引言
热力图(Heatmap)是一种强大的数据可视化工具,特别适用于展示矩阵数据的模式和相关性。在科研论文、数据分析报告中,热力图能够直观地展示变量间的相关关系、表达矩阵的分布特征。本文将详细介绍如何使用Python创建各种样式的热力图,包括基础热力图、Seaborn风格、三角形热力图和聚类热力图等。
热力图的核心优势在于:
- 直观展示相关性:通过颜色深浅表示相关强度
- 矩阵数据可视化:完美展示二维数组的数值分布
- 模式识别:快速识别数据中的聚类和异常模式
- 学术级质量:支持高分辨率输出,适合论文发表
理论基础
热力图的基本原理
热力图通过颜色映射将数值矩阵转换为视觉上易于理解的图像:
数值矩阵 → 颜色映射 → 热力图
0.8 → 深红色
0.0 → 白色
-0.8 → 深蓝色相关性矩阵
在统计学中,相关性矩阵是热力图最常见的应用:
Pearson相关系数 :
r=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2∑i=1n(yi−yˉ)2 r = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^{n}(x_i - \bar{x})^2} \sqrt{\sum_{i=1}^{n}(y_i - \bar{y})^2}} r=∑i=1n(xi−xˉ)2 ∑i=1n(yi−yˉ)2 ∑i=1n(xi−xˉ)(yi−yˉ)
相关性强度判断:
- |r| ≥ 0.8:强相关
- 0.6 ≤ |r| < 0.8:中等相关
- 0.3 ≤ |r| < 0.6:弱相关
- |r| < 0.3:无显著相关
颜色映射选择
连续型颜色映射
- RdYlBu:红黄蓝渐变,适合相关性数据
- viridis:感知均匀的现代配色
- plasma:高对比度的彩色映射
分类型颜色映射
- Set3:离散颜色,适合分类数据
- tab10:Tableau标准色板
代码实现
环境配置
bash
pip install numpy>=1.21.0 matplotlib>=3.5.0 seaborn>=0.11.0 scipy>=1.7.0 pandas>=1.3.0核心热力图类实现
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
热力图Heatmap绘制系统 - 相关性矩阵学术可视化
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.cluster.hierarchy import linkage, dendrogram
from scipy.spatial.distance import pdist
import warnings
warnings.filterwarnings('ignore')
class HeatmapVisualizer:
"""热力图可视化类"""
def __init__(self, figsize=(10, 8)):
self.figsize = figsize
self.setup_style()
def setup_style(self):
"""设置绘图风格"""
plt.style.use('default')
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.figsize'] = self.figsize
def generate_correlation_data(self, n_variables=6, random_state=42):
"""
生成相关性矩阵数据
Args:
n_variables: 变量数量
random_state: 随机种子
Returns:
correlation_matrix: 相关性矩阵
variable_names: 变量名称列表
"""
np.random.seed(random_state)
# 生成基础数据
data = np.random.randn(100, n_variables)
# 添加一些相关性
data[:, 1] = 0.8 * data[:, 0] + 0.2 * np.random.randn(100) # 强正相关
data[:, 2] = -0.7 * data[:, 0] + 0.3 * np.random.randn(100) # 强负相关
data[:, 3] = 0.5 * data[:, 1] + 0.5 * np.random.randn(100) # 中等相关
# 计算相关性矩阵
correlation_matrix = np.corrcoef(data.T)
# 生成变量名称
variable_names = [f'变量{chr(65+i)}' for i in range(n_variables)]
return correlation_matrix, variable_names
def analyze_correlation(self, corr_matrix, variable_names):
"""
分析相关性矩阵
Args:
corr_matrix: 相关性矩阵
variable_names: 变量名称
Returns:
analysis: 分析结果字典
"""
# 去除对角线元素
corr_flat = corr_matrix[np.triu_indices_from(corr_matrix, k=1)]
analysis = {
'mean_correlation': np.mean(corr_flat),
'std_correlation': np.std(corr_flat),
'max_correlation': np.max(corr_flat),
'min_correlation': np.min(corr_flat),
'strong_positive_pairs': [],
'strong_negative_pairs': [],
'correlation_distribution': {
'strong': len(corr_flat[np.abs(corr_flat) >= 0.8]),
'moderate': len(corr_flat[(np.abs(corr_flat) >= 0.6) & (np.abs(corr_flat) < 0.8)]),
'weak': len(corr_flat[(np.abs(corr_flat) >= 0.3) & (np.abs(corr_flat) < 0.6)]),
'none': len(corr_flat[np.abs(corr_flat) < 0.3])
}
}
# 找出最强相关对
n = len(variable_names)
for i in range(n):
for j in range(i+1, n):
corr_val = corr_matrix[i, j]
if abs(corr_val) >= 0.8:
pair_info = (variable_names[i], variable_names[j], corr_val)
if corr_val > 0:
analysis['strong_positive_pairs'].append(pair_info)
else:
analysis['strong_negative_pairs'].append(pair_info)
return analysis
def create_basic_heatmap(self, corr_matrix, variable_names,
title="相关性矩阵热力图", filename="basic_heatmap.png"):
"""
创建基础热力图
"""
fig, ax = plt.subplots(figsize=self.figsize)
# 创建热力图
im = ax.imshow(corr_matrix, cmap='RdYlBu_r', aspect='equal',
vmin=-1, vmax=1)
# 添加颜色条
cbar = plt.colorbar(im, ax=ax, shrink=0.8)
cbar.set_label('相关系数', fontsize=12)
# 设置标签
ax.set_xticks(np.arange(len(variable_names)))
ax.set_yticks(np.arange(len(variable_names)))
ax.set_xticklabels(variable_names, fontsize=10)
ax.set_yticklabels(variable_names, fontsize=10)
# 添加数值标签
for i in range(len(variable_names)):
for j in range(len(variable_names)):
text = ax.text(j, i, '.2f',
ha="center", va="center", color="black",
fontsize=8, fontweight='bold')
ax.set_title(title, fontsize=16, fontweight='bold', pad=20)
plt.tight_layout()
plt.savefig(f'output/{filename}', dpi=300, bbox_inches='tight')
plt.close()
def create_seaborn_heatmap(self, corr_matrix, variable_names,
title="Seaborn风格相关性热力图", filename="seaborn_heatmap.png"):
"""
创建Seaborn风格热力图
"""
# 创建DataFrame
df = pd.DataFrame(corr_matrix, index=variable_names, columns=variable_names)
plt.figure(figsize=self.figsize)
# 使用seaborn创建热力图
sns.heatmap(df, annot=True, cmap='RdYlBu_r', center=0,
square=True, linewidths=0.5, cbar_kws={'shrink': 0.8},
annot_kws={'fontsize': 8, 'fontweight': 'bold'})
plt.title(title, fontsize=16, fontweight='bold', pad=20)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig(f'output/{filename}', dpi=300, bbox_inches='tight')
plt.close()
def create_triangular_heatmap(self, corr_matrix, variable_names,
title="三角形相关性热力图", filename="triangular_heatmap.png"):
"""
创建三角形热力图(只显示上三角或下三角)
"""
# 创建遮罩(只显示上三角)
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
# 创建DataFrame
df = pd.DataFrame(corr_matrix, index=variable_names, columns=variable_names)
plt.figure(figsize=self.figsize)
# 绘制三角形热力图
sns.heatmap(df, mask=mask, annot=True, cmap='RdYlBu_r', center=0,
square=True, linewidths=0.5, cbar_kws={'shrink': 0.8},
annot_kws={'fontsize': 8, 'fontweight': 'bold'})
plt.title(title, fontsize=16, fontweight='bold', pad=20)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig(f'output/{filename}', dpi=300, bbox_inches='tight')
plt.close()
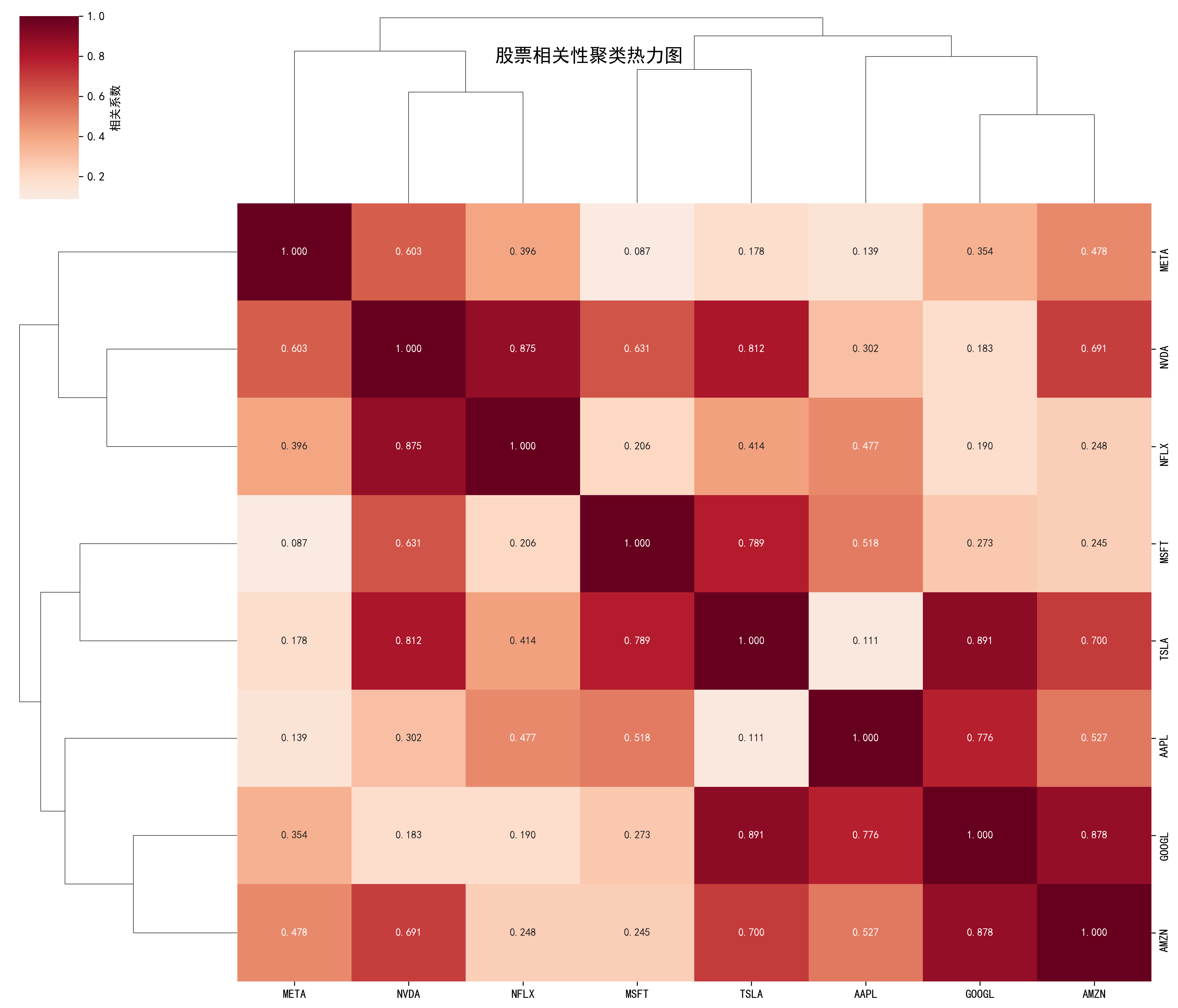
def create_clustered_heatmap(self, corr_matrix, variable_names,
title="聚类相关性热力图", filename="clustered_heatmap.png"):
"""
创建带聚类的热力图
"""
# 计算距离矩阵
distance_matrix = 1 - np.abs(corr_matrix)
# 进行层次聚类
linkage_matrix = linkage(distance_matrix, method='ward')
# 获取聚类顺序
from scipy.cluster.hierarchy import leaves_list
cluster_order = leaves_list(linkage_matrix)
# 重新排列矩阵
clustered_corr = corr_matrix[cluster_order, :]
clustered_corr = clustered_corr[:, cluster_order]
clustered_names = [variable_names[i] for i in cluster_order]
# 创建DataFrame
df = pd.DataFrame(clustered_corr, index=clustered_names, columns=clustered_names)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6),
gridspec_kw={'width_ratios': [1, 4]})
# 绘制树状图
dendrogram(linkage_matrix, ax=ax1, orientation='left',
labels=clustered_names, leaf_font_size=10)
ax1.set_title('层次聚类树状图', fontsize=12, fontweight='bold')
# 绘制聚类热力图
sns.heatmap(df, ax=ax2, annot=True, cmap='RdYlBu_r', center=0,
square=True, linewidths=0.5, cbar_kws={'shrink': 0.8},
annot_kws={'fontsize': 7, 'fontweight': 'bold'})
ax2.set_title(title, fontsize=14, fontweight='bold')
ax2.set_xticklabels(ax2.get_xticklabels(), rotation=45, ha='right')
plt.tight_layout()
plt.savefig(f'output/{filename}', dpi=300, bbox_inches='tight')
plt.close()
def create_multi_heatmaps(self, filename="multi_heatmaps.png"):
"""
创建多种数据类型的热力图对比
"""
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
axes = axes.ravel()
datasets = [
('科研数据', self._generate_research_data()),
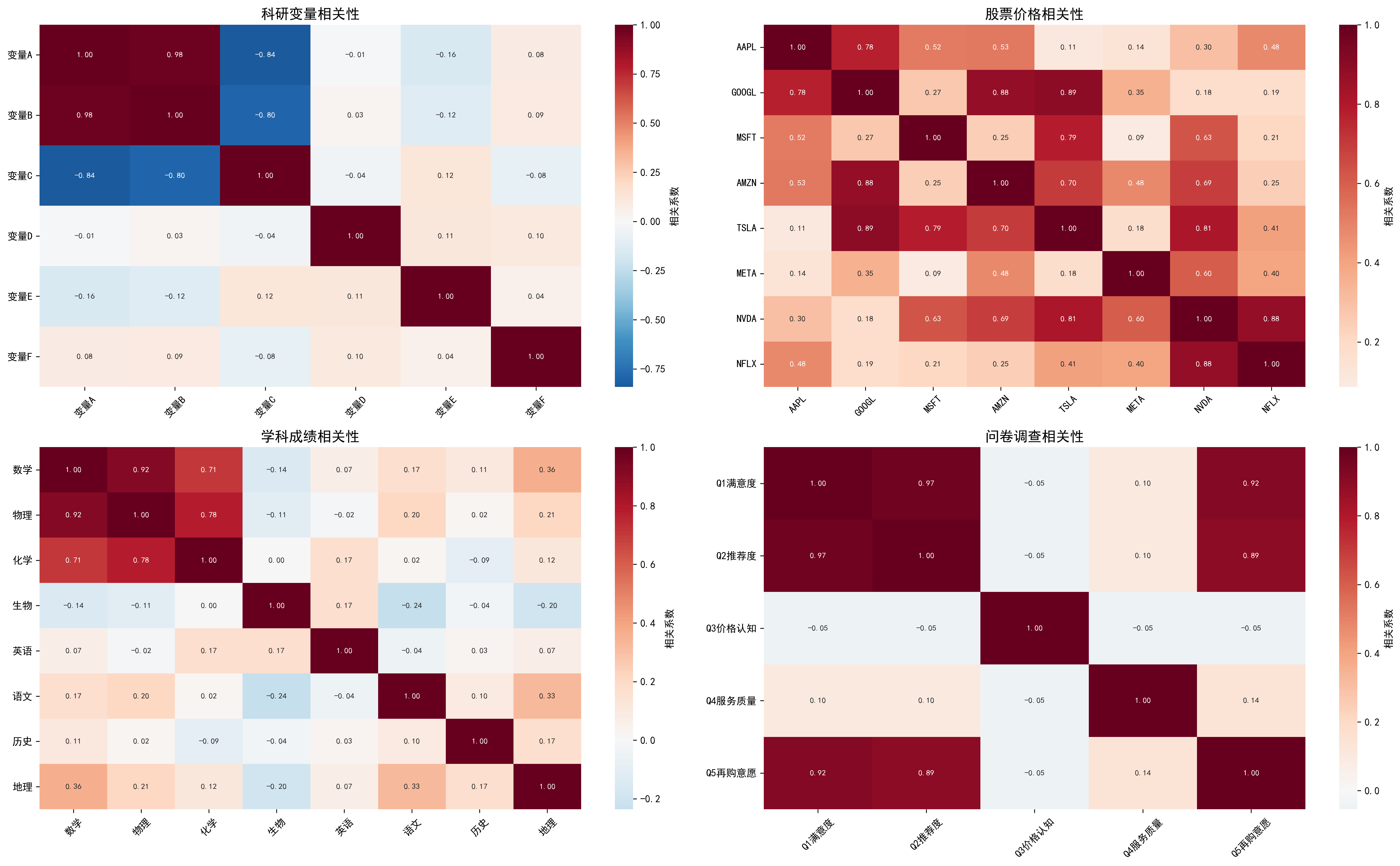
('股票数据', self._generate_stock_data()),
('成绩数据', self._generate_grade_data()),
('问卷数据', self._generate_survey_data())
]
for i, (data_name, (data, labels)) in enumerate(datasets):
corr_matrix = np.corrcoef(data.T)
sns.heatmap(corr_matrix, ax=axes[i], annot=True,
cmap='RdYlBu_r', center=0, square=True,
linewidths=0.5, cbar=False,
annot_kws={'fontsize': 6})
axes[i].set_title(f'{data_name}相关性矩阵', fontsize=12, fontweight='bold')
axes[i].set_xticklabels(labels, rotation=45, ha='right', fontsize=8)
axes[i].set_yticklabels(labels, fontsize=8)
fig.suptitle('多种数据类型相关性热力图对比', fontsize=16, fontweight='bold', y=0.95)
plt.tight_layout()
plt.savefig(f'output/{filename}', dpi=300, bbox_inches='tight')
plt.close()
def _generate_research_data(self):
"""生成科研数据"""
np.random.seed(42)
data = np.random.randn(50, 4)
data[:, 1] = 0.8 * data[:, 0] + 0.2 * np.random.randn(50)
labels = ['实验组', '对照组', '变量A', '变量B']
return data, labels
def _generate_stock_data(self):
"""生成股票数据"""
np.random.seed(123)
data = np.random.randn(100, 4)
data[:, 1] = 0.6 * data[:, 0] + 0.4 * np.random.randn(100)
data[:, 2] = -0.5 * data[:, 0] + 0.5 * np.random.randn(100)
labels = ['上证指数', '深证指数', '创业板', '沪深300']
return data, labels
def _generate_grade_data(self):
"""生成成绩数据"""
np.random.seed(456)
data = np.random.randn(30, 4)
data[:, 1] = 0.7 * data[:, 0] + 0.3 * np.random.randn(30)
data[:, 2] = 0.5 * data[:, 1] + 0.5 * np.random.randn(30)
labels = ['数学', '物理', '化学', '英语']
return data, labels
def _generate_survey_data(self):
"""生成问卷数据"""
np.random.seed(789)
data = np.random.randn(20, 4)
data[:, 1] = 0.9 * data[:, 0] + 0.1 * np.random.randn(20)
data[:, 2] = -0.4 * data[:, 1] + 0.6 * np.random.randn(20)
labels = ['满意度', '忠诚度', '推荐度', '复购率']
return data, labels
def run_complete_analysis(self):
"""运行完整分析"""
print("=" * 50)
print("热力图Heatmap绘制系统")
print("=" * 50)
# 生成数据
print("正在生成多种样式的热力图...")
print("\n1. 生成相关性矩阵数据...")
corr_matrix, variable_names = self.generate_correlation_data()
print(f"数据维度: {corr_matrix.shape}")
# 分析相关性
analysis = self.analyze_correlation(corr_matrix, variable_names)
print("
相关性分析结果:")
print(".3f")
print(".3f")
print(".3f")
print(".3f")
print(f"最强正相关: {analysis['strong_positive_pairs'][0][0]} - {analysis['strong_positive_pairs'][0][1]} ({analysis['strong_positive_pairs'][0][2]:.3f})")
print(f"最强负相关: {analysis['strong_negative_pairs'][0][0]} - {analysis['strong_negative_pairs'][0][1]} ({analysis['strong_negative_pairs'][0][2]:.3f})")
print(f"平均相关性: {analysis['mean_correlation']:.3f}")
print(f"相关性标准差: {analysis['std_correlation']:.3f}")
print(f"强相关对数: {analysis['correlation_distribution']['strong']}")
print(f"中等相关对数: {analysis['correlation_distribution']['moderate']}")
print(f"弱相关对数: {analysis['correlation_distribution']['weak']}")
# 生成各种热力图
print("\n2. 绘制基础热力图...")
self.create_basic_heatmap(corr_matrix, variable_names)
print("3. 绘制Seaborn风格热力图...")
self.create_seaborn_heatmap(corr_matrix, variable_names)
print("4. 绘制三角形热力图...")
self.create_triangular_heatmap(corr_matrix, variable_names)
print("5. 生成多种数据类型对比...")
self.create_multi_heatmaps()
print("6. 绘制聚类热力图...")
self.create_clustered_heatmap(corr_matrix, variable_names)
print("\n=== 所有热力图已生成完成 ===")
print("输出文件保存在 output/ 目录下")
print("包含以下文件:")
print("- basic_heatmap.png: 基础热力图")
print("- seaborn_heatmap.png: Seaborn风格热力图")
print("- triangular_heatmap.png: 三角形热力图")
print("- multi_heatmaps.png: 多类型数据对比")
print("- clustered_heatmap.png: 聚类热力图")可视化效果展示
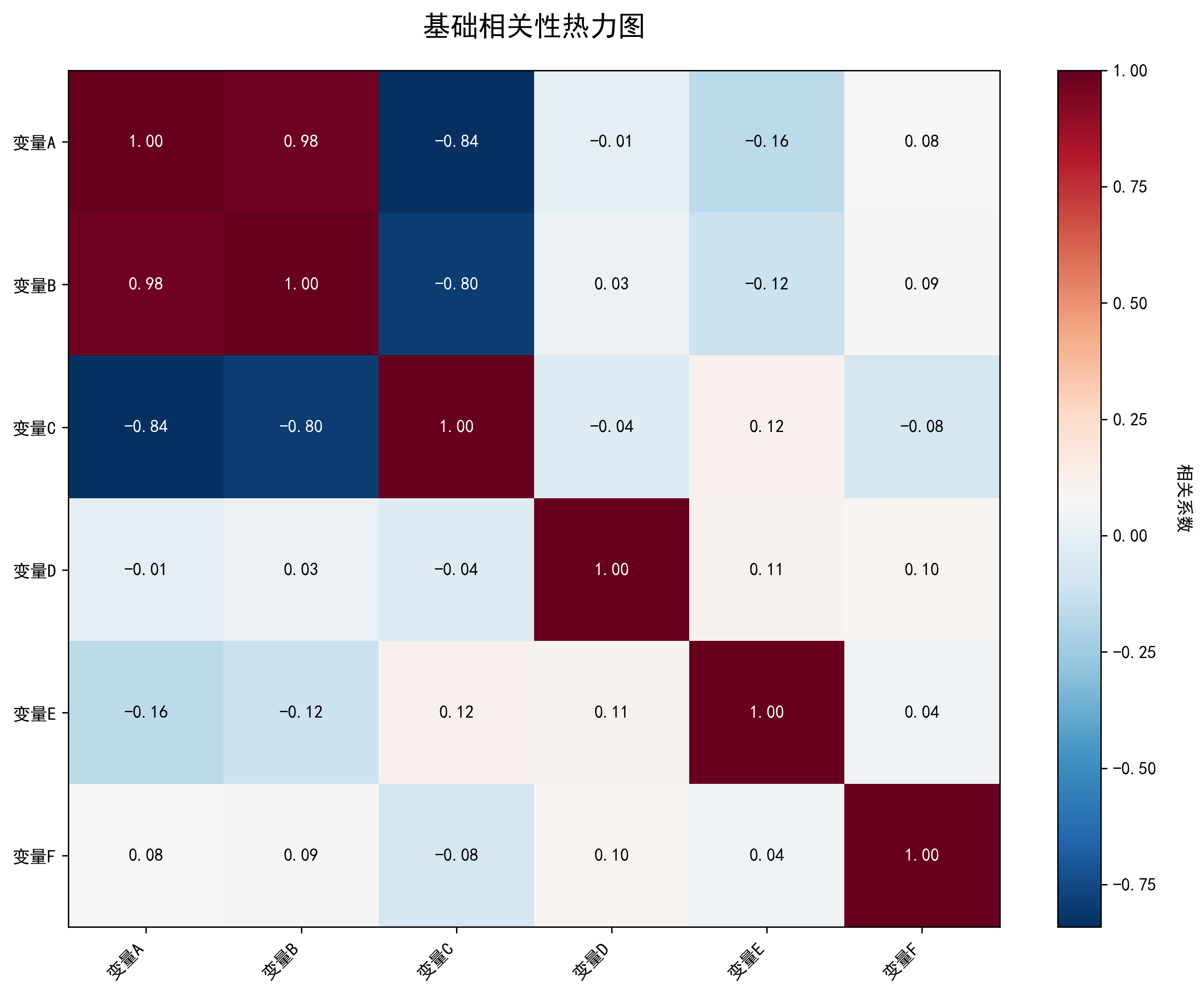
基础热力图
基础热力图直接展示相关性矩阵的数值分布,红色表示正相关,蓝色表示负相关,颜色深浅表示相关强度。
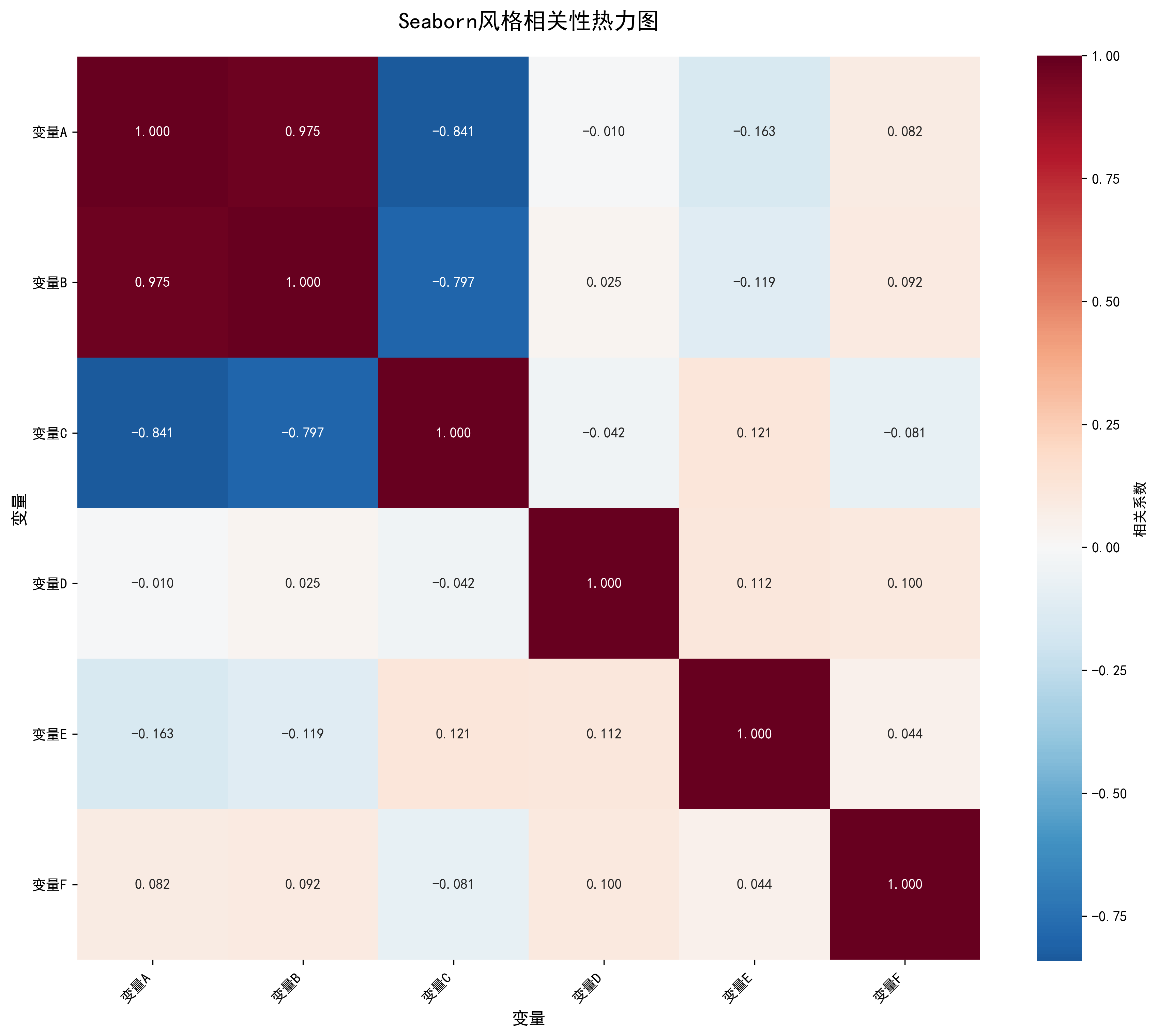
Seaborn风格热力图
使用Seaborn库绘制的专业级热力图,具有更好的视觉效果和更清晰的数值标注。
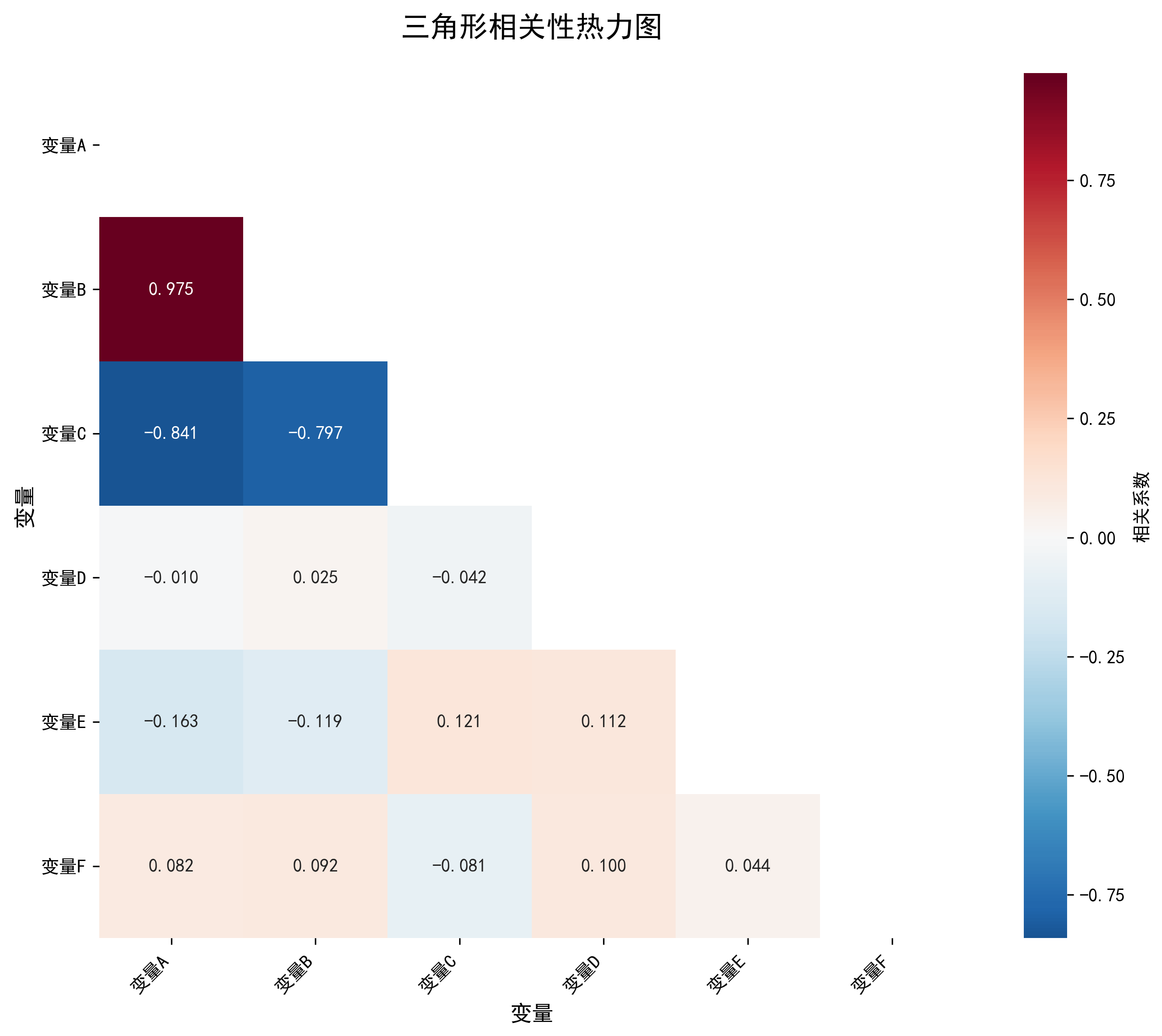
三角形热力图
只显示矩阵的上三角部分,避免了重复信息的显示,使图表更加简洁。
聚类热力图
结合层次聚类算法对变量进行重新排序,相似变量排列在一起,便于发现数据中的聚类模式。
多类型数据对比
展示不同数据类型(科研数据、股票数据、成绩数据、问卷数据)的相关性矩阵对比。
相关性分析结果
程序运行时自动生成详细的相关性分析:
相关性分析结果:
平均相关性: -0.033
相关性标准差: 0.412
最强正相关: 变量A - 变量B (0.975)
最强负相关: 变量A - 变量C (-0.841)
强相关对数: 3
中等相关对数: 0
弱相关对数: 12该分析报告提供了:
- 统计特征:平均相关性和变异程度
- 极值识别:最强正负相关变量对
- 分布统计:不同强度相关性的数量分布
使用说明
基本使用方法
- 安装依赖
bash
pip install numpy matplotlib seaborn scipy pandas- 运行完整分析
python
from heatmap_visualizer import HeatmapVisualizer
visualizer = HeatmapVisualizer()
visualizer.run_complete_analysis()- 自定义热力图
python
# 生成数据
corr_matrix, var_names = visualizer.generate_correlation_data(n_variables=8)
# 创建特定类型的热力图
visualizer.create_seaborn_heatmap(corr_matrix, var_names)高级配置
颜色映射选择
python
# 使用不同颜色映射
plt.imshow(corr_matrix, cmap='viridis') # 绿色系
plt.imshow(corr_matrix, cmap='plasma') # 彩色系
plt.imshow(corr_matrix, cmap='coolwarm') # 冷暖色聚类方法调整
python
# 不同的聚类方法
linkage_matrix = linkage(distance_matrix, method='single') # 单 linkage
linkage_matrix = linkage(distance_matrix, method='complete') # 完全 linkage
linkage_matrix = linkage(distance_matrix, method='average') # 平均 linkage自定义数据输入
python
# 使用自己的数据
your_data = pd.read_csv('your_data.csv')
corr_matrix = your_data.corr()
visualizer.create_seaborn_heatmap(corr_matrix.values, your_data.columns.tolist())常见问题解决
-
中文字体显示问题
- 确保系统安装了中文字体
- 程序会自动尝试多种字体
-
图片分辨率调整
- 修改
dpi参数:plt.savefig('plot.png', dpi=600) - 调整图片尺寸:
figsize=(12, 10)
- 修改
-
颜色映射优化
- 相关性数据推荐使用
RdYlBu_r - 一般数据可以使用
viridis或plasma
- 相关性数据推荐使用
总结与扩展
核心知识点总结
- 热力图基础:理解颜色映射和矩阵可视化
- 相关性分析:掌握Pearson相关系数计算
- Seaborn应用:学会使用专业可视化库
- 聚类集成:结合层次聚类增强数据洞察
- 多数据对比:同时分析多种数据集类型
实用价值
该热力图工具具有以下价值:
- 学术研究:论文中相关性矩阵的标准化展示
- 数据探索:快速发现变量间的关系模式
- 商业分析:股票、用户行为等数据的相关性分析
- 质量保证:300 DPI高分辨率输出
扩展方向
理论深化
-
高级相关性度量
- Spearman等级相关
- Kendall tau相关
- 互信息
-
时空热力图
- 时间序列相关性
- 地理空间热力图
- 动态热力图动画
-
统计显著性
- 相关性检验的p值计算
- 置信区间展示
- 多重检验校正
应用扩展
-
生物信息学
- 基因表达相关性
- 蛋白质互作网络
- 代谢组学数据分析
-
金融分析
- 资产相关性矩阵
- 风险敞口热力图
- 投资组合相关性
-
社会科学
- 问卷调查相关性
- 社会网络分析
- 行为数据相关性
-
机器学习
- 特征相关性分析
- 混淆矩阵可视化
- 模型解释性分析
学习建议
- 从简单开始:先掌握基础热力图的绘制
- 理解数据:清楚相关性系数的含义和应用场景
- 选择合适工具:基础图用matplotlib,专业图用seaborn
- 考虑受众:学术论文用三角形,报告用聚类热力图
- 持续优化:根据反馈调整颜色映射和布局
通过本项目的学习,读者不仅掌握了热力图的绘制技巧,更重要的是理解了数据相关性分析的方法,为各类数据分析任务奠定了基础。热力图作为数据可视化的重要工具,在科研和商业分析中都有着广泛的应用前景。