Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
目前存在的问题:
- 现有的多模态数据,Expression和音频线索之间的关联仍然是肤浅的("谁发出的声音最大?/谁最先发出声音?")
- 现有的针对多模态视觉任务数据集(RAVS,Ref-AVS)类型有限,不能够满足全模态模型的训练需求
本文贡献:
- 提出了OmniAVS数据集来推进基于推理的视听场景分割,其中的表达建立了复杂的认知链,超越了基本的声学特征("谁最有可能生病?")。
- 引入了一个基于多模态大语言模型的多模态指示分割助手基线模型(OISA)。该模型无缝地集成了文本、语音、声音和图像输入,以执行参考对象分割,同时为预测提供解释。
其中Expression包含4种不同的模式(文字、声音、语音、图片),8种不同的组合形式(纯文字、纯语音、文字配声音、语音配声音、文字配图片、语音配图片、文字配声音和图片、语音配声音和图片)
OISA模型架构:
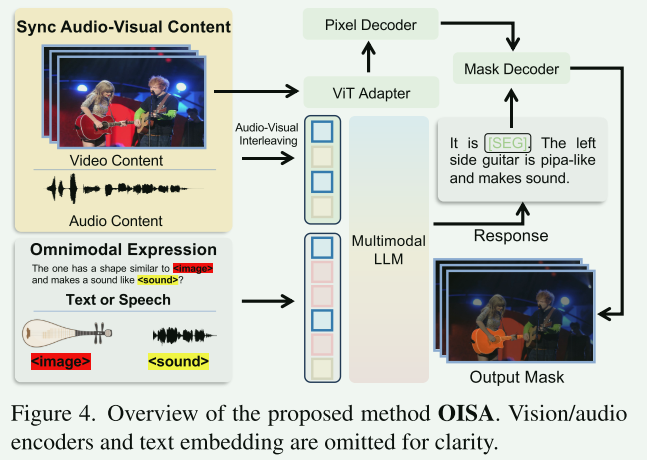
OISA由两个主要组件构成:
- 一个用于多模态理解与生成的MLLM,其中包含音频编码器、视觉编码器和LLM
- 一个用于分割与跟踪的掩码头。其中包含ViT适配器、像素解码器和掩码解码器
其中,掩码头是灵活的,可以被诸如SAM之类的模型替换。
两种输入形式:
-
给定一段音频-视觉视频 ,多模态编码器会处理视频和音频内容,以获得相应的视觉和音频标记。与VideoLLaMA顺序连接这两种模态不同,采用了音频-视觉交错策略 ,即将音频标记分割成片段,并与视觉标记交错排列。这个交错的序列就形成了我们的音频-视觉内容标记。这种方法无需引入额外参数即可有效同步音频和视频帧,这对于需要音画对齐的场景尤其有用。
-
对于全模态表达输入(如用户指令),使用音频编码器处理语音和声音,使用视觉编码器处理图像。产生的标记随后被整合到相应的文本标记中,以生成最终的全模态表达标记 。所有类型的标记随后被输入到MLLM中。MLLM生成文本响应,并产生一个代表目标对象的
[SEG]标记,该标记随后被掩码解码器用于分割预测。我们的掩码解码器使用查询传播来分割每一帧,在分割过程中在线优化查询,以缓解动态运动的影响。采用交叉熵损失 用于文本生成,并采用DICE损失 和二元交叉熵损失用于分割。
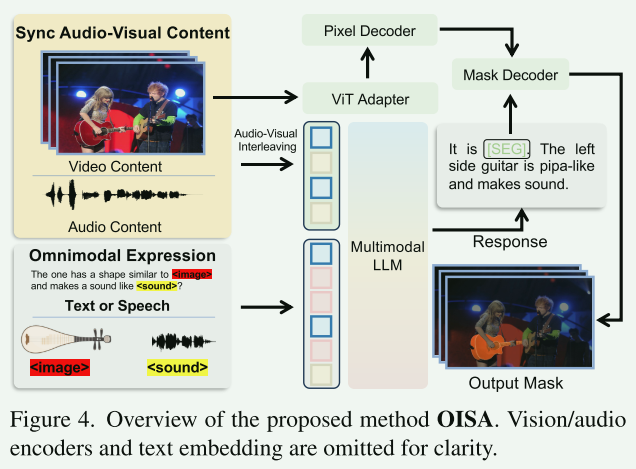
音频-视觉交错
对于任意长度的视频,我们从开头到结尾均匀采样N帧。每帧由视觉编码器单独处理,以获得LvL_vLv个视觉标记,表示为 V=v1,v2,...,vNV = {v_1, v_2, ..., v_N}V=v1,v2,...,vN,其中 vi∈RLv×dv_i ∈ R^{L_v × d}vi∈RLv×d代表第i帧的LvL_vLv 个视觉标记,维度为d。对于视频中的音频内容,我们使用音频编码器处理它以获得音频标记A∈RLA×dA ∈ R^{L_A × d}A∈RLA×d,其中 LAL_ALA表示音频标记的总数。
为了实现音频-视觉对齐,我们将音频分割成与帧率对应的片段,得到a1,a2,...,aN{a_1, a_2, ..., a_N}a1,a2,...,aN,其中ai∈RLa×da_i ∈ R^{L_a × d}ai∈RLa×d且 La=LA/NL_a = L_A / NLa=LA/N。接下来,我们交错音频标记片段和视觉标记,形成音频-视觉交错标记序列 v1,a1,v2,a2,...,vN,aNv_1, a_1, v_2, a_2, ..., v_N, a_Nv1,a1,v2,a2,...,vN,aN。
查询传播
尽管MLLM在多模态理解和推理方面表现出色,但它们并不擅长分割任务。以往的工作在MLLM之后附加了一个额外的视觉编码器(用于普通特征提取)和一个用于分割的掩码头,这导致了一种冗余且非最优的设计。为了解决这些问题,在从视频中提取视觉标记的同时,我们通过ViT适配器 12 同步提取相应的多尺度特征,然后通过像素解码器对其进行增强。这些增强的特征与MLLM生成的 [SEG]标记一同被输入到掩码解码器中。
在使用掩码解码器进行分割时,VideoLISA 对每一帧使用相同的 [SEG]标记进行独立分割,即"单令牌分割全部"(One-Token-Seg-ALL, OTSA),如图5(a)所示。然而,这种方法存在局限性。先前的研究 表明,单个查询往往无法充分表示目标物体,尤其是在视频中存在快速运动时。单个查询带有位置先验,这使得它难以捕捉动态运动过程(例如,一个物体从右向左移动,如图5(a)所示)。这种局限性会导致目标ID切换(ID-Switch)问题,即模型持续跟踪视频右侧的错误目标。
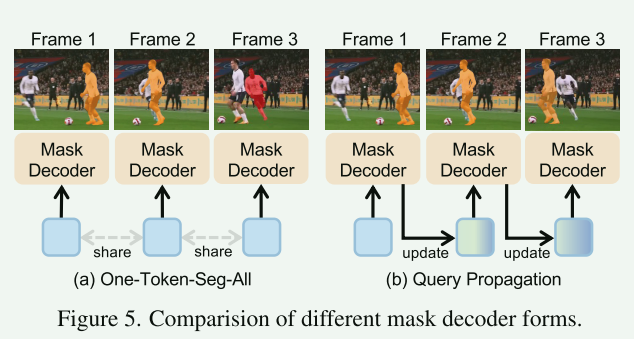
查询传播
- 工作流程 :
- 初始化 :MLLM为视频的第一帧 生成一个初始的
[SEG]查询 Q1。 - 传播与更新 :在处理第二帧 时,掩码解码器不仅接收增强后的视觉特征,还会接收来自第一帧的查询 Q1。它利用当前帧的信息更新这个查询,生成一个更适应第二帧中目标状态的新查询 Q2。
- 迭代:这个更新后的查询 Q2 被传播到第三帧,并继续更新为 Q3,如此循环往复。如图5(b)中的 "update" 箭头所示。
- 初始化 :MLLM为视频的第一帧 生成一个初始的
OTSA
- 工作流程:
- 输入处理:模型接收一个视频序列和一条语言指令
- 特征提取与融合:通过视觉编码器提取视频帧的特征,并与文本指令一起输入到多模态大语言模型(MLLM)中。
- 生成
<TRK>标记**:MLLM 基于视觉内容和文本指令进行推理,在输出的文本序列中生成一个特殊的<TRK>标记。这个标记的隐藏层嵌入(hidden embedding)包含了经过MLLM理解并融合后的目标对象的语义和空间信息,作为整个视频中该目标的统一表征。** - 帧独立分割 :将这个唯一的
<TRK>标记嵌入分别输入到每一帧的掩码解码器中(例如SAM的掩码解码器)。掩码解码器根据该标记提供的目标信息,在每一帧中独立地预测出像素级的分割掩码
OTSA 方法的一个关键特点是其 "静态性" 。在整个视频处理过程中,<TRK>标记是固定不变的。这意味着它缺乏时序适应性,难以有效处理视频中目标的剧烈外观变化、严重遮挡或复杂运动。
简而言之,音频-视觉交错 解决了跨模态理解与对齐 的问题,而查询传播 则解决了时序分割与跟踪的问题,二者共同构成了OISA模型强大的技术基础。
实验
MLLM:InternVL2-1B
- LLM:Qwen2-0.5B-Instruct
- vision encoder:InternViT-300M-448px
- audio encoder:Whisper-large-v3
评价指标:J值和F值的平均值
- J值:IoU
- F值:评估分割的"边缘质量"是否清晰、精准
当语言指令描述的内容在视频中根本不存在时,模型预测正确时,J&F为1。预测错误时,J&F为0
使用多个数据集合进行训练
- 语义分割数据集:ADE20K , COCO-Stuff, PASCAL-Part , PACO-LVIS
- 指代分割数据集:RefCOCO, RefCOCO+ , RefCOCOg, ReasonSeg
- 指代视频分割数据集:Refer-YouTube-VOS ,Refer-DAVIS-17 , MeViS , ReVOS
- 音频-视觉分割数据集:Ref-AVS Bench , OmniAVS。
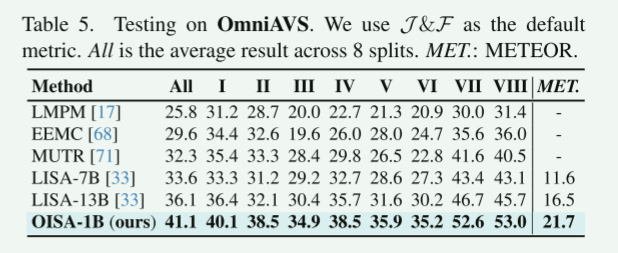
消融实验:
