parlant安装参见:https://skywalk.blog.csdn.net/article/details/152094280
手写g4f模块参见:https://skywalk.blog.csdn.net/article/details/152253434
说实话,parlant是我目前接触到的,最难配大模型的一个项目了。它没有展示配置文件,导致要换模型,都不知道该怎么写?主要是没有太仔细看手册....但是手册没有考虑到非官方大模型提供商的情况,官方倒是给了怎么样写自己的大模型,但是太复杂了,还不如我拿一个官方的py文件修改呢!
另外这几天Trae抽风,它是一点忙也没有帮上!
另外这几天g4f的gpt-4o模型也有问题,也增加了调试难度。
先看看parlant的手册
Environment Variables
Configure the Ollama service using these environment variables:
# Ollama server URL (default: http://localhost:11434)
export OLLAMA_BASE_URL="http://localhost:11434"
# Model size to use (default: 4b)
# Options: gemma3:1b, gemma3:4b, llama3.1:8b, gemma3:12b, gemma3:27b, llama3.1:70b, llama3.1:405b
export OLLAMA_MODEL="gemma3:4b"
# Embedding model (default: nomic-embed-text)
# Options: nomic-embed-text, mxbai-embed-large
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
# API timeout in seconds (default: 300)
export OLLAMA_API_TIMEOUT="300"Example Configuration
# For development (fast, good balance)
export OLLAMA_MODEL="gemma3:4b"
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
export OLLAMA_API_TIMEOUT="180"
# higher accuracy cloud
export OLLAMA_MODEL="gemma3:4b"
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
export OLLAMA_API_TIMEOUT="600"Recommended Models
⚠️ IMPORTANT: Pull these models before running Parlant to avoid API timeouts during first use:
Text Generation Models
# Recommended for most use cases (good balance of speed/accuracy)
ollama pull gemma3:4b-it-qat
# Fast but may struggle with complex schemas
ollama pull gemma3:1b
# embedding model required for creating embeddings
ollama pull nomic-embed-textLarge Models (Cloud/High-end Hardware Only)
# Better reasoning capabilities
ollama pull llama3.1:8b
# High accuracy for complex tasks
ollama pull gemma3:12b
# Very high accuracy (requires more resources)
ollama pull gemma3:27b-it-qat
# ⚠️ WARNING: Requires 40GB+ GPU memory
ollama pull llama3.1:70b
# ⚠️ WARNING: Requires 200GB+ GPU memory (cloud-only)
ollama pull llama3.1:405bEmbedding Models
To use custom embedding model set OLLAMA_EMBEDDING_MODEL environment value as required name Note that this implementation is tested using nomic-embed-text ⚠️ IMPORTANT : Support for using other embedding models has been added including a custom embedding model of your own choice Ensure to set OLLAMA_EMBEDDING_VECTOR_SIZE which is compatible with your own embedding model before starting the server Tested with snowflake-arctic-embed with vector size of 1024 It is not NECESSARY to put OLLAMA_EMBEDDING_VECTOR_SIZE if you are using the supported nomic-embed-text, mxbai-embed-large or bge-m3. The vector size defaults to 768, 1024 and 1024 respectively for these
# Alternative embedding model (512 dimensions)
ollama pull mxbai-embed-large:latest配置
export PARLANT_MODEL_URL="http://192.168.1.5:1337/v1"
export PARLANT_MODEL_API_KEY="key sample"
export PARLANT_MODEL_NAME="gpt-4o"
set PARLANT_MODEL_URL="http://192.168.1.5:1337/v1"
set PARLANT_MODEL_API_KEY="key sample"
set PARLANT_MODEL_NAME="gpt-4o"
set PARLANT_MODEL_URL="http://192.168.0.98:1337/v1"
set PARLANT_MODEL_API_KEY="key sample"
set PARLANT_MODEL_NAME="gpt-4o"不行
看看parlant源代码
ollama里面的配置
python
class OllamaEstimatingTokenizer(EstimatingTokenizer):
"""Simple tokenizer that estimates token count for Ollama models."""
def __init__(self, model_name: str):
self.model_name = model_name
self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
@override
async def estimate_token_count(self, prompt: str) -> int:
"""Estimate token count using tiktoken"""
tokens = self.encoding.encode(prompt)
return int(len(tokens) * 1.15)
class OllamaSchematicGenerator(SchematicGenerator[T]):
"""Schematic generator that uses Ollama models."""
supported_hints = ["temperature", "max_tokens", "top_p", "top_k", "repeat_penalty", "timeout"]
def __init__(
self,
model_name: str,
logger: Logger,
base_url: str = "http://localhost:11434",
default_timeout: int | str = 300,
) -> None:
self.model_name = model_name
self.base_url = base_url.rstrip("/")
self._logger = logger
self._tokenizer = OllamaEstimatingTokenizer(model_name)
self._default_timeout = default_timeout
self._client = ollama.AsyncClient(host=base_url)
@property
@override
def id(self) -> str:
return f"ollama/{self.model_name}"
@property
@override
def tokenizer(self) -> EstimatingTokenizer:
return self._tokenizer
@property
@override
def max_tokens(self) -> int:
if "1b" in self.model_name.lower():
return 12288
elif "4b" in self.model_name.lower():
return 16384
elif "8b" in self.model_name.lower():
return 16384
elif "12b" in self.model_name.lower() or "70b" in self.model_name.lower():
return 16384
elif "27b" in self.model_name.lower() or "405b" in self.model_name.lower():
return 32768
else:
return 16384这里设定了base_url 为:base_url: str = "http://localhost:11434",
openai的相关代码
python
class OpenAISchematicGenerator(SchematicGenerator[T]):
supported_openai_params = ["temperature", "logit_bias", "max_tokens"]
supported_hints = supported_openai_params + ["strict"]
unsupported_params_by_model: dict[str, list[str]] = {
"gpt-5": ["temperature"],
}
def __init__(
self,
model_name: str,
logger: Logger,
tokenizer_model_name: str | None = None,
) -> None:
self.model_name = model_name
self._logger = logger
self._client = AsyncClient(api_key=os.environ["OPENAI_API_KEY"])
self._tokenizer = OpenAIEstimatingTokenizer(
model_name=tokenizer_model_name or self.model_name
)deepseek
deepseek的,至少知道怎么设置base url
python
class DeepSeekEstimatingTokenizer(EstimatingTokenizer):
def __init__(self, model_name: str) -> None:
self.model_name = model_name
self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
@override
async def estimate_token_count(self, prompt: str) -> int:
tokens = self.encoding.encode(prompt)
return len(tokens)
class DeepSeekSchematicGenerator(SchematicGenerator[T]):
supported_deepseek_params = ["temperature", "logit_bias", "max_tokens"]
supported_hints = supported_deepseek_params + ["strict"]
def __init__(
self,
model_name: str,
logger: Logger,
) -> None:
self.model_name = model_name
self._logger = logger
self._client = AsyncClient(
base_url="https://api.deepseek.com",
api_key=os.environ["DEEPSEEK_API_KEY"],
)
self._tokenizer = DeepSeekEstimatingTokenizer(model_name=self.model_name)问题是,它也要用self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
这样我没有gpt模型,是不是就不能用了?
glm的调用
python
class GLMEmbedder(Embedder):
supported_arguments = ["dimensions"]
def __init__(self, model_name: str, logger: Logger) -> None:
self.model_name = model_name
self._logger = logger
self._client = AsyncClient(
base_url="https://open.bigmodel.cn/api/paas/v4", api_key=os.environ["GLM_API_KEY"]
)
self._tokenizer = GLMEstimatingTokenizer(model_name=self.model_name)parlant调用Ollama api的手册
参考Ollama的手册:docs/adapters/nlp/ollama.md · Gitee 极速下载/parlant - 码云 - 开源中国
Environment Variables
Configure the Ollama service using these environment variables:
# Ollama server URL (default: http://localhost:11434)
export OLLAMA_BASE_URL="http://localhost:11434"
# Model size to use (default: 4b)
# Options: gemma3:1b, gemma3:4b, llama3.1:8b, gemma3:12b, gemma3:27b, llama3.1:70b, llama3.1:405b
export OLLAMA_MODEL="gemma3:4b"
# Embedding model (default: nomic-embed-text)
# Options: nomic-embed-text, mxbai-embed-large
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
# API timeout in seconds (default: 300)
export OLLAMA_API_TIMEOUT="300"Example Configuration
# For development (fast, good balance)
export OLLAMA_MODEL="gemma3:4b"
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
export OLLAMA_API_TIMEOUT="180"
# higher accuracy cloud
export OLLAMA_MODEL="gemma3:4b"
export OLLAMA_EMBEDDING_MODEL="nomic-embed-text"
export OLLAMA_API_TIMEOUT="600"Recommended Models
⚠️ IMPORTANT: Pull these models before running Parlant to avoid API timeouts during first use:
Text Generation Models
# Recommended for most use cases (good balance of speed/accuracy)
ollama pull gemma3:4b-it-qat
# Fast but may struggle with complex schemas
ollama pull gemma3:1b
# embedding model required for creating embeddings
ollama pull nomic-embed-textLarge Models (Cloud/High-end Hardware Only)
# Better reasoning capabilities
ollama pull llama3.1:8b
# High accuracy for complex tasks
ollama pull gemma3:12b
# Very high accuracy (requires more resources)
ollama pull gemma3:27b-it-qat
# ⚠️ WARNING: Requires 40GB+ GPU memory
ollama pull llama3.1:70b
# ⚠️ WARNING: Requires 200GB+ GPU memory (cloud-only)
ollama pull llama3.1:405bEmbedding Models
To use custom embedding model set OLLAMA_EMBEDDING_MODEL environment value as required name Note that this implementation is tested using nomic-embed-text ⚠️ IMPORTANT : Support for using other embedding models has been added including a custom embedding model of your own choice Ensure to set OLLAMA_EMBEDDING_VECTOR_SIZE which is compatible with your own embedding model before starting the server Tested with snowflake-arctic-embed with vector size of 1024 It is not NECESSARY to put OLLAMA_EMBEDDING_VECTOR_SIZE if you are using the supported nomic-embed-text, mxbai-embed-large or bge-m3. The vector size defaults to 768, 1024 and 1024 respectively for these
# Alternative embedding model (512 dimensions)
ollama pull mxbai-embed-large:latestembedding
关于openai的那个embedding问题,可以使用这个
python
import tiktoken
class UniversalTokenizer:
def __init__(self, encoding_name="cl100k_base"):
self.encoding = tiktoken.get_encoding(encoding_name)
def estimate(self, text, ratio=1.1):
return int(len(self.encoding.encode(text)) * ratio)调用模型
import parlant.sdk as p
from parlant.sdk import NLPServices
async with p.Server(nlp_service=NLPServices.ollama) as server:
agent = await server.create_agent(
name="Healthcare Agent",
description="Is empathetic and calming to the patient.",
)准备这样做
直接改代码,不用gpt-4o-2024-08-06 ,直接就用字符长度算了
python
class DeepSeekEstimatingTokenizer(EstimatingTokenizer):
def __init__(self, model_name: str) -> None:
self.model_name = model_name
# self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
# self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
@override
async def estimate_token_count(self, prompt: str) -> int:
# tokens = self.encoding.encode(prompt)
tokens = prompt
return len(tokens)I get it! 我知道了!
when i changed base_url to my llm server ,such as 192.168.1.5:1337 or 127.0.0.1:1337
this change effect gpt-4o-2024-08-06 ,then error
当我修改base_url的时候,我可能也修改了gpt-4o-2024-08-06到自己的自定义llm服务器,导致会报没有这个模型。
这里吐槽一下,我的拼音输入法突然快捷键调不出来了,需要用鼠标点状态栏切换,真是屋漏偏逢连夜雨啊!
so I need to use other llms such as deepseek or ollama ,then gpt-4o-2024-08-06 can be ok
所以我只需要使用deepseek或者ollama模型的配置,这样就不会干扰pt-4o-2024-08-06模型
首先测试国内pt-4o-2024-08-06模型的连通性:
import tiktoken
import time
import asyncio
prompt="hello world 测试完成"
prompt='国内无法用这个模型怎么办? tiktoken.encoding_for_model("gpt-4o-2024-08-06")'
testencoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
tokens = testencoding.encode(prompt)
print(tokens, len(tokens))output:
[48450, 53254, 5615, 41713, 184232, 50182, 4802, 260, 8251, 2488, 154030, 11903, 10928, 568, 70, 555, 12, 19, 78, 12, 1323, 19, 12, 3062, 12, 3218, 1405] 27nlp_service=load_custom_nlp_service,
import parlant.sdk as p
from parlant.sdk import NLPServices
async with p.Server(nlp_service=NLPServices.ollama) as server:
agent = await server.create_agent(
name="Healthcare Agent",
description="Is empathetic and calming to the patient.",
)现在的几个问题
想使用deepseek,发现NLPServices里没有它:
python
from parlant.sdk import NLPServices
dir(NLPServices)'anthropic',
'azure',
'cerebras',
'gemini',
'glm',
'litellm',
'ollama',
'openai',
'qwen',
'snowflake',
'together',
'vertex
使用ollama,发现它要用自己的token模型,不太想整ollama了 。
主要是ollama启动后,整个机器负载有点大,而且只能启动8G或更小的模型,效果跟g4f比有点弱。
'anthropic', self._estimating_tokenizer = AnthropicEstimatingTokenizer(self._client, model_name)
'azure',self._tokenizer = AzureEstimatingTokenizer(model_name=self.model_name)
'cerebras', self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06")
'gemini',
'glm',self.encoding = tiktoken.encoding_for_model("gpt-4o-2024-08-06") base_url="https://open.bigmodel.cn/api/paas/v4", api_key=os.environ"GLM_API_KEY"
'litellm',
'ollama', self.model_name = os.environ.get("OLLAMA_EMBEDDING_MODEL", "nomic-embed-text")
'openai',
self._tokenizer = OpenAIEstimatingTokenizer(
model_name=tokenizer_model_name or self.model_name
'qwen',
'snowflake',
'together',
'vertex
要仔细看openai的这部分代码
python
class OpenAIEstimatingTokenizer(EstimatingTokenizer):
def __init__(self, model_name: str) -> None:
self.model_name = model_name
self.encoding = tiktoken.encoding_for_model(model_name)
@override
async def estimate_token_count(self, prompt: str) -> int:
tokens = self.encoding.encode(prompt)
return len(tokens)
class OpenAISchematicGenerator(SchematicGenerator[T]):
supported_openai_params = ["temperature", "logit_bias", "max_tokens"]
supported_hints = supported_openai_params + ["strict"]
unsupported_params_by_model: dict[str, list[str]] = {
"gpt-5": ["temperature"],
}
def __init__(
self,
model_name: str,
logger: Logger,
tokenizer_model_name: str | None = None,
) -> None:
self.model_name = model_name
self._logger = logger
self._client = AsyncClient(api_key=os.environ["OPENAI_API_KEY"])
self._tokenizer = OpenAIEstimatingTokenizer(
model_name=tokenizer_model_name or self.model_name
)测试
用这个调试
python
# 导入必要的库
import tiktoken
import time
import asyncio
import os
os.environ["DEEPSEEK_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["DEEPSEEK_BASE_URL"] = "http://192.168.0.98:1337/" # 自定义大模型API地址
os.environ["OLLAMA_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["OLLAMA_BASE_URL"] = "http://192.168.0.98:1337/" # 自定义大模型API地址
os.environ["OLLAMA_MODEL"] = "default" # 自定义大模型API地址
os.environ["SNOWFLAKE_AUTH_TOKEN"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["SNOWFLAKE_CORTEX_BASE_URL"] = "http://192.168.0.98:1337/" #
os.environ["SNOWFLAKE_CORTEX_CHAT_MODEL"] = "default"
import asyncio
import parlant.sdk as p
from parlant.sdk import NLPServices
# DEEPSEEK_API_KEY
async def main():
async with p.Server(nlp_service=NLPServices.snowflake) as server:
agent = await server.create_agent(
name="Otto Carmen",
description="You work at a car dealership",
)
asyncio.run(main())ollama和deepseek的都不适合自己。
最终解决
最终决定,自己手写g4f的service文件,在紧张的调试之后(trae还抽风,一点忙都帮不上),终于能跑了。
手写g4f的service代码过程见:https://skywalk.blog.csdn.net/article/details/152253434?spm=1011.2415.3001.5331
测试文件test_server.py这样写,把环境变量用os库写了,这里面主要起作用的是类似G4F_API_KEY这样的G4F开头的环境变量:
python
# 导入必要的库
import tiktoken
import time
import asyncio
import os
os.environ["DEEPSEEK_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["DEEPSEEK_BASE_URL"] = "http://192.168.0.98:1337/" # 自定义大模型API地址
os.environ["OLLAMA_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["OLLAMA_BASE_URL"] = "http://192.168.0.98:1337/" # 自定义大模型API地址
os.environ["OLLAMA_MODEL"] = "default" # 自定义大模型API地址
os.environ["SNOWFLAKE_AUTH_TOKEN"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["SNOWFLAKE_CORTEX_BASE_URL"] = "http://192.168.0.98:1337/" #
os.environ["SNOWFLAKE_CORTEX_CHAT_MODEL"] = "default"
os.environ["OPENAI_MODEL"] = "default"
os.environ["OPENAI_MODEL"] = "default"
os.environ["OPENAI_MODEL"] = "default"
os.environ["G4F_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["G4F_BASE_URL"] = "http://192.168.0.98:1337/v1" # 自定义大模型API地址
os.environ["G4F_MODEL"] = "default" # 自定义大模型API地址
os.environ["OPANAI_API_KEY"] = "your_custom_api_key" # 自定义API密钥(可为任意值,仅作占位)
os.environ["OPENAI_BASE_URL"] = "http://192.168.0.98:1337/v1" # 自定义大模型API地址
os.environ["OPENAI_MODEL"] = "default" # 自定义大模型API地址
import asyncio
import parlant.sdk as p
from parlant.sdk import NLPServices
# DEEPSEEK_API_KEY
async def main():
async with p.Server(nlp_service=NLPServices.g4f) as server:
agent = await server.create_agent(
name="Otto Carmen",
description="You work at a car dealership",
# model="default"
)
asyncio.run(main())跑起来这个样: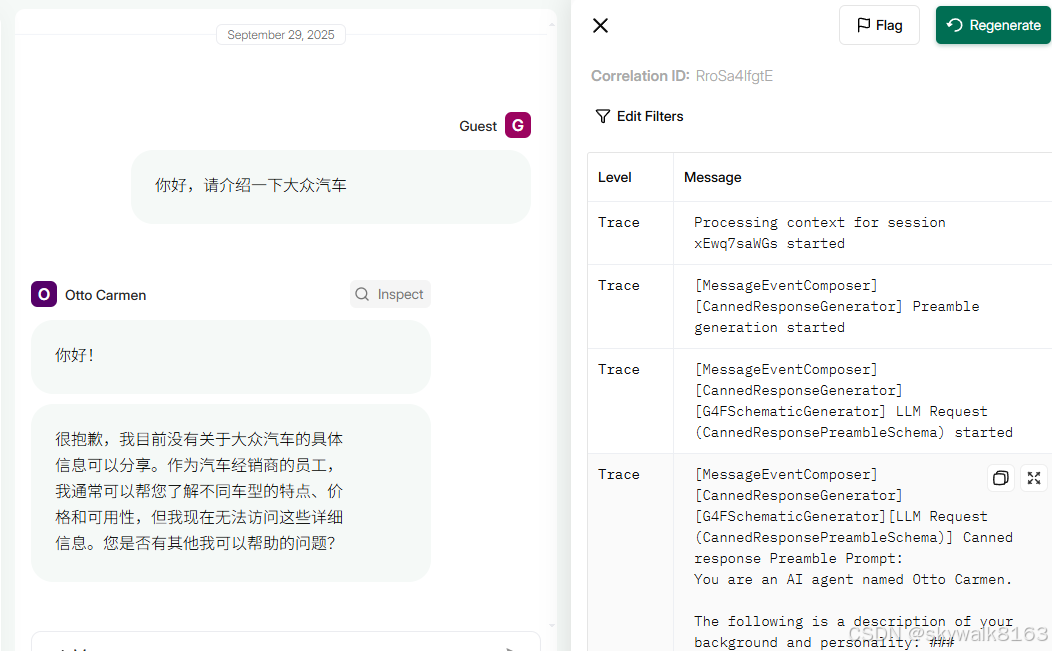
调试
没找到snowflake这个模型库
python
PS E:\work\parlwork> python .\testdeepseek.py
Traceback (most recent call last):
File "E:\work\parlwork\testdeepseek.py", line 30, in <module>
asyncio.run(main())
File "E:\py312\Lib\asyncio\runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "E:\py312\Lib\asyncio\runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\py312\Lib\asyncio\base_events.py", line 691, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "E:\work\parlwork\testdeepseek.py", line 24, in main
async with p.Server(nlp_service=NLPServices.snowflake) as server:
^^^^^^^^^^^^^^^^^^^^^我的天,咋这个也没有了?
python
>>> from parlant.sdk import NLPServices
>>> dir(NLPServices)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'anthropic', 'azure', 'cerebras', 'gemini', 'litellm', 'ollama', 'openai', 'together', 'vertex']
>>>原来没有安装本地的parlant代码,所以需要在github\parlant\src目录执行才可以,也就是需要再这个目录运行测试文件。
另外对自己手写添加的g4f的库,需要再sdk.py文件里写上相应的导入:
python
# 学习openai,加上g4f
@staticmethod
def g4f(container: Container) -> NLPService:
"""Creates an G4F NLPService instance using the provided container."""
from parlant.adapters.nlp.g4f_service import G4FService
if error := G4FService.verify_environment():
raise SDKError(error)
return G4FService(container[Logger])