1.前言
从零复现一篇域适应的论文,本人小白,如有错误欢迎指出。
2. 参考文献
Chen Z, Pu B, Zhao L, et al. Divide and augment: Supervised domain adaptation via sample-wise feature fusionJ. Information Fusion, 2025, 115: 102757.(中科院SCI一区)
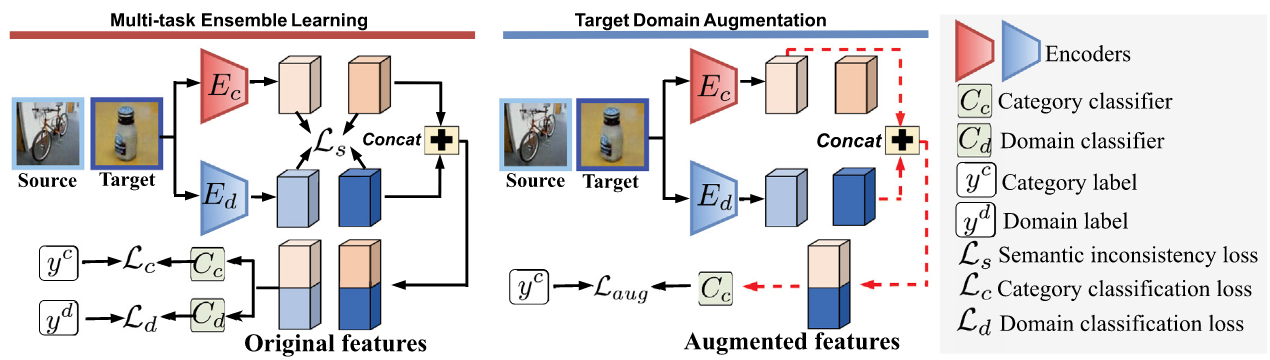
3. python代码
😁是基于我自己数据集写的代码,数据加载器部分需要大家根据自己情况自己重写;
🚀要在google colab jupyter的运行的话就点我;
🚀git仓库地址;
🫵虚拟环境:幸苦您根据import自行安装,或者直接安装YOLO的ultralytics环境。
python
# %%
import os
import torch
import torchvision
import time
from torchvision import models
from torch.utils.data import Dataset,DataLoader,TensorDataset
from sklearn.datasets import fetch_openml
import numpy as np
from sklearn.model_selection import train_test_split
import torch.nn as nn
from torch.autograd.function import Function
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.optim.lr_scheduler as lr_scheduler
import random
from torch.utils.tensorboard import SummaryWriter
import json
import copy
import cv2
import timm
import re
import itertools
from collections import defaultdict
# %%
class ToTensor16bit:
def __call__(self, pic: np.ndarray):
assert pic.ndim == 2, "只支持灰度图"
tensor = torch.from_numpy(pic.astype(np.float32)) # 原始 uint16 转 float32
tensor = tensor.unsqueeze(0) # [H,W] -> [1,H,W],单通道
tensor = tensor / 65535.0 # 映射到 0~1
return tensor
transforms_16bit = transforms.Compose([
ToTensor16bit(),
transforms.Normalize(mean=[0.5], # 灰度图只需要一个通道的均值
std=[0.5]) # 灰度图只需要一个通道的标准差
])
# %%
class AF9Dataset(Dataset):
def __init__(self, image_paths, class_labels, domain_labels):
self.image_paths = image_paths
self.labels = class_labels
self.domain_labels = domain_labels
self.transform = transforms.Compose([
ToTensor16bit(),
transforms.Normalize(mean=[0.5], # 灰度图只需要一个通道的均值
std=[0.5]) # 灰度图只需要一个通道的标准差
])
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
img16 = cv2.imread(img_path, cv2.IMREAD_UNCHANGED).astype(np.float32)
img16 = cv2.resize(img16, (128, 128))
image = self.transform(img16)
class_label = self.labels[idx]
domain_label = self.domain_labels[idx]
if domain_label == 15:
domain_label = 0
elif domain_label == 26:
domain_label = 1
elif domain_label == 35:
domain_label = 2
return image, class_label, domain_label
def load_diameters_datasets(root_dir, diameters):
"""
按 类别->程度->瓶子 聚合,并仅加载指定域(直径)的数据。
目录命名: S{cls}_{domain}_{severity}
文件命名: S{cls}_{domain}_{severity}_B{bottle}_F{frame}.png
返回:
index: dict[int][int][str] -> List[str]
index[class_id][severity][bottle_id] = [image_path, ...]
"""
dir_pat = re.compile(r"^S(\d+)_([\d]+)_(\d+)$") # 目录: S2_35_2
file_pat = re.compile(r"^S(\d+)_([\d]+)_(\d+)_B(\d+)_F(\d+)\.png$", re.IGNORECASE)
index = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
# 遍历子目录,筛选指定域
for de in os.scandir(root_dir):
if not de.is_dir():
continue
m = dir_pat.match(de.name)
if not m:
continue
cls_id, domain_id, sev_id = m.groups()
if domain_id != str(diameters):
continue # 仅保留目标域
cls_id = int(cls_id)
sev_id = int(sev_id)
# 收集该目录下的所有帧
for fn in os.listdir(de.path):
fm = file_pat.match(fn)
if not fm:
continue
cls2, domain2, sev2, bottle_id, frame_id = fm.groups()
# 双重保险:再次核对域、类别、程度
if domain2 != str(diameters) or int(cls2) != cls_id or int(sev2) != sev_id:
continue
index[cls_id][sev_id][bottle_id].append(os.path.join(de.path, fn))
# 转回普通 dict: {class_id: {severity: {bottle_id: [image_paths...]}}}
return {c: {s: dict(bdict) for s, bdict in sev_map.items()} for c, sev_map in index.items()}
def _priority_sample_bottles(sev_to_bottles, N, rng, priority=(2, 1)):
"""
按给定程度优先级顺序选取瓶子,直到达到 N 个或没有可选。
sev_to_bottles: {sev: [bottle_id, ...]}
priority: 优先级从高到低的程度列表,例如 (2,1)
返回: [(sev, bottle_id), ...]
"""
# 复制并打乱每个程度下的瓶子列表
work = {s: sev_to_bottles[s][:] for s in sev_to_bottles}
for s in work:
rng.shuffle(work[s])
# 构造遍历顺序:先优先级中存在的,再补其余(去重)
ordered_sevs = [s for s in priority if s in work]
ordered_sevs += [s for s in work.keys() if s not in priority]
picked = []
remaining = N
for s in ordered_sevs:
if remaining <= 0:
break
take = min(remaining, len(work[s]))
for _ in range(take):
picked.append((s, work[s].pop()))
remaining -= take
return picked
def _round_robin_sample_bottles(sev_to_bottles, N, rng):
"""
轮转/均匀地在多个"程度"之间抽取瓶子,尽量平均且不重复。
当 N>=3 且可用程度包含 {1,2,3} 时,轮转顺序固定为:2,1,3,2,1,3,...
"""
# 确定轮转顺序
if N >= 3 and all(s in sev_to_bottles for s in (2, 1, 3)):
sevs = [2, 1, 3] # 固定顺序
else:
# 保留原行为:随机打乱顺序
sevs = list(sev_to_bottles.keys())
rng.shuffle(sevs)
picked = []
# 将每个程度的瓶子列表复制并随机打乱
work = {s: sev_to_bottles[s][:] for s in sevs}
for s in work:
rng.shuffle(work[s])
# 按 sevs 轮转直到满 N 或没有可取的瓶子
while len(picked) < N:
progressed = False
for s in sevs:
if len(picked) >= N:
break
if work[s]:
b = work[s].pop() # 弹出一个
picked.append((s, b))
progressed = True
if not progressed:
break # 所有程度都没有可用瓶子了
return picked
def n_shot_split(dataset, N_shot=None, frames_per_bottle=1, seed=1, domain_id=None):
"""
dataset: load_diameters_datasets 返回的索引结构
dict[class_id][severity][bottle_id] = [img_paths...]
domain_id: 目录中的域字符串,例如 '15'/'26'/'35',用于生成域标签 0/1/2
返回: train_image_paths, train_class_labels, train_domain_labels,
test_image_paths, test_class_labels, test_domain_labels
"""
rng = random.Random(seed)
if domain_id is None:
raise ValueError("n_shot_split 需要提供 domain_id(如 '15'/'26'/'35')以生成域标签。")
domain_map = {'15': 0, '26': 1, '35': 2}
if str(domain_id) not in domain_map:
raise ValueError(f"未知的 domain_id: {domain_id}. 期望为 '15'/'26'/'35'。")
d_label = domain_map[str(domain_id)]
train_image_paths, train_class_labels, train_domain_labels = [], [], []
test_image_paths, test_class_labels, test_domain_labels = [], [], []
# 遍历每个类别,dataset:{class_id: {severity: {bottle_id: [image_paths...]}}}
for class_id, sev_map in dataset.items():
# 收集每个程度的瓶子列表
sev_to_bottles = {sev: list(bdict.keys()) for sev, bdict in sev_map.items()}
total_bottles = sum(len(v) for v in sev_to_bottles.values())
if N_shot is None or N_shot >= total_bottles:
# 训练:所有瓶子的所有帧;测试:无
for sev, bdict in sev_map.items():
for bottle_id, img_list in bdict.items():
for image_path in img_list:
train_image_paths.append(image_path)
train_class_labels.append(int(class_id))
train_domain_labels.append(int(d_label))
continue
# N_shot 为整数:选择瓶子
if isinstance(N_shot, int) and N_shot < 3:
picked_pairs = _priority_sample_bottles(sev_to_bottles, N_shot, rng, priority=(2, 1))
else:
picked_pairs = _round_robin_sample_bottles(sev_to_bottles, N_shot, rng)
picked_set = {(sev, b) for sev, b in picked_pairs}
# 训练集:每个被选中的瓶子取 frames_per_bottle 帧
for sev, bottle_id in picked_pairs:
img_list = dataset[class_id][sev][bottle_id]
k = frames_per_bottle
if len(img_list) >= k:
chosen_paths = rng.sample(img_list, k) # 无放回
else:
chosen_paths = [rng.choice(img_list) for _ in range(k)] # 不足则允许重复
print("Warning: Not enough images for bottle_id:", bottle_id)
for image_path in chosen_paths:
train_image_paths.append(image_path)
train_class_labels.append(int(class_id))
train_domain_labels.append(int(d_label))
# 测试集:其余未选中的瓶子的所有帧
for sev, bdict in sev_map.items():
for bottle_id, img_list in bdict.items():
if (sev, bottle_id) in picked_set:
continue
for image_path in img_list:
test_image_paths.append(image_path)
test_class_labels.append(int(class_id))
test_domain_labels.append(int(d_label))
return (train_image_paths, train_class_labels, train_domain_labels,
test_image_paths, test_class_labels, test_domain_labels)
def al9_domain_dataloader(datasets_root_dir, src_domain, src_n_shot, tar_domain, tar_n_shot, batch_size, seed):
src_domain_dataset = load_diameters_datasets(datasets_root_dir, src_domain)
tar_domain_dataset = load_diameters_datasets(datasets_root_dir, tar_domain)
(src_train_image_paths, src_train_class_labels, src_train_domain_labels,
_, _, _) = n_shot_split(src_domain_dataset, src_n_shot, frames_per_bottle=3, seed=seed, domain_id=src_domain)
(tar_train_image_paths, tar_train_class_labels, tar_train_domain_labels,
tar_test_image_paths, tar_test_class_labels, tar_test_domain_labels) = n_shot_split(
tar_domain_dataset, tar_n_shot, frames_per_bottle=3, seed=seed, domain_id=tar_domain)
src_train_dataset = AF9Dataset(src_train_image_paths, src_train_class_labels, src_train_domain_labels)
tar_train_dataset = AF9Dataset(tar_train_image_paths, tar_train_class_labels, tar_train_domain_labels)
test_dataset = AF9Dataset(tar_test_image_paths, tar_test_class_labels, tar_test_domain_labels)
src_train_loader = DataLoader(src_train_dataset, batch_size=batch_size//2, shuffle=True,
generator=torch.Generator().manual_seed(seed))
tar_train_loader = DataLoader(tar_train_dataset, batch_size=batch_size//2, shuffle=True,
generator=torch.Generator().manual_seed(seed))
tar_test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True,
generator=torch.Generator().manual_seed(seed))
return src_train_loader, tar_train_loader, tar_test_loader
# if __name__ == "__main__":
# datasets_root_dir = 'your_datasets_root_path'
# src_domain = '35'
# src_n_shot = None
# tar_domain = '15'
# tar_n_shot = 3
# batch_size = 32
# seed = 42
# src_train_loader, tar_train_loader, tar_test_loader = al9_domain_dataloader(datasets_root_dir, src_domain, src_n_shot, tar_domain, tar_n_shot, batch_size, seed)
# %%
class DivAugModel(nn.Module):
def __init__(self, num_classes=9, num_domains=3, pretrained=True, inchans=1):
super().__init__()
self.Ec = timm.create_model('timm/mobilenetv3_small_100.lamb_in1k', pretrained=pretrained, in_chans=inchans, num_classes=0)
self.Ed = timm.create_model('timm/mobilenetv3_small_100.lamb_in1k', pretrained=pretrained, in_chans=inchans, num_classes=0)
self.Cc = nn.Sequential(
nn.Linear(2048, 1024),
nn.Linear(1024, 128),
nn.Linear(128, num_classes),
)
self.Cd = nn.Sequential(
nn.Linear(2048, 1024),
nn.Linear(1024, 128),
nn.Linear(128, num_domains)
)
def forward_features(self, x1, x2):
f_c = self.Ec(x1)
f_d = self.Ed(x2)
return f_c, f_d
def feature_concat(self, f_c, f_d):
f_concat = torch.cat([f_c, f_d], dim=1)
return f_concat
def class_classify(self, f_concat):
pre_c = self.Cc(f_concat)
return pre_c
def domain_classify(self, f_concat):
pre_d = self.Cd(f_concat)
return pre_d
def forward(self, x1, x2, phase):
f_c, f_d = self.forward_features(x1, x2)
f_concat = self.feature_concat(f_c, f_d.detach())
pre_c = self.class_classify(f_concat)
if phase == 1:
f_concat = self.feature_concat(f_c.detach(), f_d)
pre_d = self.domain_classify(f_concat)
else:
pre_d = None
return pre_c, pre_d, f_c, f_d
# if __name__ == '__main__':
# model = DivAugModel()
# image = torch.rand(128, 128)
# image = image.unsqueeze(0).unsqueeze(0)
# f_c, f_d = model.forward_features(image, image)
# %%
def semantic_inconsistency_loss(c_feats, d_feats, tau=0.3):
B, _ = c_feats.shape
device = c_feats.device
if B < 2:
raise ValueError("Batch size must be at least 2.")
# 计算相似度矩阵
c_norm = F.normalize(c_feats, p=2, dim=1)
d_norm = F.normalize(d_feats, p=2, dim=1)
sim_matrix = torch.matmul(c_norm, d_norm.T) / tau
# 选取每行的正样本
row_indices = torch.arange(B, device=device).unsqueeze(1).expand(B, B-1)
col_candidates = torch.zeros(B, B-1, dtype=torch.long, device=device)
for i in range(B):
candidates = torch.cat([torch.arange(i, device=device),
torch.arange(i+1, B, device=device)])
col_candidates[i] = candidates
random_indices = torch.randint(0, B-1, (B,), device=device)
positive_cols = col_candidates[torch.arange(B), random_indices]
positive_sims = sim_matrix[torch.arange(B, device=device), positive_cols]
# 负样本, 每行除了正样本的其他元素
mask = torch.ones(B, B, device=device, dtype=torch.bool)
mask[torch.arange(B, device=device), positive_cols] = False
negative_sims = sim_matrix[mask].view(B, B-1)
# 对比损失, all_logits每行的第1个元素是正样本, softmax + BCE
all_logits = torch.cat([positive_sims.unsqueeze(1), negative_sims], dim=1)
labels = torch.zeros(B, dtype=torch.long, device=device)
loss = F.cross_entropy(all_logits, labels)
return loss
def Loss_s(c_feats, d_feats, tau=0.3):
Loss_c2d = semantic_inconsistency_loss(c_feats, d_feats, tau)
Loss_d2c = semantic_inconsistency_loss(d_feats, c_feats, tau)
return Loss_c2d + Loss_d2c
# if __name__ == '__main__':
# # 测试Loss_s函数
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# # 测试用例1:完全正交的特征
# print("=== 测试1:正交特征 ===")
# c_feats_orth = torch.tensor([[1.0, 0.0], [0.0, 1.0]], device=device)
# d_feats_orth = torch.tensor([[0.0, 1.0], [1.0, 0.0]], device=device)
# loss_orth = Loss_s(c_feats_orth, d_feats_orth)
# print(f"正交特征Loss_s: {loss_orth.item():.4f}")
# # 测试用例2:完全相同的特征
# print("\n=== 测试2:相同特征 ===")
# c_feats_same = torch.tensor([[1.0, 0.0], [0.0, 1.0]], device=device)
# d_feats_same = torch.tensor([[1.0, 0.0], [0.0, 1.0]], device=device)
# loss_same = Loss_s(c_feats_same, d_feats_same)
# print(f"相同特征Loss_s: {loss_same.item():.4f}")
# # 测试用例3:半正交特征
# print("\n=== 测试3:半正交特征 ===")
# c_feats_semi = torch.tensor([[1.0, 0.0], [0.0, 1.0]], device=device)
# d_feats_semi = torch.tensor([[0.707, 0.707], [-0.707, 0.707]], device=device) # 45度旋转
# loss_semi = Loss_s(c_feats_semi, d_feats_semi)
# print(f"半正交特征Loss_s: {loss_semi.item():.4f}")
# # 测试用例4:随机特征
# print("\n=== 测试4:随机特征 ===")
# torch.manual_seed(42)
# c_feats_rand = torch.randn(4, 8, device=device)
# d_feats_rand = torch.randn(4, 8, device=device)
# loss_rand = Loss_s(c_feats_rand, d_feats_rand)
# print(f"随机特征Loss_s: {loss_rand.item():.4f}")
# print("\n=== 预期结果 ===")
# print("语义不一致损失应该:")
# print("- 相同特征时最小(接近0)")
# print("- 正交特征时较大")
# print("- 半正交特征时中等")
# print("- 随机特征时变化较大")
# %%
def train_and_evaluation(datasets_root_dir, output_dir,
src_domain, src_n_shot, tar_domain, tar_n_shot, seed,
learning_rate=1e-3, momentum=0.9, weight_decay=5e-4,
num_epochs=100, batch_size=32, tau=0.3, lamda=3.0, N_t=10):
writer = SummaryWriter(log_dir=f'{output_dir}')
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
src_train_loader, tar_train_loader, tar_test_loader = al9_domain_dataloader(datasets_root_dir, src_domain, src_n_shot, tar_domain, tar_n_shot, batch_size, seed)
tar_train_cycle_loader = itertools.cycle(tar_train_loader)
model = DivAugModel(num_classes=9, num_domains=3, pretrained=True, inchans=1).to(DEVICE)
criterion = nn.CrossEntropyLoss()
# optimizer_c = torch.optim.SGD(
# list(model.Ec.parameters()) + list(model.Cc.parameters()),
# lr=learning_rate, momentum=momentum, weight_decay=weight_decay
# )
# optimizer_d = torch.optim.SGD(
# list(model.Ed.parameters()) + list(model.Cd.parameters()),
# lr=learning_rate, momentum=momentum, weight_decay=weight_decay
# )
# scheduler_c = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_c, T_max=num_epochs, eta_min=0)
# scheduler_d = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_d, T_max=num_epochs, eta_min=0)
optimizer_c = torch.optim.Adam(
list(model.Ec.parameters()) + list(model.Cc.parameters()),
lr=learning_rate)
optimizer_d = torch.optim.Adam(
list(model.Ed.parameters()) + list(model.Cd.parameters()),
lr=learning_rate)
scheduler_c = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_c, T_max=num_epochs, eta_min=0)
scheduler_d = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_d, T_max=num_epochs, eta_min=0)
# scheduler_c = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer_c, patience=3, factor=0.5, min_lr=1e-6)
# scheduler_d = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer_d, patience=3, factor=0.5, min_lr=1e-6)
best_acc_c = 0.0
for epoch in range(num_epochs):
model.train()
total_train_samples = 0 # 添加总样本数计数器
train_correct_predict_c = 0
train_acc_c = 0.0
total_loss_c = 0.0
total_loss_d = 0.0
total_loss_s = 0.0
total_loss_aug = 0.0
Ed_Cd_freeze_flag = False
for src_images, src_labels, src_domain in src_train_loader:
tar_images, tar_labels, tar_domain = next(tar_train_cycle_loader)
images = torch.cat([src_images, tar_images], dim=0).to(DEVICE)
labels = torch.cat([src_labels, tar_labels], dim=0).to(DEVICE)
domain = torch.cat([src_domain, tar_domain], dim=0).to(DEVICE)
if epoch < N_t:
phase = 1
pre_c, pre_d, f_c, f_d = model(images, images, phase)
optimizer_c.zero_grad()
loss_c = criterion(pre_c, labels)
loss_s1 = Loss_s(f_c, f_d.detach(), tau)
loss_c_s = loss_c + loss_s1
loss_c_s.backward()
optimizer_c.step()
# scheduler_c.step()
optimizer_d.zero_grad()
loss_d = criterion(pre_d, domain)
loss_s2 = Loss_s(f_c.detach(), f_d, tau)
loss_d_s = loss_d + loss_s2
loss_d_s.backward()
optimizer_d.step()
# scheduler_d.step()
else:
phase = 2
if Ed_Cd_freeze_flag == False:
for param in model.Ed.parameters():
param.requires_grad = False
for param in model.Cd.parameters():
param.requires_grad = False
Ed_Cd_freeze_flag = True
pre_c, _, c_feats, d_feats = model(images, images, phase)
optimizer_c.zero_grad()
loss_c = criterion(pre_c, labels)
loss_s1 = Loss_s(c_feats, d_feats.detach(), tau)
src_batch = src_images.size(0)
tar_batch = tar_images.size(0)
N = min(src_batch, tar_batch)
torch.manual_seed(epoch * 1000 + seed)
src_indices = torch.randperm(src_batch, device=DEVICE)[:N]
src_c_feats = c_feats[src_indices]
tar_indices = torch.randperm(tar_batch, device=DEVICE)[:N] + src_batch
tar_d_feats = d_feats[tar_indices]
f_aug = torch.cat([src_c_feats, tar_d_feats], dim=1)
f_aug_labels = labels[src_indices]
pre_c_aug = model.class_classify(f_aug)
loss_aug = criterion(pre_c_aug, f_aug_labels)
loss_c_s_aug = loss_c + loss_s1 + lamda * loss_aug
loss_c_s_aug.backward()
optimizer_c.step()
# scheduler_c.step()
total_loss_c += loss_c.item() * src_images.size(0)
if phase == 1:
total_loss_d += loss_d.item() * src_images.size(0)
total_loss_s += (loss_s1.item() + loss_s2.item())/2 * src_images.size(0)
else:
total_loss_aug += loss_aug.item() * src_images.size(0)
total_loss_s += loss_s1.item() * src_images.size(0)
predict_c = torch.max(pre_c, 1)[1]
train_correct_predict_c += torch.sum(predict_c == labels.data)
total_train_samples += labels.size(0)
epoch_loss_c = total_loss_c / len(src_train_loader.dataset)
writer.add_scalar('Loss/train_loss_c', epoch_loss_c, epoch)
epoch_loss_s = total_loss_s / len(src_train_loader.dataset)
writer.add_scalar('Loss/train_loss_s', epoch_loss_s, epoch)
if phase == 1:
scheduler_c.step()
scheduler_d.step()
epoch_loss_d = total_loss_d / len(src_train_loader.dataset)
writer.add_scalar('Loss/train_loss_d', epoch_loss_d, epoch)
else:
scheduler_c.step()
epoch_loss_aug = total_loss_aug / len(src_train_loader.dataset)
writer.add_scalar('Loss/train_loss_aug', epoch_loss_aug, epoch)
train_acc_c = train_correct_predict_c.double() / total_train_samples
writer.add_scalar('Acc/train_acc_c', train_acc_c, epoch)
model.eval()
test_loss_c = 0.0
test_loss_d = 0.0
test_correct_predict_c = 0
test_correct_predict_d = 0
for tar_images, tar_labels, tar_domain in tar_test_loader:
with torch.no_grad():
tar_images = tar_images.to(DEVICE)
tar_labels = tar_labels.to(DEVICE)
tar_domain = tar_domain.to(DEVICE)
pre_c, pre_d, f_c, f_d = model(tar_images, tar_images, phase)
test_loss_c += criterion(pre_c, tar_labels)
predict_c = torch.max(pre_c, 1)[1]
test_correct_predict_c += torch.sum(predict_c == tar_labels.data)
if phase == 1:
test_loss_d += criterion(pre_d, tar_domain.to(DEVICE))
predict_d = torch.max(pre_d, 1)[1]
test_correct_predict_d += torch.sum(predict_d == tar_domain.data)
test_loss_c = test_loss_c / len(tar_test_loader)
# scheduler_c.step(test_loss_c)
writer.add_scalar('Loss/test_loss_c', test_loss_c, epoch)
if phase == 1:
test_loss_d = test_loss_d / len(tar_test_loader)
# scheduler_d.step(test_loss_d)
writer.add_scalar('Loss/test_loss_d', test_loss_d, epoch)
test_acc_c = test_correct_predict_c.double() / len(tar_test_loader.dataset)
if test_acc_c > best_acc_c:
best_acc_c = test_acc_c
torch.save(model.state_dict(), os.path.join(output_dir, 'best_model.pth'))
writer.add_scalar('Acc/test_acc_c', test_acc_c, epoch)
writer.add_scalar('Acc/test_best_acc_c', best_acc_c, epoch)
writer.close()
return test_acc_c.cpu().item(), best_acc_c.cpu().item()
# %%
def compute_mean_std_acc(acc_dict, save_path):
# 备份原始 acc_dict
backup_acc_dict = copy.deepcopy(acc_dict)
# 存储均值和标准差
stats = {}
for key, value in acc_dict.items():
domain_pair = "_".join(key.split("_")[:3]) # e.g. 15_to_26
if domain_pair not in stats:
stats[domain_pair] = []
stats[domain_pair].append(value)
mean_std_results = {}
all_means = []
for domain_pair, values in stats.items():
mean = np.mean(values)
std = np.std(values)
# 保存为 mean±std 形式(保留小数位可自行调整,比如:.4f)
mean_std_results[domain_pair] = f"{mean*100:.2f}±{std*100:.1f}"
all_means.append(mean)
# 计算宏平均
macro_results = {
"macro_mean": f"{np.mean(all_means)*100:.2f}",
"macro_std": f"{np.std(all_means)*100:.1f}"
}
# 最终保存的内容
output = {
"per_fold_acc": backup_acc_dict,
"5fold_mean_std_acc": mean_std_results,
"macro_acc": macro_results
}
# 保存到 JSON 文件
with open(save_path, "w", encoding="utf-8") as f:
json.dump(output, f, indent=4, ensure_ascii=False)
# %%
def seed_everything(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
if __name__ == '__main__':
root_data = 'your_datasets_roo_patht'
base_model = 'mobilenetv3_small_100' #'VGG16' #'mobilenetv3_small_100'
src_N_shot=30
tar_N_shot=1
learning_rate=1e-4
n_epoch = 100
n_class = 9
N_t = 10
source_target_domain = [['15','26'], ['15','35'], ['26','35'], ['26','15'], ['35','15'], ['35','26']]
# source_target_domain = [['15','35'], ['26','15'], ['26','35'], ['35','15'], ['35','26']]
root_output = f'./AF9-DivAug/{src_N_shot}-{tar_N_shot}-shot'
best_acc_dict = {}
last_acc_dict = {}
for source_domain, target_domain in source_target_domain:
for fold_id in range(5):
output_dir = f'{root_output}/{source_domain}_to_{target_domain}/fold_{fold_id}'
random_seed = fold_id
seed_everything(random_seed)
last_acc, best_acc = train_and_evaluation(root_data, output_dir,
source_domain, src_N_shot, target_domain, tar_N_shot, random_seed,
learning_rate=learning_rate, momentum=0.9, weight_decay=5e-4,
num_epochs=n_epoch, batch_size=32, tau=0.3, lamda=3.0, N_t=N_t)
last_acc_dict[f'{source_domain}_to_{target_domain}_fold{fold_id}'] = last_acc
best_acc_dict[f'{source_domain}_to_{target_domain}_fold{fold_id}'] = best_acc
compute_mean_std_acc(last_acc_dict, f'{root_output}/last_acc_all_results.json')
compute_mean_std_acc(best_acc_dict, f'{root_output}/best_acc_all_results.json')4. 监控训练
bash
tensorboard --logdir=这里填root_output的路径