D044 中国上市公司数据(2000-2023年)
数据简介
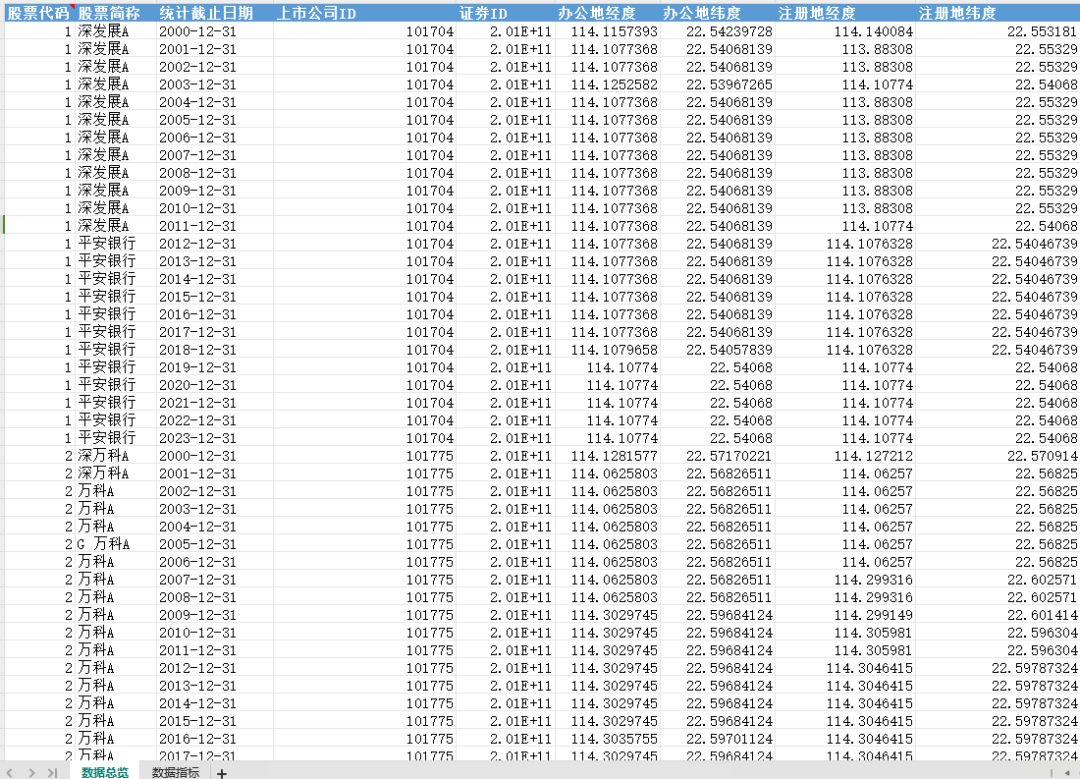
今天带来的数据是2000-2023年的全国上市公司的注册地、办公地、股票代码、股票简称、上市公司ID、证券ID数据,并对其进行了可视化处理,方便大家研究使用。
通过分析这些数据,可以了解上市公司的地理分布、行业分布及其市场表现。这有助于政府制定区域经济政策,投资者进行投资决策,企业进行市场定位和竞争分析。此外,还能揭示区域经济发展不平衡的问题,为实现区域协调发展提供数据支持。
数据详情
数据来源:上市 公司年报
时间跨度:2000-2023
数据频度:年度
数据范围:中国
数据格式:Excel/Shp
数据概览
该数据的指标概览与数据概览如下,并将其按照年份分成了24个分表与1个数据总表:

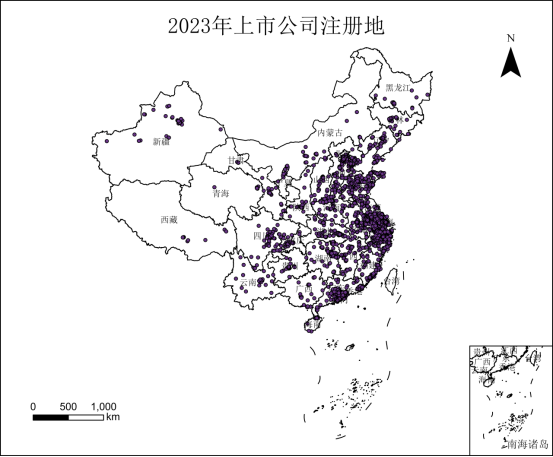
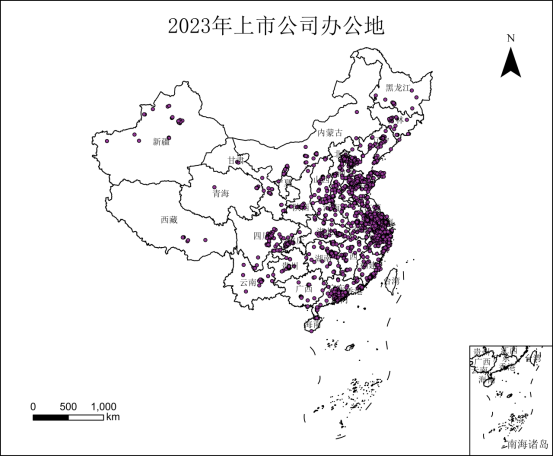
本文将Excel数据进行可视化表达,将其转换成Shp格式文件,下图为2023年上市公司注册地和办公地的可视化示例: