摘要
原生3D生成模型的最新进展加速了游戏、影视和设计领域的资产创建。然而,现有方法主要依赖图像或文本条件输入,缺乏细粒度的跨模态控制,制约了可控性和实际应用。为此,我们基于Hunyuan3D 2.1提出了Hunyuan3D-Omni------一个支持细粒度控制的统一3D资产生成框架。除图像外,该系统可接受点云、体素、边界框和骨骼姿态先验作为条件信号,实现对几何结构、拓扑形态和姿态的精确控制。我们采用单一跨模态架构统一处理所有信号,而非为每种模态设计独立模块。训练过程中采用渐进式难度感知采样策略:每个样本仅选择一种控制模态,并倾向于采样更难处理的信号(如骨骼姿态),同时降低简单信号(如点云)的权重,从而促进鲁棒的多模态融合与缺失输入的优雅处理。实验表明,这些新增控制方式能提升生成精度,实现几何感知变换,并增强生产流程的健壮性。

Hunyuan3D-Omni
混元3D-Omni是一个可控生成3D资产的统一框架,继承了混元3D 2.1的结构。相比之下,混元3D-Omni构建了一个统一控制编码器来引入额外控制信号,包括点云、体素、骨骼和边界框。
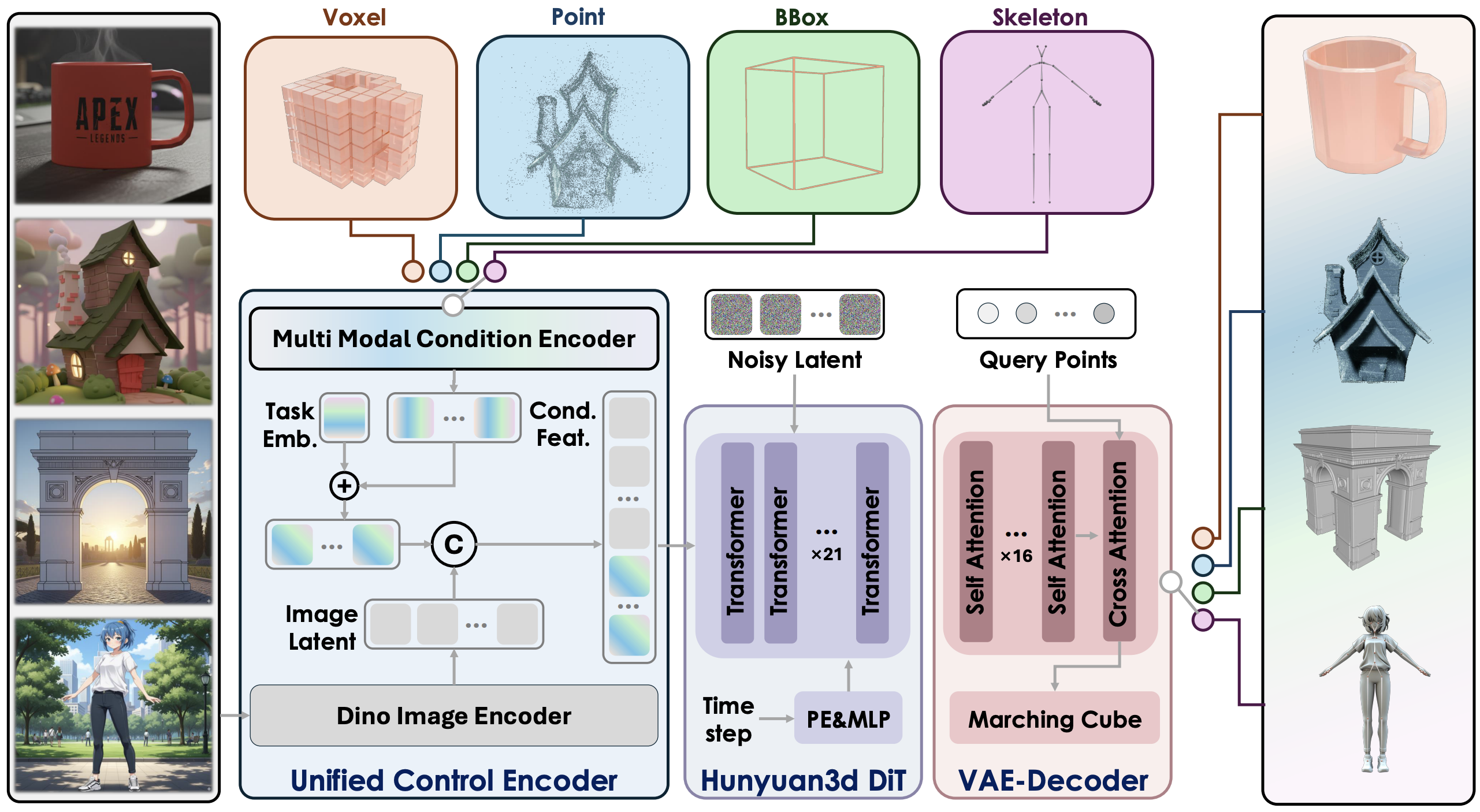
多模态条件控制
- 边界框控制:生成受3D边界框约束的3D模型
- 姿态控制:创建具有特定骨骼姿态的3D人体模型
- 点云控制:根据输入点云生成3D模型
- 体素控制:从体素表示生成3D模型
🎁 模型库
生成需要10GB显存。
| 模型名称 | 描述 | 发布日期 | 大小 | Huggingface链接 |
|---|---|---|---|---|
| Hunyuan3D-Omni | 图像到形状模型的多模态控制 | 2025-09-25 | 3.3B | Download |
安装
要求
我们的模型在Python 3.10环境下进行了测试。
bash
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt用法
推理
多模态推理
bash
python inference.py --control_type <control_type> [--use_ema] [--flashvdm]control_type 参数有以下四种可选模式:
point:采用点控制模式进行推理。
voxel:采用体素控制模式进行推理。
bbox:采用边界框控制模式进行推理。
pose:采用姿态控制模式进行推理。
--use_ema 参数用于启用指数移动平均(EMA)模型以获取更稳定的推理结果。
--flashvdm 参数用于开启FlashVDM优化以提升推理速度。
请根据需求选择合适的control_type。例如若需使用point控制模式,可运行:
bash
python inference.py --control_type point
python inference.py --control_type point --use_ema
python inference.py --control_type point --flashvdm该模型在论文《Hunyuan3D-Omni:可控3D资产生成的统一框架》(https://huggingface.co/papers/2509.21245)中提出。
致谢
我们衷心感谢以下开源项目的贡献者:
TripoSG、Trellis、DINOv2、Stable Diffusion、FLUX、diffusers、HuggingFace、CraftsMan3D、Michelangelo、Hunyuan-DiT、HunyuanVideo、HunyuanWorld-1.0以及HunyuanWorld-Voyager项目组,感谢他们在开放研究和探索方面做出的贡献。