 论文标题:Unified Multimodal Understanding via Byte-Pair Visual Encoding
论文标题:Unified Multimodal Understanding via Byte-Pair Visual Encoding
作者团队:Wanpeng Zhang, Yicheng Feng, Hao Luo, Yijiang Li, Zihao Yue, Sipeng Zheng, Zongqing Lu
作者机构:北京大学,加州大学圣地亚哥分校,中国人民大学,BeingBeyond
论文地址:https://arxiv.org/abs/2506.00596
项目主页:https://beingbeyond.github.io/Being-VL-0.5
代码仓库:https://github.com/beingbeyond/Being-VL-0.5
前言
大家好,今天CV君要聊的话题,是关于如何让AI更好地"读图会意"。目前的多模态大模型(MLLM)在融合视觉和语言信息方面取得了很大进展,但背后一直存在一个根本性的挑战:图像和文字,这两种模态的信息表示方式,存在一道天然的鸿沟。
目前主流的方法主要分两派:
-
连续派:用一个视觉编码器(比如CLIP)把图片变成一长串连续的向量。这种方法语义信息保留得不错,但这些"模拟信号"般的视觉特征,和语言模型习惯处理的"数字信号"般的文本Token格格不入,存在"模态鸿沟",而且计算量大,容易产生幻觉。
-
离散派:用VQ-GAN等技术把图片"像素化"成一堆离散的视觉Token。这样做虽然统一了格式,但这些Token往往只代表了基础的颜色和纹理,缺乏高级语义,就像把一幅画拆成了一堆马赛克色块,很难理解画的是什么。
有没有办法能鱼与熊掌兼得呢?来自北大、UCSD、BeingBeyond等机构的研究者们带来了一篇非常有启发性的工作------Being-VL,他们创造性地将自然语言处理(NLP)领域大名鼎鼎的BPE(Byte-Pair Encoding)算法引入了视觉领域,试图为视觉和语言的统一表示找到一条新路。
核心思想:像学文字一样学看图
BPE算法的核心思想很简单:在文本处理中,它会不断地把语料库里最高频出现的相邻字符对(比如'e'和's')合并成一个新的、更长的子词('es'),如此迭代,最终形成一个从"字母组合"到"常用单词"的层级化词表。
Being-VL就借鉴了这个思想,把图片也看成一篇"文章"。
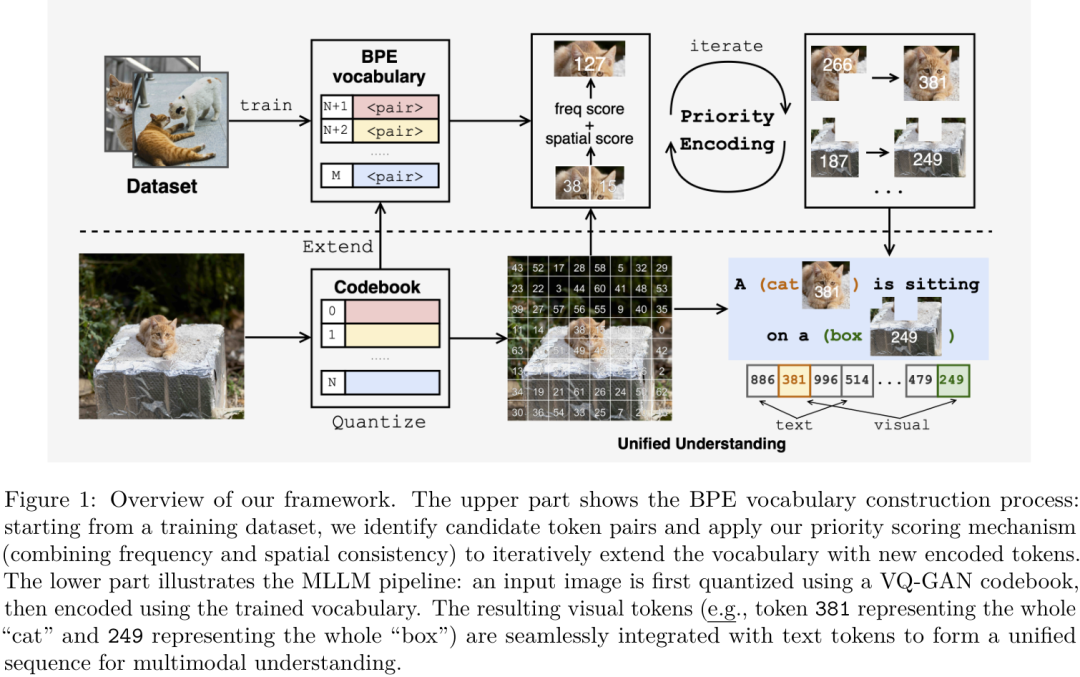
如上图所示,整个流程分为两步:
-
构建BPE视觉词表:首先,用一个VQ-GAN把图片切分成一堆基础的视觉"偏旁"(离散Token)。然后,在大量的图片数据上,不断寻找那些既频繁出现、空间位置又相对固定的相邻Token对,将它们合并成一个新的"视觉词汇"。比如,"猫鼻子"的Token和"猫眼睛"的Token总是一起出现,并且位置固定,那么它们就可以被合并成一个代表"猫脸"的新Token。通过这种方式,模型就学会了一个从基础纹理到复杂物体(比如整个"猫"或"箱子")的层级化视觉词典。
-
统一多模态理解:当一张新图片输入时,模型先用VQ-GAN进行离散化,然后用上面学到的BPE词表进行"分词",得到一系列包含高级语义的视觉Token。这些视觉Token和文本Token一起,被无缝地送入一个统一的Transformer模型中进行理解。CV君觉得,这个过程真的就像我们阅读图文混排文章一样自然。
优先引导的编码方案 (Priority-Guided Encoding)
为了构建出高质量的视觉词表,作者没有简单地只看"频率",而是设计了一个"优先引导"的打分机制,同时考虑了 "共现频率" 和 "空间一致性"。只有那些既经常一起出现、空间关系又稳定的Token对,才会被优先合并。这保证了新生成的视觉词汇是真正有意义的视觉概念,而不是随机的拼凑。
训练策略:循序渐进的课程学习
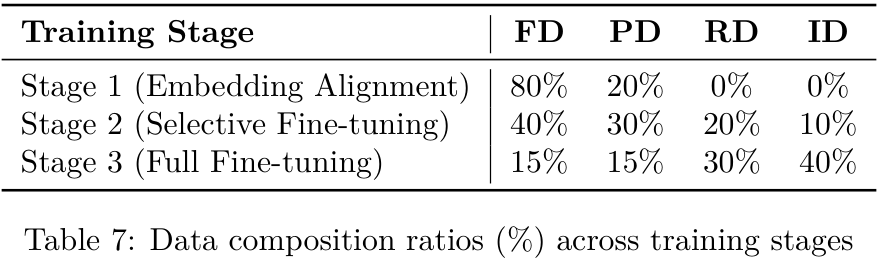
有了层级化的视觉词表,训练也得跟上节奏。作者为此设计了一套三阶段的"课程学习"策略。
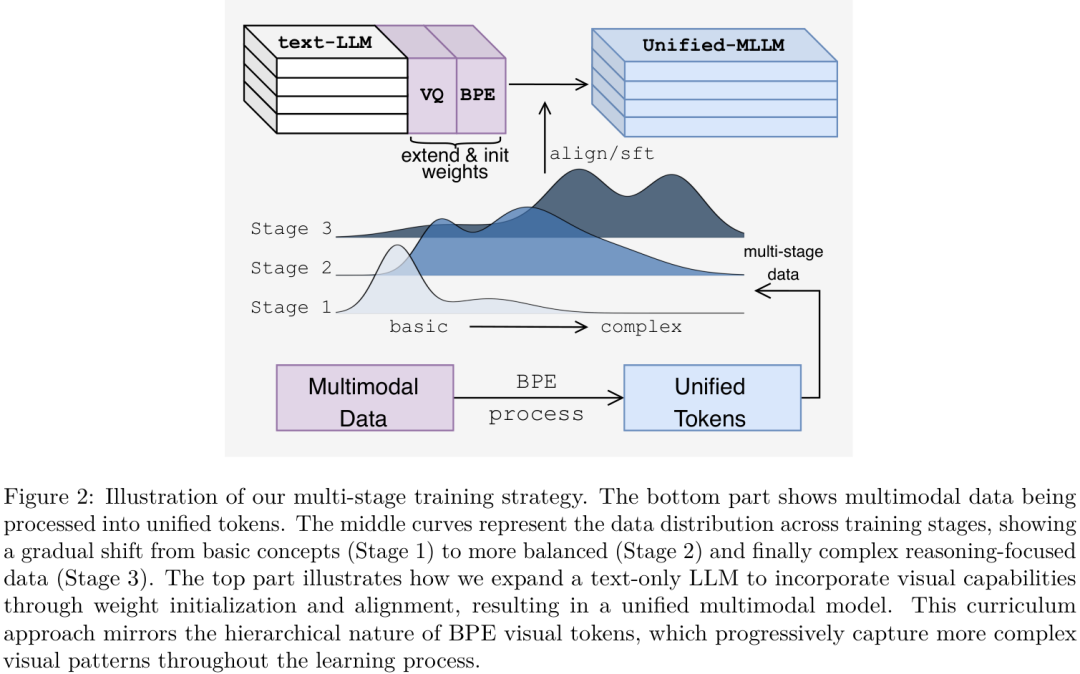
如上图所示,整个训练过程就像一个人的学习成长过程:
-
第一阶段: Embedding对齐。先让模型学习基础的图文对应关系,比如让它知道哪些视觉Token对应"猫",哪些对应"狗"。这个阶段主要训练新加入的视觉Embedding层,语言模型主体部分冻结。
-
第二阶段:选择性微调。开始接触更复杂的感知和推理数据,并解冻Transformer模型的前几层,让模型学习更深层次的跨模态交互。
-
第三阶段:完全微调。在最复杂的指令和推理数据上进行端到端的微调,释放模型的全部潜力。
这种从易到难、逐步深入的课程学习方法,与BPE视觉词表的层级化特性完美契合,使得模型能够高效地掌握视觉语言的奥秘。
实验结果:统一模型有多强?
Being-VL在多个主流的视觉语言评测基准上都取得了非常出色的成绩。
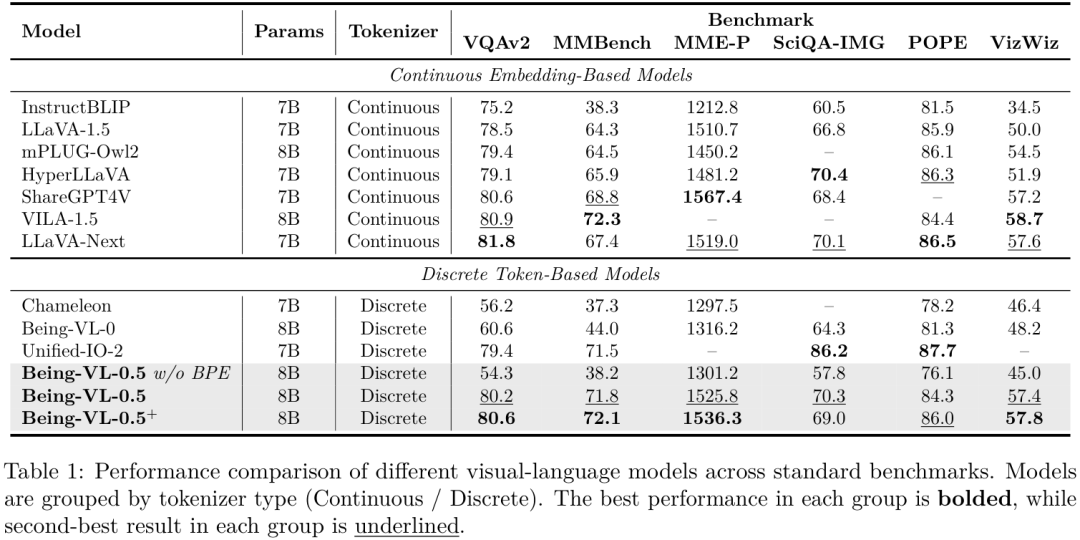
从上表可以看到,在"离散Token"这条赛道上,Being-VL-0.5 和 Being-VL-0.5+ 全面超越了之前的模型。更重要的是,它们成功地缩小了与"连续派"顶尖模型(如LLaVA-Next, VILA-1.5)的性能差距,在VQAv2和MMBench等关键指标上达到了相当的水平。例如,Being-VL-0.5+在VQAv2上取得了80.6的得分,在MMBench上取得了72.1的得分,这证明了BPE视觉编码这条路是完全走得通的,并且极具潜力。
BPE Token激活机制分析
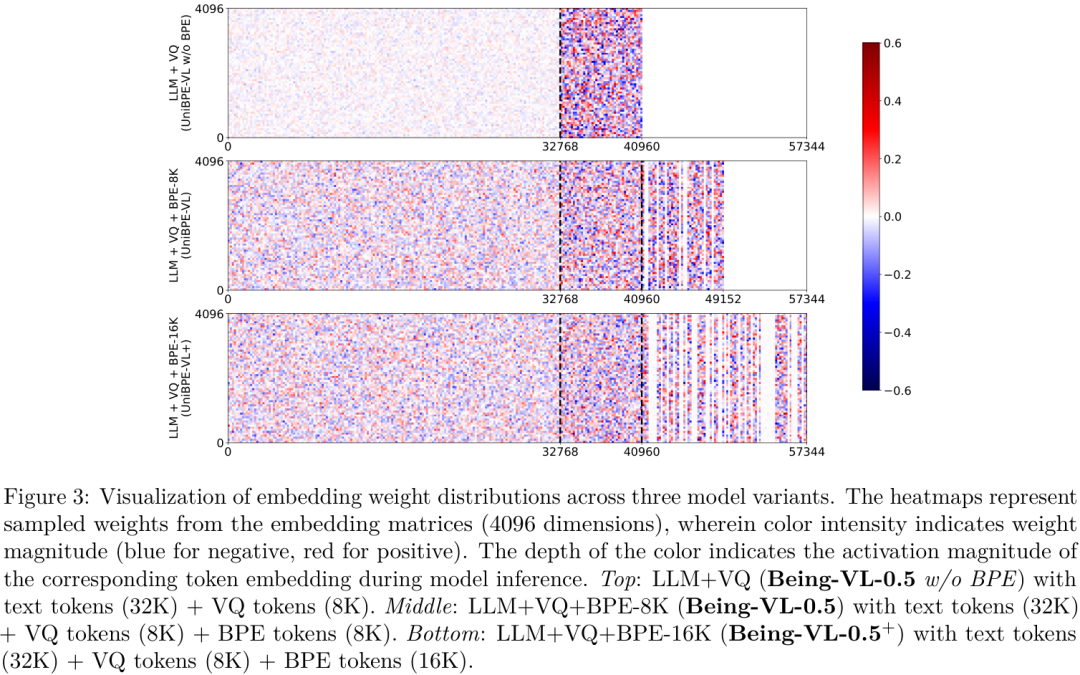
这张Embedding权重分布的可视化图非常有趣。在没有BPE的基础模型中(上图顶部),文本Token和视觉Token的权重分布差异巨大,泾渭分明,这正是"模态鸿沟"的体现。而加入了BPE词表后(中图和下图),两者的权重分布变得更加均衡和统一,说明BPE确实起到了桥梁作用,拉近了视觉和语言的距离。
扩展潜力与训练效率
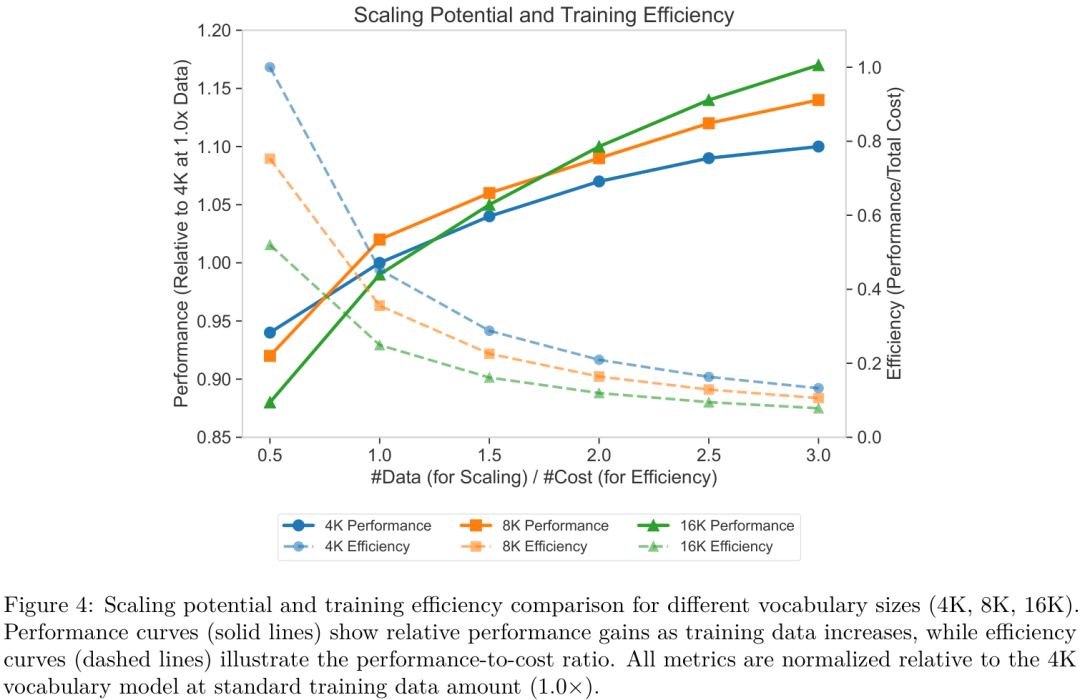
作者还探讨了BPE词表大小的影响。如上图所示,更大的词表(如16K)虽然在训练初期效率稍低,但随着数据量的增加,其性能扩展潜力也更大。这说明该方法具有很好的可扩展性,未来可以通过更大的词表和更多的训练数据,进一步提升模型性能。
消融实验

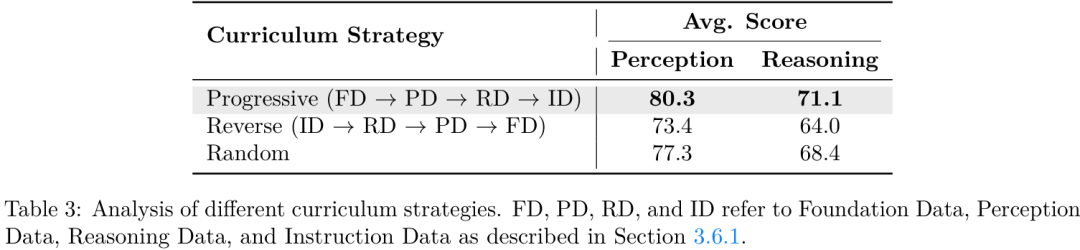
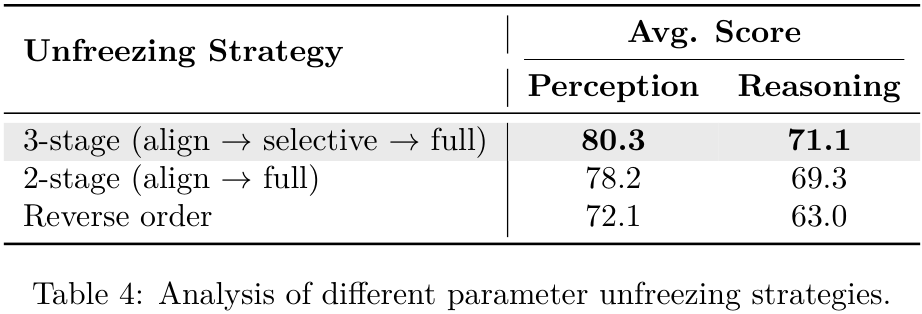
一系列详尽的消融实验也证明了"课程学习"和"渐进式解冻"等训练策略的有效性。例如,标准的多阶段训练方法比简单粗暴的单阶段训练在感知和推理任务上分别高出12.8%和14.1%。
总结
总的来说,CV君认为Being-VL这项工作非常亮眼。它不仅仅是提出了一个新模型,更是为解决多模态领域长期存在的"模态鸿沟"问题,提供了一个全新的、统一的视角。将NLP中成熟的BPE思想巧妙地迁移到视觉领域,并通过一系列精心设计的策略使其落地,最终实现了与主流连续派方法相媲美的性能,这本身就是一次成功的探索。
这种统一的Token表示方法,未来甚至有潜力扩展到多模态生成任务,让模型像写文章一样"画画"。
Being-VL获得了ICCV25 highlight,作者会在会场介绍工作,欢迎大家前来探讨工作!!
具体信息:
Exhibit Hall I #1195
Wed 22 Oct 11:15 a.m. HST --- 1:15 p.m. HST
期待看到更多有趣的研究!