1.什么是one-hot编码?为什么使用?
one-hot编码 是一种把类别数据(分类变量)转换为数值型向量 的方式,常用于机器学习和深度学习中。计算机擅长处理数字,但分类数据(比如"红/绿/蓝")是非数值的。如果直接用数字代替类别(比如红=1,绿=2,蓝=3),模型可能会误以为它们之间存在大小关系或距离(例如蓝 > 绿 > 红),但其实类别之间没有这种顺序。所以需要 one-hot 编码,把每个类别表示成一种"独立"的方式。
2.卷积层总结
卷积核的channel与输入特征层的channel相同
输出特征矩阵的channel与卷积核的个数相同
3.常用激活函数
3.1 sigmoid激活函数
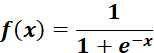
缺点在于Sigmoid激活函数饱和时梯度值非常小,故网络层数较深时,容易出现梯度消失现象
3.2 ReLU激活函数
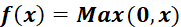
缺点在于当反向传播过程中有一个非常大的梯度经过时,反向传播更新后可能导致权重分布中心小于0,导致该处的倒数始终为0,反向传播无法更新权重,即进入失活状态
3.3 为什么使用激活函数
因为在我们的计算过程中是一个线性的计算过程,为了引入非线性因素,使其具备非线性计算能力,那么就需要通过一个非线性函数来达到这个目的。在实际应用中,ReLU函数用的更多
4.当卷积过程中出现越界时如何解决
使用padding的方式在图像周围补零即可,补完之后便可以正常卷积;在卷积操作过程中,矩阵经卷积操作后的尺寸由以下几个因素决定:
- 输入图片大小w*w
- Filter大小F*F Filter表示滤波器或者叫做卷积核kernel
- 步长 S
- padding的像素p
经卷积后的矩阵尺寸大小计算公式为:
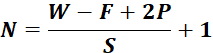
5.池化层
5.1目的
对特征图进行稀疏处理,减少数据运算量
5.2特点
没有训练参数(卷积层的每个卷积核都有各自的参数),只是在原始的特征层上求取最大值(MaxPooling下采样层)或者最小值
只改变特征矩阵的w和h,不改变channel(深度)
一般poolsize(池化核大小)和stride(布局)相同
6.反向传播过程中的一些问题
6.1什么是反向传播
反向传播BP是神经网络学习的核心算法,它的作用是自动计算每个参数(权重、偏置)对最终误差(损失)的影响,并用这些信息来更新参数,让模型学得越来越好。
6.1.2正向传播
输入数据经过神经网络(层层加权、非线性激活),得到输出结果。用损失函数衡量输出和真实标签之间的差距。
例如:预测结果为0.8 ,真实值为1 ,损失为0.04。
6.1.3反向传播
反向传播就是从输出层往输入层"反传"误差,计算每个参数应该怎样调整。
核心思想:用链式法则(微积分中的导数规则) ,逐层计算损失函数对每个参数的偏导数(梯度) 。梯度表示"如果我稍微改变这个参数,损失会变大还是变小"。计算完梯度后,用优化算法(最常见是梯度下降)来更新参数:
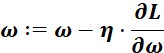
其中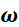 是权重参数,
是权重参数,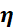 为学习率,
为学习率,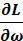 是损失函数对参数的梯度
是损失函数对参数的梯度
总结:反向传播 = 链式法则 + 梯度下降,它让神经网络能够"自我调整",学会从错误中改进。如果没有反向传播,神经网络就无法有效训练。
6.2损失的计算一般为:交叉熵损失(Cross Entropy Loss)
6.2.1针对多分类问题
softmax输出,所有输出概率和为1,公式如下:
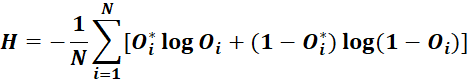
对于上述两个公式其中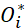 为真是标签值,
为真是标签值,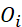 为输出预测值,
为输出预测值,
默认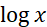 以e为底
以e为底
6.3优化器optimazer
6.3.1 SGD优化器
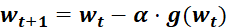
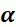 为学习率,
为学习率,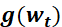 为t 时刻对参数
为t 时刻对参数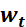 的损失梯度
的损失梯度
缺点:易受样本噪声的影响,可能陷入局部最优解
6.3.2 SGD+Momentum优化器(常用)
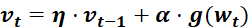
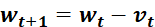
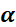 为学习率,
为学习率,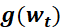 为t 时刻对参数
为t 时刻对参数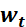 的损失梯度,
的损失梯度,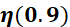 为动量系数
为动量系数
6.3.3 Adagrad优化器(自适应学习率)
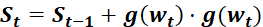
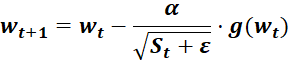
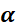 为学习率,
为学习率,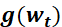 为t 时刻对参数
为t 时刻对参数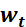 的损失梯度,
的损失梯度,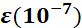 为防止分母为零的小数
为防止分母为零的小数
缺点:学习率下降的太快,可能还没收敛就停止训练了
6.3.4 RMSProp优化器(自适应学习率)
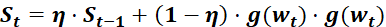
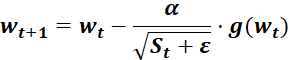
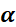 为学习率,
为学习率,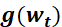 为t 时刻对参数
为t 时刻对参数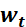 的损失梯度,
的损失梯度,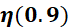 为动量系数,控制衰减速度,
为动量系数,控制衰减速度,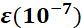 为防止分母为零的小数
为防止分母为零的小数