集合为空,添加文档
if collection.count() == 0:
print("正在添加文档到集合...")
collection.add(
ids=[str(uuid.uuid4()) for _ in chunks],
documents=chunks,
metadatas=[{"chunk_index": i} for i inrange(len(chunks))]
)
client.persist()
print("文档已添加并持久化")步骤 3:实现带 Reranking 的智能搜索
python
def smart_search(query: str, top_k: int = 5) -> str:
"""
多阶段检索:
1. 用 vector search 广撒网
2. 按关键词重叠 rerank
3. 返回最佳结果
"""
# 第一阶段:vector search 提高 recall
initial_results = collection.query(
query_texts=[query],
n_results=min(top_k * 3, 15) # 获取更多候选
)
docs = initial_results["documents"][0]
ifnot docs:
return"未找到相关信息。"
# 第二阶段:按关键词重叠 rerank
query_words = set(query.lower().split())
scored_docs = []
for doc in docs:
doc_words = set(doc.lower().split())
keyword_score = len(query_words.intersection(doc_words))
scored_docs.append((doc, keyword_score))
# 按关键词重叠排序,保留最佳结果
reranked = sorted(scored_docs, key=lambda x: x[1], reverse=True)
best_docs = [doc for doc, score in reranked[:top_k]]
return"\n\n---\n\n".join(best_docs)步骤 4:用 OpenAI Agents SDK 打造 RAG 智能体
这里是魔法发生的地方。OpenAI Agents SDK 让构建会用工具的智能体变得超简单。下面是一个完整的工作示例:
ini
import uuid
from pathlib import Path
import chromadb
import tiktoken
from agents import Agent, Runner, function_tool
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 加载并切分剧本
script_text = Path("back_to_the_future.txt").read_text(encoding="utf-8")
defsimple_chunk(text, max_tokens=200):
tokenizer = tiktoken.get_encoding("cl100k_base")
words, chunk, chunks = text.split(), [], []
for w in words:
iflen(tokenizer.encode(" ".join(chunk + [w]))) > max_tokens:
chunks.append(" ".join(chunk))
chunk = [w]
else:
chunk.append(w)
if chunk:
chunks.append(" ".join(chunk))
return chunks
docs = simple_chunk(script_text, max_tokens=200)
# 设置带持久化的 ChromaDB
client = chromadb.PersistentClient(path="./chroma_script_store")
collection_name = "bttf_script"
# 获取或创建集合
try:
collection = client.get_collection(collection_name)
except Exception:
collection = client.create_collection(name=collection_name)
# 如果集合为空,添加文档
if collection.count() == 0:
collection.add(
ids=[str(uuid.uuid4()) for _ in docs],
documents=docs
)
# 定义搜索工具,带正确的装饰器
@function_tool
defsearch_script(query: str, top_k: int = 3) -> str:
"""搜索《回到未来》剧本中的相关片段"""
res = collection.query(query_texts=[query], n_results=top_k)
if res and"documents"in res and res["documents"] and res["documents"][0]:
return"\n\n".join(res["documents"][0])
return"未找到相关文档。"
# 创建智能体
agent = Agent(
name="Script Agent",
instructions=(
"你回答关于《回到未来》电影的问题。\n"
"需要时调用 `search_script` 工具获取片段,"
"然后引用或改述它们来回答。"
),
tools=[search_script],
)
# 测试智能体
query = "Doc 在哪里让 Marty 见他,几点钟?"
result = Runner.run_sync(agent, query)
print("\n--- 答案 ---\n", result.final_output)
query = "凌晨 1:15 发生了什么?"
result = Runner.run_sync(agent, query)
print("\n--- 答案 ---\n", result.final_output)优雅之处:
-
@function_tool装饰器自动把你的 Python 函数变成智能体能用的工具
-
智能体指令告诉 LLM 什么时候、怎么用搜索工具
-
Runner.run_sync()管理整个对话流程------智能体决定什么时候搜索,处理结果,生成最终答案
-
持久化存储让你不用每次重启都重新嵌入文档
秘诀:让它达到生产级
以下是区分业余项目和生产系统的关键:
1. 智能切块策略
别光按 token 数切分,还要考虑:
- 句子边界
- 段落分隔
- 主题转换
- 重叠块保留上下文
2. 多阶段检索
ini
# 生产级检索管道
def production_search(query: str):
# 第一阶段:快速检索(广撒网)
candidates = vector_search(query, k=20)
# 第二阶段:关键词加权
keyword_boosted = boost_keyword_matches(candidates, query)
# 第三阶段:交叉编码器 rerank(如果预算够)
final_results = cross_encoder_rerank(keyword_boosted, query, k=5)
return final_results3. 评估与监控
跟踪这些指标:
-
Hit Rate
:检索到相关文档的问题百分比
-
Answer Quality
:人工评分或用 LLM 做裁判
-
Latency
:端到端响应时间
-
Cost
:嵌入和生成成本
4. 错误处理
python
def robust_search(query: str):
try:
return smart_search(query)
except Exception as e:
# 回退到简单搜索
logging.error(f"智能搜索失败: {e}")
return simple_keyword_search(query)什么时候用什么:你的决策矩阵

这是我的速查表,帮你选对方法:
从 Vector Search 开始,如果:
- 内容多变,偏自然语言
- 用户提开放式问题
- 想要开箱即用的好结果
加 Keyword Search,如果:
- 用户搜具体术语、代码、名字
- 有结构化或一致的术语
- 精准度比召回率更重要
用 Hybrid Search,如果:
- 建生产系统
- 不能漏掉重要结果
- 有工程带宽
考虑 Graph/SQL,如果:
- 需要关系查询
- 有结构化数据
- 实时准确性关键
总结
打造一个牛逼的 RAG 系统,不是用最新的 embedding 模型或最炫的 vector database,而是要懂你的用户、你的数据,选对每种场景的检索策略。
从简单的 vector search 开始,衡量关键指标,逐步增加复杂度。最重要的是,永远用真实用户查询测试------别光用演示里完美的例子。
你的 RAG 翻车故事是啥?在下面留言吧!我想听听你的经历和解决办法。
想深入了解?我正在写一个完整的 RAG 实现指南,包含生产级示例。关注我获取更新,告诉我你想让我下次讲啥具体话题。
关键要点:
- 单靠 vector search 不够做生产级 RAG
- 不同搜索策略解决不同问题
- Hybrid 方案在现实场景中常胜出
- Relevance 比复杂算法更重要
- 永远根据真实用户需求衡量和迭代
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。