前言
在目标检测领域,DETR开创了端到端检测的新范式,但其复杂的计算导致训练慢、推理延迟高,难以落地实时场景。百度推出的RT-DETR在保留DETR端到端优点的同时,实现了突破性的实时性能,所以我们有必要花点时间学习一下。
论文地址:DETRs Beat YOLOs on Real-time Object Detection
代码:https://github.com/lyuwenyu/RT-DETR
RT-DETR整体结构
RT-DETR采用的是在ImageNet上预训练的ResNet(如R18/R34/R50/R101等)作为主干网络,用于提取多尺度信息,最后三个阶段 {S3, S4, S5} 的特征输入到编码器中,高效的混合编码器进行单尺度注意力交互与卷积式跨尺度融合。随后,采用不确定性最小的查询选择机制来选择固定数量的编码器特征,作为解码器的初始物体查询,再由多层Transformer解码器迭代优化,最终实现端到端、无需NMS的实时目标检测。
结构图如下所示:
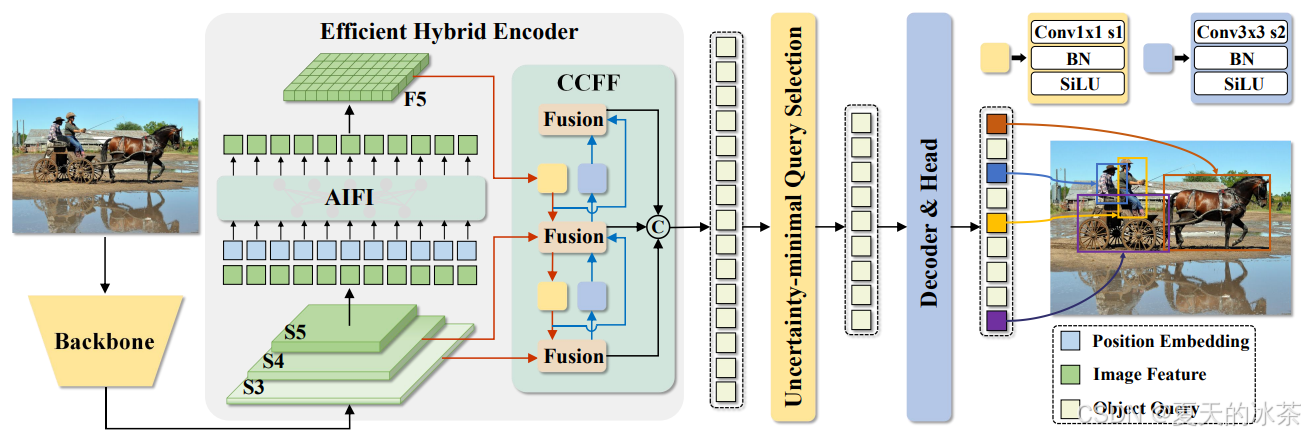
高效混合编码器
该编码器由两个模块组成,分别是基于注意力的同尺度特征交互(AIFI)和基于卷积的跨尺度特征融合(CCFF)。
对包含更多语义信息的高层特征应用自注意力有助于捕捉目标之间的联系,有助于帮助后续的模块进行定位和识别,而低层特征缺乏语义信息,对起进行同尺度的特征交互没有什么作用,甚至会有与高层特征交互重复的风险,所以这里仅使用单尺度Transformer编码器仅在S5上执行同尺度交互,这样不仅显著减少了延迟(快35%),而且提高了准确性(AP提升了0.4%)。
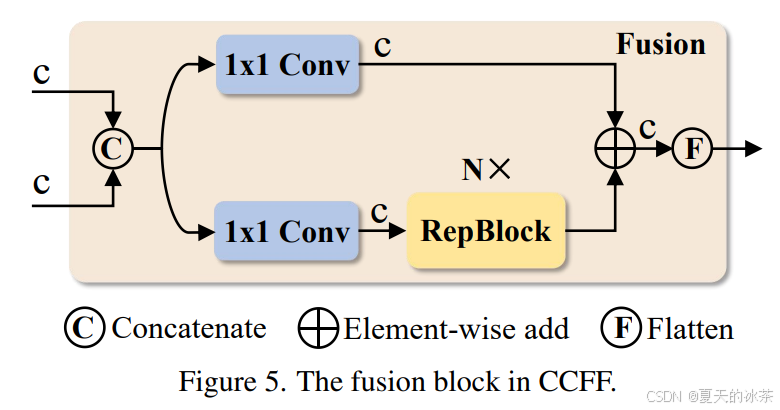
CCFF基于跨尺度融合模块进行了优化,在融合路径中插入了由卷积层组成的多个融合块。融合块的作用是将两个相邻尺度的特征融合为一个新特征,其结构如下图所示。
融合块包含两个1×1卷积以调整通道数量,N个由RepConv组成的RepBlocks用于特征融合,两个路径的输出通过逐元素加法融合,也就是下面当中的CSPRepLayer。
混合编码器的计算公式表示为:
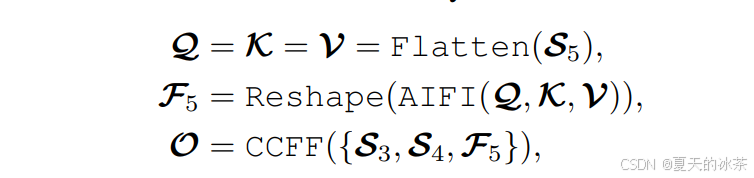
python
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_activation(act: str, inpace: bool = True):
act = act.lower()
if act == 'silu':
m = nn.SiLU()
elif act == 'relu':
m = nn.ReLU()
elif act == 'leaky_relu':
m = nn.LeakyReLU()
elif act == 'silu':
m = nn.SiLU()
elif act == 'gelu':
m = nn.GELU()
elif act is None:
m = nn.Identity()
elif isinstance(act, nn.Module):
m = act
else:
raise RuntimeError('')
if hasattr(m, 'inplace'):
m.inplace = inpace
return m
class ConvNormLayer(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size, stride, padding=None, bias=False, act=None):
super().__init__()
self.conv = nn.Conv2d(
ch_in,
ch_out,
kernel_size,
stride,
padding=(kernel_size - 1) // 2 if padding is None else padding,
bias=bias)
self.norm = nn.BatchNorm2d(ch_out)
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
return self.act(self.norm(self.conv(x)))
class RepVggBlock(nn.Module):
def __init__(self, ch_in, ch_out, act='relu'):
super().__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = ConvNormLayer(ch_in, ch_out, 3, 1, padding=1, act=None)
self.conv2 = ConvNormLayer(ch_in, ch_out, 1, 1, padding=0, act=None)
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
if hasattr(self, 'conv'):
y = self.conv(x)
else:
y = self.conv1(x) + self.conv2(x)
return self.act(y)
def convert_to_deploy(self):
if not hasattr(self, 'conv'):
self.conv = nn.Conv2d(self.ch_in, self.ch_out, 3, 1, padding=1)
kernel, bias = self.get_equivalent_kernel_bias()
self.conv.weight.data = kernel
self.conv.bias.data = bias
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1), bias3x3 + bias1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return F.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch: ConvNormLayer):
if branch is None:
return 0, 0
kernel = branch.conv.weight
running_mean = branch.norm.running_mean
running_var = branch.norm.running_var
gamma = branch.norm.weight
beta = branch.norm.bias
eps = branch.norm.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
class CSPRepLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_blocks=3,
expansion=1.0,
bias=None,
act="silu"):
super(CSPRepLayer, self).__init__()
hidden_channels = int(out_channels * expansion)
self.conv1 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
self.conv2 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
self.bottlenecks = nn.Sequential(*[
RepVggBlock(hidden_channels, hidden_channels, act=act) for _ in range(num_blocks)
])
if hidden_channels != out_channels:
self.conv3 = ConvNormLayer(hidden_channels, out_channels, 1, 1, bias=bias, act=act)
else:
self.conv3 = nn.Identity()
def forward(self, x):
x_1 = self.conv1(x)
x_1 = self.bottlenecks(x_1)
x_2 = self.conv2(x)
return self.conv3(x_1 + x_2)
# transformer
class TransformerEncoderLayer(nn.Module):
def __init__(self,
d_model,
nhead,
dim_feedforward=2048,
dropout=0.1,
activation="relu",
normalize_before=False):
super().__init__()
self.normalize_before = normalize_before
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout, batch_first=True)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = get_activation(activation)
@staticmethod
def with_pos_embed(tensor, pos_embed):
return tensor if pos_embed is None else tensor + pos_embed
def forward(self, src, src_mask=None, pos_embed=None) -> torch.Tensor:
residual = src
if self.normalize_before:
src = self.norm1(src)
q = k = self.with_pos_embed(src, pos_embed)
src, _ = self.self_attn(q, k, value=src, attn_mask=src_mask)
src = residual + self.dropout1(src)
if not self.normalize_before:
src = self.norm1(src)
residual = src
if self.normalize_before:
src = self.norm2(src)
src = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = residual + self.dropout2(src)
if not self.normalize_before:
src = self.norm2(src)
return src
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([copy.deepcopy(encoder_layer) for _ in range(num_layers)])
self.num_layers = num_layers
self.norm = norm
def forward(self, src, src_mask=None, pos_embed=None) -> torch.Tensor:
output = src
for layer in self.layers:
output = layer(output, src_mask=src_mask, pos_embed=pos_embed)
if self.norm is not None:
output = self.norm(output)
return output
class HybridEncoder(nn.Module):
def __init__(self,
in_channels=[512, 1024, 2048],
feat_strides=[8, 16, 32],
hidden_dim=256,
nhead=8,
dim_feedforward=1024,
dropout=0.0,
enc_act='gelu',
use_encoder_idx=[2],
num_encoder_layers=1,
pe_temperature=10000,
expansion=1.0,
depth_mult=1.0,
act='silu',
eval_spatial_size=None):
super().__init__()
self.in_channels = in_channels
self.feat_strides = feat_strides
self.hidden_dim = hidden_dim
self.use_encoder_idx = use_encoder_idx
self.num_encoder_layers = num_encoder_layers
self.pe_temperature = pe_temperature
self.eval_spatial_size = eval_spatial_size
self.out_channels = [hidden_dim for _ in range(len(in_channels))]
self.out_strides = feat_strides
# channel projection
self.input_proj = nn.ModuleList()
for in_channel in in_channels:
self.input_proj.append(
nn.Sequential(
nn.Conv2d(in_channel, hidden_dim, kernel_size=1, bias=False),
nn.BatchNorm2d(hidden_dim)
)
)
# encoder transformer
encoder_layer = TransformerEncoderLayer(
hidden_dim,
nhead=nhead,
dim_feedforward=dim_feedforward,
dropout=dropout,
activation=enc_act)
self.encoder = nn.ModuleList([
TransformerEncoder(copy.deepcopy(encoder_layer), num_encoder_layers) for _ in range(len(use_encoder_idx))
])
# top-down fpn
self.lateral_convs = nn.ModuleList()
self.fpn_blocks = nn.ModuleList()
for _ in range(len(in_channels) - 1, 0, -1):
self.lateral_convs.append(ConvNormLayer(hidden_dim, hidden_dim, 1, 1, act=act))
self.fpn_blocks.append(
CSPRepLayer(hidden_dim * 2, hidden_dim, round(3 * depth_mult), act=act, expansion=expansion)
)
# bottom-up pan
self.downsample_convs = nn.ModuleList()
self.pan_blocks = nn.ModuleList()
for _ in range(len(in_channels) - 1):
self.downsample_convs.append(
ConvNormLayer(hidden_dim, hidden_dim, 3, 2, act=act)
)
self.pan_blocks.append(
CSPRepLayer(hidden_dim * 2, hidden_dim, round(3 * depth_mult), act=act, expansion=expansion)
)
self._reset_parameters()
def _reset_parameters(self):
if self.eval_spatial_size:
for idx in self.use_encoder_idx:
stride = self.feat_strides[idx]
pos_embed = self.build_2d_sincos_position_embedding(
self.eval_spatial_size[1] // stride, self.eval_spatial_size[0] // stride,
self.hidden_dim, self.pe_temperature)
setattr(self, f'pos_embed{idx}', pos_embed)
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.):
grid_w = torch.arange(int(w), dtype=torch.float32)
grid_h = torch.arange(int(h), dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')
assert embed_dim % 4 == 0, \
'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 4
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1. / (temperature ** omega)
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
return torch.concat([out_w.sin(), out_w.cos(), out_h.sin(), out_h.cos()], dim=1)[None, :, :]
def forward(self, feats):
assert len(feats) == len(self.in_channels)
proj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]
# encoder
if self.num_encoder_layers > 0:
for i, enc_ind in enumerate(self.use_encoder_idx):
h, w = proj_feats[enc_ind].shape[2:]
# flatten [B, C, H, W] to [B, HxW, C]
src_flatten = proj_feats[enc_ind].flatten(2).permute(0, 2, 1)
if self.training or self.eval_spatial_size is None:
pos_embed = self.build_2d_sincos_position_embedding(
w, h, self.hidden_dim, self.pe_temperature).to(src_flatten.device)
else:
pos_embed = getattr(self, f'pos_embed{enc_ind}', None).to(src_flatten.device)
memory = self.encoder[i](src_flatten, pos_embed=pos_embed)
proj_feats[enc_ind] = memory.permute(0, 2, 1).reshape(-1, self.hidden_dim, h, w).contiguous()
# print([x.is_contiguous() for x in proj_feats ])
# broadcasting and fusion
inner_outs = [proj_feats[-1]]
for idx in range(len(self.in_channels) - 1, 0, -1):
feat_high = inner_outs[0]
feat_low = proj_feats[idx - 1]
feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_high)
inner_outs[0] = feat_high
upsample_feat = F.interpolate(feat_high, scale_factor=2., mode='nearest')
inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](torch.concat([upsample_feat, feat_low], dim=1))
inner_outs.insert(0, inner_out)
outs = [inner_outs[0]]
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1]
feat_high = inner_outs[idx + 1]
downsample_feat = self.downsample_convs[idx](feat_low)
out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_high], dim=1))
outs.append(out)
return outs不确定性最小的查询选择
为了降低DETR中物体查询的优化难度,以往的方案是使用置信得分从编码器中选择前K个特征来初始化物体查询,置信得分表示该特征包含前景物体的可能性。
然而,检测器需要同时对物体的类别和位置进行建模,这两者共同决定了特征的质量。因此,特征的性能得分是一个同时与分类和定位相关的潜在变量。基于这一分析,目前的查询选择导致了所选特征存在相当程度的不确定性,导致解码器初始化次优,从而阻碍了检测器的性能。
RT-DETR通过显式构建和优化认知不确定性来建模编码器特征的联合潜在变量,从而为解码器提供高质量的查询。具体来说,特征不确定性U定义为预测的定位P和分类C分布之间的差异
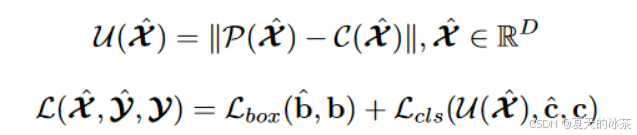
此过程被整合到损失函数当中,作者也对这部分进行了实验,紫色和绿色的点分别代表了使用不确定性最小查询选择和普通查询选择训练的模型的所选特征。
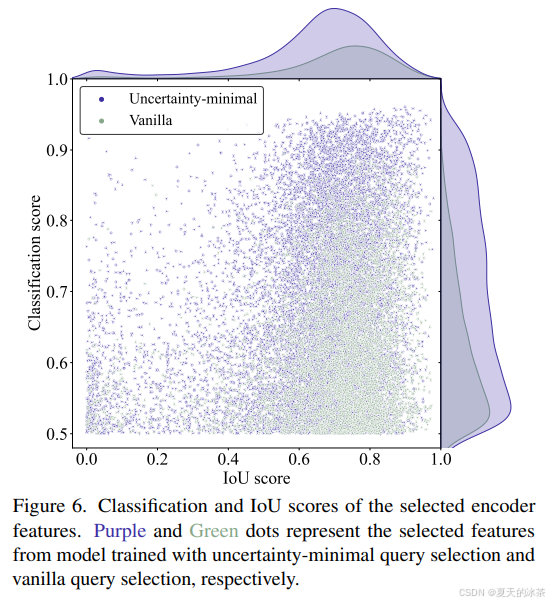
可以发现紫色点集中在图的右上角,而绿色点集中在右下角,这表明不确定性最小查询选择产生了更多高质量的编码器特征。
可扩展的RT-DETR
RT-DETR支持灵活的缩放,在混合编码器部分通过调整嵌入维度和通道数来控制宽度,通过调整 Transformer 层数和 RepBlock 数量来控制深度。解码器的宽度和深度可以通过调整目标查询数和解码器层数来控制。
消融实验
因为在ultralytics里面就有现成的,我们就不去跑它官方的代码了:
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'rtdetr-resnet50.yaml', task='detect')
model.train(data=r'E:\PythonProject\SmallTargetDetection\data\AI_TOD\data.yaml',
cache=False,
imgsz=480,
epochs=30,
single_cls=False,
batch=8,
close_mosaic=1,
workers=0,
device='0',
patience=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='exp')可能是使用了Transformer的缘故,训练起来还是比较的慢的。下面是原版的RT-DETR的轻量版本的指标:
精度 (P): 0.645
召回率 (R): 0.133
mAP50 (IoU=0.5时的平均精度): 0.0848
mAP50-95 (IoU=0.5到0.95的平均精度): 0.0274
参考文章
RT-DETR:《DETRs Beat YOLOs on Real-time Object Detection》-CSDN博客
目标检测 RT-DETR(2023)详细解读_rtdetr-CSDN博客