一、逻辑回归简介
学习目标:
1.知道逻辑回归的应用场景
2.复习逻辑回归应用到的数学知识
应用场景
 逻辑回归是解决二分类问题的利器
逻辑回归是解决二分类问题的利器
数学知识
sigmoid函数
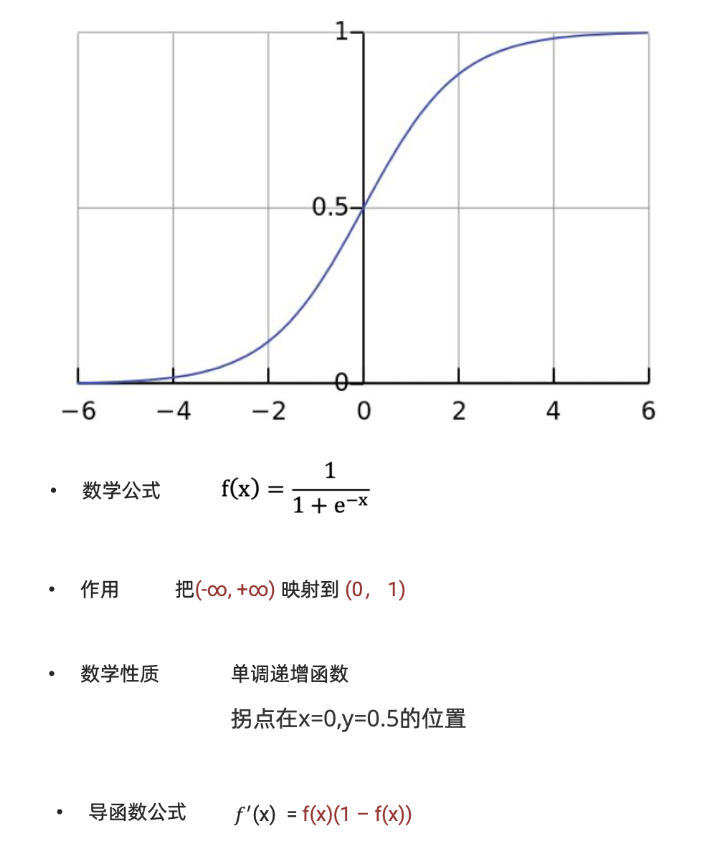
概率

极大似然估计
核心思想:
设模型中含有待估参数w,可以取很多值。已经知道了样本观测值,从w的一切可能值中(选出一个使该观察值出现的概率为最大的值,作为w参数的估计值,这就是极大似然估计。(顾名思义:就是看上去那个是最大可能的意思)
举个例子:
假设有一枚不均匀的硬币,出现正面的概率和反面的概率是不同的。假定出现正面的概率为𝜃, 抛了6次得到如下现象 D = {正面,反面,反面,正面,正面,正面}。每次投掷事件都是相互独立的。 则根据产生的现象D,来估计参数𝜃是多少?
P(D|𝜃) = P {正面,反面,反面,正面,正面,正面}
= P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃)
=𝜃 *(1-𝜃)*(1-𝜃)𝜃*𝜃*𝜃 = 𝜃4(1 − 𝜃)问题转化为:求此函数的极大值时,估计𝜃为多少

对数函数

二、逻辑回归原理
学习目标
1.理解逻辑回归算法的原理
2.知道逻辑回归的损失函数
原理
逻辑回归概念 Logistic Regression
• 一种分类模型,把线性回归的输出,作为逻辑回归的输入。
• 输出是(0, 1)之间的值
• 基本思想
- 利用线性模型 f(x) = wx + b 根据特征的重要性计算出一个值
- 再使用 sigmoid 函数将 f(x) 的输出值映射为概率值
- 设置阈值(eg:0.5),输出概率值大于 0.5,则将未知样本输出为 1 类
- 否则输出为 0 类
3.逻辑回归的假设函数
h(w) = sigmoid(wx + b )
线性回归的输出,作为逻辑回归的输入
在逻辑回归中,当预测结果不对的时候,我们该怎么衡量其损失呢?
我们来看下图(下图中,设置阈值为0.6),
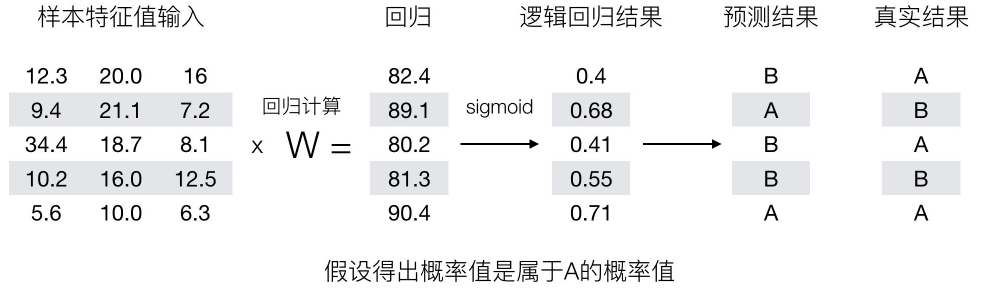
那么如何去衡量逻辑回归的预测结果与真实结果的差异?
损失函数



三、逻辑回归API
学习目标:
1.知道逻辑回归的API
2.动手实现癌症分类案例
API介绍
python
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C = 1.0)solver 损失函数优化方法:
训练速度:liblinear 对小数据集场景训练速度更快,sag 和 saga 对大数据集更快一些。 2 正则化:
- newton-cg、lbfgs、sag、saga 支持 L2 正则化或者没有正则化
- 2liblinear 和 saga 支持 L1 正则化
penalty:正则化的种类,l1 或者 l2
C:正则化力度
默认将类别数量少的当做正例
【实践】癌症分类案例
- 数据介绍
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用"?"标出。
(3)2表示良性,4表示恶性
数据描述
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤
相关的医学特征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用"?"标出。
-
案例分析
1.获取数据
2.基本数据处理
2.1 缺失值处理
2.2 确定特征值,目标值
2.3 分割数据
3.特征工程(标准化)
4.机器学习(逻辑回归)
5.模型评估 -
代码实现
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.metrics import accuracy_score # 评估
if __name__ == '__main__':
# 1- 数据准备
df = pd.read_csv("./data/breast-cancer-wisconsin.csv",encoding="UTF-8")
# df.info()
# 2- 数据基本处理
# 2.1- 将问号替换为NaN值
# inplace=True:直接对原始数据内容修改。默认是False
df.replace("?",np.NAN,inplace=True)
# df.info()
# 2.2- 将包含NaN值的样本数据删除
df.dropna(inplace=True)
# df.info()
# 2.3- 将整个数据分为特征数据和目标数据
x = df.iloc[:,1:-1] # 删除前后两列
y = df.iloc[:,-1]
# 3- 特征工程,标准化处理
# 3.1- 对样本数据进行划分,为训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=56)
# 3.2- 标准化处理
# 3.1- 创建标准化的实例对象
transformer = StandardScaler()
# 3.2- 对训练集数据进行先学习规则(均值、标准差),然后再对训练集进行处理
new_x_train = transformer.fit_transform(x_train)
# 4- 创建机器学习实例对象
estimator = LogisticRegression()
# 5- 模型训练:对模型使用训练集数据进行训练
estimator.fit(new_x_train, y_train)
# 6- 模型评估
# 6.1- 对测试集数据直接进行内容转换
new_x_test = transformer.transform(x_test)
# 6.2- 对测试集数据进行预测
y_predict = estimator.predict(new_x_test)
# 6.3- 评估
print("逻辑回归的算法预测评分:", accuracy_score(y_test, y_predict))增加交叉验证和网格搜索的功能
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.metrics import accuracy_score # 评估
from sklearn.model_selection import GridSearchCV # 交叉验证和网格搜索
if __name__ == '__main__':
# 1- 数据准备
df = pd.read_csv("./data/breast-cancer-wisconsin.csv",encoding="UTF-8")
# df.info()
# 2- 数据基本处理
# 2.1- 将问号替换为NaN值
# inplace=True:直接对原始数据内容修改。默认是False
df.replace("?",np.NAN,inplace=True)
# df.info()
# 2.2- 将包含NaN值的样本数据删除
df.dropna(inplace=True)
# df.info()
# 2.3- 将整个数据分为特征数据和目标数据
x = df.iloc[:,1:-1] # 删除前后两列
y = df.iloc[:,-1]
# 3- 特征工程,标准化处理
# 3.1- 对样本数据进行划分,为训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=56)
# 3.2- 标准化处理
# 3.1- 创建标准化的实例对象
transformer = StandardScaler()
# 3.2- 对训练集数据进行先学习规则(均值、标准差),然后再对训练集进行处理
new_x_train = transformer.fit_transform(x_train)
# 4- 创建机器学习实例对象:交叉验证和网格搜索
# 4.1- 实例化对象
estimator = LogisticRegression()
# 4.2- 创建交叉验证和网格搜索
"""
交叉验证和网格搜索的回顾
1- 交叉验证:数据集划分的一种方式
2- 网格搜索:从众多的参数中,找出最优的超参数
3- 参数解释
3.1- estimator:原始的算法模型
3.2- param_grid:超参数的选择范围
3.3- cv:交叉验证中将数据分为几份/几折。将样本数据中的训练集分为小份的训练集和验证集
"""
param_grid = {
"solver":["liblinear", "sag", "saga"],
"max_iter":[100,150,200]
}
super_estimator = GridSearchCV(estimator,param_grid=param_grid,cv=4)
# 4.3- 带入数据进行训练
super_estimator.fit(new_x_train,y_train)
# 5- 输出交叉验证和网格搜索后的结果
print("最优的超参数:",super_estimator.best_params_)
# 交叉验证和网格搜索后的super_estimator可以直接拿着用,也可以自己再重新创建一个
estimator = LogisticRegression(max_iter=100, solver='liblinear')
estimator.fit(new_x_train,y_train)
# 6- 模型评估
# 6.1- 对测试集数据直接进行内容转换
new_x_test = transformer.transform(x_test)
# 6.2- 对测试集数据进行预测
# y_predict = super_estimator.predict(new_x_test)
y_predict = estimator.predict(new_x_test)
# 6.3- 评估
print("逻辑回归的算法预测评分:", accuracy_score(y_test, y_predict))四、分类评估方法
学习目标:
1.理解混淆矩阵的构建方法
2.掌握精确率,召回率和F1score的计算方法
3.知道ROC曲线和AUC指标
混淆矩阵
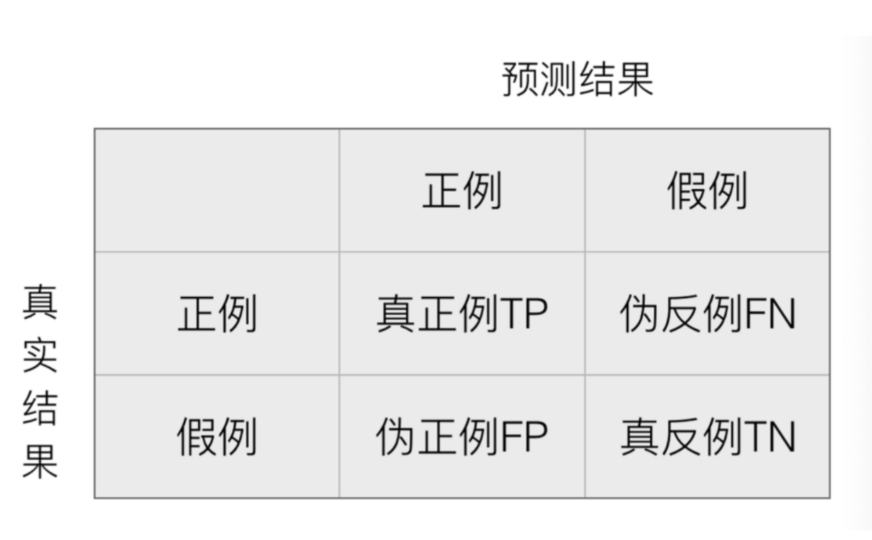
混淆矩阵作用在测试集样本集中:
- 真实值是 正例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做真正例(TP,True Positive)
- 真实值是 正例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做伪反例(FN,False Negative)
- 真实值是 假例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做伪正例(FP,False Positive)
- 真实值是 假例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做真反例(TN,True Negative)
True Positive :表示样本真实的类别
Positive :表示样本被预测为的类别
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 伪正例 FP 为:0
- 真反例 TN:4
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 伪正例 FP 为:3
- 真反例 TN:1
我们会发现:TP+FN+FP+TN = 总样本数量
Precision(精确率)
精确率也叫做查准率,指的是对正例样本的预测准确率。比如:我们把恶性肿瘤当做正例样本,则我们就需要知道模型对恶性肿瘤的预测准确率。
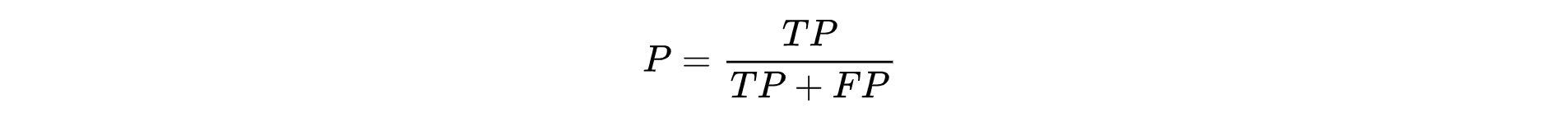
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
Recall(召回率)
召回率也叫做查全率,指的是预测为真正例样本占所有真实正例样本的比重。例如:我们把恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。

例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
F1-score
如果我们对模型的精度、召回率都有要求,希望知道模型在这两个评估方向的综合预测能力如何?则可以使用 F1-score 指标。
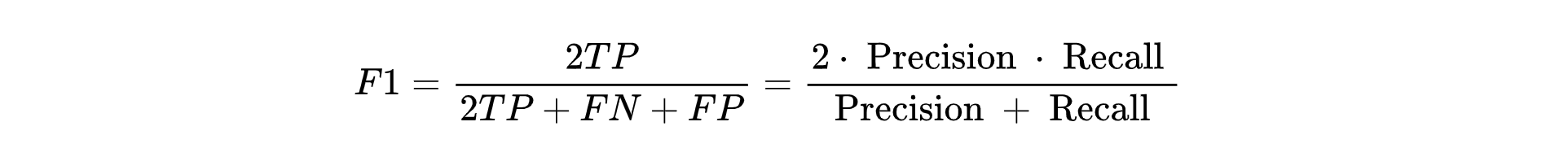
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
- F1-score:(2*3)/(2*3+3+0)=67%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
- F1-score:(2*6)/(2*6+0+3)=80%
python
"""
只要是和模型评估相关的功能,全在sklearn.metrics里面
confusion_matrix:混淆矩阵
precision_score:精确率
recall_score:召回率
f1_score:F1得分
"""
import pandas as pd
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score
if __name__ == '__main__':
# 1- 准备数据
# 1.1- 构建【真实】样本数据,10条样本,6个恶性样本,4个良性样本
y_true = ["恶性","恶性","恶性","恶性","恶性","恶性","良性","良性","良性","良性"]
# 1.2- 构建【模型A预测】样本数据,10条样本,预测对了3个恶性样本,4个良性样本
# 其中6个恶性样本中有3个样本没有预测正确,也就是预测结果是【良性】
A_y_predict = ["恶性", "恶性", "恶性", "良性", "良性", "良性", "良性", "良性", "良性", "良性"]
# 1.3- 构建【模型B预测】样本数据,10条样本,预测对了6个恶性样本,1个良性样本
# 其中4个良性样本中有3个样本没有预测正确,也就是预测结果是【恶性】
B_y_predict = ["恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "恶性", "良性"]
# 2- 分别构建模型A、模型B的混淆矩阵
# 2.1- 构建模型A的混淆矩阵
# labels:混淆矩阵中的二分类的类别是哪些
A_cm = confusion_matrix(y_true, A_y_predict, labels=["恶性","良性"])
# 2.2- 构建模型B的混淆矩阵
B_cm = confusion_matrix(y_true, B_y_predict, labels=["恶性", "良性"])
# 2.3- 将混淆矩阵变成DataFrame输出展示
A_df = pd.DataFrame(data=A_cm,index=["正例(恶性)","假例(良性)"], columns=["正例(恶性)","假例(良性)"])
print(A_df)
print("-" * 50)
B_df = pd.DataFrame(data=B_cm, index=["正例(恶性)", "假例(良性)"], columns=["正例(恶性)","假例(良性)"])
print(B_df)
print("-" * 50)
# 3- 对混淆矩阵进行计算,得到精确率、召回率、F1
# pos_label参数表示数据中正例的分类类别
print("模型A的精确率:",precision_score(y_true, A_y_predict, pos_label="恶性"))
print("模型A的召回率:",recall_score(y_true, A_y_predict, pos_label="恶性"))
print("模型A的F1:",f1_score(y_true, A_y_predict, pos_label="恶性"))
print("-"*50)
print("模型B的精确率:", precision_score(y_true, B_y_predict, pos_label="恶性"))
print("模型B的召回率:", recall_score(y_true, B_y_predict, pos_label="恶性"))
print("模型B的F1:", f1_score(y_true, B_y_predict, pos_label="恶性"))ROC曲线和AUC指标
ROC 曲线
ROC 曲线:我们分别考虑正负样本的情况:
- 正样本中被预测为正样本的概率,即:TPR (True Positive Rate)
- 负样本中被预测为正样本的概率,即:FPR (False Positive Rate)
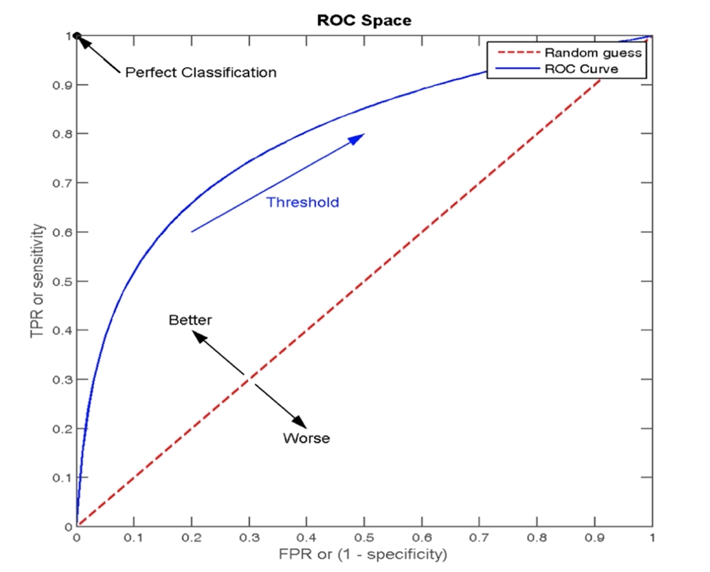
ROC 曲线图像中,4 个特殊点的含义:
- (0, 0) 表示所有的正样本都预测为错误,所有的负样本都预测正确
- (1, 0) 表示所有的正样本都预测错误,所有的负样本都预测错误
- (1, 1) 表示所有的正样本都预测正确,所有的负样本都预测错误
- (0, 1) 表示所有的正样本都预测正确,所有的负样本都预测正确
绘制 ROC 曲线
假设:在网页某个位置有一个广告图片或者文字,该广告共被展示了 6 次,有 2 次被浏览者点击了。每次点击的概率如下:
| 样本 | 是否被点击 | 预测点击概率 |
|---|---|---|
| 1 | 1 | 0.9 |
| 2 | 0 | 0.7 |
| 3 | 1 | 0.8 |
| 4 | 0 | 0.6 |
| 5 | 0 | 0.5 |
| 6 | 0 | 0.4 |
根据预测点击概率排序之后:
| 样本 | 是否被点击 | 预测点击概率 |
|---|---|---|
| 1 | 1 | 0.9 |
| 3 | 1 | 0.8 |
| 2 | 0 | 0.7 |
| 4 | 0 | 0.6 |
| 5 | 0 | 0.5 |
| 6 | 0 | 0.4 |
绘制 ROC 曲线:
阈值:0.9
- 原本为正例的 1、3 号的样本中 3 号样本被分类错误,则 TPR = 1/2 = 0.5
- 原本为负例的 2、4、5、6 号样本没有一个被分为正例,则 FPR = 0
阈值:0.8
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负例的 2、4、5、6 号样本没有一个被分为正例,则 FPR = 0
阈值:0.7
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2 号样本被分类错误,则 FPR = 1/4 = 0.25
阈值:0.6
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2、4 号样本被分类错误,则 FPR = 2/4 = 0.5
阈值:0.5
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本中 2、4、5 号样本被分类错误,则 FPR = 3/4 = 0.75
阈值 0.4
- 原本为正例的 1、3 号样本被分类正确,则 TPR = 2/2 = 1
- 原本为负类的 2、4、5、6 号样本全部被分类错误,则 FPR = 4/4 = 1
(0, 0.5)、(0, 1)、(0.25, 1)、(0.5, 1)、(0.75, 1)、(1, 1)
AUC 值
- 我们发现:图像越靠近 (0,1) 点则模型对正负样本的辨别能力就越强
- 我们发现:图像越靠近 (0, 1) 点则 ROC 曲线下面的面积就会越大
- AUC 是 ROC 曲线下面的面积,该值越大,则模型的辨别能力就越强
- AUC 范围在 0, 1 之间
- 当 AUC= 1 时,该模型被认为是完美的分类器,但是几乎不存在完美分类器
AUC 值主要评估模型对正例样本、负例样本的辨别能力.
分类评估报告api
python
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
'''
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
'''AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
计算ROC曲线面积,即AUC值
y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
y_score:预测得分,可以是正例的估计概率、置信值或者分类器方法的返回值癌症分类结果评估
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # 逻辑回归
# roc_curve曲线,roc_auc_score面积
from sklearn.metrics import accuracy_score,roc_curve,roc_auc_score # 评估
import matplotlib.pyplot as plt
if __name__ == '__main__':
# 1- 数据准备
df = pd.read_csv("./data/breast-cancer-wisconsin.csv",encoding="UTF-8")
# df.info()
# 2- 数据基本处理
# 2.1- 将问号替换为NaN值
# inplace=True:直接对原始数据内容修改。默认是False
df.replace("?",np.NAN,inplace=True)
# df.info()
# 2.2- 将包含NaN值的样本数据删除
df.dropna(inplace=True)
# df.info()
# 2.3- 将整个数据分为特征数据和目标数据
x = df.iloc[:,1:-1] # 删除前后两列
y = df.iloc[:,-1]
# 将目标值有2,4变成0,1
y = y.apply(lambda x:0 if x==2 else 1)
# 3- 特征工程,标准化处理
# 3.1- 对样本数据进行划分,为训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=56)
# 3.2- 标准化处理
# 3.1- 创建标准化的实例对象
transformer = StandardScaler()
# 3.2- 对训练集数据进行先学习规则(均值、标准差),然后再对训练集进行处理
new_x_train = transformer.fit_transform(x_train)
# 4- 创建机器学习实例对象
estimator = LogisticRegression()
# 5- 模型训练:对模型使用训练集数据进行训练
estimator.fit(new_x_train, y_train)
# 6- 模型评估
# 6.1- 对测试集数据直接进行内容转换
new_x_test = transformer.transform(x_test)
# 6.2- 对测试集数据进行预测
y_predict = estimator.predict(new_x_test)
# predict_proba得到分类的概率值
y_predict_proba = estimator.predict_proba(new_x_test)
print(y_predict_proba)
# 6.3- 评估
print("逻辑回归的算法预测评分:", accuracy_score(y_test, y_predict))
# 7- 绘制roc曲线
fpr,tpr,thresholds = roc_curve(y_test, y_predict_proba[:,1])
print(f"fpr={fpr},tpr={tpr},thresholds={thresholds}")
plt.plot(fpr,tpr,c="r")
plt.xlabel("fpr")
plt.ylabel("tpr")
plt.show()
# 8- 得到auc面积值
print("auc面积",roc_auc_score(y_test, y_predict_proba[:, 1]))五、电信客户流失预测
学习目标:
1.了解案例的背景信息
2.知道案例的处理流程
3.动手实现电信客户流失案例的代码
数据集介绍
- 流失用户指的使用过产品因为某些原因不再使用该产品。随着产品的更新迭代,都会存在一定的流失情况,这时正常现象。流失用户的比例和变化趋势能够反映该产品当前是否存在问题以及未来的发展趋势。
- 当用户群体庞大时,有限的人力和精力不能为每个用户都投入大量的时间。如果公司可以预测哪些用户可能提前流失,这样就能将主要精力聚焦于这些用户,实施有效的用户挽留策略,提高用户粘性。
- 本项目旨在通过分析特征属性确定用户流失的原因,以及哪些因素可能导致用户流失。建立预测模型来判断用户是否流失,并提出用户流失预警策略。
- 具体数据说明如下:数据集中总计7043条数据,21个特征字段,最终分类特征为Churn:用户是否流失,具体内容如下所示:
customerID:用户ID
gender:性别
SeniorCitizen:是否是老人
Partner:是否有伴侣
Dependents:是否有需要抚养的孩子
tenure:任职
PhoneService:是否办理电话服务
MultipleLines:是否开通了多条线路
InternetService:是否开通网络服务和开通的服务类型(光纤、电话拨号)
TechSupport:是否办理技术支持服务
OnlineBackup:是否办理在线备份服务
OnlineSecurity:是否办理在线安全服务
DeviceProtection:是否办理设备保护服务
StreamingTV:是否办理电视服务
StreamingMovies:是否办理电影服务
Contract:签订合约的时长
PaperlessBilling:是否申请了无纸化账单
PaymentMethod:付款方式(电子支票、邮寄支票、银行自动转账、信用卡自动转账)
MonthlyCharges:月消费
TotalCharges:总消费
Churn:用户是否流失
处理流程
1、数据基本处理
查看数据的基本信息
对类别数据数据进行one-hot编码处理
查看标签分布情况2、特征筛选
分析哪些特征对标签值影响大
对标签进行分组统计,对比0/1标签分组后的均值等
初步筛选出对标签影响比较大的特征,形成x、y3、模型训练
模型训练
交叉验证网格搜索等4、模型评估
精确率
Roc_AUC指标计算案例实现完整代码
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# classification_report分类评估报告
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,classification_report
if __name__ == '__main__':
# 1- 准备数据
df = pd.read_csv("./data/churn.csv",encoding="UTF-8")
# 2- 数据基本处理
# get_dummies:one-hot热编码处理,在逻辑回归中负责将非数值的列值拆开为True和False
new_df = pd.get_dummies(df)
# 展示所有的字段
# pd.set_option('display.max_columns', None)
# print(new_df.head())
# 2.1- 删除不要的字段,axis=1表示按列对列进行删除
new_df.drop(["gender_Male","Churn_No"], inplace=True, axis=1)
# 2.2- 【可选,主要为了查看方便】修改目标值字段名称Churn_Yes 变成 target
new_df.rename(columns={"Churn_Yes":"target"}, inplace=True)
print(new_df)
# 2.3- 数据的拆分,分为特征数据、目标值
# 为什么特征数据的代码这样写?1- 上面处理后的数据目标值列在中间,不好切片;2- 不是所有的特征对结果都有意义,特征选择
x = new_df[["PaymentElectronic","Contract_Month","MonthlyCharges"]]
y = new_df["target"]
# print(x)
# print(y)
# 3- 机器学习
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=56)
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
# 4- 模型评估
# 4.1- 预测
y_predict = estimator.predict(x_test)
# 4.2- 评估
print(accuracy_score(y_test, y_predict))
print("精确率",precision_score(y_test, y_predict))
print("召回率",recall_score(y_test, y_predict))
print("f1值",f1_score(y_test, y_predict))
# 4.3- 评估报告
"""
macro avg:宏均值,计算公式=(类别1的概率值+类别2的概率值)/2
weighted avg:加权均值,计算公式=(类别1的概率值*类别1的样本数 + 类别2的概率值*类别2的样本数)/总样本数
"""
print("分类评估报告",classification_report(y_test, y_predict))