数字化时代的故障恢复黄金标准
在当今高度数字化的商业环境中,系统可用性直接关系到企业的生存与发展。一次持续仅几分钟的故障可能导致数百万的收入损失、客户信任度下降和品牌声誉受损。正是在这种背景下,**"1分钟发现,3分钟定位,5分钟解决"**的故障恢复目标成为了互联网企业追求的黄金标准。
这个看似简单的数字目标背后,体现的是现代互联网架构师对系统可观测性的深刻理解和高效实践。本文将深入探讨这一目标的技术实现路径,分析如何通过科学的可观测性架构设计,将理想变为现实。
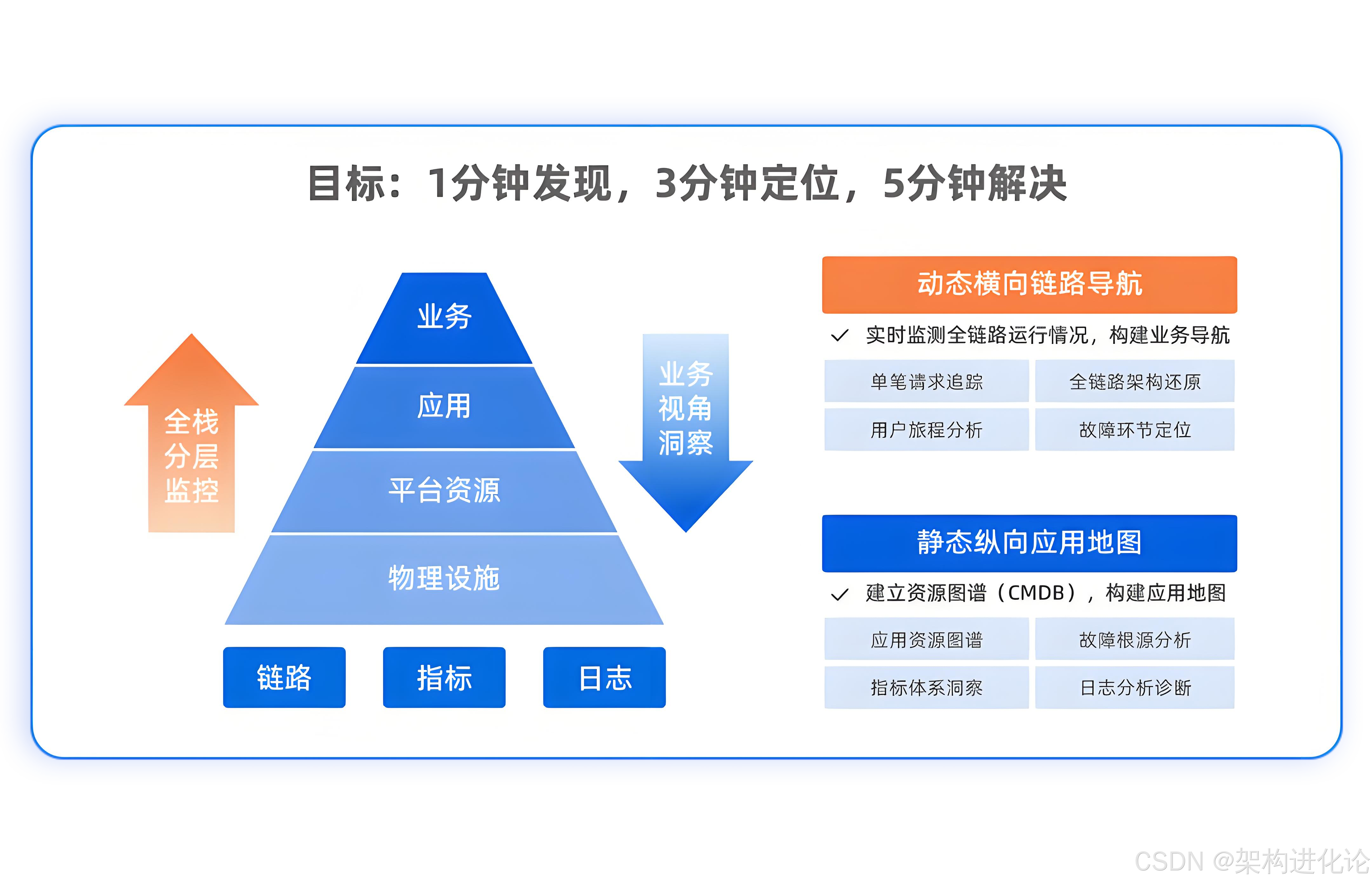
理论基础------"1-3-5"目标的可行性与挑战
故障恢复时间分解的数学原理
"1-3-5"目标建立在严谨的时间分配逻辑上:
-
第1分钟:检测与发现 - 系统需要实时感知异常并发出告警
-
第3分钟:定位与分析 - 快速确定故障范围和根本原因
-
第5分钟:解决与恢复 - 执行修复措施并验证恢复效果
这种时间分配基于人类认知心理学和应急响应理论,符合"快速检测→精准定位→有效解决"的问题处理自然流程。
微服务架构下的特殊挑战
在微服务环境中实现"1-3-5"目标面临独特挑战:
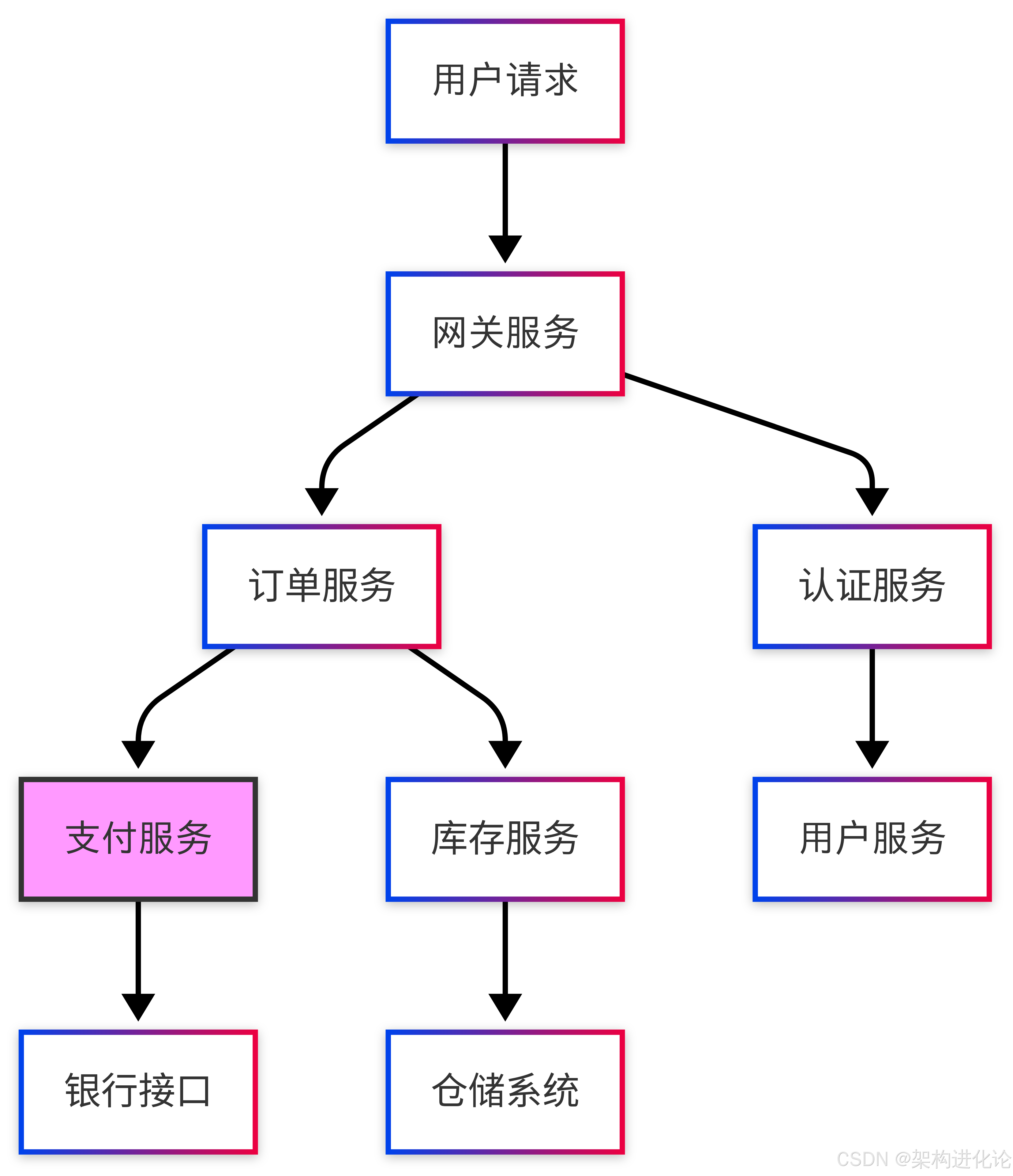
图:微服务架构中故障传播的复杂性。
当支付服务(粉色节点)发生故障时,影响会沿着调用链扩散。
传统单体应用故障定位相对简单,而微服务架构中,一次用户请求可能涉及10+个服务,故障可能出现在任何环节。如果没有完善的可观测体系,运维人员就像在迷宫中寻找出口,难以在3分钟内完成定位。
第一分钟的艺术------从被动响应到主动发现
智能化异常检测体系
实现1分钟发现的关键在于建立多层检测防线:
java
/**
* 智能异常检测系统示例
* 实现多维度、实时性的故障检测
*/
@Component
public class IntelligentDetectionSystem {
@Autowired
private MetricCollector metricCollector;
@Autowired
private AlertManager alertManager;
// 指标异常检测
public void monitorCriticalMetrics() {
// 1. 基础资源监控
monitorResourceMetrics();
// 2. 业务指标监控
monitorBusinessMetrics();
// 3. 依赖服务健康状态监控
monitorDependencyHealth();
}
private void monitorResourceMetrics() {
// CPU使用率异常检测(动态阈值)
double cpuUsage = metricCollector.getCpuUsage();
double dynamicThreshold = calculateDynamicThreshold("cpu_usage");
if (cpuUsage > dynamicThreshold) {
alertManager.sendAlert("CPU_USAGE_HIGH",
String.format("CPU使用率异常: %.2f > %.2f", cpuUsage, dynamicThreshold),
AlertLevel.WARNING);
}
// 内存使用检测
double memoryUsage = metricCollector.getMemoryUsage();
if (memoryUsage > 0.85) { // 85%阈值
alertManager.sendAlert("MEMORY_USAGE_HIGH",
String.format("内存使用率过高: %.2f", memoryUsage),
AlertLevel.CRITICAL);
}
}
private void monitorBusinessMetrics() {
// 业务错误率检测(基于趋势分析)
double errorRate = metricCollector.getErrorRateLast5min();
double historicalAvg = metricCollector.getHistoricalErrorRate();
// 基于3-sigma原理的异常检测
if (errorRate > historicalAvg * 3) {
alertManager.sendAlert("BUSINESS_ERROR_SPIKE",
String.format("业务错误率异常波动: 当前%.4f, 历史平均%.4f",
errorRate, historicalAvg),
AlertLevel.CRITICAL);
}
// 交易量异常检测
long currentTps = metricCollector.getCurrentTPS();
long expectedTps = metricCollector.getExpectedTPS();
if (currentTps < expectedTps * 0.5) {
alertManager.sendAlert("TRANSACTION_DROP",
String.format("交易量异常下降: 当前%d, 预期%d", currentTps, expectedTps),
AlertLevel.CRITICAL);
}
}
private double calculateDynamicThreshold(String metricName) {
// 基于历史数据计算动态阈值,考虑时间周期性
// 例如:工作日高峰期的阈值应高于夜间低谷期
return DynamicThresholdCalculator.calculate(metricName);
}
}告警收敛与智能路由
避免告警风暴是实现1分钟发现的关键挑战:
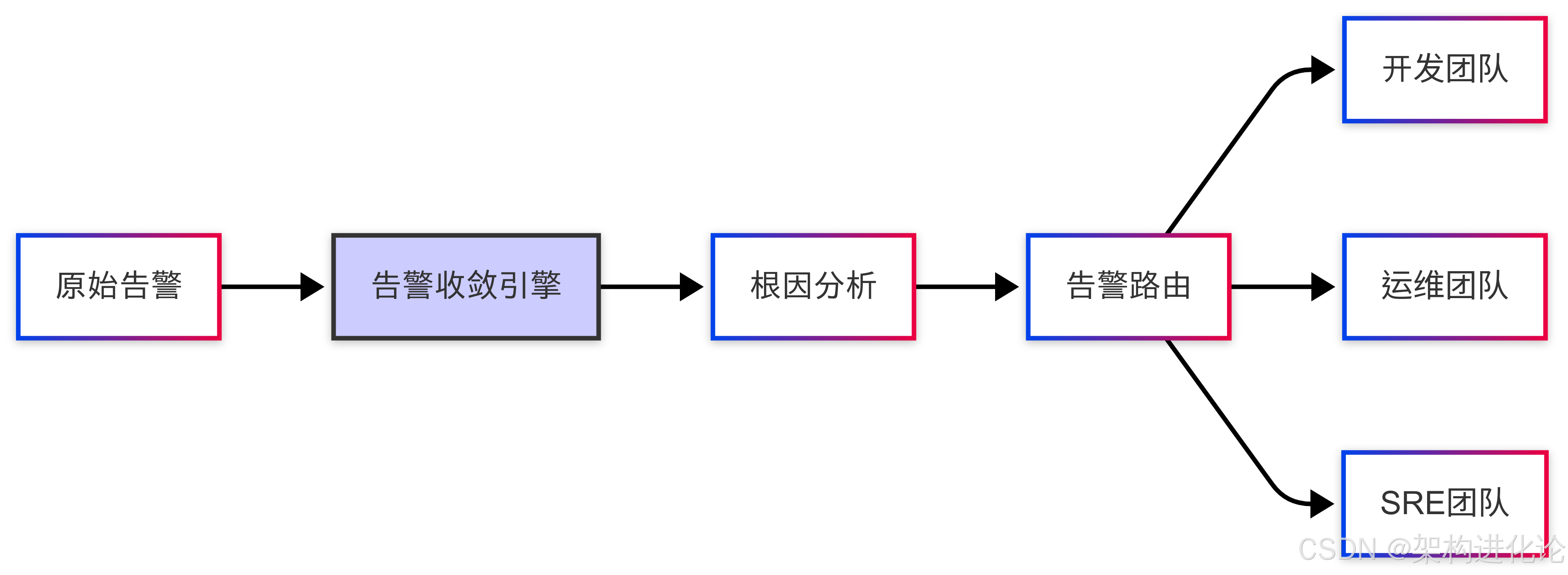
图:告警智能路由流程,避免信息过载
java
/**
* 告警收敛与路由管理器
* 防止告警风暴,确保关键信息及时送达正确人员
*/
@Service
public class AlertConvergenceManager {
private Map<String, AlertGroup> alertGroups = new ConcurrentHashMap<>();
private ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(2);
@PostConstruct
public void init() {
// 定期清理过期告警分组
scheduler.scheduleAtFixedRate(this::cleanupExpiredGroups, 1, 1, TimeUnit.MINUTES);
}
public void processAlert(Alert alert) {
String groupKey = generateGroupKey(alert);
alertGroups.compute(groupKey, (key, group) -> {
if (group == null) {
group = new AlertGroup(alert);
} else {
group.addAlert(alert);
}
return group;
});
// 判断是否达到发送条件
AlertGroup group = alertGroups.get(groupKey);
if (shouldSendImmediately(group) || isTimeToSend(group)) {
sendConvergedAlert(group);
alertGroups.remove(groupKey);
}
}
private String generateGroupKey(Alert alert) {
// 根据告警特征生成分组键
return String.format("%s-%s-%s",
alert.getServiceName(),
alert.getAlertType(),
alert.getSeverity());
}
private boolean shouldSendImmediately(AlertGroup group) {
// 关键告警立即发送
return group.getHighestSeverity() == AlertLevel.CRITICAL;
}
private void sendConvergedAlert(AlertGroup group) {
ConvergedAlert convergedAlert = new ConvergedAlert(group);
// 根据告警类型和级别路由到不同团队
AlertRouter.route(convergedAlert);
// 多通道通知(钉钉、短信、电话)
MultiChannelNotifier.notify(convergedAlert);
}
}三分钟定位的科学------可观测性三要素的协同作战
基于Trace的故障快速定位
实现3分钟定位的核心在于链路追踪的精准分析:
java
/**
* 智能故障定位引擎
* 通过Trace分析快速确定故障范围
*/
@Service
public class FaultLocalizationEngine {
@Autowired
private TraceQueryService traceQueryService;
@Autowired
private MetricService metricService;
public FaultAnalysisResult analyzeFault(String alertId, Duration timeRange) {
long startTime = System.currentTimeMillis();
try {
// 1. 获取相关时间段内的异常Trace
List<Trace> abnormalTraces = traceQueryService.findAbnormalTraces(
timeRange, 1000L); // 1秒以上为慢请求
// 2. 分析Trace模式,识别共同特征
TracePattern pattern = analyzeTracePattern(abnormalTraces);
// 3. 定位故障服务
String faultyService = identifyFaultyService(abnormalTraces);
// 4. 分析故障传播路径
FaultPropagationPath path = analyzePropagationPath(abnormalTraces);
return FaultAnalysisResult.builder()
.faultyService(faultyService)
.pattern(pattern)
.propagationPath(path)
.confidence(calculateConfidence(pattern))
.analysisTime(System.currentTimeMillis() - startTime)
.build();
} catch (Exception e) {
logger.error("故障分析失败: {}", alertId, e);
return FaultAnalysisResult.errorResult(e.getMessage());
}
}
private TracePattern analyzeTracePattern(List<Trace> traces) {
if (traces.isEmpty()) {
return TracePattern.UNKNOWN;
}
// 分析错误类型分布
Map<String, Long> errorCounts = traces.stream()
.flatMap(trace -> trace.getSpans().stream())
.filter(span -> span.hasError())
.collect(Collectors.groupingBy(
Span::getErrorType,
Collectors.counting()
));
// 分析服务延迟分布
Map<String, Double> latencyPercentiles = calculateLatencyPercentiles(traces);
// 识别异常模式(级联失败、单点故障等)
return identifyFailureMode(errorCounts, latencyPercentiles);
}
private String identifyFaultyService(List<Trace> traces) {
// 使用根因分析算法定位故障源
return RootCauseAnalyzer.analyze(traces);
}
}多维数据关联分析
单纯的Trace分析还不够,需要关联日志、指标和事件数据:
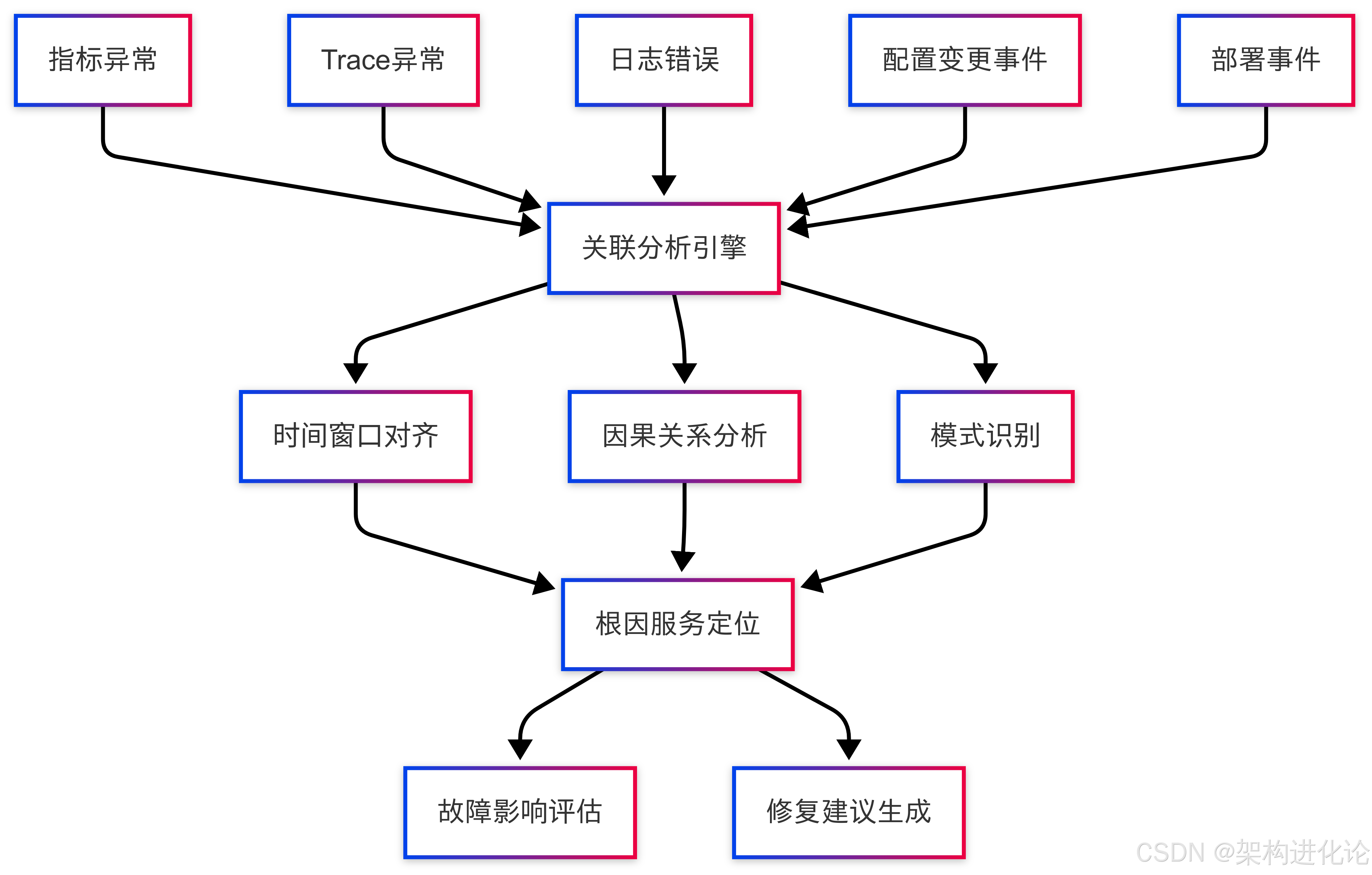
图:多维数据关联分析流程
java
/**
* 多维数据关联分析器
* 关联指标、日志、追踪数据,提高定位准确性
*/
@Component
public class CorrelationAnalyzer {
public CorrelationResult correlateData(Alert alert, Duration timeRange) {
Instant alertTime = alert.getTriggerTime();
Instant startTime = alertTime.minus(timeRange);
Instant endTime = alertTime.plus(Duration.ofMinutes(2));
// 并行获取各类数据
CompletableFuture<MetricData> metricsFuture = getMetricsData(startTime, endTime);
CompletableFuture<List<Trace>> tracesFuture = getTracesData(startTime, endTime);
CompletableFuture<List<LogEntry>> logsFuture = getLogsData(startTime, endTime);
CompletableFuture<List<Event>> eventsFuture = getEventsData(startTime, endTime);
// 等待所有数据就绪
CompletableFuture.allOf(metricsFuture, tracesFuture, logsFuture, eventsFuture)
.join();
try {
MetricData metrics = metricsFuture.get();
List<Trace> traces = tracesFuture.get();
List<LogEntry> logs = logsFuture.get();
List<Event> events = eventsFuture.get();
// 时间窗口对齐和关联分析
return performCorrelationAnalysis(metrics, traces, logs, events, alertTime);
} catch (Exception e) {
logger.error("关联分析失败", e);
throw new AnalysisException("数据关联分析失败", e);
}
}
private CorrelationResult performCorrelationAnalysis(MetricData metrics,
List<Trace> traces,
List<LogEntry> logs,
List<Event> events,
Instant alertTime) {
CorrelationResult result = new CorrelationResult();
// 1. 找到异常开始时间点
Instant anomalyStart = findAnomalyStartTime(metrics, alertTime);
result.setAnomalyStartTime(anomalyStart);
// 2. 分析异常时间点附近的事件
List<Event> relatedEvents = findRelatedEvents(events, anomalyStart);
result.setRelatedEvents(relatedEvents);
// 3. 关联异常Trace和日志
Map<String, List<Object>> serviceAnalysis = analyzeServiceBehavior(
traces, logs, anomalyStart);
result.setServiceAnalysis(serviceAnalysis);
// 4. 计算根因概率
Map<String, Double> rootCauseProbabilities = calculateRootCauseProbabilities(
metrics, traces, logs, events);
result.setRootCauseProbabilities(rootCauseProbabilities);
return result;
}
}五分钟解决的实践------从定位到恢复的自动化
智能修复策略库
实现5分钟解决需要预设修复策略和自动化工具:
java
/**
* 智能修复策略管理器
* 根据故障类型自动匹配合适的修复策略
*/
@Service
public class RemediationStrategyManager {
private Map<FaultType, RemediationStrategy> strategyMap = new HashMap<>();
@PostConstruct
public void initStrategies() {
// 初始化各种故障类型的修复策略
strategyMap.put(FaultType.CPU_HIGH, new CpuHighRemediation());
strategyMap.put(FaultType.MEMORY_LEAK, new MemoryLeakRemediation());
strategyMap.put(FaultType.DATABASE_SLOW, new DatabaseSlowRemediation());
strategyMap.put(FaultType.DEPENDENCY_TIMEOUT, new DependencyTimeoutRemediation());
strategyMap.put(FaultType.CONFIG_ERROR, new ConfigErrorRemediation());
}
public RemediationPlan createRemediationPlan(FaultAnalysisResult analysis) {
FaultType faultType = analysis.getFaultType();
RemediationStrategy strategy = strategyMap.get(faultType);
if (strategy == null) {
strategy = new GenericRemediation(); // 通用修复策略
}
return strategy.createPlan(analysis);
}
}
/**
* 具体修复策略实现:依赖服务超时处理
*/
@Component
public class DependencyTimeoutRemediation implements RemediationStrategy {
@Override
public RemediationPlan createPlan(FaultAnalysisResult analysis) {
String faultyService = analysis.getFaultyService();
return RemediationPlan.builder()
.faultType(FaultType.DEPENDENCY_TIMEOUT)
.description(String.format("依赖服务%s响应超时", faultyService))
.steps(createRemediationSteps(analysis))
.estimatedDuration(Duration.ofMinutes(3))
.riskLevel(RiskLevel.MEDIUM)
.autoExecute(true)
.build();
}
private List<RemediationStep> createRemediationSteps(FaultAnalysisResult analysis) {
List<RemediationStep> steps = new ArrayList<>();
// 步骤1:检查依赖服务健康状态
steps.add(RemediationStep.builder()
.sequence(1)
.action("检查依赖服务健康状态")
.command("curl -f http://" + analysis.getFaultyService() + "/health")
.timeout(Duration.ofSeconds(10))
.build());
// 步骤2:临时流量降级
steps.add(RemediationStep.builder()
.sequence(2)
.action("启用熔断器,降级依赖服务调用")
.command("circuitbreaker enable " + analysis.getFaultyService())
.timeout(Duration.ofSeconds(5))
.build());
// 步骤3:重启问题实例(谨慎操作)
if (analysis.getConfidence() > 0.8) {
steps.add(RemediationStep.builder()
.sequence(3)
.action("重启异常服务实例")
.command("kubectl rollout restart deployment/" + analysis.getFaultyService())
.timeout(Duration.ofMinutes(2))
.confirmationRequired(true) // 需要人工确认
.build());
}
return steps;
}
}自动化修复执行与验证
自动化执行是5分钟解决的关键保障:
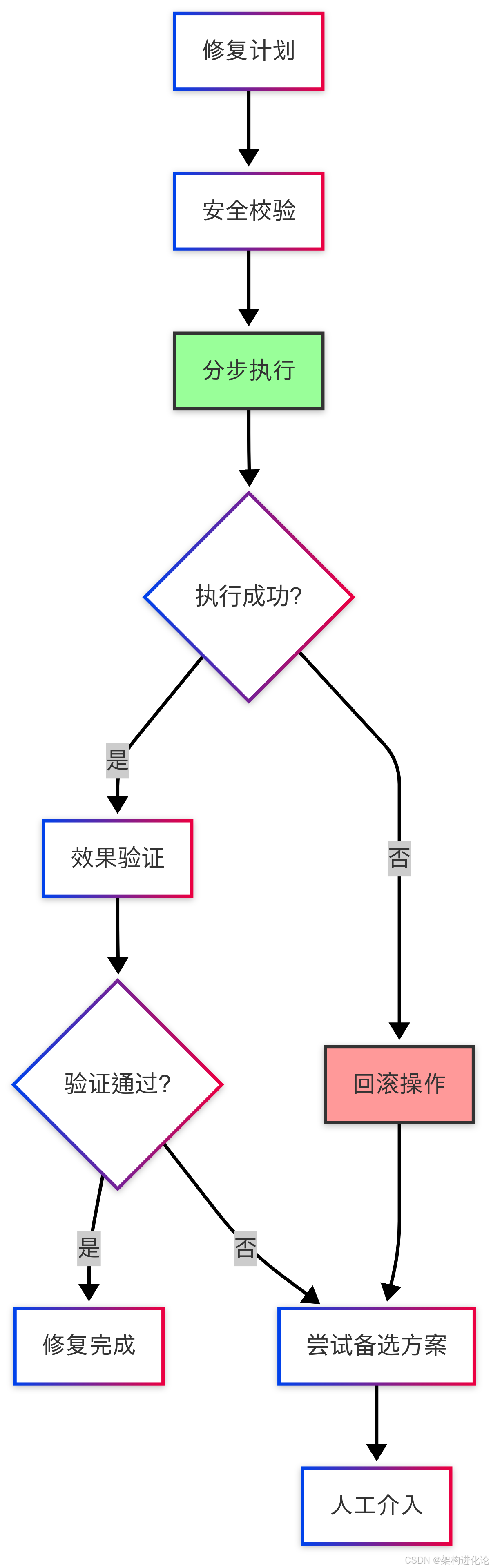
图:自动化修复执行流程,包含安全校验和回滚机制
java
/**
* 自动化修复执行引擎
* 安全、可靠地执行修复操作
*/
@Service
public class AutomatedRemediationEngine {
@Autowired
private RemediationStepExecutor stepExecutor;
@Autowired
private VerificationService verificationService;
public RemediationResult executePlan(RemediationPlan plan) {
logger.info("开始执行修复计划: {}", plan.getDescription());
List<StepResult> stepResults = new ArrayList<>();
boolean overallSuccess = true;
for (RemediationStep step : plan.getSteps()) {
StepResult result = executeStep(step, plan);
stepResults.add(result);
if (!result.isSuccess()) {
logger.error("步骤执行失败: {}", step.getAction());
overallSuccess = false;
// 根据策略决定是否继续
if (step.isCritical()) {
break;
}
}
// 步骤间延迟
if (step.getDelayAfter() > 0) {
try {
Thread.sleep(step.getDelayAfter() * 1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
// 验证修复效果
VerificationResult verification = verifyRemediation(plan);
return RemediationResult.builder()
.plan(plan)
.success(overallSuccess && verification.isSuccess())
.stepResults(stepResults)
.verificationResult(verification)
.completionTime(Instant.now())
.build();
}
private StepResult executeStep(RemediationStep step, RemediationPlan plan) {
try {
// 需要确认的步骤先请求授权
if (step.isConfirmationRequired() && !requestConfirmation(step)) {
return StepResult.skipped("用户取消执行");
}
// 执行具体操作
String output = stepExecutor.execute(step.getCommand(), step.getTimeout());
return StepResult.success(output);
} catch (TimeoutException e) {
logger.error("步骤执行超时: {}", step.getAction());
return StepResult.failed("执行超时");
} catch (Exception e) {
logger.error("步骤执行异常: {}", step.getAction(), e);
return StepResult.failed(e.getMessage());
}
}
private VerificationResult verifyRemediation(RemediationPlan plan) {
// 验证修复效果,确保问题真正解决
return verificationService.verify(plan.getFaultType());
}
}实战案例------电商系统故障的"1-3-5"恢复实践
案例背景:黑色星期五的突发故障
某电商平台在黑色星期五大促期间,突然出现订单提交失败率飙升的紧急故障。
时间线分析:严格的"1-3-5"执行
第一阶段:第1分钟 - 发现与响应
-
00:00 - 监控系统检测到订单失败率 >15% ,并自动触发最高级别(P0)的告警。这体现了主动监控 和明确的告警阈值的重要性。
-
00:15 - 告警智能路由到SRE值班工程师。通过集成钉钉、企业微信或PagerDuty等工具,告警被精准、快速地推送到责任人,避免了在公共频道被淹没。
-
00:45 - 工程师确认告警并开始处理 。值班工程师在45秒内响应并开始介入,表明团队有明确的值班制度和响应职责。
**本阶段核心要素:**全面的监控覆盖、精准的告警机制、高效的告警通知流程。
第二阶段:第3分钟 - 定位与诊断
-
01:00 - 智能分析系统自动关联相关数据。系统自动将订单失败率异常与相关的指标(如应用性能、基础设施状态)进行关联分析,大大缩短了人工排查时间。
-
01:30 - 定位到支付服务响应时间从200ms升至2000ms。通过应用性能监控(APM)工具,迅速将问题范围从"订单"缩小到"支付服务"这个具体组件。
-
02:15 - 根因分析指向支付服务的数据库连接池耗尽。这是最关键的一步,找到了问题的根本原因,而非表面现象。
-
02:45 - 确认影响范围:30%支付请求受影响。准确评估影响面,为决策和沟通提供依据。
本阶段核心要素: 强大的可观测平台(日志、指标、链路追踪)、智能的根因分析工具、经验丰富的SRE团队(扩展阅读:微服务架构的可观测性三要素:从监控到洞察的架构演进)。
第三阶段:第5分钟 - 解决与恢复
-
03:00 - 自动执行连接池扩容修复方案。对于已知的、常见的故障模式,系统可以执行预设的自动化修复剧本(Runbook),这是实现分钟级恢复的关键。
-
03:30 - 系统自动验证修复效果。修复后自动进行健康检查和业务验证,确保问题真正解决,而不仅仅是症状消失。
-
04:00 - 失败率降至正常水平 (<0.5%)。业务指标恢复正常,故障影响被消除。
-
04:30 - 生成故障分析报告。自动化工具开始初步整理事件时间线、指标变化等,为事后复盘做好准备。
**本阶段核心要素:**自动化运维能力、有效的应急预案、闭环的验证流程。
技术细节:全链路可观测性的价值体现
在这个案例中,关键的技术支撑包括:
-
实时指标监控:每10秒采集一次业务指标
-
智能基线计算:考虑大促期间的流量特征
-
分布式追踪:精确识别慢调用链
-
日志实时分析:快速定位错误堆栈
-
自动化修复:预设的扩容策略立即执行
体系建设------打造可持续的"1-3-5"故障恢复能力
组织与文化支撑
技术体系需要配套的组织能力:
-
SRE团队建设:专业的站点可靠性工程师团队
-
on-call轮值制度:7×24小时应急响应能力
-
故障演练文化:定期进行故障注入和应急演练
-
复盘改进机制:每次故障后深度复盘并落实改进
技术架构演进路径
构建"1-3-5"能力需要循序渐进:

图:可观测体系四阶段演进路径
持续优化机制
建立数据驱动的优化闭环:
java
/**
* 故障恢复能力评估与优化系统
* 基于历史数据持续改进恢复效率
*/
@Service
public class RecoveryCapabilityOptimizer {
public void analyzeRecoveryPerformance(Period period) {
List<Incident> incidents = incidentRepository.findByPeriod(period);
RecoveryMetrics metrics = calculateRecoveryMetrics(incidents);
// 识别改进机会点
List<ImprovementOpportunity> opportunities =
identifyImprovementOpportunities(metrics);
// 生成优化建议
generateOptimizationSuggestions(opportunities);
// 跟踪改进效果
trackImprovementEffectiveness(opportunities);
}
private RecoveryMetrics calculateRecoveryMetrics(List<Incident> incidents) {
return RecoveryMetrics.builder()
.avgDetectionTime(calculateAvgDetectionTime(incidents))
.avgLocationTime(calculateAvgLocationTime(incidents))
.avgResolutionTime(calculateAvgResolutionTime(incidents))
.successRate(calculateSuccessRate(incidents))
.automationRate(calculateAutomationRate(incidents))
.build();
}
}结论:从理想走向现实的"1-3-5"可观测性实践
"1分钟发现,3分钟定位,5分钟解决"不仅是故障恢复的目标,更是衡量企业技术成熟度的重要标尺。通过系统的可观测性架构建设、智能化的分析工具和自动化的修复机制,这一目标正在从理想走向现实。
然而,我们需要清醒认识到,"1-3-5"不是终点而是新的起点。随着系统复杂性的持续增加和业务需求的不断变化,可观测体系也需要持续演进。真正的卓越不在于一次达到目标,而在于能够持续保持这种高标准的恢复能力。
未来的可观测性将更加智能化、自动化和预见性。AI技术的深入应用将使系统能够预测故障而不仅仅是响应故障,真正实现从"被动救火"到"主动防火"的转变。在这个过程中,"1-3-5"原则将继续指导我们构建更加稳定、可靠的数字世界。