大家好,我是熊哥!2025年8月5日,ChatGPT 官方开源了20B 和120B 两个大模型,采用Apache 2.0 许可,个人和工作室都能自由训练和部署。这对开发者来说是个大事件!我在Threadripper 3960X 主机上测试了部署流程,分享如何快速上手,助力AI开发。

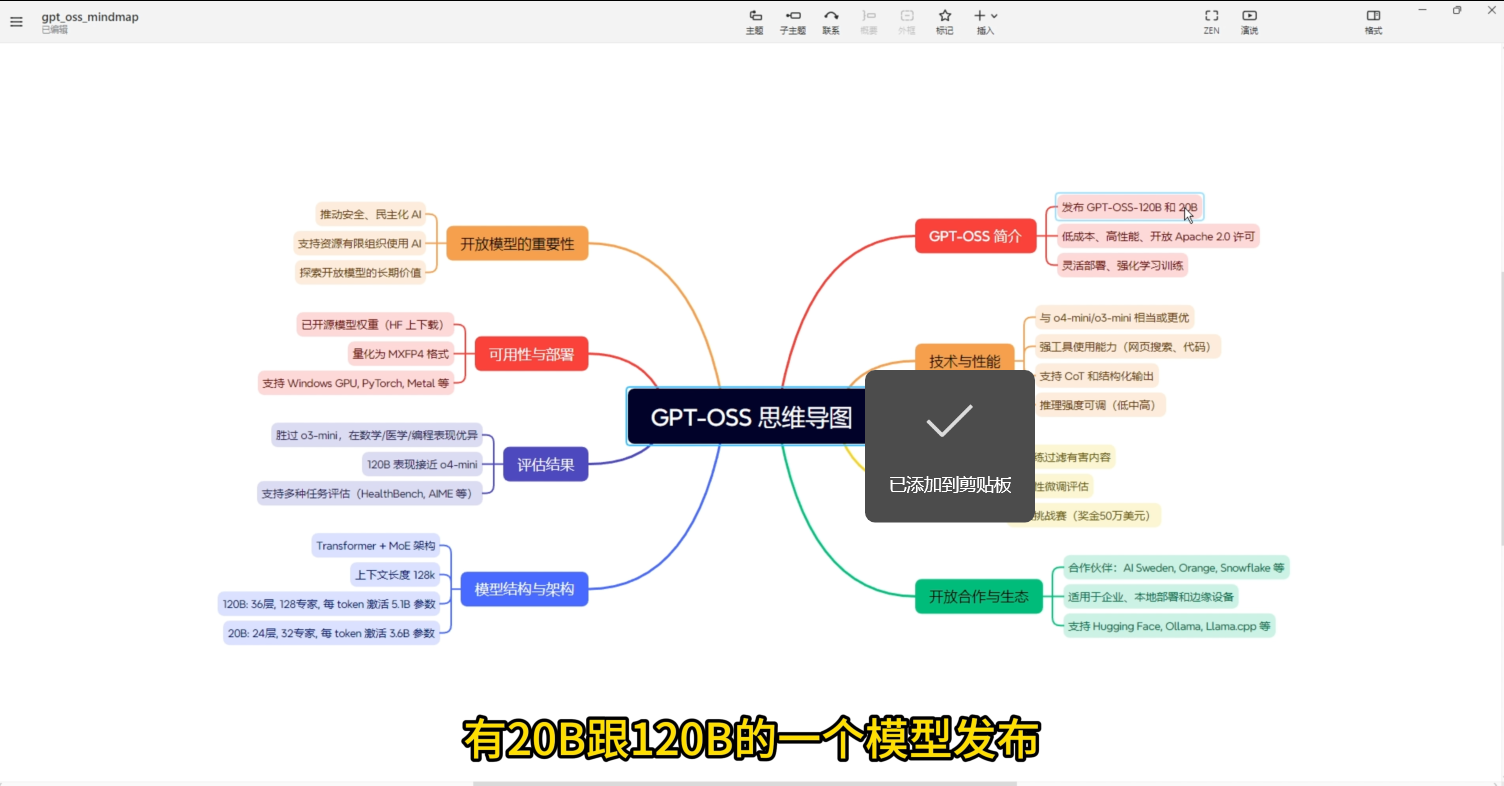
模型亮点
-
开源模型 :20B 和120B 模型发布,性能媲美o4 mini 和o3 mini ,支持网页搜索 、代码生成 和CoT结构化输出,推理强度可调。
-
灵活部署 :支持Hugging Face 、Ollama 和Llama.cpp ,可在本地断网运行,适合企业本地化 和边缘设备。
-
性能优异 :120B 在数学、医学、编程任务上接近o4 mini ,支持128K上下文,表现强劲。
部署实战
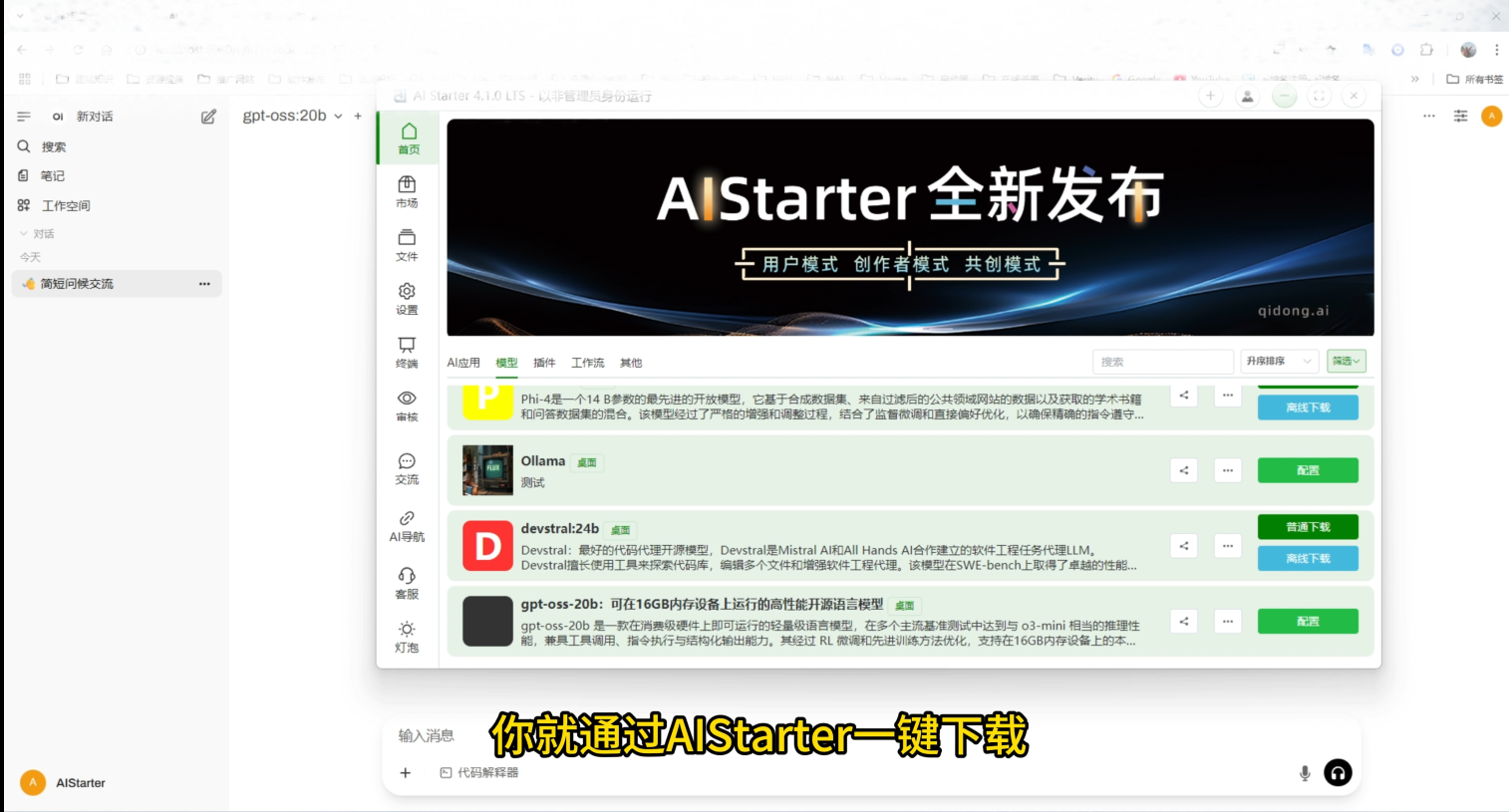
官方文档文字多,读起来费时。我直接将文档丢进大模型 ,生成Markdown格式,再导入思维导图,清晰梳理重点。部署方法:
-
下载Ollama(支持Windows、Mac、Linux),安装后启动。
-
在AIStarter 市场更新Ollama到最新版(0.11.3),或手动复制新版文件到项目目录。
-
下载20B 或120B 模型,配置路径后一键启动。无需Docker,Windows上也能轻松运行。

整个过程简单高效,Threadripper 3960X 的强多核性能让模型运行流畅。未来结合RTX 3090 可进一步加速AI训练。
小经验
-
模型选择 :20B 轻量,适合快速测试;120B性能更强,适合复杂任务。
-
本地部署 :断网也能用,安全又省心。推荐用AIStarter一键管理模型,省去复杂配置。
-
硬件支持 :高性能CPU如Threadripper 3960X对模型推理帮助大,内存建议64GB以上。
想深入了解模型对比和安全性?官方文档有详细说明。欢迎开发者们评论分享你的AI部署 经验,一起探讨如何用开源大模型提升效率!