我先给出结论:两个方法的核心向量转换逻辑是一致的,但是由于添加的前缀不同,导致最终的向量值差异很大,但是由于两者的'语义匹配能力'并未失效,计算余弦相似度时,仍会呈现极高的相似度(接近 1)。
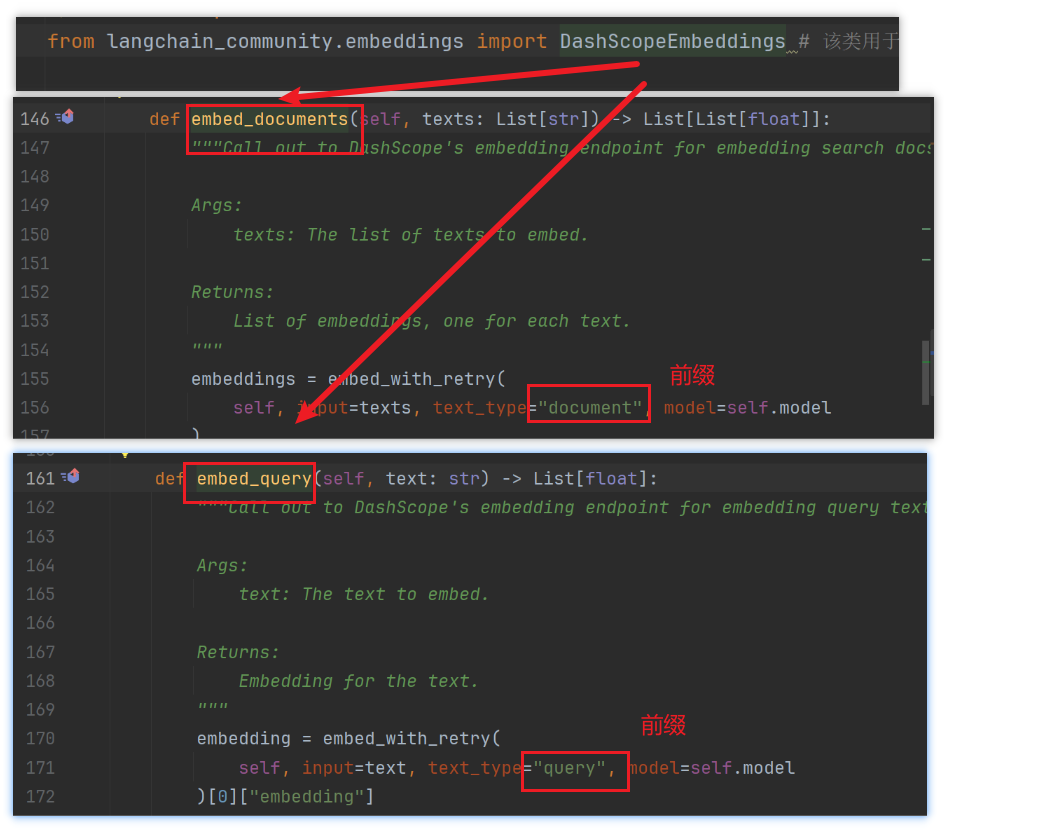
- embed_query方法使用的前缀是 query:
- embed_documents方法使用的前缀是document
共享同一模型的编码能力
两种方法本质上调用的是同一个嵌入模型,使用的是完全相同的向量转换算法。例如:
- 对于
DashScopeEmbeddings,无论是embed_query("问题")还是embed_documents(["文档1", "文档2"]),最终都会调用阿里达摩院的同一个嵌入模型(如text-embedding-v1); - 模型内部对文本的分词、特征提取、向量生成逻辑完全一致,生成的向量维度和语义编码规则也相同(因此才能计算"问题向量"与"文档向量"的相似度)。
向量数值差异性的原因
两个方法的前缀不同
特殊场景的文本截断
对于超长文本(超过模型支持的最大长度):
embed_documents可能会对每个文档进行自动截断或分段处理(不同模型实现不同),确保符合模型输入要求;embed_query由于输入通常是短文本(问题),截断处理较少见,但本质逻辑与文档截断一致。
在RAG中的使用区分
在 RAG 中,必须用 embed_query 处理用户问题,embed_documents 处理知识库文档(尽管逻辑相同,但接口设计对应不同角色)。
例如,在典型的 RAG 流程中:
python
# 用 embed_documents 处理文档(批量)
docs = ["文档1内容...", "文档2内容..."]
doc_vectors = embeddings.embed_documents(docs)
# 用 embed_query 处理用户问题(单个)
query = "用户的问题..."
query_vector = embeddings.embed_query(query)
# 计算相似度(因向量来自同一逻辑,可直接比对)
similarity = cosine_similarity(query_vector, doc_vectors)这里正因为两者的向量转换逻辑一致,才能通过余弦相似度准确匹配问题与文档。