LISA: Reasoning Segmentation via Large Language Model
摘要:
提出当前系统不能够很好的理解用户的真正意图,目前在执行视觉识别任务还是依赖明确的人类指令和预先定义的类别来识别物体
本文贡献:
- 提出一个新的分割任务---reasoning segmentation(基于隐式查询文本生成涉及复杂推理的二值掩码)
- 建立了一个包含一千多个图像-指令-掩码的数据样本
- 最后,提出了LISA模型(它继承了多模态大语言模型的语言生成能力,同时还具有生成分割掩码的能力)
模型架构
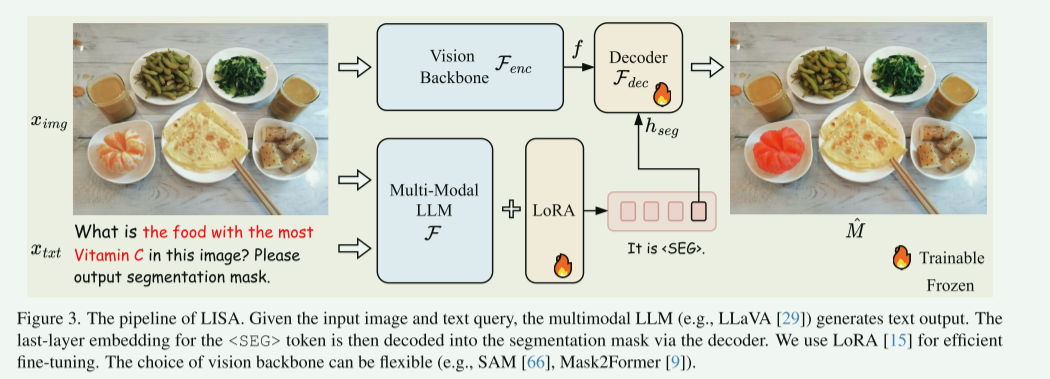
具体而言,首先在原始LLM词表中添加一个特殊标记 <SEG> (代表分割输出符号)。给定文本指令 xtxtx_{txt}xtxt 和输入图像 ximgx_{img}ximg 后,两者被输入到多模态 LLM \mathcal{F},生成文本响应 y^txt\hat{y}{txt}y^txt,该过程可以表述为:
y^txt=F(ximg,xtxt) \hat{y}{txt} = \mathcal{F}(x_{img}, x_{txt}) y^txt=F(ximg,xtxt)
当 LLM 需要生成二值分割掩码时,其输出序列 y^txt\hat{y}{txt}y^txt 将包含 <SEG> 标记。此时,我们提取与该 <SEG> 标记对应的最后一层隐藏状态嵌入 h^seg\hat{h}{seg}h^seg,并通过一个 MLP 投影层 γ\gammaγ 进行处理,得到 hsegh_{seg}hseg。同时,视觉主干网络 Fenc\mathcal{F}{enc}Fenc 从输入图像 ximgx{img}ximg 中提取密集的视觉特征 fff。最后,将 hsegh_{seg}hseg 和 fff 输入解码器 Fdec\mathcal{F}{dec}Fdec 以生成最终的分割掩码 M^\hat{M}M^。解码器 Fdec\mathcal{F}{dec}Fdec 的详细结构遵循文献 19。该过程可表述为:
hseg=γ(h^seg),f=Fenc(ximg),M^=Fdec(hseg,f). \begin{array}{l} h_{seg} = \gamma(\hat{h}{seg}), \\ f = \mathcal{F}{enc}(x_{img}), \\ \hat{M} = \mathcal{F}{dec}(h{seg}, f). \end{array} hseg=γ(h^seg),f=Fenc(ximg),M^=Fdec(hseg,f).
创新点:
- "嵌入即掩码"范式:这是最大的创新点。它不依赖传统的分割头,而是利用LLM的嵌入作为控制信号,将开放词汇的语义理解与分割任务无缝衔接。
- 推理引领分割:模型不是简单地分割"提到的"物体,而是先进行知识推理(判断维生素C含量),再分割"推理得出的"物体。这解决了传统方法无法处理的复杂指令。
- 高效的训练策略 :冻结LLM :在训练时,多模态LLM的主体参数被冻结,只通过LoRA等技术进行高效微调,这大大降低了计算成本,防止模型遗忘已有的语言知识。可训练的解码器:主要训练视觉主干之后的解码器部分,使模型学习如何将LLM的语义指令与视觉特征对齐。
- 灵活性 :框架中的视觉主干Fenc\mathcal{F}{enc}Fenc和解码器Fdec\mathcal{F}{dec}Fdec可以替换为任何先进的分割模型组件(如SAM、Mask2Former),具有良好的扩展性
数据来源
主要来自三个公共分割数据集:
- Semantic Segmentation Dataset
- Referring Segmentation Data
- VQA Data

评价指标
- glou:所有单张图像交并比的平均值
- clou:累积交集与累积并集之比
多任务损失函数
LISA的训练目标是一个加权求和的多任务损失函数,这反映了其需要同时优化文本生成 和分割掩码生成这两个子任务。
- 文本生成损失L_txt
- 文本生成损失L_mask
- 二元交叉熵损失BCE
- DICE损失
BCE损失负责细节轮廓,DICE损失负责整体形状,总损失是文本损失和分割损失的加权和
实验结果
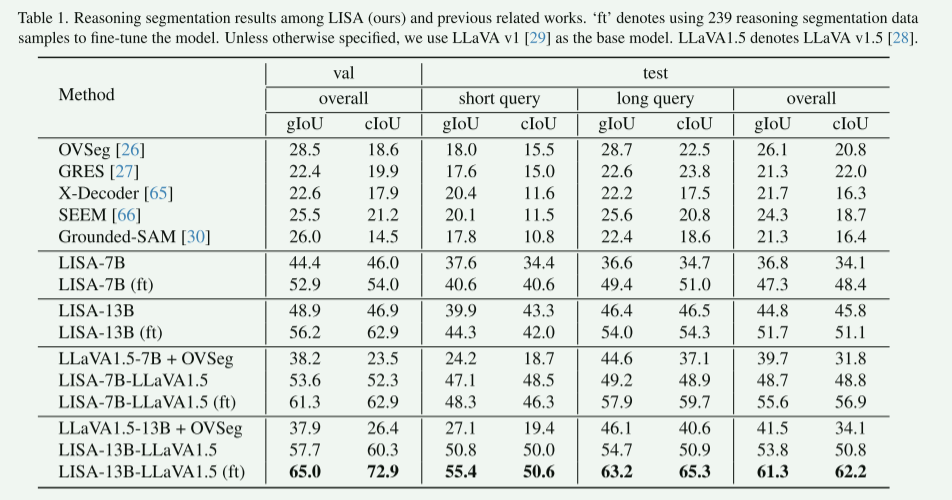
其中:
- OVSeg : 一个典型的开放词汇分割 模型。它擅长根据给定的类别名称列表(如"猫"、"狗"、"树")进行分割。但它的查询是"类别名",而不是自然语言指令,因此难以处理需要常识推理的复杂指令(如"分割出最易燃的物品")。
- GRES : 一个生成式指代分割 模型。它已经向前迈进了一步,可以根据简短的描述性短语(如"左边的蓝衬衫")生成分割掩码。但它仍然侧重于根据外观描述进行定位,而非深层次的推理。
- X-Decoder 和 SEEM : 这两个都是功能强大的通用多模态模型,集成了多种视觉任务(如分割、检测、识别)。它们具备更强的通用性,但其核心设计目标并非专门针对复杂的、需要知识推理的语言指令进行分割。
- Grounded-SAM : 这是一个非常流行且强大的组合式基线模型 。它采用"流水线"方式:先用一个模型(如GLIP)根据文本描述检测出物体的边界框。再将边界框输入分割模型(如SAM)得到掩码。它的性能很强,但LISA的端到端架构(理解、推理、分割一体化)旨在避免这种流水线系统的误差累积问题,并处理更抽象的指令。
LISA-7B/13B : 这是论文的核心模型,默认使用LLaVA v1 作为多模态基础模型,(+ft表示)在LISA 基础上,使用仅239个 推理分割数据样本进行微调 的版本(+OVSeg)代表分双阶段分割与本文的端到端的方式进行了对比。其中LLaVA1.5-7B+OVSeg代表首先使用多模态LLM(例如LLaVA v1.5)为输入查询生成文本输出,然后采用引用或开放词汇分词模型(例如OVSeg)生成分词掩码,两阶段是独立的,之间没有反馈,一旦第一阶段文本生成错误,也无法修正。