目录:
文本张量表示方法
-
one-hot编码
-
Word2vec
-
Word Embedding
文本张量表示:将一段文本使用张量进行表示这个过程就是文本张量表示。
1.文本--->张量
文本-->词-->词向量-->词向量矩阵-->张量
- one-hot属于稀疏向量表示。
Word2vec和Word Embedding都是稠密向量表示。
一、one-hot编码
也叫 独热编码 或 0-1编码
- 优势:操作简单
- 劣势:高维稀疏
- 高维:每个向量长度过大占内存(长度=不同词汇的总数)
- 稀疏:割裂了词与词之间的联系
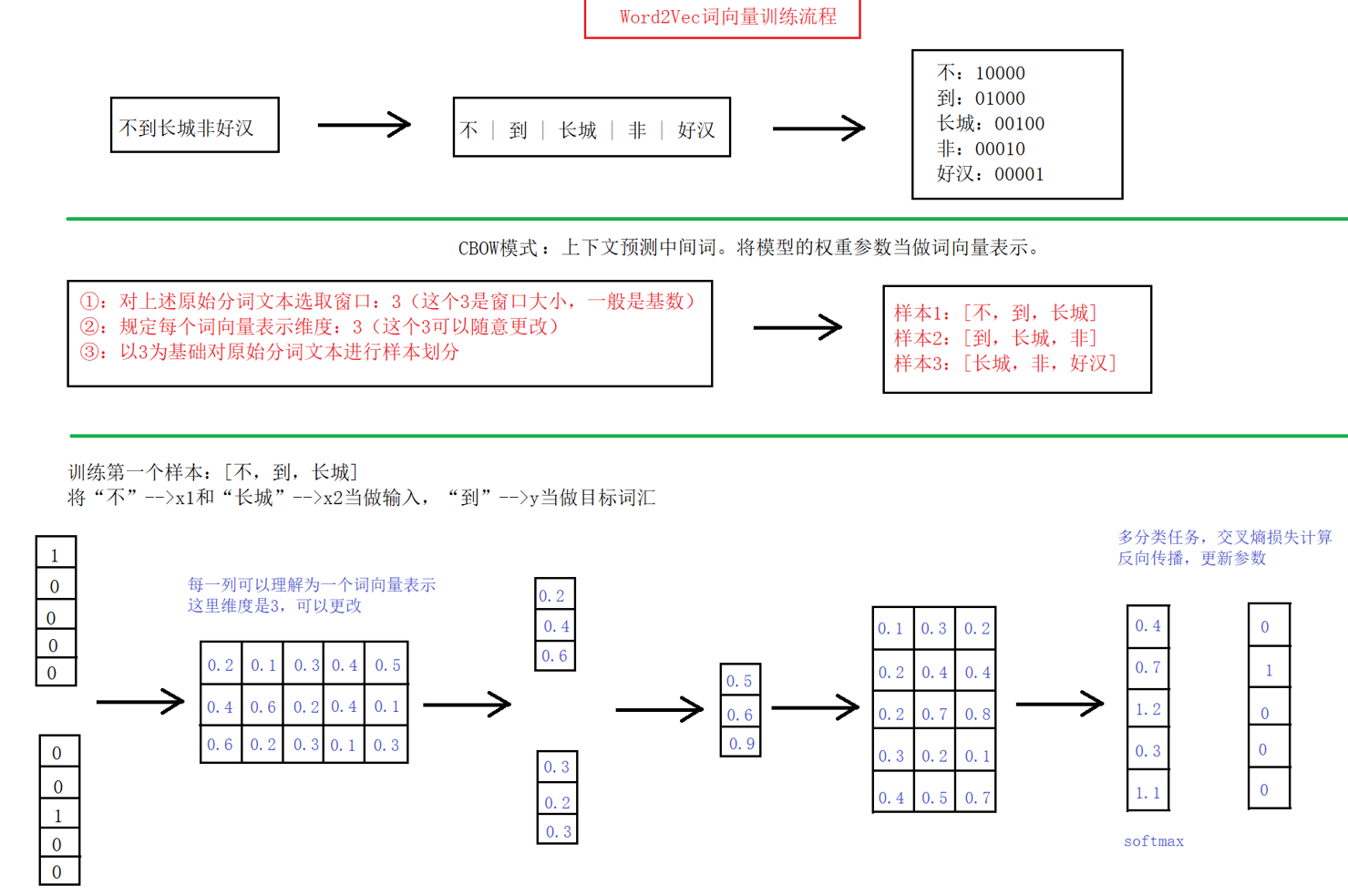
二、Word2vec
含义:将词表示成词向量的无监督方法
原理:构建神经网络模型,将网络参数作为词向量表示
模式:CBOW、skipgram。
CBOW模式 思路:
- 给定一段用于训练的文本语料
- 再选定某段长度(窗口)作为研究对象
- 使用上下文词汇预测目标词汇
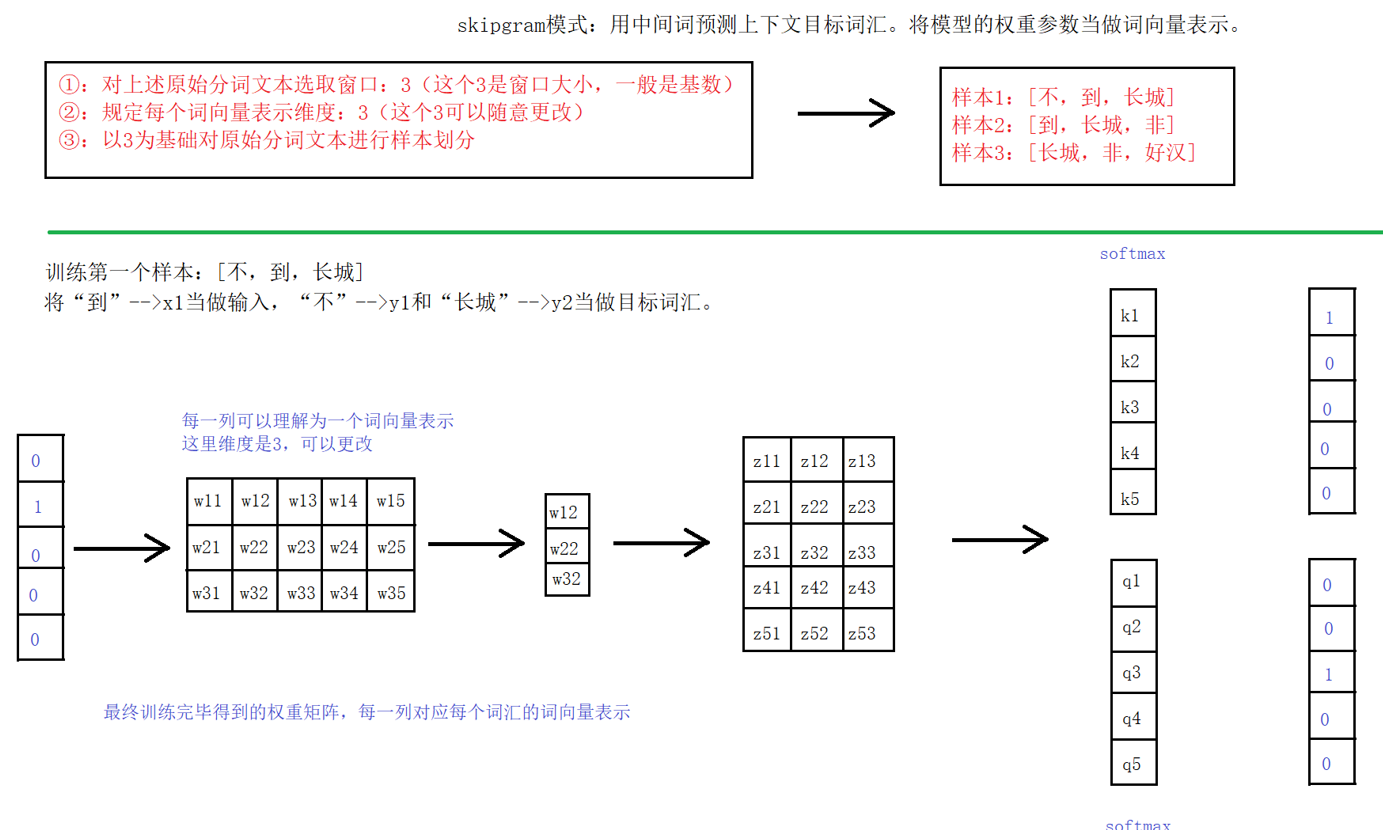
skipgram模式 思路:
- 给定一段用于训练的文本语料
- 再选定某段长度(窗口)作为研究对象
- 使用目标词汇预测上下文词汇
实现API
安装:fastext词向量训练工具包
pip install fasttext-wheel==0.9.2 -ifasttext两大作用:文本分类、训练词向量。
API:
# 训练词向量
model=fasttext.train_unsupervised()
# 加载模型
model.save_model()
# 保存模型
fasttext.load_model()
# 获取词向量
model.get_word_vector()
# 获取邻近词
model.get_nearest_neighbors()三、Word Embedding
广义:密集词向量的表示方法,如word2vec
狭义:在神经网络中嵌入nn.embedding层,nn.Embedding()
狭义Word Embedding就是指词嵌入层nn.Embedding()
Word Embedding与Word2vec区别
Word2vec
- 静态词向量:模型训练好后,使用模型输入词汇加载词向量,参数固定
- 实现任务需分两步
- 训练词向量
- 基于训练好的词向量完成任务
Word Embedding
- 动态词向量:词嵌入层作为整体神经网络的一部分,权重参数会参与更新,是动态的
- 实现任务一步到位