
2025 年 2 月 12 日
1.摘要
background
多模态大语言模型(MLLMs)在短视频理解上表现出色,但在处理长视频时仍然面临巨大挑战。长视频包含更复杂的动态行为和时间关系,导致 MLLMs 难以有效定位关键视频片段,经常出现"幻觉"(Hallucination)现象,即生成与视频内容不符的描述。因此,核心问题是:如何提升 MLLMs 对长视频的理解能力,并抑制其幻觉问题? 论文提出了一个自然的问题:我们能否利用时间定位(temporal grounding)作为辅助任务来增强长视频理解?
innovation
论文提出了一个名为 TimeSuite 的综合解决方案,它不是单一模型,而是一系列新设计的集合。
1.高效长视频处理框架 (VideoChat-T):
Token Shuffle:提出了一种简单高效的令牌压缩方案。它通过在通道维度上合并相邻的视觉令牌(tokens)再进行线性投影,有效减少了长视频中海量视觉令牌带来的计算负担,同时保持了时间连续性。相比于池化(pooling)或聚类(clustering),这种方法更灵活且性能损失更小。
Temporal Adaptive Position Encoding (TAPE):设计了一个即插即用的时间自适应位置编码模块。它能为视频令牌序列生成自适应的位置编码,增强模型对时间顺序的感知能力,这对于需要精确定位时间的任务至关重要。
2.高质量的指令微调数据集 (TimePro):
构建了一个以时间为中心的、大规模、高质量的指令微调数据集 TimePro。它包含 9 种任务类型和约 34.9 万个带有精确时间戳的标注,数据来源多样,质量高。这为模型学习精确的时间感知能力提供了丰富监督信号。
3.新的指令微调任务 (Temporal Grounded Caption):
设计了一种名为"时间定位字幕"的新任务。该任务要求模型不仅要预测事件发生的时间段,还要同时生成该时间段内详细的视频内容描述。这种设计强制模型将其生成的文本"锚定"在具体的视觉片段上,从而显著减少了由大模型自身推理产生的幻觉。
- 方法 Method
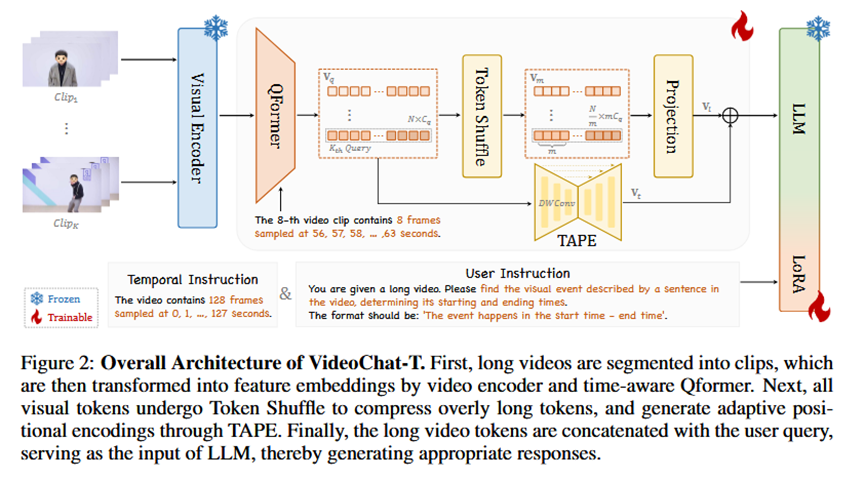
Pipeline 总览
整个流程基于 VideoChat-T 架构,分为三个阶段(见原文图2):
1.输入处理:将一个长视频均匀分割成多个视频片段(clips)。
2.特征提取与压缩 :每个片段通过视频编码器(Video Encoder)和 Q-Former 提取成视觉令牌序列。然后,所有片段的令牌序列被送入 Token Shuffle 模块进行压缩,以减少令牌数量。
3.时间编码与生成 :压缩后的令牌序列经过 TAPE 模块,被注入自适应的时间位置信息。最后,携带了时间信息的视觉令牌序列与用户的文本问题(query)拼接在一起,共同作为 LLM 的输入,LLM 最终生成答案。
各部分细节
1.VideoChat-T 架构:
骨干网络 (Backbone Design):
输入:长视频。
处理:视频被均匀采样成 KxT 帧,分为 K 个片段,每个片段 T 帧。使用视频编码器和 Q-Former 将每个片段编码为 N 个视觉令牌。
输出:一个形状为 LxCq 的视觉令牌序列 Vq,其中 L=KxN 是令牌总数。
VL-Connector: Token Shuffle:
输入:长视频的视觉令牌序列 Vq。
处理:将 m 个相邻的令牌在通道维度上拼接(concatenate),然后通过一个线性层投影回目标维度。这种方法的初始化很巧妙,等效于平均池化,但为后续微调提供了更大的灵活性。
输出:压缩后的视觉令牌序列 Vl。
Temporal Adaptive Position Encoding (TAPE):
输入:经过 Token Shuffle 压缩后的视觉令牌 Vl。
处理:这是一个独立的适配器模块。它使用一个类似 U-Net 的一维卷积结构,对令牌序列进行降采样和上采样,同时在最深层通过卷积编码相对位置信息。通过残差连接将这些时间特征添加到原始的视觉令牌上。
输出:带有时间位置信息的视觉特征 Vt。
2.TimePro 数据集:
这是一个为了"有地放矢"地进行微调而构建的数据集。它整合了 15 个现有数据集,并创建了 2 个新数据集,覆盖了 9 类与时间高度相关的任务,如:时间视频定位、密集视频字幕、视频摘要、步骤定位、高光检测等。
3.Temporal Grounded Caption 任务:
输入:一个简短的场景标题作为问题(e.g., "卡车卸货")。
输出:一个结构化的文本,包含两部分:1)该场景出现的精确开始和结束时间(e.g., "happens between 15.2 - 20.8 seconds");2)对该场景的详细描述(e.g., "一辆蓝色的卡车停在路边,工人正在从车上卸下箱子...")。
- 实验 Experimental Results
实验数据集:
时间定位任务: Charades-STA, QVHighlights。
长视频问答任务: Egoschema, VideoMME。
短视频(通用)问答任务: MVBench。
实验结论:
1.时间定位能力实验 (表1): VideoChat-T 在零样本(zero-shot)时间定位任务上,性能远超之前的 MLLMs(如 TimeChat)。例如,在 Charades-STA (R@1, IoU=0.5) 指标上,VideoChat-T 达到 48.7%,而 TimeChat 只有 32.2%。
2.通用视频 QA 能力实验 (表2): VideoChat-T 在长视频 QA 任务上取得了显著提升 (Egoschema 提升 5.6%, VideoMME 提升 6.8%)。在短视频 QA 任务 (MVBench) 上,性能仅有 0.5% 的轻微下降,这证明 TimeSuite 在引入新能力的同时,很好地保持了原有的通用能力。
3.消融实验 (表3, 4, 5):
TAPE 的作用: 去掉 TAPE 会导致所有任务性能下降,证明了它对时间感知的重要性。
Token Shuffle 的有效性: Token Shuffle 显著优于传统的池化和聚类方法。
TimePro 数据集各部分的作用: 逐步增加 TimePro 中的不同任务数据,模型的长视频理解和时间定位能力都随之稳定提升,证明了高质量、多样化的时间中心数据是有效的。
- 总结 Conclusion
论文的核心信息是,通过将时间定位作为一种"接地"(grounding) 的监督信号,可以显著改善 MLLMs 对长视频的理解能力并减少幻觉。论文提出的 TimeSuite 工具集(包括高效架构 VideoChat-T、高质量数据集 TimePro 和创新的微调任务),为如何将短视频 MLLMs 有效适配于长视频任务提供了一套成功且可行的方案。