一、任务排查思路
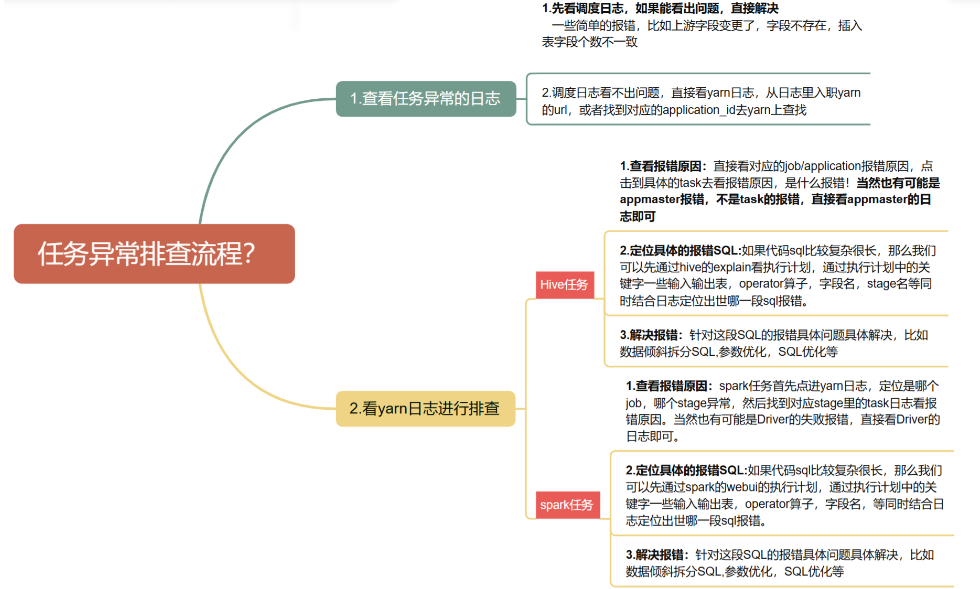 hive引擎会根据shuffle算子把同一个sql划分成多个stage,每个stage都是独立的application运行,这与spark是不同的,spark是多个job复用一个application。
hive引擎会根据shuffle算子把同一个sql划分成多个stage,每个stage都是独立的application运行,这与spark是不同的,spark是多个job复用一个application。
二、Hive任务如何定位异常是哪段具体的sql
select t3.create_date,
count(
case
when t3.login_day = 1 then t3.role_id
end
) as cnt_2,
count(
case
when t3.login_day = 2 then t3.role_id
end
) as cnt_3,
count(
case
when t3.login_day = 6 then t3.role_id
end
) as cnt_7,
count(
case
when t3.login_day = 14 then t3.role_id
end
) as cnt_15,
count(
case
when t3.login_day = 29 then t3.role_id
end
) as cnt_30
from (
select t1.role_id,
t1.create_date,
t2.part_date,
datediff (t2.part_date, t1.create_date) as login_day
from (
select role_id,
min(part_date) as create_date part_da
from ods_game_dev.ods_role_create
group by role_id
) t1
join (
select role_id,
part_date,
min(1) as cnt
from ods_game_dev.ods_user_login
group by role_id,
part_date
) t2 on t1.role_id = t2.role_id
group by t3.create_date初始:
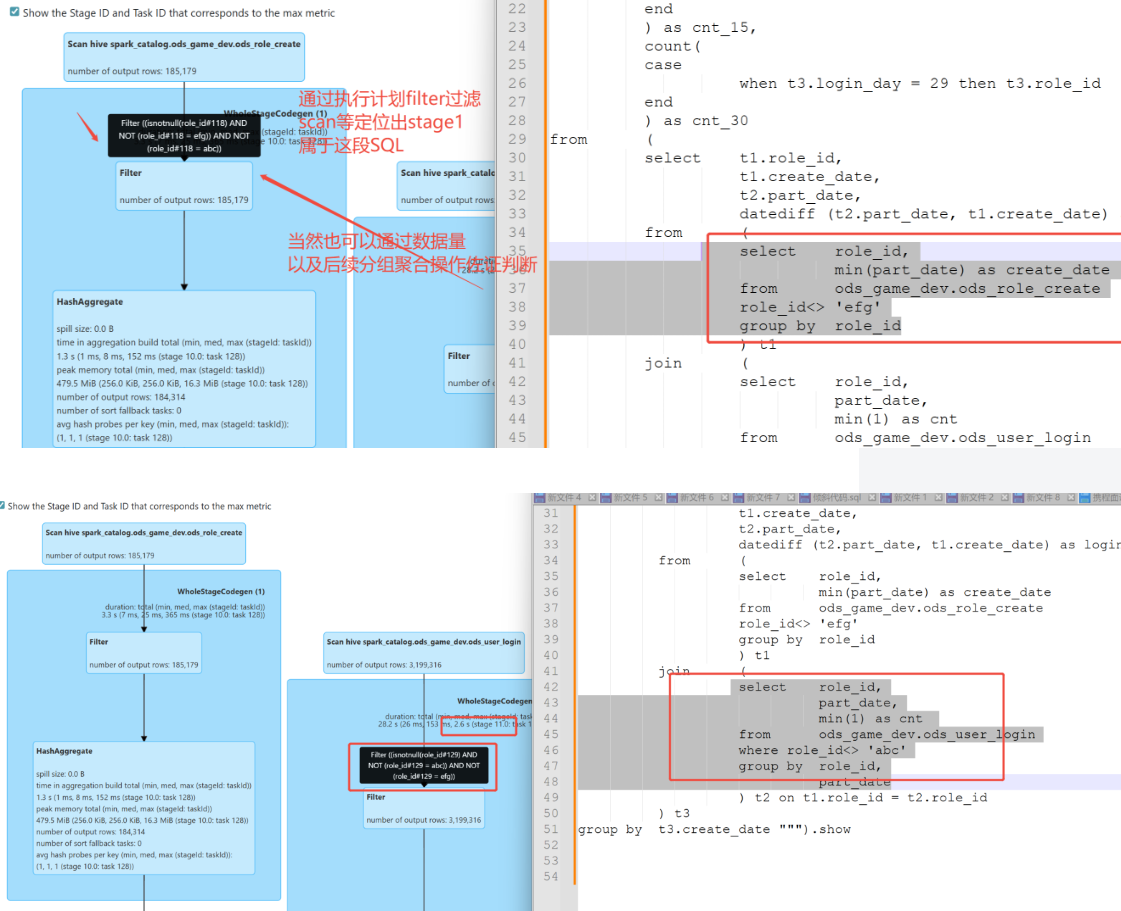
- expain解析hive sql的执行计划。虽然可读性较差,但是可以看出各个任务的依赖。
- expain formatted / expain extended 可以看出更详细的信息
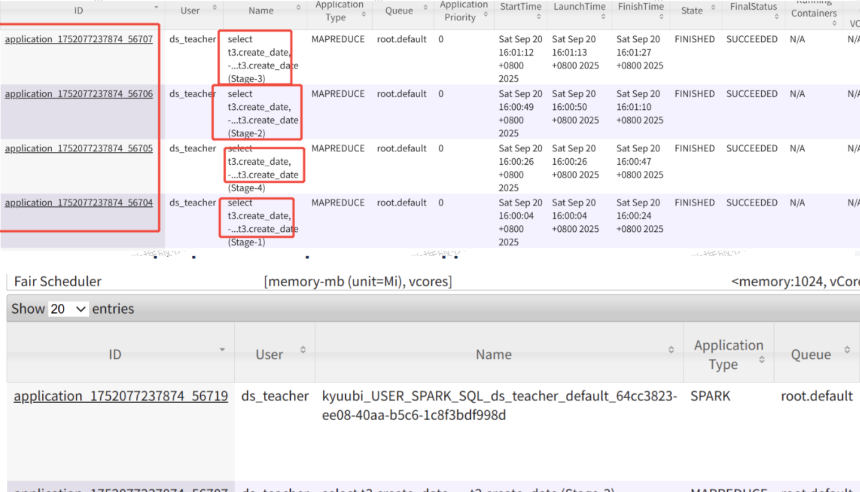
step1
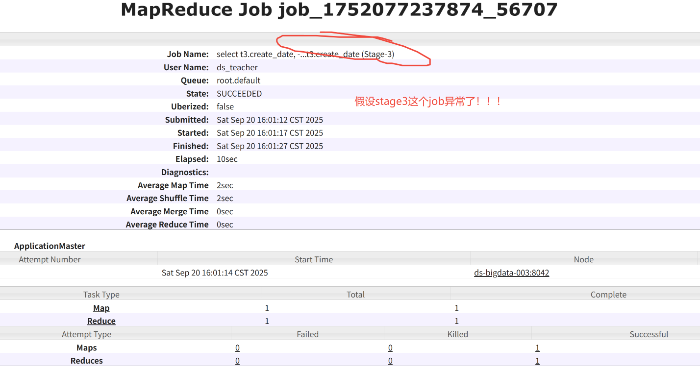
去yarn上看看是哪个stage出现异常
step2
在expain给出的执行计划中看看是哪段sql
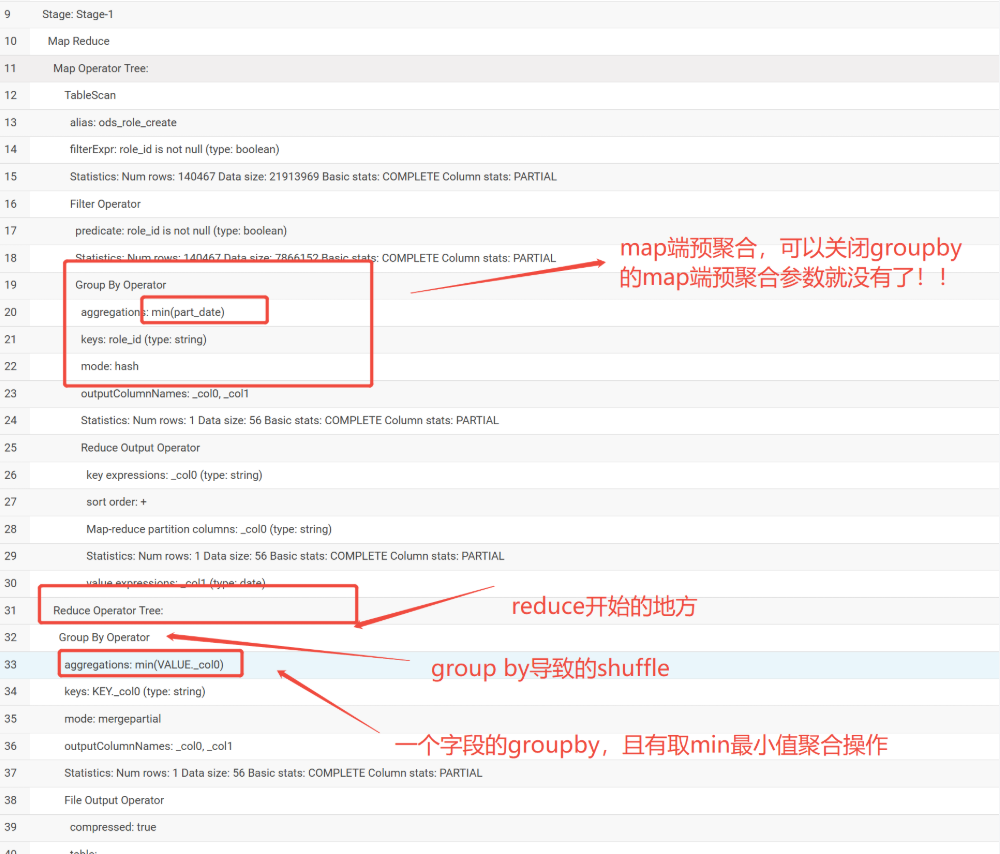
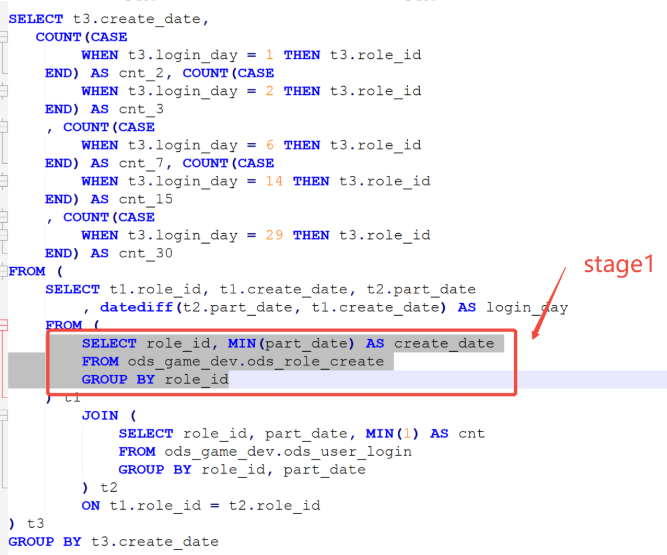
通过上面的关键字段,我们可以定位出stage1是哪段sql,但这不是我们想要的出现异常的stage3
我们可以依据这样定位出stage3是哪段
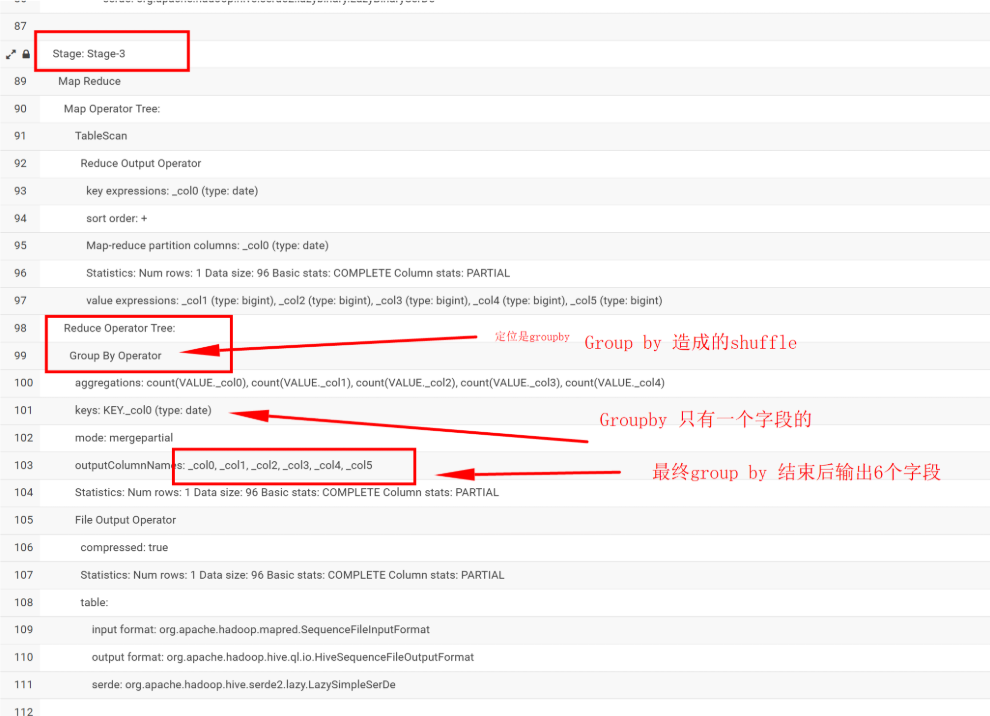

除此之外,还可以看出stage的执行顺序
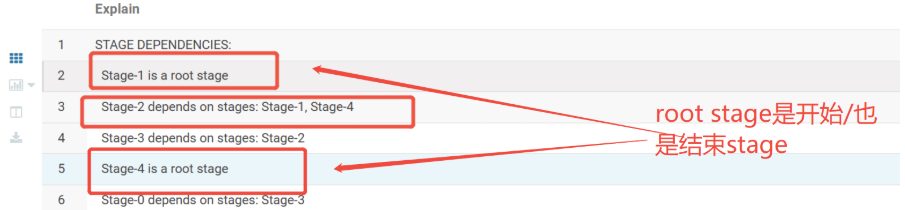
Hive SQL的执行阶段(stage)不是按编号顺序执行,而是按其内部的依赖关系(Dependency)来执行的。编号靠后的stage先执行,是因为它不依赖于编号靠前的stage,或者它是整个执行计划的起点。
- 执行计划是一个有向无环图 (DAG)
当你提交一条Hive SQL后,Hive会先将它解析并优化成一个有向无环图(Directed Acyclic Graph,DAG)。这个图中的每个节点就是一个Stage,箭头表示依赖关系。
Stage:一个Stage通常代表一个独立的计算任务,比如一个MapReduce作业中的Map阶段或Reduce阶段,或者是Tez/Spark中的一个任务组。
依赖关系:箭头从Stage A指向Stage B,意味着stage B的执行需要等待stage A的输出作为其输入。也就是说,Stage A是父亲,Stage B是儿子。 - stageD编号规则与依赖关系的解耦
Hive在为Stage分配编号时,通常遵循某种遍历逻辑(例如深度优先搜索),Hive的执行是看Stage的依赖图(DAG),而不是看它们的编号顺序。编号只是一个标识符,执行顺序由"谁依赖谁"来决定。 没有依赖关系的stage会并行执行,有依赖关系的Stage则顺序执行(上游先于下游)
这种基于依赖关系的执行模型是分布式计算的精髓,主要有两大优势:- 并行化:没有依赖关系的任务可以同时运行,极大地提高了资源利用率和执行速度。就像上面的例子,两个表可以同时被读取和处理。
- 流水线化:数据在一个Stage处理完后会立刻流向下一个Stage,减少了不必要的磁盘I/O和等待时间。
三、Spark任务如何定位异常是哪段具体的sql
| 概念 | 划分依据 | 说明 |
|---|---|---|
| Application | 一段完整的 SQL | 基于 Spark 构建的用户程序。我们提交的一次作业其实就是一个应用 |
| Job | Action | 一个Action产生一个Job。Job是Spark作业调度的最大单位。 |
| Stage | Shuffle (宽依赖) | 一个Job根据宽依赖被划分为多个Stage。Stage是任务执行(Task调度)的单位。每个作业都被分成更小的任务集,称为stage阶段,这些阶段相互依赖(类似于 MapReduce 中的 map 和 reduce 阶段) |
| Executor | container | 为工作节点上的应用程序启动的进程,它运行任务并将数据保存在内存或磁盘存储中 |
| Task | 分区数 | 一个Stage会根据最终RDD的分区数,生成多个Task。每个Task处理一个分区的数据。Task是最终在Executor上执行的工作单元。 |
执行流程简化视图:一条SQL → 遇到Action → 生成一个Job → Job根据宽依赖划分成多个Stage → 每个Stage根据分区数生成多个Task → Task被调度到Executor上并行执行。
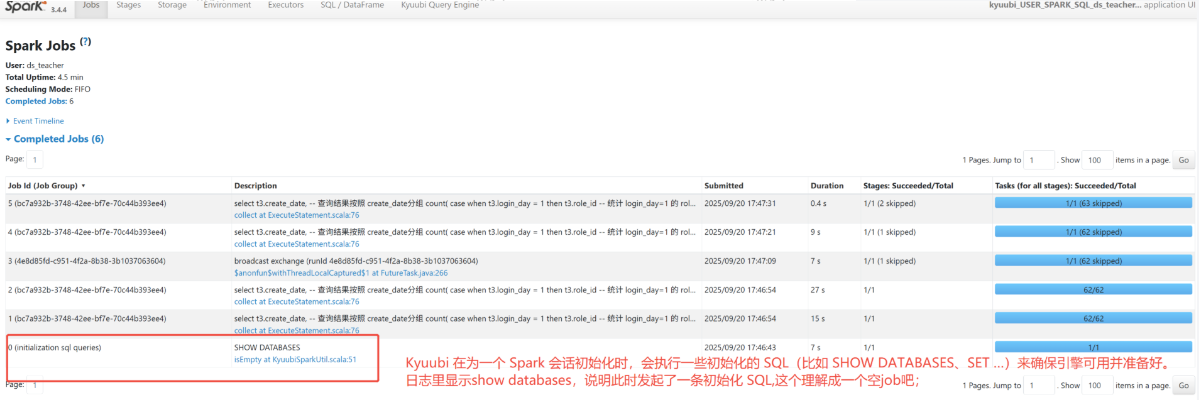
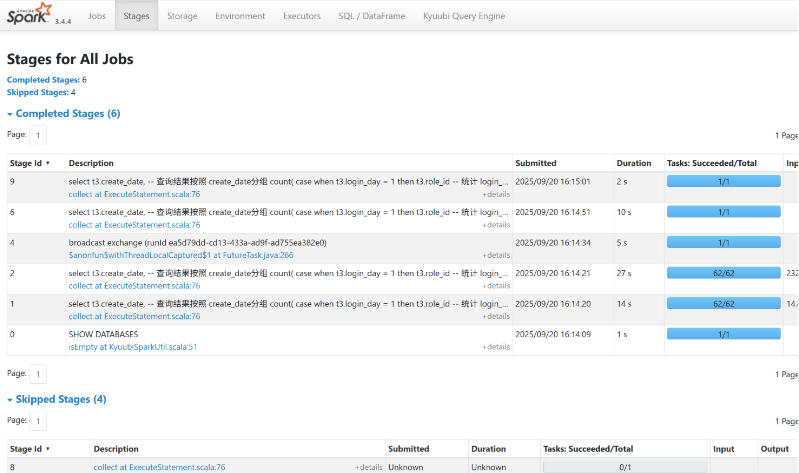
step1
看Spark Web UI的执行计划图
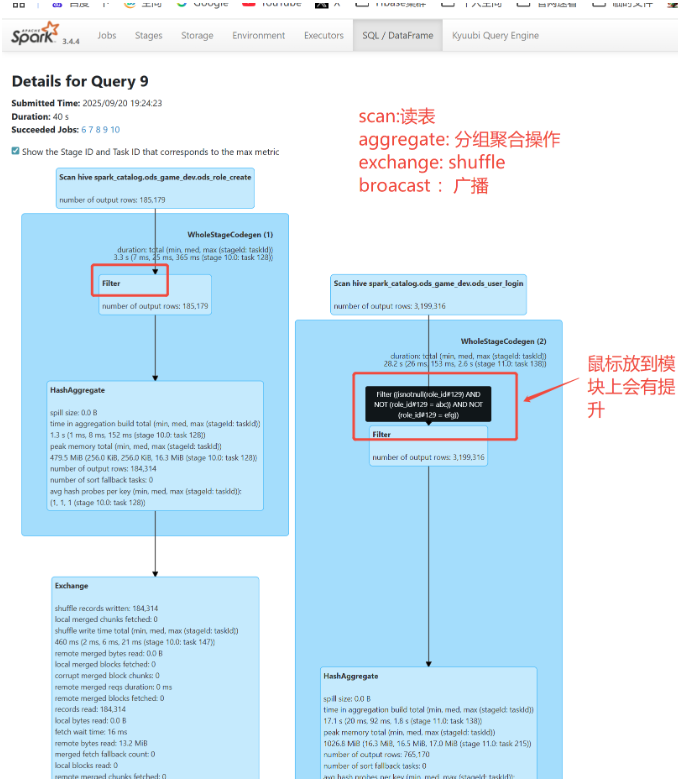
step2
看spark-ul界面的sql整体执行计划定位出Stage10和Stage11,其他依次类推