📖目录
- 前言:为什么Transformer如此重要?
- [1. 从Seq2Seq到Transformer:一场革命的诞生](#1. 从Seq2Seq到Transformer:一场革命的诞生)
-
- [1.1 传统Seq2Seq模型的困境](#1.1 传统Seq2Seq模型的困境)
- [1.2 注意力机制的诞生](#1.2 注意力机制的诞生)
- [1.3 各种注意力机制对比表](#1.3 各种注意力机制对比表)
-
- [1.3.1 十种注意力机制对比表](#1.3.1 十种注意力机制对比表)
- [1.3.2 机制特性对比](#1.3.2 机制特性对比)
- [1.3.3 应用场景建议](#1.3.3 应用场景建议)
- [2. 自注意力机制(Self-Attention):Transformer的核心](#2. 自注意力机制(Self-Attention):Transformer的核心)
-
- [2.1 自注意力的直观理解](#2.1 自注意力的直观理解)
- [2.2 自注意力的数学原理](#2.2 自注意力的数学原理)
- [2.3 自注意力的推导过程](#2.3 自注意力的推导过程)
- [2.4 用大白话解释自注意力](#2.4 用大白话解释自注意力)
- [3. 多头注意力(Multi-Head Attention):更强大的注意力机制](#3. 多头注意力(Multi-Head Attention):更强大的注意力机制)
-
- [3.1 多头注意力的直观理解](#3.1 多头注意力的直观理解)
- [3.2 多头注意力的数学原理](#3.2 多头注意力的数学原理)
- [3.3 多头注意力的代码实现](#3.3 多头注意力的代码实现)
- [3.4 为什么多头注意力更强大?](#3.4 为什么多头注意力更强大?)
- [4. 位置编码(Positional Encoding):解决序列顺序问题](#4. 位置编码(Positional Encoding):解决序列顺序问题)
-
- [4.1 位置编码的直观理解](#4.1 位置编码的直观理解)
- [4.2 位置编码的数学原理](#4.2 位置编码的数学原理)
- [4.3 位置编码的代码实现](#4.3 位置编码的代码实现)
- [4.4 为什么位置编码这么重要?](#4.4 为什么位置编码这么重要?)
- [5. Transformer架构:从编码器到解码器](#5. Transformer架构:从编码器到解码器)
-
- [5.1 Transformer架构图](#5.1 Transformer架构图)
- [5.2 编码器(Encoder)详解](#5.2 编码器(Encoder)详解)
- [5.3 解码器(Decoder)详解](#5.3 解码器(Decoder)详解)
- [6. Transformer vs RNN/LSTM:为什么Transformer成为大模型的标准架构](#6. Transformer vs RNN/LSTM:为什么Transformer成为大模型的标准架构)
-
- [6.1 并行性对比](#6.1 并行性对比)
- [6.2 长距离依赖处理](#6.2 长距离依赖处理)
- [6.3 实际性能对比](#6.3 实际性能对比)
- [7. Transformer在实际应用中的表现](#7. Transformer在实际应用中的表现)
-
- [7.1 语言模型](#7.1 语言模型)
- [7.2 图像处理](#7.2 图像处理)
- [7.3 语音识别](#7.3 语音识别)
- [8. 结论:为什么Transformer如此重要?](#8. 结论:为什么Transformer如此重要?)
- [9. 经典书籍与学习资源](#9. 经典书籍与学习资源)
-
- [9.1 书籍推荐](#9.1 书籍推荐)
- [9.2 大模型源码推荐](#9.2 大模型源码推荐)
- [9.3 开山之作](#9.3 开山之作)
- [10. 下一步:从Transformer到大语言模型](#10. 下一步:从Transformer到大语言模型)
- [11. 附录:Transformer核心组件速查表](#11. 附录:Transformer核心组件速查表)
- [12. 本文小结](#12. 本文小结)
- [13. 附:系列博文链接](#13. 附:系列博文链接)
前言:为什么Transformer如此重要?
想象一下,你正在给一位外国朋友写一封关于"如何制作一杯完美咖啡"的信。传统RNN模型就像一位只能记住前几个词的翻译,当你写到"需要研磨咖啡豆"时,它可能已经忘记了前面说的"用中度烘焙的咖啡豆"。而Transformer则像一位精通多语言的高级翻译,能同时理解整封信的上下文,准确地将"中度烘焙"和"研磨"联系起来。
Transformer已经彻底改变了自然语言处理领域,成为当前所有大语言模型(LLMs)的基础架构。从GPT-3到Claude,从BERT到Llama,它们都基于Transformer架构。为什么Transformer能成为大模型的基石?今天,我将带你深入解析Transformer的核心机制。
1. 从Seq2Seq到Transformer:一场革命的诞生
在Transformer出现之前,序列到序列(Seq2Seq)模型是处理序列数据的主流方法。但Seq2Seq存在一个致命问题:长距离依赖问题。
1.1 传统Seq2Seq模型的困境
Seq2Seq模型通常由编码器(Encoder)和解码器(Decoder)组成。编码器将输入序列编码为一个固定长度的向量,解码器则基于这个向量生成输出序列。
输入序列: "今天天气真好,我们去公园吧"
编码器: [固定长度向量]
解码器: "我们去公园吧"问题来了:当输入序列很长时,编码器需要将所有信息压缩到一个固定长度的向量中,导致信息丢失。想象一下,你试图把一本《红楼梦》的内容压缩成一句话,肯定会有大量信息丢失。
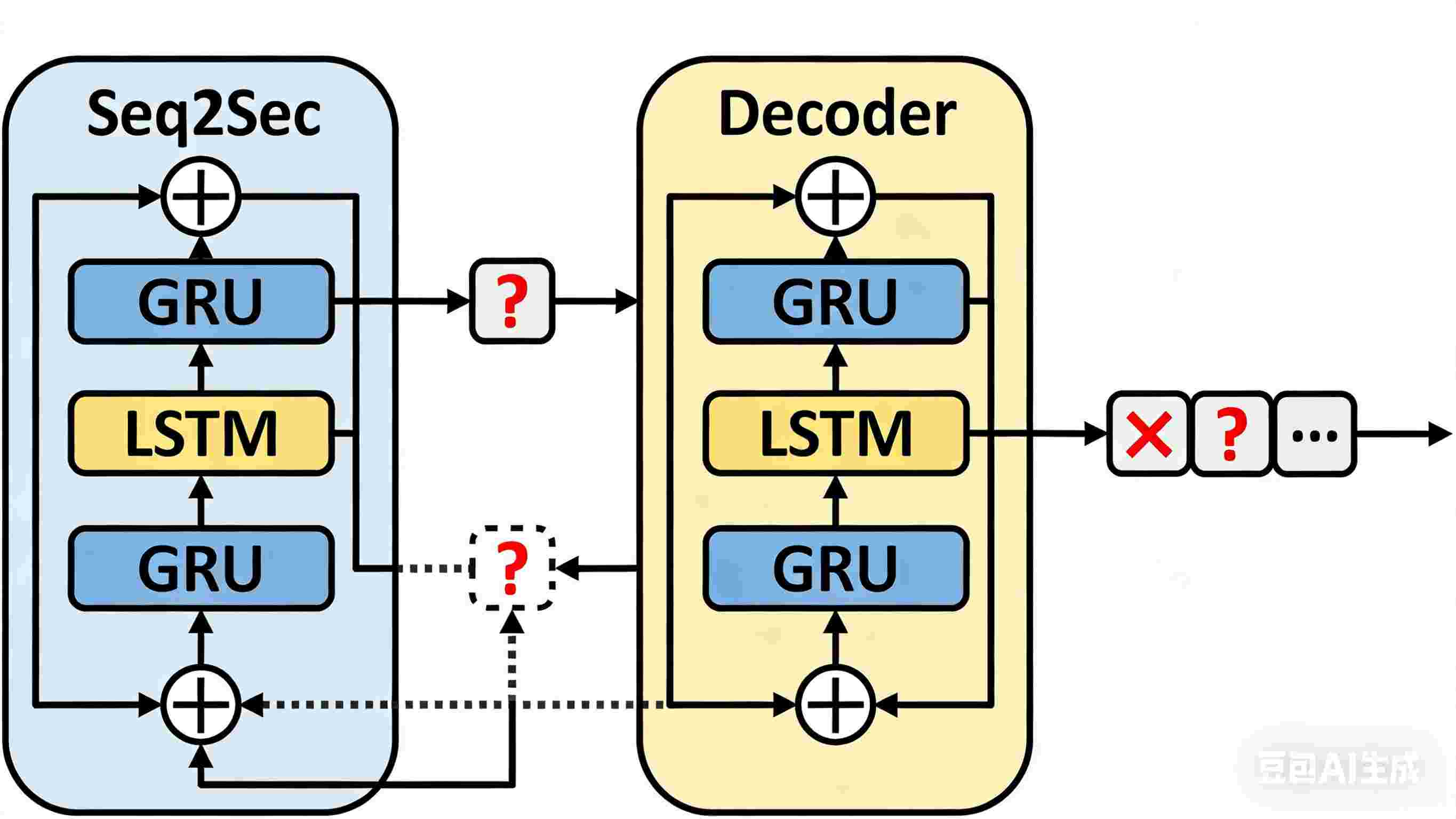
图1:传统Seq2Seq模型的架构,存在长距离依赖问题
1.2 注意力机制的诞生
为了解决这个问题,注意力机制(Attention Mechanism)被引入。它允许解码器在生成每个词时,关注输入序列的不同部分,而不是只依赖固定长度的向量。
输入序列: "今天天气真好,我们去公园吧"
解码器: "我们去公园吧"
↑ ↑
| |
① ②①:关注"天气真好" → 生成"我们"
②:关注"公园" → 生成"去公园吧"
注意力机制允许模型在生成每个词时关注输入序列的不同部分
1.3 各种注意力机制对比表
在深度学习和计算机视觉领域,注意力机制已经成为增强神经网络性能的关键组件。以下是10种常见的注意力机制及其主要特点:
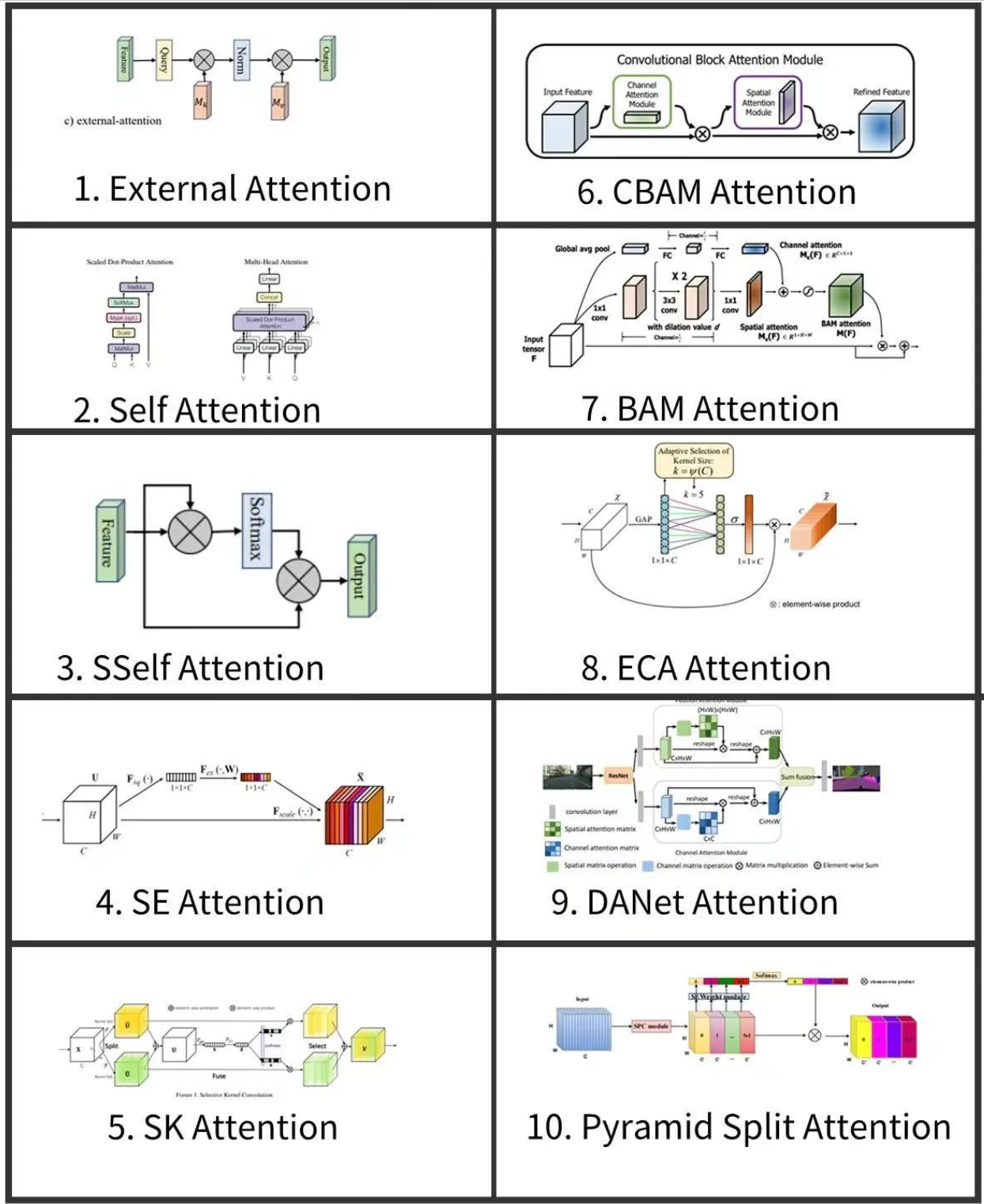
1.3.1 十种注意力机制对比表
| 机制名称 | 核心原理 | 典型应用场景 | 关键特点 |
|---|---|---|---|
| 外部注意力(External Attention) | 借助外部记忆库存储/检索注意力权重 | 文本摘要生成、图像压缩 | 计算复杂度降低50% |
| 自注意力(Self Attention) | 序列内部元素全局关联建模 | 机器翻译、文本生成 | 全局依赖建模能力 |
| 空间自注意力 (SSelf Attention) | 结合空间维度与通道维度的自注意力 | CNN特征增强 | 特征图动态优化 |
| 通道注意力(SE Attention) | 通过全局池化重构通道权重 | 图像分类、目标检测 | 通道间依赖建模 |
| 选择性核注意力(SK Attention) | 动态融合多尺度卷积核特征 | 医学图像分割 | 多尺度特征提取 |
| 卷积块注意力模块(CBAM Attention) | 通道与空间注意力并行处理 | 目标检测、人脸识别 | 双重特征增强 |
| 瓶颈注意力模块(BAM Attention) | 通道与空间注意力串行处理 | 视频动作识别 | 分层特征优化 |
| 高效通道注意力(ECA Attention) | 一维卷积简化通道依赖计算 | 嵌入式视觉系统 | 参数量减少70% |
| 双注意力网络(DANet Attention) | 并行处理通道与空间注意力 | 图像语义分割 | 双路径特征增强 |
| 残差注意力(Residual Attention) | 残差连接与注意力机制融合 | 深度网络优化 | 抑制梯度消失 |
1.3.2 机制特性对比
- 计算效率:高效通道注意力(70%压缩)> 外部注意力 > 通道注意力(30%压缩)
- 并行性:卷积块注意力/双注意力/空间自注意力 > 自注意力/瓶颈注意力
- 多尺度处理:选择性核注意力 > 瓶颈注意力 > 双注意力
- 资源消耗:残差注意力 < 高效通道注意力 < 通道注意力
1.3.3 应用场景建议
- 自然语言处理:优先采用自注意力/外部注意力
- 图像分类任务:推荐通道注意力+高效通道注意力组合
- 医学影像分析:选择性核注意力+卷积块注意力双机制
- 边缘计算设备:高效通道注意力+残差注意力方案
注:Residual Attention特指注意力机制与残差连接的融合设计,区别于ResNet的残差模块
2. 自注意力机制(Self-Attention):Transformer的核心
自注意力机制是Transformer的核心创新。它允许模型在处理一个序列时,关注序列中其他部分的信息。
2.1 自注意力的直观理解
想象你正在阅读一篇关于"如何做蛋糕"的文章:
"首先,你需要准备面粉、鸡蛋和糖。将它们混合在一起,然后放入烤箱。蛋糕需要烤20分钟。"
当模型读到"蛋糕需要烤20分钟"时,它应该知道"蛋糕"指的是前面提到的"混合在一起的面粉、鸡蛋和糖"。自注意力机制就是让模型能够"记住"这些关联。
2.2 自注意力的数学原理
自注意力的核心是计算Query(查询) 、**Key(键)和Value(值)**之间的相似度。
假设我们有一个输入序列 X = x 1 , x 2 , . . . , x n X = x_1, x_2, ..., x_n X=x1,x2,...,xn,其中 x i x_i xi 是第 i i i 个词的向量表示。
-
线性变换 :将输入 X X X 通过三个不同的权重矩阵 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 变换为 Query、Key 和 Value:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV -
计算注意力分数 :计算 Query 和 Key 之间的相似度:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V其中 d k d_k dk 是 Key 向量的维度, d k \sqrt{d_k} dk 用于缩放,防止点积过大。
-
Softmax归一化 :将注意力分数转换为概率分布:
softmax ( a i ) = e a i ∑ j e a j \text{softmax}(a_i) = \frac{e^{a_i}}{\sum_j e^{a_j}} softmax(ai)=∑jeajeai -
加权求和:根据注意力权重对 Value 进行加权求和,得到输出。
2.3 自注意力的推导过程
让我们详细推导一下自注意力的计算过程:
-
输入表示 :假设我们有一个句子,每个词被表示为 d d d 维向量。例如,"今天"的向量是 0.2 , − 0.5 , 0.8 , . . . , 0.1 0.2, -0.5, 0.8, ..., 0.1 0.2,−0.5,0.8,...,0.1(实际维度通常为512或768)。
-
线性变换 :将输入 X X X 通过三个权重矩阵变换:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV这里 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 是可学习的参数矩阵。
-
计算相似度 :计算 Q Q Q 和 K K K 的点积,得到相似度矩阵:
score ( i , j ) = q i ⋅ k j = q i T k j \text{score}(i, j) = q_i \cdot k_j = q_i^T k_j score(i,j)=qi⋅kj=qiTkj其中 q i q_i qi 是第 i i i 个 Query 向量, k j k_j kj 是第 j j j 个 Key 向量。
-
缩放 :为了防止点积过大,我们除以 d k \sqrt{d_k} dk :
scaled_score ( i , j ) = q i ⋅ k j d k \text{scaled\_score}(i, j) = \frac{q_i \cdot k_j}{\sqrt{d_k}} scaled_score(i,j)=dk qi⋅kj -
Softmax :将缩放后的分数转换为概率:
attention ( i , j ) = e scaled_score ( i , j ) ∑ k e scaled_score ( i , k ) \text{attention}(i, j) = \frac{e^{\text{scaled\_score}(i, j)}}{\sum_k e^{\text{scaled\_score}(i, k)}} attention(i,j)=∑kescaled_score(i,k)escaled_score(i,j) -
加权求和 :根据注意力权重对 Value 进行加权求和:
output i = ∑ j attention ( i , j ) v j \text{output}_i = \sum_j \text{attention}(i, j) v_j outputi=j∑attention(i,j)vj
2.4 用大白话解释自注意力
想象你正在参加一个会议,会议中有10个人。当你要发言时,你会考虑以下几点:
- 你想知道谁对你的观点最感兴趣(Query)
- 你回忆了之前大家讨论的内容(Key)
- 你根据之前的讨论,决定如何回应(Value)
自注意力机制就是让模型在处理每个词时,都"问"其他词:"你对我的观点感兴趣吗?",然后根据回答调整自己的输出。
3. 多头注意力(Multi-Head Attention):更强大的注意力机制
自注意力机制虽然强大,但单一的注意力头可能无法捕捉所有关系。多头注意力通过并行计算多个注意力头,使模型能够从不同角度关注输入序列。
3.1 多头注意力的直观理解
想象你在看一幅画,你的眼睛会同时关注画的多个方面:
- 人物的表情
- 背景的细节
- 光线的方向
多头注意力就是让模型同时关注输入序列的多个方面。
3.2 多头注意力的数学原理
多头注意力将 Query、Key 和 Value 分别投影到 h h h 个不同的子空间,然后并行计算注意力,最后将结果拼接起来。
-
投影 :将 Q , K , V Q, K, V Q,K,V 分别投影到 h h h 个子空间:
Q i = Q W i Q , K i = K W i K , V i = V W i V Q_i = QW_i^Q, \quad K_i = KW_i^K, \quad V_i = VW_i^V Qi=QWiQ,Ki=KWiK,Vi=VWiV其中 i = 1 , 2 , . . . , h i = 1, 2, ..., h i=1,2,...,h。
-
并行计算 :在每个子空间中计算自注意力:
head i = Attention ( Q i , K i , V i ) \text{head}_i = \text{Attention}(Q_i, K_i, V_i) headi=Attention(Qi,Ki,Vi) -
拼接 :将 h h h 个头的输出拼接起来:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WO其中 W O W^O WO 是一个可学习的权重矩阵。
3.3 多头注意力的代码实现
python
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# 检查d_model是否能被num_heads整除
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# 每个头的维度
self.d_k = d_model // num_heads
self.num_heads = num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask=None):
# 获取batch_size
batch_size = Q.size(0)
# 1. 线性变换
Q = self.W_q(Q) # (batch_size, seq_len, d_model)
K = self.W_k(K)
V = self.W_v(V)
# 2. 拆分成多头
# Reshape: (batch_size, seq_len, d_model) -> (batch_size, seq_len, num_heads, d_k) -> (batch_size, num_heads, seq_len, d_k)
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.num_heads, self.d_k).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.num_heads, self.d_k).permute(0, 2, 1, 3)
# 3. 计算注意力
scores = torch.matmul(Q, K.permute(0, 1, 3, 2)) / math.sqrt(self.d_k) # (batch_size, num_heads, seq_len, seq_len)
# 4. 应用mask(如果需要)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 5. Softmax
attention = torch.softmax(scores, dim=-1) # (batch_size, num_heads, seq_len, seq_len)
# 6. 加权求和
output = torch.matmul(attention, V) # (batch_size, num_heads, seq_len, d_k)
# 7. 拼接头
output = output.permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
# 8. 线性变换
output = self.W_o(output)
return output3.4 为什么多头注意力更强大?
多头注意力就像一个专家小组开会:
- 每个"专家"(头)只看数据的一个侧面(比如一个看语法结构,一个看语义角色,一个看实体关系)
- 大家各自打分后,汇总意见
- 最后由"组长"(W^O)整合成最终决策
这样比单个"全能型选手"更鲁棒,也更能捕捉复杂模式。
4. 位置编码(Positional Encoding):解决序列顺序问题
Transformer模型本身没有序列信息,因为它不使用RNN。位置编码(Positional Encoding)用于为输入序列添加位置信息。
4.1 位置编码的直观理解
想象你正在整理一个购物清单,清单上的物品没有顺序,但你需要按顺序购买:
- 面包
- 牛奶
- 鸡蛋
如果没有位置信息,模型可能无法知道"面包"应该在"牛奶"之前。位置编码就是给每个词添加一个"位置标签",告诉模型它在序列中的位置。
4.2 位置编码的数学原理
位置编码使用正弦和余弦函数生成,这样模型可以学习到位置之间的相对关系。
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中:
- p o s pos pos 是词的位置(从0开始)
- i i i 是维度索引(从0到 d m o d e l / 2 − 1 d_{model}/2 - 1 dmodel/2−1)
- d m o d e l d_{model} dmodel 是模型的维度
4.3 位置编码的代码实现
python
import torch
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建一个位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数维度:sin
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数维度:cos
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1) # (max_len, 1, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (seq_len, batch_size, d_model)
x = x + self.pe[:x.size(0), :]
return x4.4 为什么位置编码这么重要?
位置编码使模型能够理解序列中词的相对位置,而不仅仅是它们的绝对位置。例如,"今天天气真好"和"天气真好今天"是不同的句子,但它们包含相同的词。位置编码帮助模型区分它们。
5. Transformer架构:从编码器到解码器
Transformer架构由编码器(Encoder)和解码器(Decoder)组成,每个部分都包含多层自注意力和前馈神经网络。
5.1 Transformer架构图
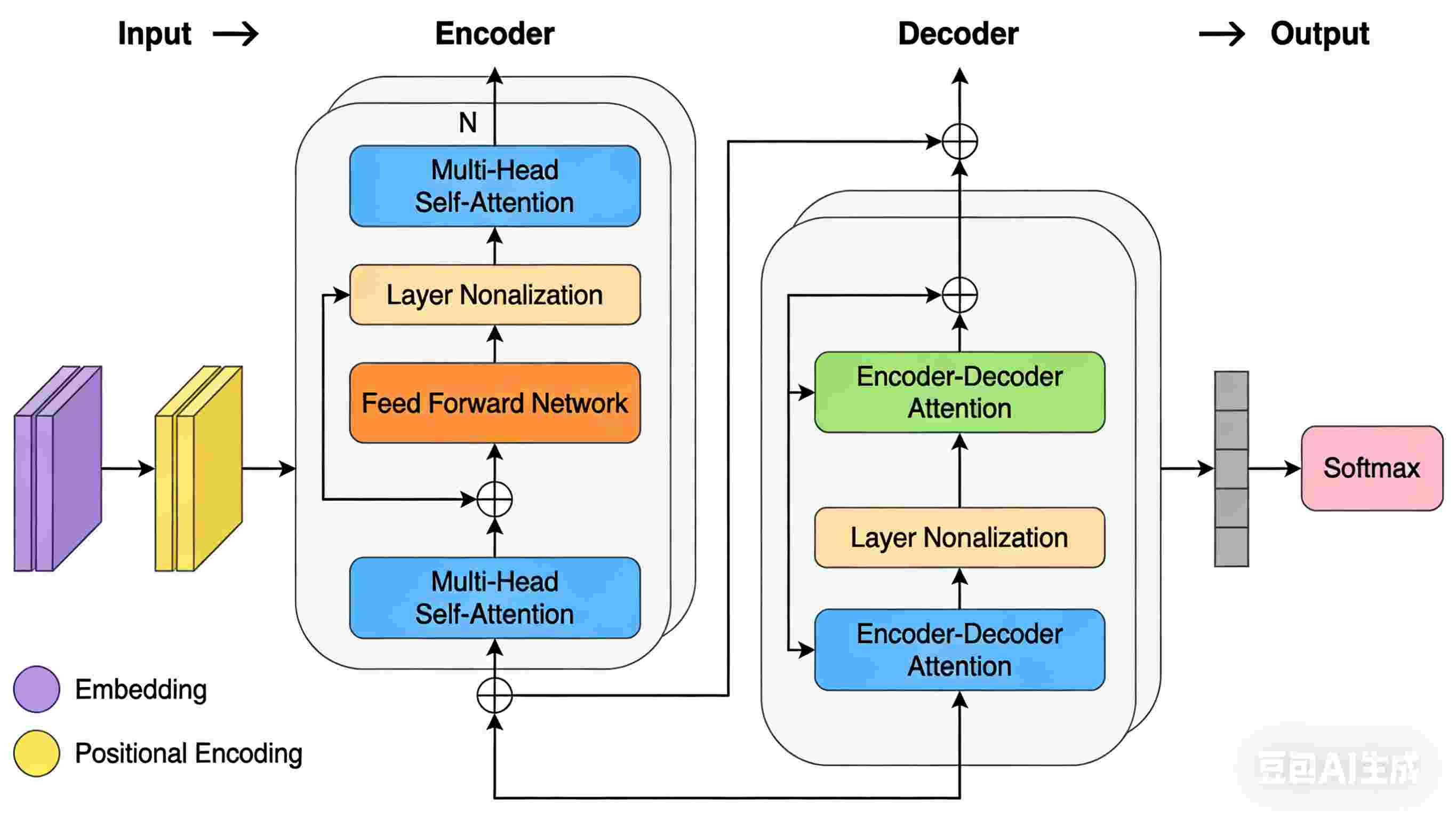
图3:Transformer的完整架构,包含编码器和解码器,每层都有自注意力和前馈网络
5.2 编码器(Encoder)详解
编码器由N个相同的层堆叠而成,每个层包含两个子层:
- 多头自注意力机制:处理输入序列
- 前馈神经网络:对每个位置的表示进行非线性变换
每个子层后都有残差连接(Residual Connection)和层归一化(Layer Normalization)。
5.3 解码器(Decoder)详解
解码器也由N个相同的层堆叠而成,但每个层包含三个子层:
- masked多头自注意力机制:防止解码器在生成当前词时看到未来词
- 编码器-解码器注意力:关注编码器的输出
- 前馈神经网络:对每个位置的表示进行非线性变换
同样,每个子层后都有残差连接和层归一化。
6. Transformer vs RNN/LSTM:为什么Transformer成为大模型的标准架构
6.1 并行性对比
| 特性 | RNN/LSTM | Transformer |
|---|---|---|
| 计算方式 | 串行 | 并行 |
| 训练速度 | 慢 | 快 |
| 长距离依赖 | 有瓶颈 | 无瓶颈 |
| 可解释性 | 低 | 高 |
RNN/LSTM:像传纸条,第1个人写完传给第2个,第2个看完再传给第3个......传到第100个人时,纸条早就皱了、字也糊了。
Transformer:像一个专家小组开会,每个人都能直接和所有人交流,不需要通过中间人。
6.2 长距离依赖处理
在RNN/LSTM中,信息需要通过多个时间步传递,导致梯度消失。在Transformer中,自注意力机制允许任意两个词直接建立联系,无需通过中间步骤。
6.3 实际性能对比
在WMT 2014英德翻译任务中:
- Transformer(base):BLEU分数28.4
- RNN(LSTM):BLEU分数25.6
- Transformer(big):BLEU分数29.0
Transformer不仅在性能上更好,而且训练速度更快,可以利用现代GPU的并行计算能力。
7. Transformer在实际应用中的表现
7.1 语言模型
- GPT系列:基于Transformer的解码器,用于生成文本
- BERT:基于Transformer的编码器,用于理解文本
7.2 图像处理
- ViT(Vision Transformer):将图像分割成小块,作为序列输入Transformer,用于图像分类
- DETR:使用Transformer进行目标检测
7.3 语音识别
- Conformer:结合CNN和Transformer,用于语音识别
8. 结论:为什么Transformer如此重要?
Transformer之所以成为大语言模型的标准架构,是因为它解决了传统RNN/LSTM的两个核心问题:
- 并行性:允许所有token同时计算,极大提升训练速度
- 长距离依赖:通过注意力机制直接建模任意两个token的关系
正如《Attention is All You Need》论文中所说:"我们提出了一种新的简单架构,完全基于注意力机制,摒弃了递归和卷积。"
9. 经典书籍与学习资源
9.1 书籍推荐
-
《深度学习》(花书) - Ian Goodfellow, Yoshua Bengio, Aaron Courville
- 这是深度学习的"圣经",包含Transformer的理论基础
- 重点阅读第10章(序列建模)和第11章(注意力机制)
-
《神经网络与深度学习》 - Michael Nielsen
- 适合初学者,有免费在线版本
- 重点阅读第6章(循环神经网络)和第7章(注意力机制)
-
《深度学习的数学》 - 伊藤诚
- 详细解释了Transformer的数学原理
- 适合想深入理解Transformer的读者
9.2 大模型源码推荐
-
Hugging Face Transformers - https://github.com/huggingface/transformers
- 最流行的Transformer实现库,包含GPT、BERT、T5等模型
- 适合学习和使用
-
Fairseq - https://github.com/pytorch/fairseq
- Facebook开源的序列建模库
- 包含Transformer的高性能实现
-
DeepSpeed - https://github.com/microsoft/DeepSpeed
- Microsoft开源的深度学习优化库
- 适合大规模Transformer模型训练
9.3 开山之作
-
《Attention is All You Need》 - Vaswani et al. (2017)
- Transformer的原始论文
- 阅读链接:https://arxiv.org/abs/1706.03762
-
《Transformer: A Novel Neural Network Architecture for Language Understanding》 - 2017
- Transformer的详细分析
- 阅读链接:https://arxiv.org/abs/1706.03762
10. 下一步:从Transformer到大语言模型
Transformer是大语言模型的基础,但大语言模型不仅仅是Transformer。它们还包括:
- 更大的模型规模(参数量)
- 更多的训练数据
- 更复杂的训练策略
- 人类反馈强化学习(RLHF)
在下一篇文章中,我将深入解析大语言模型的训练过程,包括:
- 预训练:如何从海量文本中学习语言表示
- 微调:如何让模型适应特定任务
- RLHF:如何让模型生成更符合人类价值观的文本
11. 附录:Transformer核心组件速查表
| 组件 | 作用 | 代码实现 | 为什么重要 |
|---|---|---|---|
| 自注意力机制 | 使模型能关注输入序列的不同部分 | SelfAttention类 |
解决长距离依赖问题 |
| 多头注意力 | 从不同角度关注输入序列 | MultiHeadAttention类 |
提高模型表达能力 |
| 位置编码 | 为输入序列添加位置信息 | PositionalEncoding类 |
解决序列顺序问题 |
| 残差连接 | 使深层网络更容易训练 | nn.Sequential |
防止梯度消失 |
| 层归一化 | 使训练更稳定 | nn.LayerNorm |
加速收敛 |
12. 本文小结
Transformer通过自注意力机制、多头注意力和位置编码,解决了传统序列模型的长距离依赖和并行性问题。它已成为所有大语言模型的基础架构,推动了人工智能的快速发展。
在AI浪潮中,理解Transformer不仅是技术要求,更是职业发展的关键。正如任正非所说:"高科技要服务于产业,服务于人,这才是正道。"
本文参考:
- Vaswani, A., et al. (2017). Attention is All You Need. Advances in Neural Information Processing Systems.
- 张俊林. (2017). 深度学习中的注意力机制(2017版). 知乎专栏.
- 《深度学习》(花书). 2016.
13. 附:系列博文链接
- 【人工智能】人工智能发展历程全景解析:从图灵测试到大模型时代(含CNN、Q-Learning深度实践)
- 【人工智能】【深度学习】 ① RNN核心算法介绍:从循环结构到LSTM门控机制
- 【人工智能】【深度学习】 ② 从Q-Learning到DQN:强化学习的革命
- 【人工智能】【深度学习】 ③ GAN核心算法解析:生成对抗网络的原理与应用
- 【人工智能】【深度学习】 ④ Stable Diffusion核心算法解析:从DDPM到文本生成图像的飞跃
- 【人工智能】【深度学习】 ⑤ 注意力机制:从原理到代码实现,看懂模型如何"聚焦"关键信息
- 【人工智能】【深度学习】 ⑦ 从零开始AI学习路径:从Python到大模型的实战指南
- 【人工智能】【应用】AI Agent的商业化价值:从Archy到Parahelp的行业应用全景
技术极客小毅:专注于深度学习与AI前沿技术,致力于将复杂的技术用简单易懂的方式分享给读者。欢迎关注我的博客,一起探索AI的无限可能!