本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
最近 RAG(检索增强生成)这个概念火得一塌糊涂,各种优化方案层出不穷。如果你还在为如何构建一个高效、智能的 RAG 系统而苦恼,或者想深入了解 RAG 的各种高级玩法,那么今天老章要给大家安利一个宝藏项目------bRAG-langchain!
这个项目简直就是 RAG 领域的"葵花宝典",它通过一系列精心设计的 Jupyter Notebooks,带你从 RAG 的基本架构,一路玩转到多查询、路由、高级检索和重排等各种骚操作。跟着它走,你的 RAG 系统绝对能脱胎换骨!
什么是 bRAG-langchain?
简单来说,bRAG-langchain 是一个专注于探索 LangChain 框架下 RAG 技术的开源项目。它不仅仅是代码的堆砌,更是一套系统性的学习路径,旨在帮助开发者理解并实践 RAG 的各种高级策略。
项目巧妙地将复杂的 RAG 概念拆解成一个个独立的 Jupyter Notebooks,每个 Notebook 都聚焦于一个特定的主题,让你能够循序渐进地掌握 RAG 的精髓。
从零到英雄:bRAG-langchain 项目深度解析,你的一站式高级 RAG 应用开发指南
在人工智能领域,检索增强生成(RAG)已成为构建智能、可靠、能引用特定知识的语言模型的关键技术。然而,从一个简单的概念到一个生产级的 RAG 系统,中间充满了挑战。如何超越基础的"向量搜索+LLM",构建一个真正强大、精确且高效的 RAG 应用?
答案就在 bRAG-langchain 这个开源项目中。
bRAG-langchain 不仅仅是一个代码库,它更像是一本互动式的教科书。通过一系列精心设计的 Jupyter Notebooks,该项目为开发者和 AI 爱好者们提供了一条从入门到精通的清晰学习路径。
本文将带您深入探索 bRAG-langchain,理解其核心架构,并领略其如何通过一系列进阶技术,将一个基础的 RAG 应用逐步打造成一个智能、高效的知识问答系统。
宏观视角:RAG 架构解析
在深入代码之前,我们首先需要理解一个典型的 RAG 系统是如何工作的。bRAG-langchain 项目中提供的这张架构图清晰地展示了其核心流程:
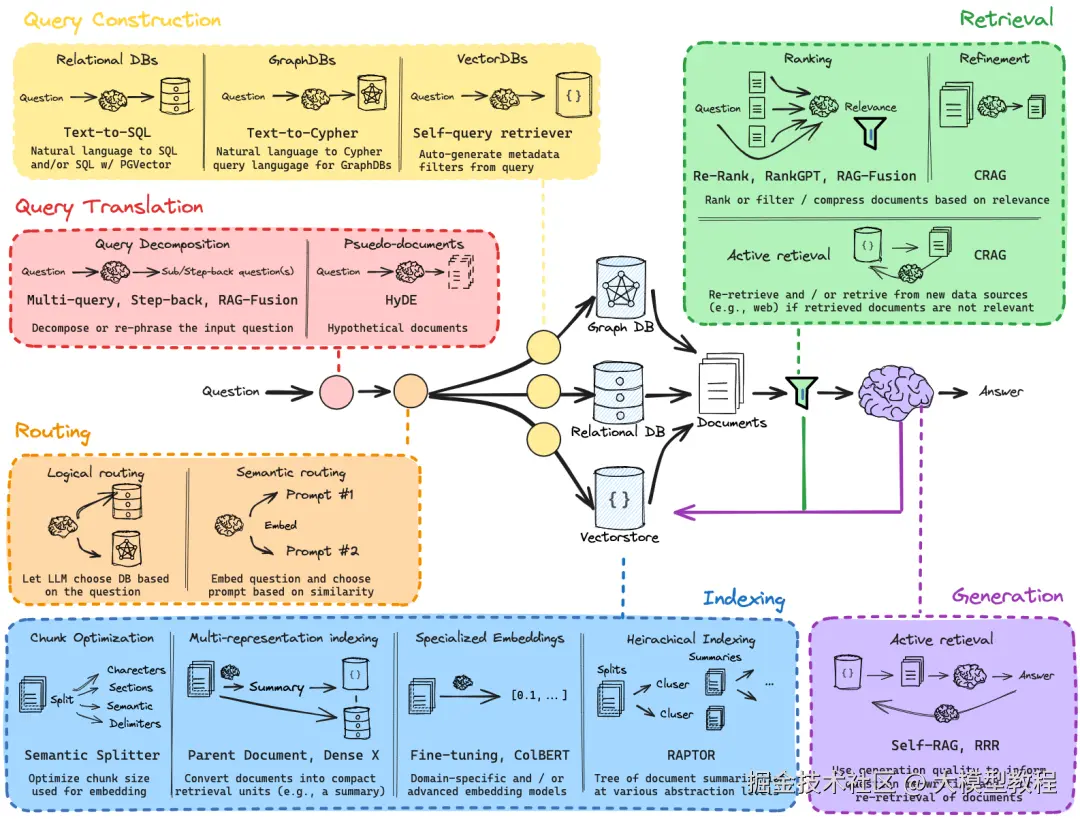
RAG 详细架构图
这个流程可以分解为以下几个关键阶段:
- 文档加载与切分 (Loading & Splitting): 首先,系统加载你的原始文档(如 PDF、Markdown、网页等),并将其切割成更小的、易于处理的文本块 (Chunks)。
- 向量化 (Embedding): 使用像 OpenAI 这样的模型,将每个文本块转换为一个向量(一串数字)。这个向量代表了文本块在多维空间中的语义位置。
- 向量存储 (Vector Store): 将这些文本块及其对应的向量存储在一个专门的数据库中,如
ChromaDB或Pinecone。这个数据库能以极高的效率进行向量相似度搜索。 - 检索 (Retrieval): 当用户提出问题时,系统同样将问题向量化,然后在向量数据库中搜索与之最相似的文本块,并将它们作为"上下文"检索出来。
- 生成 (Generation): 最后,系统将用户的原始问题和检索到的上下文信息,一同"喂"给大型语言模型(LLM),让 LLM 基于给定的上下文来生成一个精准、可靠的答案。
整个过程由 LangChain 框架进行编排和粘合,极大地简化了开发流程。
动手实践:项目设置
理论讲完了,让我们亲自动手。bRAG-langchain 的上手过程非常简单:
-
克隆项目库:
bashgit clone <https://github.com/bRAGAI/bRAG-langchain.git> -
安装依赖:
pip install -r requirements.txt -
配置环境变量:
bash
cp .env.example .env然后,编辑新创建的 .env 文件,填入你的 OpenAI、Cohere 等平台的 API 密钥。
完成以上步骤后,你就可以开始探索了!项目根目录下的 full_basic_rag.ipynb 是一个绝佳的起点,它包含了一个完整、基础的 RAG 聊天机器人的所有代码,让你可以在几分钟内就拥有一个可以运行的原型。
进阶之旅:Notebooks 核心内容探索
bRAG-langchain 的精髓在于其 notebooks/ 目录下的系列教程。它引导你从一个最基础的 RAG 开始,逐步为其添加高级功能。
[1]_rag_setup_overview.ipynb - 奠定基石
这是你的"Hello, World!"。这个 Notebook 详细演示了 RAG 的基础构建模块:如何加载文档、切块、使用 OpenAI 进行向量化,以及如何将它们存入 ChromaDB 向量数据库。这是后续所有高级功能的基础。
[2]_rag_with_multi_query.ipynb - 超越简单搜索
问题: 用户的提问方式可能是模糊或多方面的,单一的向量搜索可能无法命中最佳答案。解决方案: 多查询检索 (Multi-Query Retrieval)。这个 Notebook 教你如何利用 LLM,根据用户的原始问题自动生成多个不同角度的子问题。例如,当用户问"如何构建一个好的 RAG 系统?"时,LLM 可能会自动生成"RAG 的关键组件是什么?"、"评估 RAG 性能的指标有哪些?"等子问题。通过对这些子问题分别进行检索并合并结果,系统能撒下一张更大的网,从而捕获到更全面、更相关的上下文。
[3]_rag_routing_and_query_construction.ipynb - 构建智能路由
问题: 并非所有问题都需要通过向量搜索来回答。有些可能是简单的对话,有些可能需要查询结构化数据。解决方案: 路由 (Routing)。这是通往智能 Agent 的关键一步。该 Notebook 演示了如何构建一个"路由器",它首先分析用户的意图,然后智能地将请求分发到不同的处理链上。例如,一个问题可以被路由到:
- 一个用于向量搜索的 RAG 链。
- 一个用于总结对话历史的摘要链。
- 一个用于回答常规问题的普通 LLM 链。
这使得你的应用不再是一个单功能的问答机器人,而是一个能处理复杂任务的智能系统。
[4]_rag_indexing_and_advanced_retrieval.ipynb - 探索高级索引
问题: 如何索引数据与如何检索数据同等重要。仅索引原始文本块可能限制了检索的效果。解决方案: 多重表示索引 (Multi-representation Indexing)。这个 Notebook 引入了一个强大的概念:除了索引原始文本块,我们还可以索引该文本块的多种其他"表示",例如:
- 该文本块的摘要。
- 由 LLM 生成的、与该文本块相关的可能问题。
这样,即使用户的提问方式与原文措辞差异很大,也可能通过摘要或可能问题命中相关的上下文,极大地提升了检索的召回率。
[5]_rag_retrieval_and_reranking.ipynb - 精益求精的重排序
问题: 初步检索出的文档列表可能数量很多,且相关性良莠不齐,甚至存在干扰信息。解决方案: 重排序 (Re-ranking)。这是提升 RAG 质量的最后一道关键工序。该 Notebook 演示了如何引入一个"第二阶段"模型(如 Cohere 的 Re-ranker 或 Reciprocal Rank Fusion 算法),对初步检索到的文档列表进行重新打分和排序,确保最相关、最重要的信息排在最前面。这能显著提升 LLM 生成答案的质量和准确性。
为什么 bRAG-langchain 是一个必藏项目?
- 实践出真知: 它不是枯燥的理论,而是你可以直接运行、修改和实验的可执行代码。
- 结构化学习路径: 从基础到高级,循序渐进,完美匹配人类的学习曲线。
- 紧跟前沿技术: 涵盖了多查询、路由、重排序、多重表示等现代 RAG 系统的核心高级技术。
- 绝佳的样板工程:
full_basic_rag.ipynb为你提供了一个可以快速启动自己项目的完美起点。
结语
bRAG-langchain 项目为所有希望在 RAG 领域深耕的开发者提供了一个宝贵的资源库。它不仅展示了如何"构建"一个 RAG 应用,更重要的是,它揭示了如何"构建一个好"的 RAG 应用。
准备好成为一名 RAG 专家了吗?现在就去克隆这个项目,深入探索这些 Notebooks 吧!别忘了在 GitHub 上给它一个 Star 来支持作者的辛勤工作!
项目链接: github.com/bRAGAI/bRAG...
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。