
上海交通大学推出单图像生成3D场景方法SceneGen,它以单个场景图像与目标资源蒙版为输入,在一次前馈中就能同时合成多个具备结构、纹理及相对空间位置的 3D 资源。通过结合专用视觉和几何编码器提取资源与场景级特征,再经特征聚合模块有效融合。精心设计使其可推广至多图像输入,提升生成质量。经定量和定性评估,SceneGen 能生成物理合理且相互一致的 3D 资源,性能远超前代。
相关链接
方法概述
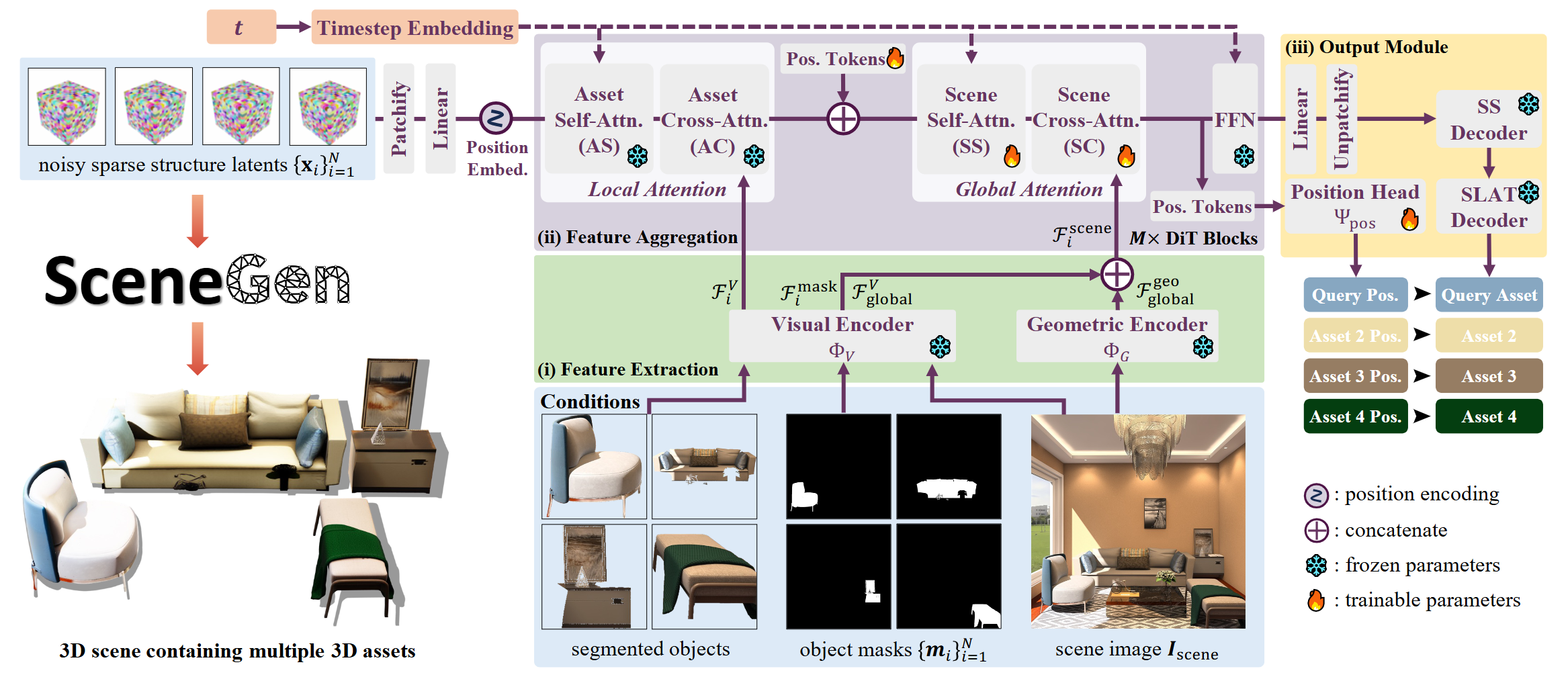
SceneGen将包含多个对象及其相应分割蒙版的单幅场景图像作为输入。预训练的局部注意力模块首先细化每个素材的纹理。然后,我们引入的全局注意力模块整合了由专用视觉和几何编码器提取的素材级和场景级特征。最后,两个现成的结构解码器和我们的位置头将这些潜在特征解码为多个具有几何形状、纹理和相对空间位置的 3D 素材。
实验结果
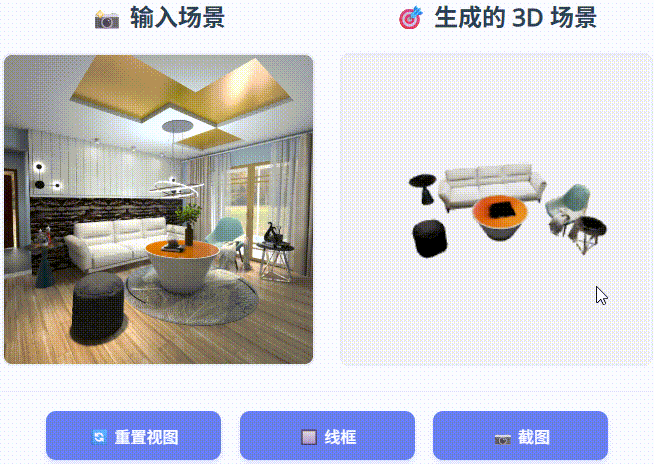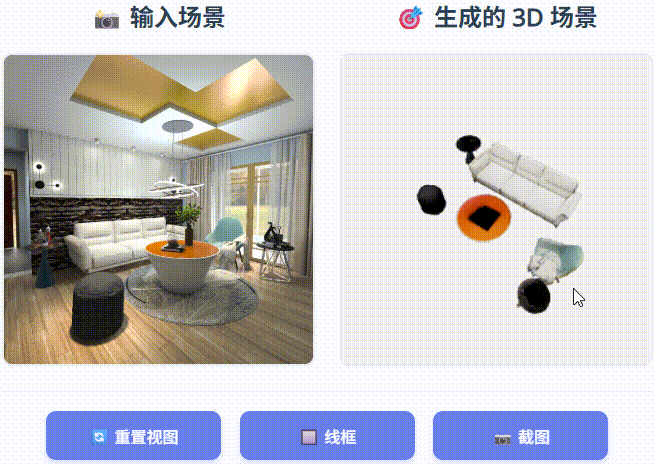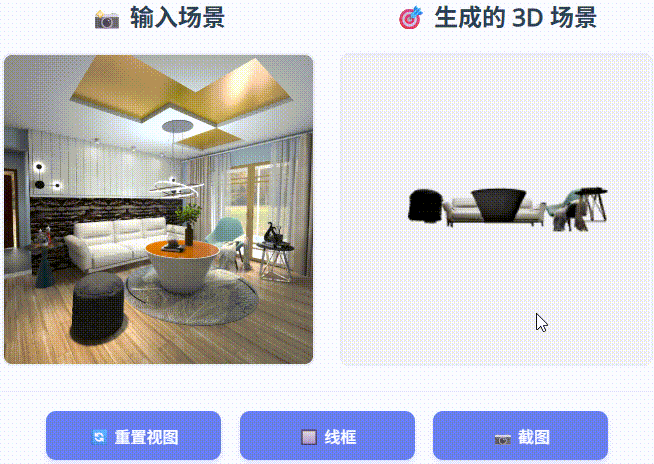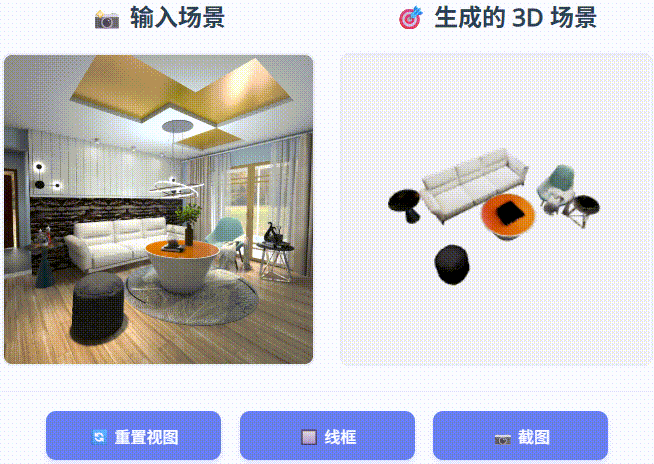
SceneGen 能够生成具有完整结构、详细纹理和精确空间关系的物理上合理的 3D 场景,在合成和真实世界数据集的几何精度和视觉质量方面均表现出优于以前的方法的性能。
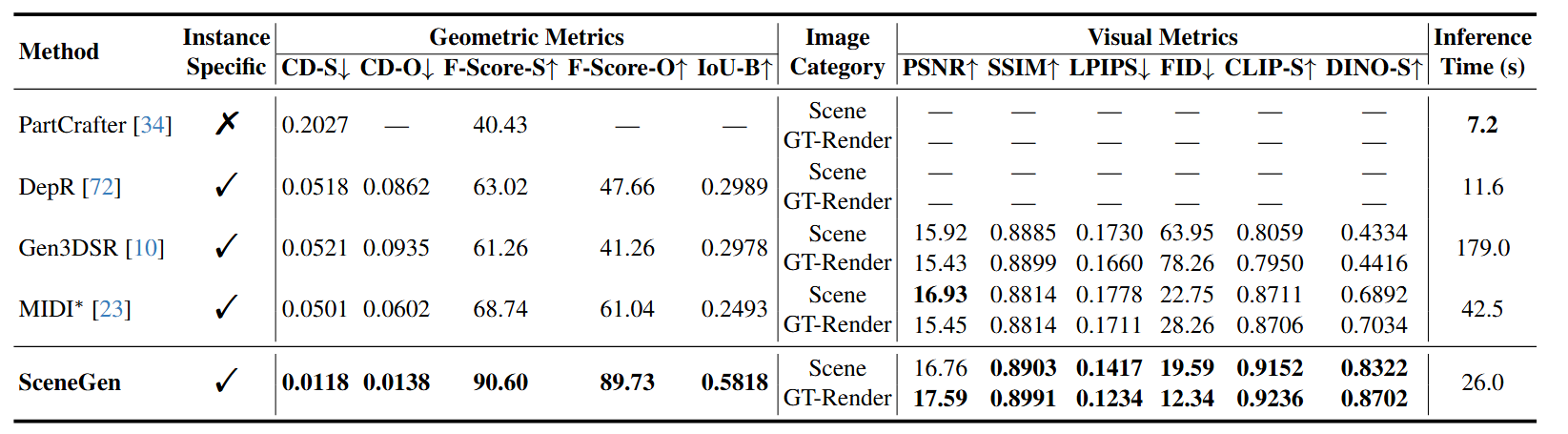
在 3D-FUTURE 测试集上 进行定量比较。我们使用场景级倒角距离 (CD-S) 和 F 值 (F-Score-S)、对象级倒角距离 (CD-O) 和 F 值 (F-Score-O) 以及对象边界框的体积 IoU (IoU-B) 来评估几何结构。对于视觉质量,CLIP-S 和 DINO-S 分别代表 CLIP 和 DINOv2 图像到图像的相似度。我们报告了在单个 A100 GPU 上生成单个资源的时间成本,*表示采用 MV-Adapter 进行纹理渲染。
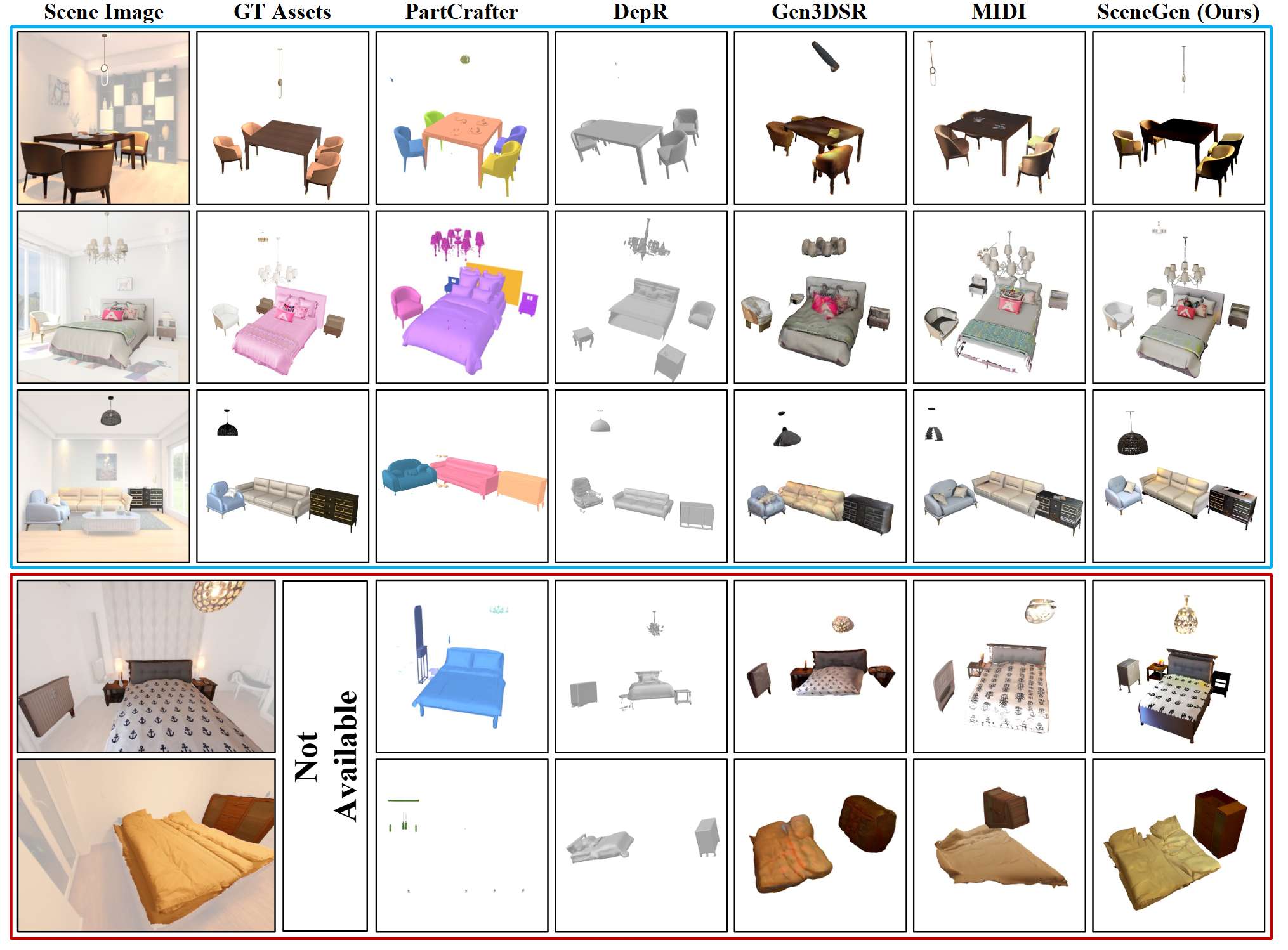
在 3D FUTURE 测试集和 ScanNet++ 上进行定性比较。 我们提出的 SceneGen 能够生成物理上可信的 3D 场景,具有完整的结构、详细的纹理和精确的空间关系,在合成和真实数据集的几何精度和视觉质量方面均表现出优于先前方法的性能。
结论
SceneGen 以单个场景图像和目标资源蒙版作为输入,在一次前馈过程中同时合成多个具有结构、纹理以及相对空间位置的 3D 资源。 具体来说,论文结合了专用的视觉和几何编码器来提取资源级和场景级特征,并与我们引入的特征聚合模块进行了有效融合。值得注意的是,通过设计,SceneGen 甚至可以直接推广到多图像输入,并实现更高的生成质量。定量和定性评估表明,SceneGen 可以生成物理上合理且相互一致的 3D 资源,性能显著优于之前的版本。