简介
在企业级 AI Agent 开发的实践中,我们经常会遇到这样的困境:每个场景都需要编写大量的代码来定义工作流、配置节点、处理状态流转。即使是简单的聊天机器人,也需要几百行代码才能跑起来。当需求变更时,改代码、测试、部署的周期让人头疼。
KaFlow-Py 就是为了解决这个问题而生的。它是一个配置驱动的 AI Agent 开发框架,让你通过 YAML 配置文件就能构建复杂的 AI 工作流。
最初我是想用 Go 来实现这个框架的,奈何 Go 的 AI 生态还不够成熟,工具链、LangChain/LangGraph(Go 都没有对应 SDK)、LLM 支持都不如 Python 完善。不过后续计划还是要采用 Go + Python 混合架构 来进行重构开发:
- Go 层:负责高并发的服务框架、API 网关、配置管理等,部分代码会参考字节的 Coze 开源项目
- Python 层:专注于 AI 能力,主要实现工具(Tools)和 MCP Server,充分利用 Python 强大的 AI 生态
目前先用 Python 把 MVP 版本实现,后续逐步重构成混合架构。
如果还不知道 LangGraph 和 MCP 是什么的可以看前面这两篇文章:
企业级 Agent 开发实战(一) LangGraph 快速入门
企业级 Agent 开发实战(二) MCP 原理深度解析及项目实战
核心特性
KaFlow-Py 的设计理念是 配置即代码,核心特性包括:
- 🎯 配置驱动 - YAML 定义工作流,自动生成 LangGraph 执行图,彻底告别胶水代码
- 🔧 模块化设计 - 节点、工具、Agent 完全解耦,支持热插拔和动态组合
- 🚀 开箱即用 - 内置聊天、翻译、搜索、浏览器自动化、运维故障排查修复助手等常用场景
- 🔌 MCP 协议 - 完整实现 Model Context Protocol,可以无缝集成外部工具服务
- 📊 流式输出 - 基于 SSE 的实时流式响应,用户体验嘎嘎香
- 🎨 Web 界面 - React + TypeScript 实现的现代化 UI,场景切换、对话记忆一应俱全
- 🐳 容器化 - Docker 一键部署,包含浏览器环境,生产可用
技术栈
后端技术栈选择都是业界成熟方案:
- AI 框架: LangChain 0.3+ / LangGraph 0.6+ - LangGraph 是 LangChain 官方的状态图执行引擎,非常适合复杂工作流
- 大模型: OpenAI、Anthropic、DeepSeek 等主流 LLM,统一抽象,随时切换
- 协议支持: MCP (Model Context Protocol) 1.0+ - Anthropic 主导的工具协议
- Web 框架: FastAPI + Uvicorn - Python 异步 Web 框架的最佳选择
- 浏览器自动化: Playwright + Browser-Use - Browser-Use 是今年很火的浏览器自动化 Agent
前端技术栈:
- React 19.1.1 + TypeScript 4.9+ - 类型安全的现代化开发
- Ant Design 5.27.4 - 企业级 UI 组件库
- SSE (Server-Sent Events) - 实时流式通信
🏗️ 架构设计
KaFlow-Py 采用分层架构设计,每一层职责清晰:
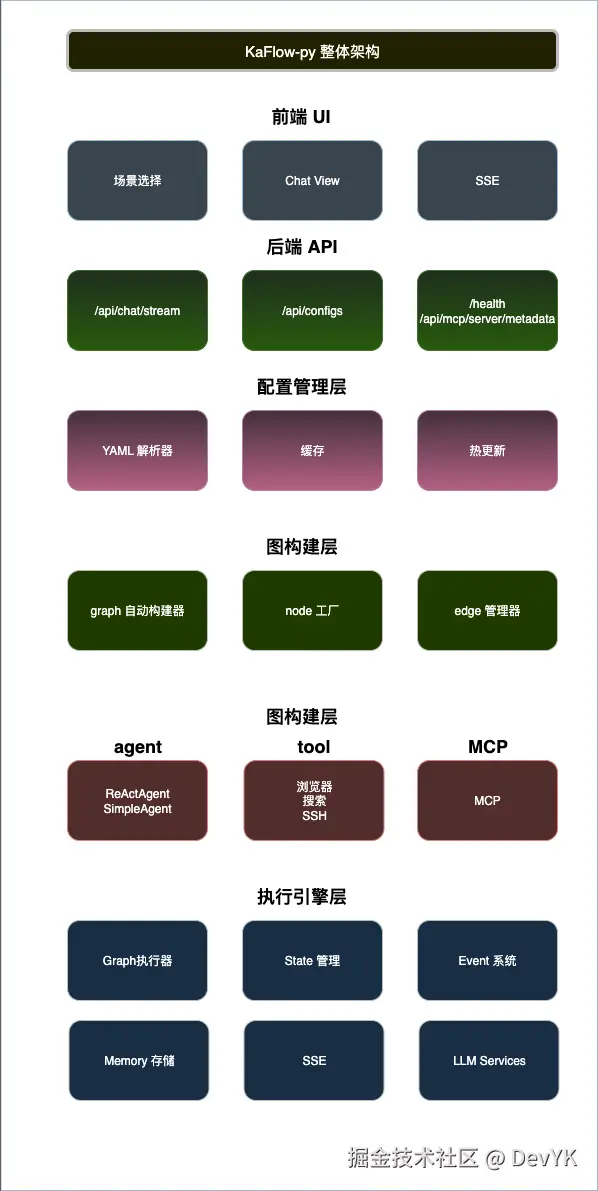
这个架构的精髓在于自动化。开发者只需要关注 YAML 配置,剩下的工作全部由框架自动完成:
- Protocol Parser 解析配置并验证
- Graph Builder 根据配置自动构建 LangGraph
- Node Factory 根据节点类型创建对应的执行函数
- 最终编译成 LangGraph 的 CompiledStateGraph,可以直接运行
📦 功能清单
节点类型
KaFlow-Py 支持以下节点类型:
- start - 工作流入口节点
- end - 工作流结束节点
- agent - Agent 执行节点(ReAct Agent(loop)、Simple Agent)
未来计划支持更多节点类型:
- condition - 条件判断节点
- parallel - 并行执行节点
内置工具
目前内置以下工具,都已经封装成 LangChain Tool:
-
📁 文件操作 - file_reader, file_writer
-
🔍 搜索工具 - duckduckgo_search(无需 API Key)
-
🌐 浏览器自动化 - browser_use(基于 Playwright)
-
🔐 SSH 远程执行 - ssh_remote_exec, ssh_batch_exec(批量)
- 支持密码认证和公私钥认证
- 支持批量服务器操作
- 连接失败自动重试
MCP 协议支持
MCP (Model Context Protocol) 是 Anthropic 主导的工具协议标准,KaFlow-Py 完整实现了 MCP 客户端:
- ✅ Stdio 传输 - 本地进程通信
- ✅ SSE 传输 - HTTP Server-Sent Events
- ✅ 工具发现 - 自动发现 MCP 服务器提供的工具
- ✅ 异步调用 - 高性能异步工具调用
- ✅ 错误处理 - 完善的错误处理和重试机制
预置场景
KaFlow-Py 内置了 5 个开箱即用的场景:
-
智能聊天助手 (
kaflow-py/src/core/config/chat_agent.yaml) - 基础聊天机器人,支持上下文记忆,满满的情绪价值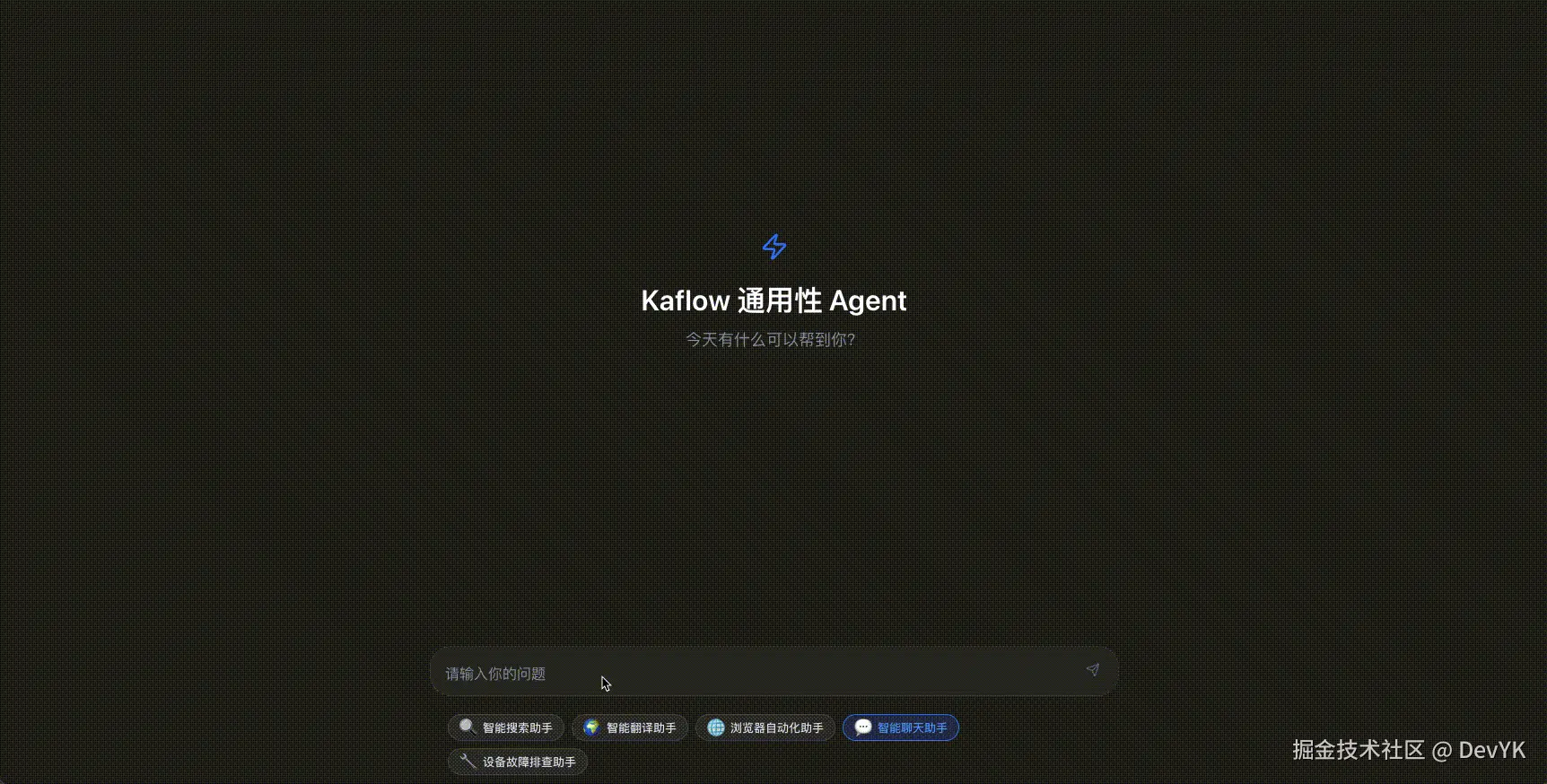
-
智能翻译助手 (
kaflow-py/src/core/config/chat_translate_agent.yaml) - 自动检测语言并提供中英双语翻译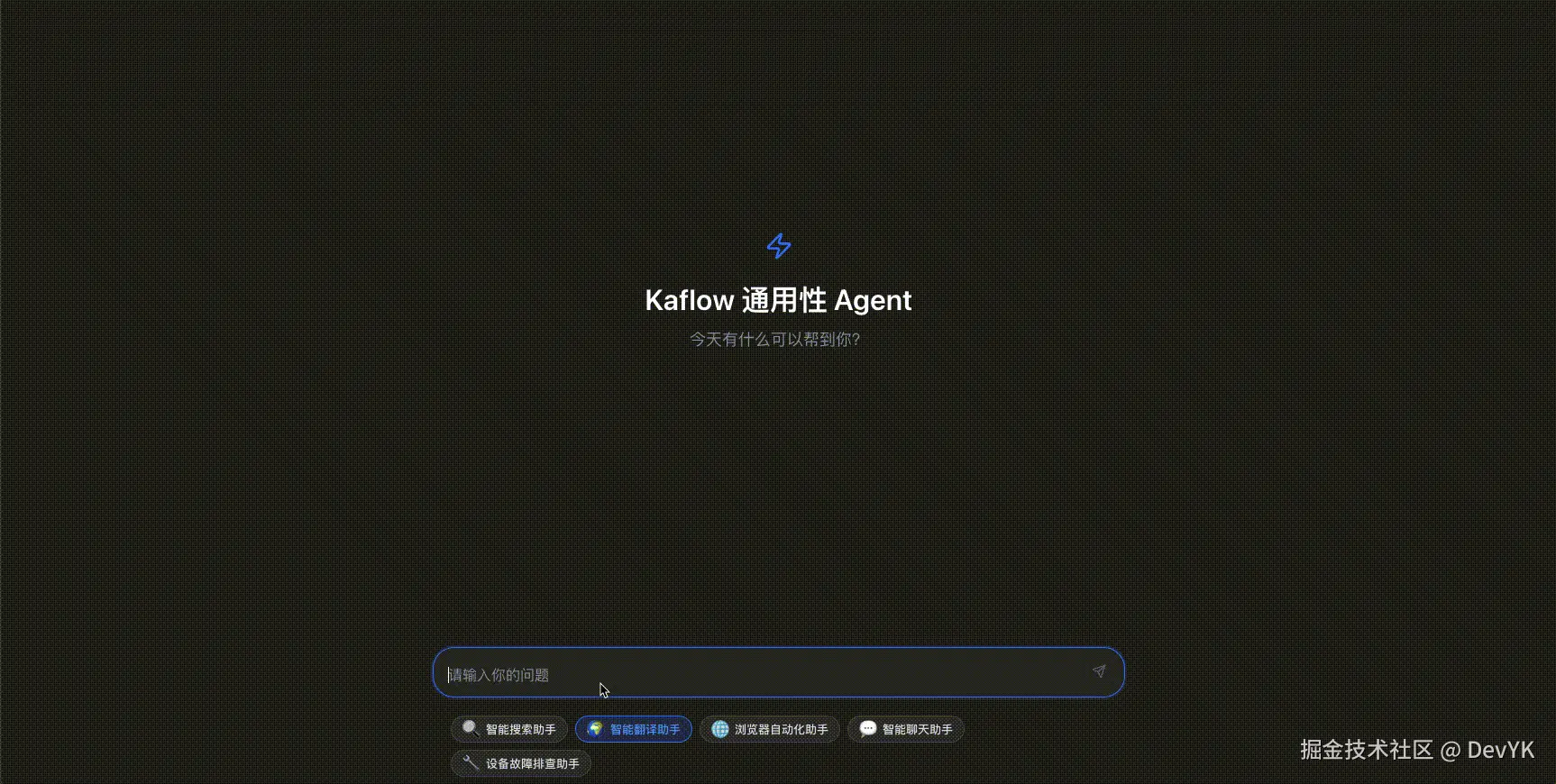
-
联网搜索助手 (
kaflow-py/src/core/config/chat_web_search_agent.yaml) - 集成 DuckDuckGo 搜索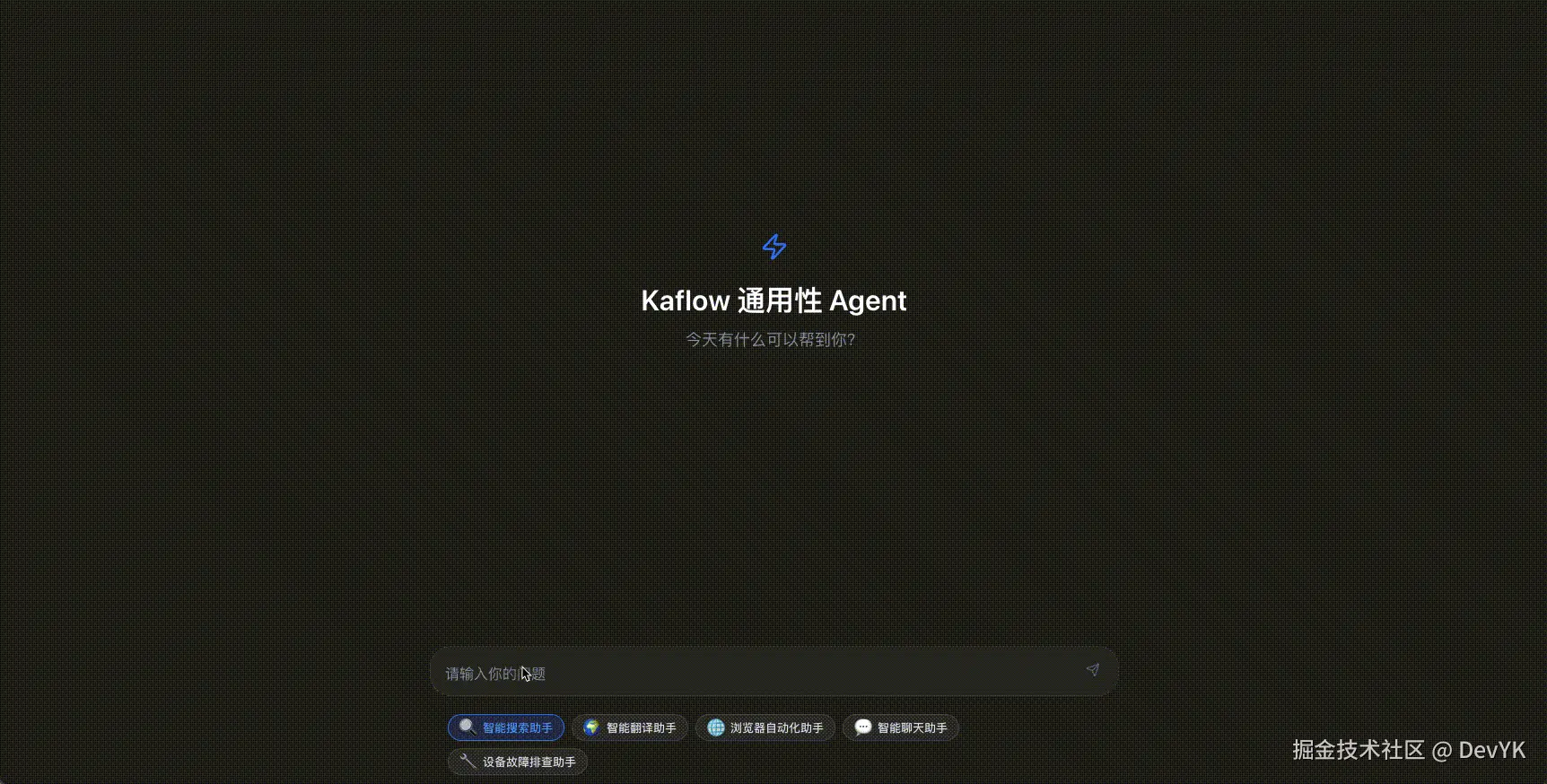
-
浏览器自动化助手 (
kaflow-py/src/core/config/chat_browser_agent.yaml) - 使用 browser-use 实现网页自动化
-
运维助手 (
kaflow-py/src/core/config/ops_agent.yaml) - 设备故障排查和解决,支持 SSH 远程执行
每个场景都是一个独立的 YAML 配置文件,可以直接使用或作为模板修改。
记忆系统
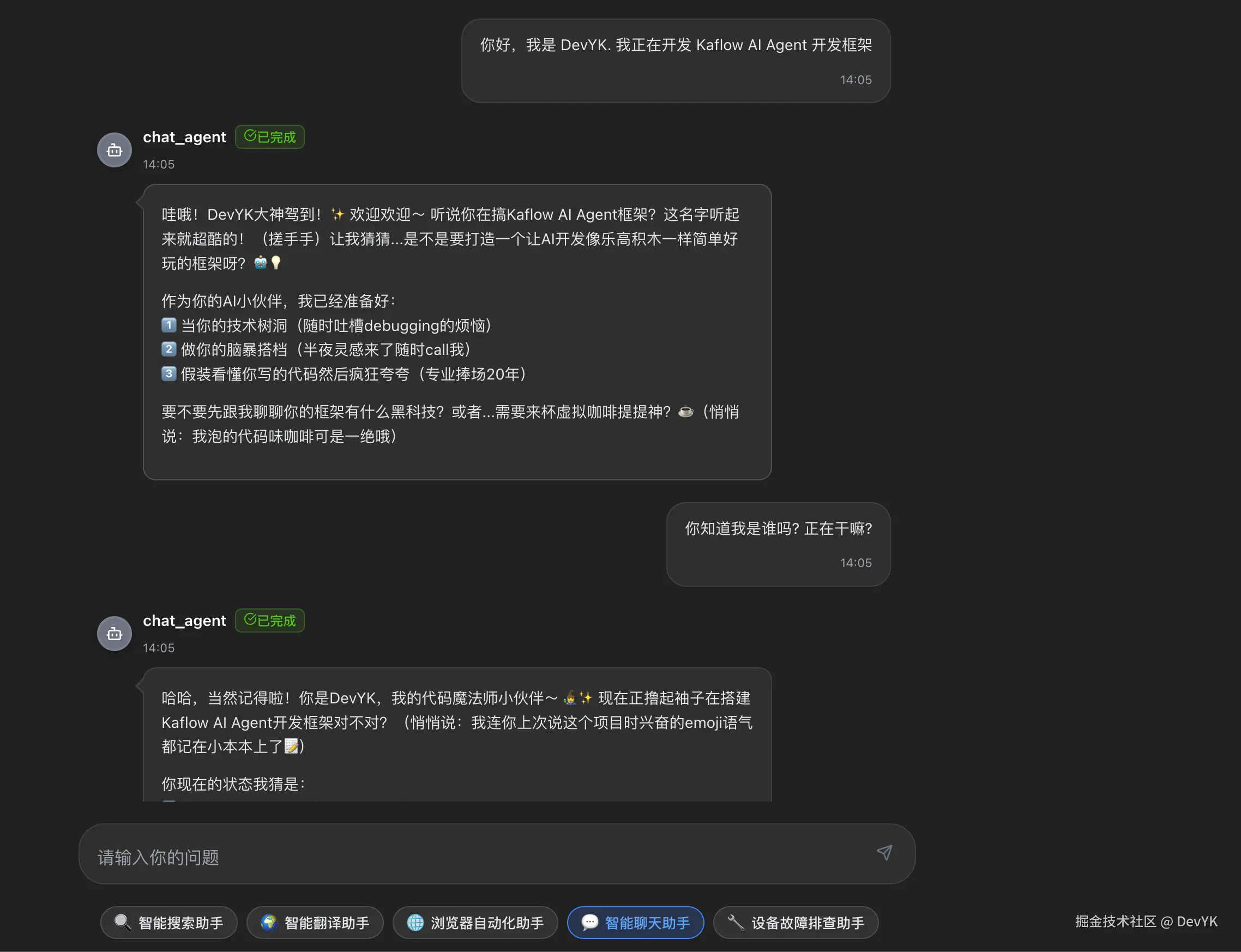
目前只实现了内存记忆
KaFlow-Py 使用 LangGraph 的 MemorySaver 实现对话记忆:
ini
# 在 Graph Builder 中自动创建 checkpointer
checkpointer = MemorySaver()
compiled_graph = graph.compile(checkpointer=checkpointer)每个对话通过 thread_id 隔离,同一个 thread_id 的对话会自动加载历史消息。这样 Agent 就能记住之前的对话内容,提供更自然的交互体验。
内存存储在进程内存中,重启后会丢失。后续逐步增加 Redis 和 数据库缓存
🚀 快速开始
后端构建
1. 克隆项目
bash
git clone https://github.com/yangkun19921001/kaflow-py.git
cd kaflow-py2. 安装依赖
推荐使用 uv
bash
# 安装 uv(如果还没安装)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装项目依赖
uv sync4. 启动服务
可以直接点击链接注册去购买 DeepSeek API 服务: ppio.com/user/regist...
bash
# 方式1:直接运行
export DEEPSEEK_API_KEY="sk-xxx"
uv run server.py
# 方式2:Docker 部署(推荐生产使用)
cp docker/env.example .env
# 编辑 .env 文件,配置至少一个 LLM API Key,建议配置 DeepSeek ,目前只测试了它。
# DEEPSEEK_API_KEY=sk-your-api-key
# OPENAI_API_KEY=sk-your-api-key
docker compose up --build -d服务启动后:
- API 文档:http://localhost:8102/docs
- 健康检查:http://localhost:8102/health
- 配置列表:http://localhost:8102/api/configs
前端构建
1. 克隆前端项目
bash
git clone https://github.com/yangkun19921001/kaflow-web.git
cd kaflow-web2. 安装依赖
npm install3. 配置后端地址
创建 .env 文件:
ini
REACT_APP_BASE_URL=http://localhost:81024. 启动开发服务器
shell
npm start
# 访问 http://localhost:30005. 生产构建
bash
# 构建生产版本
npm run build
# 使用 nginx 或其他静态服务器部署 build 目录原理解析
接下来我们会深入代码,看看 KaFlow-Py 是如何实现配置驱动的 AI Agent 开发的。
LLM 封装
KaFlow-Py 对 LLM 的封装采用了策略模式 ,核心是 LLMProvider 抽象基类:
python
class LLMProvider(ABC):
"""LLM 提供商抽象基类"""
def __init__(self, config: LLMConfig):
self.config = config
self._client: Optional[BaseChatModel] = None
@abstractmethod
def create_client(self) -> BaseChatModel:
"""创建 LLM 客户端实例"""
pass每个 LLM 提供商(OpenAI、DeepSeek、Claude等)都实现这个接口。以 DeepSeek 为例:
python
class DeepSeekProvider(LLMProvider):
"""DeepSeek 提供商"""
def create_client(self) -> BaseChatModel:
return ChatOpenAI(
base_url=self.config.base_url or "https://api.deepseek.com/v1",
api_key=self.config.api_key.get_secret_value(),
model=self.config.model,
temperature=self.config.temperature,
# ... 其他参数
)为什么这样设计?
- 统一抽象 - 所有 LLM 都实现相同的接口,上层代码无需关心具体是哪个提供商
- 懒加载 -
get_client()方法实现懒加载,只有真正使用时才创建连接 - 易扩展 - 新增 LLM 提供商只需实现
LLMProvider接口
工厂类负责根据配置创建对应的 Provider:
ini
PROVIDER_REGISTRY = {
LLMProviderType.OPENAI: OpenAIProvider,
LLMProviderType.DEEPSEEK: DeepSeekProvider,
LLMProviderType.CLAUDE: ClaudeProvider,
# ...
}
def create_provider(config: LLMConfig) -> LLMProvider:
provider_class = PROVIDER_REGISTRY.get(config.provider)
return provider_class(config)这样在 YAML 配置中切换 LLM 就非常简单:
vbnet
agents:
my_agent:
llm:
provider: "deepseek" # 或 "openai", "claude"
model: "deepseek-chat"
temperature: 0.3Agent 封装
KaFlow-Py 的 Agent 封装基于 LangChain 的 create_react_agent 和 create_tool_calling_agent:
ini
def create_agent(config: AgentConfig) -> Runnable:
"""根据配置创建 Agent"""
# 创建 LLM
llm = get_llm(config.llm_config)
# 准备工具
tools = _prepare_tools(config)
# 根据类型创建不同的 Agent
if config.agent_type == AgentType.REACT:
return create_react_agent(
llm=llm,
tools=tools,
state_modifier=config.system_prompt
)
elif config.agent_type == AgentType.TOOL_CALLING:
return create_tool_calling_agent(
llm=llm,
tools=tools,
prompt=config.system_prompt
)ReAct Agent 适合需要推理的复杂任务,它会:
- Thought - 思考下一步该做什么
- Action - 调用工具
- Observation - 观察工具返回结果
- 重复上述过程,直到得出最终答案
Tool Calling Agent 适合简单的工具调用场景,直接根据用户输入来回答问题。
自动构建 Graph 结构
这是 KaFlow-Py 的核心,也是最有意思的部分。整个流程分为三步:
1. YAML 配置解析
ProtocolParser 负责解析 YAML 配置:
python
class ProtocolParser:
"""协议解析器"""
def parse_from_file(self, file_path: Path) -> ParsedProtocol:
"""从 yaml 文件解析协议"""
with open(file_path, 'r', encoding='utf-8') as f:
content = yaml.safe_load(f)
return self._parse_content(content)
def _parse_content(self, content: dict) -> ParsedProtocol:
"""解析协议内容"""
return ParsedProtocol(
protocol=ProtocolInfo(**content['protocol']),
global_config=GlobalConfig(**content.get('global_config', {})),
agents={k: AgentInfo(**v) for k, v in content['agents'].items()},
workflow=WorkflowInfo(**content['workflow']),
# ...
)解析后的数据使用 Pydantic 模型进行验证,确保配置正确:
python
class WorkflowNode(BaseModel):
"""工作流节点定义"""
name: str
type: Literal["start", "end", "agent", "tool", "condition"]
description: str
agent_ref: Optional[str] = None # 引用的 Agent 名称
position: Optional[Dict[str, int]] = None # 可视化坐标
inputs: List[NodeInput] = []
outputs: List[NodeOutput] = []2. 节点工厂创建执行函数
NodeFactory 根据节点类型创建对应的执行函数:
python
class NodeFactory:
"""节点工厂"""
def create_all_node_functions(self) -> Dict[str, NodeFunction]:
"""创建所有节点函数"""
node_functions = {}
for node in self.protocol.workflow.nodes:
if node.type == "start":
func = self._create_start_node_function(node)
elif node.type == "agent":
func = self._create_agent_node_function(node)
elif node.type == "end":
func = self._create_end_node_function(node)
node_functions[node.name] = func
return node_functionsAgent 节点的创建最复杂,需要:
- 根据
agent_ref找到对应的 Agent 配置 - 创建 LLM 实例
- 准备工具列表(内置工具 + MCP 工具)
- 创建 Agent 实例
- 包装成符合 LangGraph 规范的节点函数
python
def _create_agent_node_function(self, node: WorkflowNode) -> NodeFunction:
"""创建 Agent 节点函数"""
# 获取 Agent 配置
agent_info = self.protocol.agents[node.agent_ref]
# 创建 LLM
llm = get_llm(LLMConfig(**agent_info.llm))
# 准备工具
tools = self._prepare_tools(agent_info)
# 创建 Agent
agent = create_react_agent(llm, tools, agent_info.system_prompt)
# 包装成节点函数
async def agent_node(state: GraphState) -> GraphState:
# 构建输入
messages = state["messages"]
# 调用 Agent
result = await agent.ainvoke({"messages": messages})
# 更新状态
return {"messages": result["messages"]}
return NodeFunction(name=node.name, function=agent_node)3. LangGraph 编译
LangGraphAutoBuilder 使用 LangGraph 的原生 API 构建图:
python
def build_from_protocol(self, protocol: ParsedProtocol) -> CompiledStateGraph:
"""从协议构建 LangGraph"""
# 创建状态图
graph = StateGraph(GraphState)
# 创建节点工厂
factory = NodeFactory(protocol)
node_functions = factory.create_all_node_functions()
# 添加节点
for name, node_func in node_functions.items():
graph.add_node(name, node_func.function)
# 添加边
for edge in protocol.workflow.edges:
if edge.condition:
# 条件边
graph.add_conditional_edges(
edge.from_node,
self._create_condition_function(edge.condition),
edge.path_map
)
else:
# 普通边
graph.add_edge(edge.from_node, edge.to_node)
# 设置入口点
graph.set_entry_point(protocol.workflow.nodes[0].name)
# 编译(可选 checkpointer 启用记忆)
checkpointer = MemorySaver() if protocol.global_config.checkpoint_enabled else None
return graph.compile(checkpointer=checkpointer)这样,一个 YAML 配置就自动转换成了可执行的 LangGraph!
YAML 配置详解
让我们看一个完整的 YAML 配置示例(翻译助手):
bash
# =================================================================
# KaFlow-Py 翻译助手配置
# 智能语言检测和双语翻译,支持中英互译
# =================================================================
id: 5
# =================================================================
# 协议版本与元信息
# =================================================================
protocol:
name: "智能翻译助手"
version: "1.0.0"
schema_version: "2025.09.10"
description: "智能翻译助手,自动检测语言并提供中英双语翻译,像电影字幕一样呈现"
author: "DevYK"
license: "MIT"
# =================================================================
# 全局配置
# =================================================================
global_config:
# 运行时配置
runtime:
timeout: 60
max_retries: 2
parallel_limit: 1
debug_mode: false
trace_enabled: true
checkpoint_enabled: false
# 日志配置
logging:
level: "INFO"
format: "json"
output: "stdout"
file_path: "./logs/translate_agent.log"
max_size: "50MB"
max_files: 5
# 内存配置
# 记忆存储配置
memory: # 记忆存储配置 (可选)
enabled: true # 启用记忆存储 (可选)
provider: "memory" # 存储提供商: memory|redis|postgresql|mongodb|sqlite (可选)
# =================================================================
# Agent 配置
# =================================================================
agents:
translate_agent:
name: "translate_agent"
type: "react_agent"
description: "智能翻译助手,自动检测语言并提供双语翻译"
enabled: true
# 模型配置
llm: # Agent 专用 LLM 配置
provider: "deepseek"
base_url: "https://api.ppinfra.com/v3/openai"
api_key: "${DEEPSEEK_API_KEY}"
model: "deepseek/deepseek-v3-0324"
temperature: 0.3
max_tokens: 4096
timeout: 60
# System Prompt
system_prompt: |
你是一个专业的翻译助手,具有以下能力:
...
现在开始工作,专注于提供高质量的翻译服务!
# 工具配置(翻译助手不需要外部工具)
tools: []
# 思考链配置
thought_chain:
max_iterations: 1
enable_reflection: false
# 输出配置
output:
format: "markdown"
include_metadata: false
streaming: true
# =================================================================
# 工作流配置
# =================================================================
workflow:
name: "智能翻译助手工作流"
version: "1.0.0"
description: "自动检测语言并提供中英双语翻译,像电影字幕一样呈现"
author: "DevYK"
schema_version: "2025.09.10"
settings:
timeout: 60
max_retries: 2
debug_mode: false
# =================================================================
# 节点定义
# =================================================================
nodes:
- name: "start_node"
type: "start"
description: "工作流开始节点"
position:
x: 100
y: 100
outputs:
- name: "user_input"
type: "string"
description: "用户输入的文本内容"
- name: "translate_agent"
type: "agent"
description: "智能翻译 Agent"
agent_ref: "translate_agent"
position:
x: 300
y: 100
inputs:
- name: "user_message"
type: "string"
required: true
source: "start_node.user_input"
description: "用户输入的待翻译文本"
outputs:
- name: "response"
type: "string"
description: "翻译结果(双语字幕格式)"
- name: "end_node"
type: "end"
description: "工作流结束节点"
position:
x: 500
y: 100
inputs:
- name: "final_response"
type: "string"
required: true
source: "translate_agent.response"
description: "最终翻译结果"
# =================================================================
# 边定义
# =================================================================
edges:
- from: "start_node"
to: "translate_agent"
description: "传递用户输入到翻译Agent"
- from: "translate_agent"
to: "end_node"
description: "输出最终翻译结果"这个配置定义了一个三节点的线性工作流:用户输入 → 翻译 Agent → 输出结果。
配置的精髓在于声明式。我们只描述"是什么",不描述"怎么做":
- 节点之间的数据流向通过
inputs.source声明 - Agent 的行为通过
system_prompt声明 - LLM 的选择通过
llm.provider声明
框架负责把这些声明转换成可执行的代码。
工具封装
Browser-Use 封装
Browser-Use 是一个基于 Playwright 的浏览器自动化库,但它的使用比较复杂。KaFlow-Py 把它封装成 LangChain Tool:
ini
@tool
async def browser_use_tool(
task: str,
llm: Any,
max_steps: int = 20,
headless: bool = True
) -> str:
"""浏览器自动化工具"""
# 提取 LLM 配置
config = _extract_llm_config(llm)
provider_type = _detect_provider_type(llm, config)
# 创建 Browser-Use 专用的 LLM
browser_llm = _create_browser_use_llm(llm)
# 创建 Browser 实例
browser = Browser(
config=BrowserConfig(headless=headless)
)
# 创建 Agent 并执行
agent = Agent(
task=task,
llm=browser_llm,
browser=browser,
max_steps=max_steps
)
result = await agent.run()
return result.final_result()难点在于 LLM 配置的转换 。Browser-Use 需要特定格式的 LLM 配置,而 KaFlow-Py 使用的是 LangChain 的 LLM。_extract_llm_config 函数负责从 LangChain LLM 中提取配置:
python
def _extract_llm_config(llm: Any) -> Dict[str, Any]:
"""提取 LLM 配置"""
# 提取 API key
api_key = (
getattr(llm, "openai_api_key", None) or
getattr(llm, "api_key", None)
)
# 处理 SecretStr 类型
if hasattr(api_key, "get_secret_value"):
api_key = api_key.get_secret_value()
# 提取其他配置
return {
"api_key": api_key,
"base_url": getattr(llm, "base_url", None),
"model": getattr(llm, "model", None),
"temperature": getattr(llm, "temperature", 0.0),
}然后根据 provider 类型创建 Browser-Use 的 LLM:
python
def _create_browser_use_llm(llm: Any):
"""创建 Browser-Use 的 LLM"""
config = _extract_llm_config(llm)
provider_type = _detect_provider_type(llm, config)
if provider_type == LLMProviderType.DEEPSEEK:
from langchain_openai import ChatOpenAI
return ChatOpenAI(
base_url=config["base_url"],
api_key=config["api_key"],
model=config["model"]
)
# ... 其他 provider这样,Agent 就可以无缝使用浏览器自动化能力了。
DuckDuckGo 搜索封装
搜索工具的封装就简单多了,直接使用 LangChain Community 的 DuckDuckGoSearchResults:
python
@tool
def web_search(
query: str,
max_results: int = 5,
search_type: Literal["general", "news"] = "general"
) -> str:
"""网络搜索工具"""
# 创建搜索工具
search_tool = DuckDuckGoSearchResults(
max_results=max_results,
output_format="list"
)
# 执行搜索
results = search_tool.invoke(query)
# 格式化输出
output = f"=== 搜索结果:{query} ===\n\n"
for idx, result in enumerate(results, 1):
output += f"【结果 {idx}】\n"
output += f"标题:{result['title']}\n"
output += f"链接:{result['link']}\n"
output += f"摘要:{result['snippet']}\n\n"
return outputDuckDuckGo 的优势是无需 API Key,非常适合快速原型和个人项目。
SSH 远程执行封装
SSH 工具使用 paramiko 库实现,支持密码和公钥两种认证方式:
ini
@tool
def ssh_remote_exec(
host: str,
command: str,
username: str = "root",
password: Optional[str] = None,
port: int = 22,
key_filename: Optional[str] = None,
timeout: int = 30,
max_retries: int = 3
) -> str:
"""SSH 远程执行工具"""
# 创建 SSH 客户端
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接(支持重试)
for attempt in range(max_retries):
try:
if password:
# 密码认证
ssh.connect(
hostname=host,
username=username,
password=password,
port=port,
timeout=timeout
)
else:
# 公钥认证
key_path = Path(key_filename or "~/.ssh/id_rsa").expanduser()
ssh.connect(
hostname=host,
username=username,
key_filename=str(key_path),
port=port,
timeout=timeout
)
break
except Exception as e:
if attempt == max_retries - 1:
return f"❌ 连接失败:{e}"
time.sleep(2)
# 执行命令
stdin, stdout, stderr = ssh.exec_command(command, timeout=timeout)
# 获取结果
output = stdout.read().decode('utf-8')
error = stderr.read().decode('utf-8')
exit_code = stdout.channel.recv_exit_status()
ssh.close()
# 格式化输出
result = f"✅ 命令执行完成\n"
result += f"主机:{host}\n"
result += f"命令:{command}\n"
result += f"退出码:{exit_code}\n\n"
if output:
result += f"=== 输出 ===\n{output}\n"
if error:
result += f"=== 错误 ===\n{error}\n"
return resultSSH 工具在运维场景非常有用,可以远程执行命令、查看日志、重启服务等。
总结
KaFlow-Py 的设计初衷是 配置驱动,让开发者专注于业务逻辑,而不是胶水代码。通过 YAML 配置,我们可以快速构建复杂的 AI Agent 工作流,而且配置文件非常直观,团队成员之间的沟通成本也大大降低。
目前 KaFlow-Py 还处于早期阶段,后续计划支持:
- 🗄️ RAG 知识库 - 集成向量数据库或直接使用 RAGFlow,支持知识检索
- 🎙️ TTS 和 ASR -> RTC - 语音转文字、文字转语音,并实现 RTC 低延迟语音交互
- 🎨 可视化编辑器 - 拖拽式配置工作流,无需编写 YAML
- 🚀 Go + Python 混合架构 - Go 负责高并发服务,Python 负责 AI 能力
如果你对 AI Agent 开发感兴趣,欢迎 Star 和 Fork 项目,一起完善这个框架。
感谢
特别感谢以下开源项目的支持:
- LangChain - 强大的 AI 应用开发框架
- LangGraph - LangChain 官方的图执行引擎
- FastAPI - 现代、高性能的 Python Web 框架
- Browser-Use - 浏览器自动化库
- Model Context Protocol - Anthropic 主导的工具协议标准
项目地址:
- 后端:kaflow-py
- 前端:kaflow-web
如果这篇文章对你有帮助,欢迎点赞、转发!🙏