every blog every motto: There's only one corner of the universe you can be sure of improving, and that's your own self.
https://blog.csdn.net/weixin_39190382?spm=1010.2135.3001.5343
0. 前言
Mask rcnn 梳理
1. 正文
Mask-RCNN 主要在Faster R-CNN的基础做了两点改进:
- 引入 ROIAlign,解决 ROI Pooling 带来的插值误差问题。
- 引入 Mask 分支,预测每个目标物体的 mask。
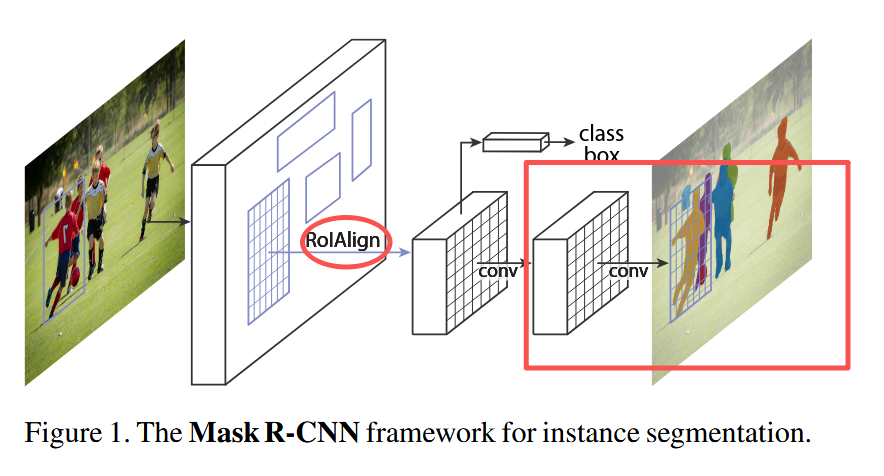
1.1 backbone
梗概: 输入是原图,输出是经过resnet和FPN处理后的P2-P6五个特征图。
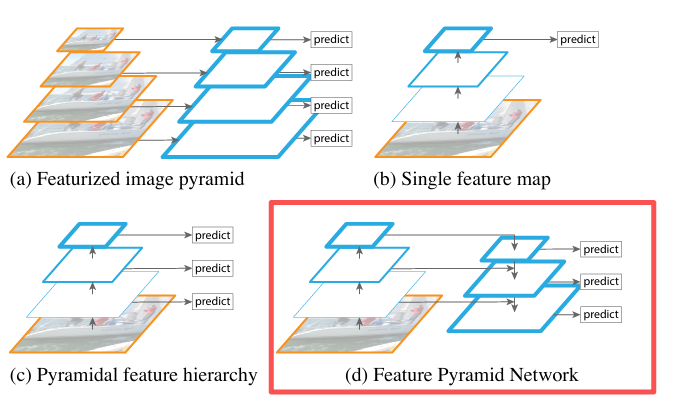
backbone这部分采用resnet50或resnet101,进行特征提取,随着深度增加,特征图尺寸变为(H/2,W/2),(H/4,W/4),(H/8,W/8),(H/16,W/16),(H/32,W/32)。我们知道,低层特征往往含有较多的细节信息(颜色、轮廓、纹理),但包含许多的噪声以及无关信息。而高层特征包含有充分的语义信息(类别、属性等),但空间分辨率却很小,从而导致高层特征上信息丢失较为严重。因此maskrcnn采用了FPN(特征金字塔网络)的结构,来进行特征的融合。
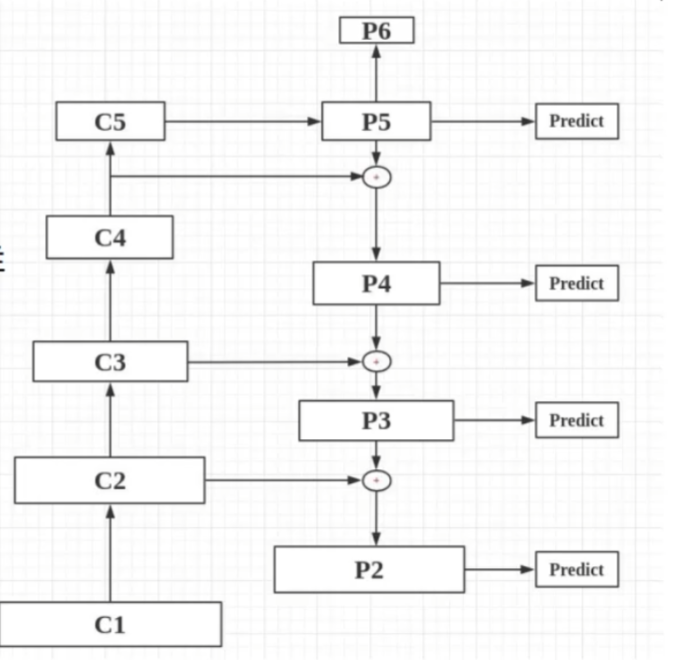
1.1.1 调用部分
python
resnet = ResNet("resnet101", stage5=True)
C1, C2, C3, C4, C5 = resnet.stages()
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
self.fpn = FPN(C1, C2, C3, C4, C5, out_channels=256)1.1.1 Rsenet网络代码
python
class ResNetBackbone(nn.Module):
"""ResNet backbone stripped to C1..C5 feature maps."""
def __init__(self, layers: Tuple[int, int, int, int]) -> None:
super().__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=True)
self.bn1 = FrozenBatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, layers[0], stride=1)
self.layer2 = self._make_layer(128, layers[1], stride=2)
self.layer3 = self._make_layer(256, layers[2], stride=2)
self.layer4 = self._make_layer(512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
def _make_layer(self, planes: int, blocks: int, stride: int) -> nn.Sequential:
downsample = None
if stride != 1 or self.inplanes != planes * Bottleneck.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes,
planes * Bottleneck.expansion,
kernel_size=1,
stride=stride,
bias=True,
),
FrozenBatchNorm2d(planes * Bottleneck.expansion),
)
layers = [Bottleneck(self.inplanes, planes, stride=stride, downsample=downsample)]
self.inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, ...]: # noqa: D401
c1 = self.relu(self.bn1(self.conv1(x)))
c1 = self.maxpool(c1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
return c1, c2, c3, c4, c5将resnet的中间过程C2-C5作为输入,会得到p2-p6
1.1.2 FPN网络结构
python
class ResNetFPN(nn.Module):
"""ResNet backbone followed by a top-down Feature Pyramid Network."""
def __init__(
self,
architecture: str = "resnet50",
out_channels: int = 256,
) -> None:
super().__init__()
layers = {"resnet50": (3, 4, 6, 3), "resnet101": (3, 4, 23, 3)}[architecture]
self.backbone = ResNetBackbone(layers)
c2_channels = 256
c3_channels = 512
c4_channels = 1024
c5_channels = 2048
self.lateral_c5 = nn.Conv2d(c5_channels, out_channels, kernel_size=1)
self.lateral_c4 = nn.Conv2d(c4_channels, out_channels, kernel_size=1)
self.lateral_c3 = nn.Conv2d(c3_channels, out_channels, kernel_size=1)
self.lateral_c2 = nn.Conv2d(c2_channels, out_channels, kernel_size=1)
self.out_p5 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.out_p4 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.out_p3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.out_p2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, ...]: # noqa: D401
_, c2, c3, c4, c5 = self.backbone(x)
p5 = self.lateral_c5(c5)
p4 = self.lateral_c4(c4) + F.interpolate(p5, scale_factor=2.0, mode="nearest")
p3 = self.lateral_c3(c3) + F.interpolate(p4, scale_factor=2.0, mode="nearest")
p2 = self.lateral_c2(c2) + F.interpolate(p3, scale_factor=2.0, mode="nearest")
p5 = self.out_p5(p5)
p4 = self.out_p4(p4)
p3 = self.out_p3(p3)
p2 = self.out_p2(p2)
p6 = F.max_pool2d(p5, kernel_size=1, stride=2)
return p2, p3, p4, p5, p61.2 anchor生成
梗概: 以特征图每个像素点为中心生成anchor(坐标系在原图上,根据缩放关系映射回去的)
从原图到特征图有一个缩放的过程,假设这个缩放是feature_stride = 16,生成的特征图大小为(2,3)。
- 特征图上的每个点都是我们生成框的中心点。
- 需要将框映射到原始图像坐标
框的大小由三种,32,64,128,宽高比由三种,0.5,1,2。
如果不是多尺度(只使用backbone的最后一个特征图),特征图上每个点,都会生成3 * 3=9个框,也就是常说的9k个,所以特征图上2 * 3=6个点,会生成6 * 9=54个框。
而如果使用多尺度的话,会根据框的大小分到不同的特征图中,小框(32)会分到大的分辨率中(256×256),大框512,会被分到小分辨率的特征图(16×16)。(下面会举例),所特征图上的每个点会有3个宽高比的框,即,3k。
框的面积为S, S = w h = s c a l e 2 , r a t i o s = w / h S=wh=scale^2, ratios=w/h S=wh=scale2,ratios=w/h,
h = S / r a t i o s = s c a l e s / r a t i o s h = \sqrt{S/ratios} = scales/\sqrt{ratios} h=S/ratios =scales/ratios ;
w = s c a l e s ∗ r a t i o s w = scales*\sqrt{ratios} w=scales∗ratios
说明: 这里使用面积为基准
- 保持不同长宽比的anchor具有相似的目标检测能力
- 避免某些anchor过大或过小导致的检测问题
- 更符合实际目标检测的需求
调用部分
python
# Generate Anchors
self.anchors = Variable(torch.from_numpy(utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
config.BACKBONE_SHAPES,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)).float(), requires_grad=False)实现部分
这里的scales是32,64,128,256,512,而对应的feature shape为256,128,64,32,16,即,在
256×256的特征图上生成面积为32×32的box;
128×128的特征图上生成面积为64×64的box;
...
16×16的特征图上生成面积为512×512的box.
python
def generate_pyramid_anchors(scales, ratios, feature_shapes, feature_strides,
anchor_stride):
"""Generate anchors at different levels of a feature pyramid. Each scale
is associated with a level of the pyramid, but each ratio is used in
all levels of the pyramid.
Returns:
anchors: [N, (y1, x1, y2, x2)]. All generated anchors in one array. Sorted
with the same order of the given scales. So, anchors of scale[0] come
first, then anchors of scale[1], and so on.
"""
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
anchors = []
for i in range(len(scales)): # [32, 64, 128, 256, 512]
anchors.append(generate_anchors(scales[i], ratios, feature_shapes[i],
feature_strides[i], anchor_stride))
return np.concatenate(anchors, axis=0)
python
def generate_anchors(scales, ratios, shape, feature_stride, anchor_stride):
"""
scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128]
ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2]
shape: [height, width] spatial shape of the feature map over which
to generate anchors.
feature_stride: Stride of the feature map relative to the image in pixels.
anchor_stride: Stride of anchors on the feature map. For example, if the
value is 2 then generate anchors for every other feature map pixel.
"""
# 获取所有尺度和长宽比的组合
scales, ratios = np.meshgrid(np.array(scales), np.array(ratios))
# scales: [[32,64,128], [32,64,128], [32,64,128]]
# ratios: [[0.5,0.5,0.5], [1,1,1], [2,2,2]]
scales = scales.flatten() # [32, 64, 128, 32, 64, 128, 32, 64, 128]
ratios = ratios.flatten() # [0.5, 0.5, 0.5, 1, 1, 1, 2, 2, 2]
# 根据尺度和长宽比计算高度和宽度
heights = scales / np.sqrt(ratios) # [45.25, 90.51, 181.02, 32, 64, 128, 22.63, 45.25, 90.51]
widths = scales * np.sqrt(ratios) # [22.63, 45.25, 90.51, 32, 64, 128, 45.25, 90.51, 181.02]
# 在特征空间生成偏移量(锚框中心点位置)
shifts_y = np.arange(0, shape[0], anchor_stride) * feature_stride # [0, 16] (假设shape[0]=2, feature_stride=16)
shifts_x = np.arange(0, shape[1], anchor_stride) * feature_stride # [0, 16, 32] (假设shape[1]=3, feature_stride=16)
shifts_x, shifts_y = np.meshgrid(shifts_x, shifts_y)
# shifts_x: [[0,16,32], [0,16,32]]
# shifts_y: [[0,0,0], [16,16,16]]
# 生成偏移量、宽度和高度的所有组合
box_widths, box_centers_x = np.meshgrid(widths, shifts_x)
# box_widths: 9种宽度重复6次,形状(6,9)
# box_centers_x: 6个x中心点重复9次,形状(6,9)
box_heights, box_centers_y = np.meshgrid(heights, shifts_y)
# box_heights: 9种高度重复6次,形状(6,9)
# box_centers_y: 6个y中心点重复9次,形状(6,9)
# 重塑为(y,x)坐标列表和(h,w)尺寸列表
box_centers = np.stack([box_centers_y, box_centers_x], axis=2).reshape([-1, 2])
# box_centers: [[0,0], [0,0], ..., [16,32]] 共54行(6位置×9尺寸)
box_sizes = np.stack([box_heights, box_widths], axis=2).reshape([-1, 2])
# box_sizes: [[45.25,22.63], [90.51,45.25], ..., [90.51,181.02]] 共54行
# 转换为角点坐标(y1, x1, y2, x2)
boxes = np.concatenate([box_centers - 0.5 * box_sizes, # 左上角坐标
box_centers + 0.5 * box_sizes], axis=1) # 右下角坐标
# boxes: [[-22.63,-11.31,22.63,11.31], ..., 共54个边界框]1.3 RPN
梗概: 返回 对anchor进行粗分类(前景还是背景)**, 坐标的回归值(偏移量)
RPN(Region Proposal Network)网络用于生成候选区域,这部分之前在Faster R-CNN中有介绍,点击查看

对每个特征图都进行:
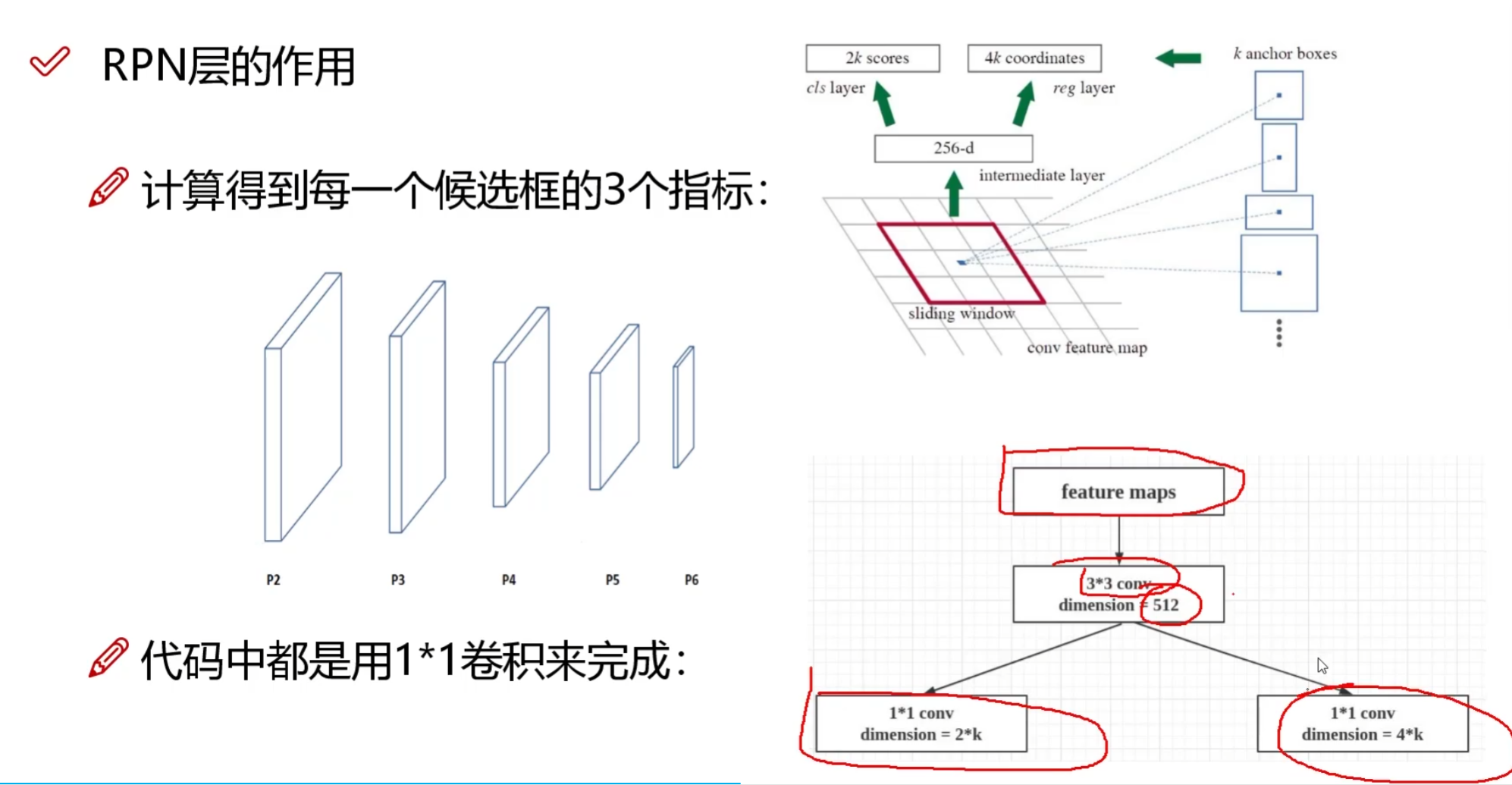
实例化部分
python
# RPN
self.rpn = RPN(len(config.RPN_ANCHOR_RATIOS), config.RPN_ANCHOR_STRIDE, 256)rpn层的调用部分
python
# Feature extraction
[p2_out, p3_out, p4_out, p5_out, p6_out] = self.fpn(molded_images)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [p2_out, p3_out, p4_out, p5_out, p6_out]
mrcnn_feature_maps = [p2_out, p3_out, p4_out, p5_out]
# Loop through pyramid layers
layer_outputs = [] # list of lists
for p in rpn_feature_maps:
layer_outputs.append(self.rpn(p))
# Concatenate layer outputs
# Convert from list of lists of level outputs to list of lists
# of outputs across levels.
# e.g. [[a1, b1, c1], [a2, b2, c2]] => [[a1, a2], [b1, b2], [c1, c2]]
# 将每个特征图产生的结果合并
outputs = list(zip(*layer_outputs))
outputs = [torch.cat(list(o), dim=1) for o in outputs]
rpn_class_logits, rpn_class, rpn_bbox = outputs rpn层实现,
对fpn的每一个特征图都都经过rpn层,有两个分支,一个是分类分支,判断是前景还是背景;一个是回归分支,判断框的位置。
说明:
这里的anchors_per_location=3,因为是多尺度的,anchor会分配到不同的尺度上进行裁剪,所以特征图上的每个像素有三种(1:2,1:1,2:1)
python
class RPN(nn.Module):
"""Builds the model of Region Proposal Network.
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
Returns:
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
def __init__(self, anchors_per_location, anchor_stride, depth):
super(RPN, self).__init__()
self.anchors_per_location = anchors_per_location
self.anchor_stride = anchor_stride
self.depth = depth
self.padding = SamePad2d(kernel_size=3, stride=self.anchor_stride)
self.conv_shared = nn.Conv2d(self.depth, 512, kernel_size=3, stride=self.anchor_stride)
self.relu = nn.ReLU(inplace=True)
self.conv_class = nn.Conv2d(512, 2 * anchors_per_location, kernel_size=1, stride=1)
self.softmax = nn.Softmax(dim=2)
self.conv_bbox = nn.Conv2d(512, 4 * anchors_per_location, kernel_size=1, stride=1)
def forward(self, x):
# Shared convolutional base of the RPN
x = self.relu(self.conv_shared(self.padding(x)))
# Anchor Score. [batch, anchors per location * 2, height, width].
rpn_class_logits = self.conv_class(x)
# Reshape to [batch, 2, anchors]
rpn_class_logits = rpn_class_logits.permute(0,2,3,1)
rpn_class_logits = rpn_class_logits.contiguous()
rpn_class_logits = rpn_class_logits.view(x.size()[0], -1, 2)
# Softmax on last dimension of BG/FG.
rpn_probs = self.softmax(rpn_class_logits)
# Bounding box refinement. [batch, H, W, anchors per location, depth]
# where depth is [x, y, log(w), log(h)]
rpn_bbox = self.conv_bbox(x)
# Reshape to [batch, 4, anchors]
rpn_bbox = rpn_bbox.permute(0,2,3,1)
rpn_bbox = rpn_bbox.contiguous()
rpn_bbox = rpn_bbox.view(x.size()[0], -1, 4)
return [rpn_class_logits, rpn_probs, rpn_bbox]1.4 Proposal Layer
梗概: 根据rpn的结果(分类、坐标回归值)调整anchor(候选框=anchor box +坐标回归值),并对anchor进行过滤,返回候选框。
说明: 训练时可能有2k候选框,推理时只有1k候选框。
python
# Generate proposals
# Proposals are [batch, N, (y1, x1, y2, x2)] in normalized coordinates
# and zero padded.
# 需要多少个候选框
proposal_count = self.config.POST_NMS_ROIS_TRAINING if mode == "training" \
else self.config.POST_NMS_ROIS_INFERENCE
rpn_rois = proposal_layer([rpn_class, rpn_bbox],
proposal_count=proposal_count,
nms_threshold=self.config.RPN_NMS_THRESHOLD,
anchors=self.anchors,
config=self.config)现在我们有两部分信息,一个是生成的anchor,一个上面rpn层的分类结果(前景还是背景)和坐标回归(偏移量)结果。
这一步就是根据分类结果和回归结果,筛选出部分前景的anchor,并调整其坐标(加上偏移量)。
步骤:
- 取得分最高的6000个anchor
- 根据delta调整anchor
- 框超过图像边界的进行裁剪
- 非极大值抑制,去除重叠的框
- 归一化坐标
实现部分
python
def apply_box_deltas(boxes, deltas):
"""Applies the given deltas to the given boxes.
boxes: [N, 4] where each row is y1, x1, y2, x2
deltas: [N, 4] where each row is [dy, dx, log(dh), log(dw)]
"""
# 1. anchor是(y1,x1,y2,x2) 转成(y, x, h, w)
# Convert to y, x, h, w
height = boxes[:, 2] - boxes[:, 0]
width = boxes[:, 3] - boxes[:, 1]
center_y = boxes[:, 0] + 0.5 * height
center_x = boxes[:, 1] + 0.5 * width
# 2. 根据delta调整anchor
# Apply deltas
center_y += deltas[:, 0] * height
center_x += deltas[:, 1] * width
height *= torch.exp(deltas[:, 2])
width *= torch.exp(deltas[:, 3])
# 3. 调整后的anchor转回(y1,x1,y2,x2)
# Convert back to y1, x1, y2, x2
y1 = center_y - 0.5 * height
x1 = center_x - 0.5 * width
y2 = y1 + height
x2 = x1 + width
result = torch.stack([y1, x1, y2, x2], dim=1)
return result
def clip_boxes(boxes, window):
"""
boxes: [N, 4] each col is y1, x1, y2, x2
window: [4] in the form y1, x1, y2, x2
"""
boxes = torch.stack( \
[boxes[:, 0].clamp(float(window[0]), float(window[2])),
boxes[:, 1].clamp(float(window[1]), float(window[3])),
boxes[:, 2].clamp(float(window[0]), float(window[2])),
boxes[:, 3].clamp(float(window[1]), float(window[3]))], 1)
return boxes
def proposal_layer(inputs, proposal_count, nms_threshold, anchors, config=None):
"""Receives anchor scores and selects a subset to pass as proposals
to the second stage. Filtering is done based on anchor scores and
non-max suppression to remove overlaps. It also applies bounding
box refinment detals to anchors.
Inputs:
rpn_probs: [batch, anchors, (bg prob, fg prob)]
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
Returns:
Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)]
"""
# 1. input: [rpn_class, rpn_bbox]
# Currently only supports batchsize 1
inputs[0] = inputs[0].squeeze(0) # rpn_class
inputs[1] = inputs[1].squeeze(0) # rpn_bbox
# Box Scores. Use the foreground class confidence. [Batch, num_rois, 1]
# 取前景的得分值
scores = inputs[0][:, 1]
# Box deltas [batch, num_rois, 4]
deltas = inputs[1] # box偏移量 的(dx,dy,log(dh),log(dw))
std_dev = Variable(torch.from_numpy(np.reshape(config.RPN_BBOX_STD_DEV, [1, 4])).float(), requires_grad=False)
if config.GPU_COUNT:
std_dev = std_dev.cuda()
deltas = deltas * std_dev # 乘以标准差,还原到实际偏移量
# 2. 取得分最高的6000个anchor
# Improve performance by trimming to top anchors by score
# and doing the rest on the smaller subset.
pre_nms_limit = min(6000, anchors.size()[0]) # 设置上限,只处理6000个anchor
scores, order = scores.sort(descending=True) # 得分降序
order = order[:pre_nms_limit] # 得分最高的索引
scores = scores[:pre_nms_limit]
deltas = deltas[order.data, :] # TODO: Support batch size > 1 ff. 6000个anchor对应的(dx,dy,log(dh),log(dw))
anchors = anchors[order.data, :] # 6000个anchor
# 3. 根据delta调整anchor
# Apply deltas to anchors to get refined anchors.
# [batch, N, (y1, x1, y2, x2)]
boxes = apply_box_deltas(anchors, deltas)
# 4. 框超过图像边界的进行裁剪
# Clip to image boundaries. [batch, N, (y1, x1, y2, x2)]
height, width = config.IMAGE_SHAPE[:2]
window = np.array([0, 0, height, width]).astype(np.float32)
boxes = clip_boxes(boxes, window)
# Filter out small boxes
# According to Xinlei Chen's paper, this reduces detection accuracy
# for small objects, so we're skipping it.
# 5. Non-max suppression
keep = nms(torch.cat((boxes, scores.unsqueeze(1)), 1).data, nms_threshold)
keep = keep[:proposal_count]
boxes = boxes[keep, :]
# 6. 归一化操作
# Normalize dimensions to range of 0 to 1.
norm = Variable(torch.from_numpy(np.array([height, width, height, width])).float(), requires_grad=False)
if config.GPU_COUNT:
norm = norm.cuda()
normalized_boxes = boxes / norm
# Add back batch dimension
normalized_boxes = normalized_boxes.unsqueeze(0)
return normalized_boxes1.5 dataset
我们看下训练数据是如何准备的,训练时需要准备两份信息一份是图片相关信息(image,gt_class_ids,gt_boxes,gt_masks)这个用于最后的精确分类和回归。
另一份是rpn相关信息(rpn_match,rpn_bbox)这个用于在rpn层对候选框粗分类。
1.5.1 rpn_targets 建立
正样本:
- iou>0.7
- gt对应最大iou的anchor
负样本:
iou<0.3
正负样本都不超过一半。
具体,
- anchor粗分类,正负中立样本(根据规则)->rpn_match
- 计算gt和对应的anchor的偏移量 ->rpn_bbox
python
def build_rpn_targets(image_shape, anchors, gt_class_ids, gt_boxes, config):
"""Given the anchors and GT boxes, compute overlaps and identify positive
anchors and deltas to refine them to match their corresponding GT boxes.
anchors: [num_anchors, (y1, x1, y2, x2)]
gt_class_ids: [num_gt_boxes] Integer class IDs.
gt_boxes: [num_gt_boxes, (y1, x1, y2, x2)]
Returns:
rpn_match: [N] (int32) matches between anchors and GT boxes.
1 = positive anchor, -1 = negative anchor, 0 = neutral
rpn_bbox: [N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
"""
# 正负anchor位置
# RPN Match: 1 = positive anchor, -1 = negative anchor, 0 = neutral
rpn_match = np.zeros([anchors.shape[0]], dtype=np.int32)
# 每张图的用于训练的最大anchor数
# RPN bounding boxes: [max anchors per image, (dy, dx, log(dh), log(dw))]
rpn_bbox = np.zeros((config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4)) # (256,4)
# ----------------------------------------------------------------------------------------------
# 找出非多物体的anchor
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
crowd_ix = np.where(gt_class_ids < 0)[0]
if crowd_ix.shape[0] > 0:
# Filter out crowds from ground truth class IDs and boxes
non_crowd_ix = np.where(gt_class_ids > 0)[0]
crowd_boxes = gt_boxes[crowd_ix]
gt_class_ids = gt_class_ids[non_crowd_ix]
gt_boxes = gt_boxes[non_crowd_ix]
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = utils.compute_overlaps(anchors, crowd_boxes)
crowd_iou_max = np.amax(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
else:
# All anchors don't intersect a crowd
no_crowd_bool = np.ones([anchors.shape[0]], dtype=bool)
# ----------------------------------------------------------------------------------------------
# 计算anchor与gt_boxes的IoU
# Compute overlaps [num_anchors, num_gt_boxes]
overlaps = utils.compute_overlaps(anchors, gt_boxes)
# Match anchors to GT Boxes
# If an anchor overlaps a GT box with IoU >= 0.7 then it's positive.
# If an anchor overlaps a GT box with IoU < 0.3 then it's negative.
# Neutral anchors are those that don't match the conditions above,
# and they don't influence the loss function.
# However, don't keep any GT box unmatched (rare, but happens). Instead,
# match it to the closest anchor (even if its max IoU is < 0.3).
#
# ----------------------------------------------------------------------------------------------
# 设置正负样本
# 1. Set negative anchors first. They get overwritten below if a GT box is
# matched to them. Skip boxes in crowd areas.
# 设置负样本
anchor_iou_argmax = np.argmax(overlaps, axis=1) # 每个anchor与哪个gt_box的IoU最大
anchor_iou_max = overlaps[np.arange(overlaps.shape[0]), anchor_iou_argmax] # 每个anchor与IoU最大的gt_box的IoU值
rpn_match[(anchor_iou_max < 0.3) & (no_crowd_bool)] = -1 # IoU小于0.3的anchor为负样本
# 2. Set an anchor for each GT box (regardless of IoU value).
# TODO: If multiple anchors have the same IoU match all of them
gt_iou_argmax = np.argmax(overlaps, axis=0) # 每个gt_box与哪个anchor的IoU最大
rpn_match[gt_iou_argmax] = 1 # 规则1,每个gt_box对应一个anchor,为正样本
# 3. Set anchors with high overlap as positive.
rpn_match[anchor_iou_max >= 0.7] = 1 # 规则2, IoU大于0.7的anchor为正样本
# ----------------------------------------------------------------------------------------------
# 设置正负样本数量,正样本不超过一半
# Subsample to balance positive and negative anchors
# Don't let positives be more than half the anchors
ids = np.where(rpn_match == 1)[0] # 正样本的索引
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2) # 正样本数超过一半的个数
#
if extra > 0:
# Reset the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0 # 正样本数超过一半的anchor置为0
# Same for negative proposals
# 同样限制负样本数量
ids = np.where(rpn_match == -1)[0] # 负样本的索引
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE -
np.sum(rpn_match == 1)) # 负样本数超过一半的个数
if extra > 0:
# Rest the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0 # 负样本数超过一半的anchor置为0
# ----------------------------------------------------------------------------------------------
# 计算正样本的偏移量,负样本不需要计算偏移量
# For positive anchors, compute shift and scale needed to transform them
# to match the corresponding GT boxes.
ids = np.where(rpn_match == 1)[0] # 正样本的索引
ix = 0 # index into rpn_bbox
# TODO: use box_refinment() rather than duplicating the code here
for i, a in zip(ids, anchors[ids]):
# Closest gt box (it might have IoU < 0.7)
gt = gt_boxes[anchor_iou_argmax[i]] #
# Convert coordinates to center plus width/height.
# GT Box,(y1, x1, y2, x2) -> (center_y, center_x, height, width)
gt_h = gt[2] - gt[0]
gt_w = gt[3] - gt[1]
gt_center_y = gt[0] + 0.5 * gt_h
gt_center_x = gt[1] + 0.5 * gt_w
# Anchor, (y1, x1, y2, x2) -> (center_y, center_x, height, width)
a_h = a[2] - a[0]
a_w = a[3] - a[1]
a_center_y = a[0] + 0.5 * a_h
a_center_x = a[1] + 0.5 * a_w
# Compute the bbox refinement that the RPN should predict.
# (dy, dx, log(dh), log(dw)) gt相对于anchor的偏移量
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / a_h,
(gt_center_x - a_center_x) / a_w,
np.log(gt_h / a_h),
np.log(gt_w / a_w),
]
# Normalize
rpn_bbox[ix] /= config.RPN_BBOX_STD_DEV # 标准化,后需要反标准化
ix += 1
return rpn_match, rpn_bbox1.5.2 dataset
获取rpn和最后的标签
python
class Dataset(torch.utils.data.Dataset):
def __init__(self, dataset, config, augment=True):
"""A generator that returns images and corresponding target class ids,
bounding box deltas, and masks.
dataset: The Dataset object to pick data from
config: The model config object
shuffle: If True, shuffles the samples before every epoch
augment: If True, applies image augmentation to images (currently only
horizontal flips are supported)
Returns a Python generator. Upon calling next() on it, the
generator returns two lists, inputs and outputs. The containtes
of the lists differs depending on the received arguments:
inputs list:
- images: [batch, H, W, C]
- image_metas: [batch, size of image meta]
- rpn_match: [batch, N] Integer (1=positive anchor, -1=negative, 0=neutral)
- rpn_bbox: [batch, N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
- gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs
- gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]
- gt_masks: [batch, height, width, MAX_GT_INSTANCES]. The height and width
are those of the image unless use_mini_mask is True, in which
case they are defined in MINI_MASK_SHAPE.
outputs list: Usually empty in regular training. But if detection_targets
is True then the outputs list contains target class_ids, bbox deltas,
and masks.
"""
self.b = 0 # batch item index
self.image_index = -1
self.image_ids = np.copy(dataset.image_ids)
self.error_count = 0
self.dataset = dataset
self.config = config
self.augment = augment
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
self.anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
config.BACKBONE_SHAPES,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)
def __getitem__(self, image_index):
# Get GT bounding boxes and masks for image.
image_id = self.image_ids[image_index]
image, image_metas, gt_class_ids, gt_boxes, gt_masks = \
load_image_gt(self.dataset, self.config, image_id, augment=self.augment,
use_mini_mask=self.config.USE_MINI_MASK)
# Skip images that have no instances. This can happen in cases
# where we train on a subset of classes and the image doesn't
# have any of the classes we care about.
if not np.any(gt_class_ids > 0):
return None
# RPN Targets
rpn_match, rpn_bbox = build_rpn_targets(image.shape, self.anchors,
gt_class_ids, gt_boxes, self.config)
# If more instances than fits in the array, sub-sample from them.
#
if gt_boxes.shape[0] > self.config.MAX_GT_INSTANCES:
ids = np.random.choice(
np.arange(gt_boxes.shape[0]), self.config.MAX_GT_INSTANCES, replace=False)
gt_class_ids = gt_class_ids[ids]
gt_boxes = gt_boxes[ids]
gt_masks = gt_masks[:, :, ids]
# Add to batch
rpn_match = rpn_match[:, np.newaxis]
images = mold_image(image.astype(np.float32), self.config)
# Convert
images = torch.from_numpy(images.transpose(2, 0, 1)).float()
image_metas = torch.from_numpy(image_metas)
rpn_match = torch.from_numpy(rpn_match)
rpn_bbox = torch.from_numpy(rpn_bbox).float()
gt_class_ids = torch.from_numpy(gt_class_ids)
gt_boxes = torch.from_numpy(gt_boxes).float()
gt_masks = torch.from_numpy(gt_masks.astype(int).transpose(2, 0, 1)).float()
return images, image_metas, rpn_match, rpn_bbox, gt_class_ids, gt_boxes, gt_masks
def __len__(self):
return self.image_ids.shape[0]1.6 detection_target_layer
梗概: 对proposals筛选的候选框(训练2k,推理1k)进一步筛选,分为正负样本,找到正样本对应的gt信息,最终 得到200个roi(正负样本1:3,负样本用gt信息用0填充)
具体,
- 从候选框(proposals)中采样正负样本
- 为每个样本生成对应的类别ID、边界框回归目标(delta)和分割掩码(mask)
- 保持正负样本的比例平衡
调用部分:
python
rois, target_class_ids, target_deltas, target_mask = \
detection_target_layer(rpn_rois, gt_class_ids, gt_boxes, gt_masks, self.config)实现部分:
python
def detection_target_layer(proposals, gt_class_ids, gt_boxes, gt_masks, config):
"""Subsamples proposals and generates target box refinment, class_ids,
and masks for each.
Inputs:
proposals: [batch, N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs.
gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized
coordinates.
gt_masks: [batch, height, width, MAX_GT_INSTANCES] of boolean type
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized
coordinates
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE]. Integer class IDs.
target_deltas: [batch, TRAIN_ROIS_PER_IMAGE, NUM_CLASSES,
(dy, dx, log(dh), log(dw), class_id)]
Class-specific bbox refinments.
target_mask: [batch, TRAIN_ROIS_PER_IMAGE, height, width)
Masks cropped to bbox boundaries and resized to neural
network output size.
"""
# Currently only supports batchsize 1
proposals = proposals.squeeze(0)
gt_class_ids = gt_class_ids.squeeze(0)
gt_boxes = gt_boxes.squeeze(0)
gt_masks = gt_masks.squeeze(0)
# -- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# 1. 区分多物体和非多物体
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
if torch.nonzero(gt_class_ids < 0).size():
crowd_ix = torch.nonzero(gt_class_ids < 0)[:, 0] # 多物体索引
non_crowd_ix = torch.nonzero(gt_class_ids > 0)[:, 0] # 非多物体索引
crowd_boxes = gt_boxes[crowd_ix.data, :]
crowd_masks = gt_masks[crowd_ix.data, :, :]
# 非多物体的gt_class_ids, gt_boxes, gt_masks
gt_class_ids = gt_class_ids[non_crowd_ix.data]
gt_boxes = gt_boxes[non_crowd_ix.data, :]
gt_masks = gt_masks[non_crowd_ix.data, :]
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = bbox_overlaps(proposals, crowd_boxes)
crowd_iou_max = torch.max(crowd_overlaps, dim=1)[0]
no_crowd_bool = crowd_iou_max < 0.001
else:
no_crowd_bool = Variable(torch.ByteTensor(proposals.size()[0]*[True]), requires_grad=False)
if config.GPU_COUNT:
no_crowd_bool = no_crowd_bool.cuda()
# ----------------------------------------------------------------------------------------------
# 2. 根据IoU筛选出正样本
# Compute overlaps matrix [proposals, gt_boxes]
overlaps = bbox_overlaps(proposals, gt_boxes) # 候选框与真实框质检的IOU
# Determine postive and negative ROIs
roi_iou_max = torch.max(overlaps, dim=1)[0] # 每个候选框与真实框质检的最大IOU
# 1. Positive ROIs are those with >= 0.5 IoU with a GT box
positive_roi_bool = roi_iou_max >= 0.5 # IoU大于0.5的候选框为正样本
# Subsample ROIs. Aim for 33% positive
# Positive ROIs
if torch.nonzero(positive_roi_bool).size():
positive_indices = torch.nonzero(positive_roi_bool)[:, 0] # 正样本索引
positive_count = int(config.TRAIN_ROIS_PER_IMAGE * # 正样本数量 ,总样本:200
config.ROI_POSITIVE_RATIO) # 正样本比例:0.33
rand_idx = torch.randperm(positive_indices.size()[0]) # 打乱正样本索引
rand_idx = rand_idx[:positive_count] # 取前positive_count个正样本索引
if config.GPU_COUNT:
rand_idx = rand_idx.cuda() # GPU加速
positive_indices = positive_indices[rand_idx] # 正样本索引
positive_count = positive_indices.size()[0] # 正样本数量
positive_rois = proposals[positive_indices.data,:] # 正样本
# Assign positive ROIs to GT boxes.
positive_overlaps = overlaps[positive_indices.data,:] # 正样本与真实框质检的IOU
roi_gt_box_assignment = torch.max(positive_overlaps, dim=1)[1] # 正样本对应的真实框索引
roi_gt_boxes = gt_boxes[roi_gt_box_assignment.data,:] # 正样本对应的真实框
roi_gt_class_ids = gt_class_ids[roi_gt_box_assignment.data] # 正样本对应的真实框类别
# 计算偏移量并归一化
# Compute bbox refinement for positive ROIs
deltas = Variable(utils.box_refinement(positive_rois.data, roi_gt_boxes.data), requires_grad=False)
std_dev = Variable(torch.from_numpy(config.BBOX_STD_DEV).float(), requires_grad=False)
if config.GPU_COUNT:
std_dev = std_dev.cuda()
deltas /= std_dev
# Assign positive ROIs to GT masks
roi_masks = gt_masks[roi_gt_box_assignment.data,:,:] # 正样本对应的真实框掩码
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI corrdinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = positive_rois.chunk(4, dim=1) # 候选框坐标
gt_y1, gt_x1, gt_y2, gt_x2 = roi_gt_boxes.chunk(4, dim=1) # 真实框坐标
gt_h = gt_y2 - gt_y1 # 真实框高度
gt_w = gt_x2 - gt_x1 # 真实框宽度
y1 = (y1 - gt_y1) / gt_h # 候选框坐标归一化
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = torch.cat([y1, x1, y2, x2], dim=1)
box_ids = Variable(torch.arange(roi_masks.size()[0]), requires_grad=False).int()
if config.GPU_COUNT:
box_ids = box_ids.cuda()
masks = Variable(CropAndResizeFunction(config.MASK_SHAPE[0], config.MASK_SHAPE[1], 0)(roi_masks.unsqueeze(1), boxes, box_ids).data, requires_grad=False)
masks = masks.squeeze(1)
# Threshold mask pixels at 0.5 to have GT masks be 0 or 1 to use with
# binary cross entropy loss.
masks = torch.round(masks)
else:
positive_count = 0
# ----------------------------------------------------------------------------------------------
# 负样本
# 2. Negative ROIs are those with < 0.5 with every GT box. Skip crowds.
negative_roi_bool = roi_iou_max < 0.5 # IoU小于0.5的候选框为负样本
negative_roi_bool = negative_roi_bool & no_crowd_bool # 排除多物体
# Negative ROIs. Add enough to maintain positive:negative ratio.
if torch.nonzero(negative_roi_bool).size() and positive_count>0:
negative_indices = torch.nonzero(negative_roi_bool)[:, 0] # 负样本索引
r = 1.0 / config.ROI_POSITIVE_RATIO # 正负样本比例
negative_count = int(r * positive_count - positive_count) # 负样本数量
rand_idx = torch.randperm(negative_indices.size()[0]) # 打乱负样本索引
rand_idx = rand_idx[:negative_count] # 取前negative_count个负样本索引
if config.GPU_COUNT:
rand_idx = rand_idx.cuda()
negative_indices = negative_indices[rand_idx] # 负样本索引
negative_count = negative_indices.size()[0] # 负样本数量
negative_rois = proposals[negative_indices.data, :] # 负样本
else:
negative_count = 0
# -----------------------------------------------------------------------------------------------
# Append negative ROIs and pad bbox deltas and masks that
# are not used for negative ROIs with zeros.
# 正负样本都有
if positive_count > 0 and negative_count > 0:
# 1. 负样本候选框
rois = torch.cat((positive_rois, negative_rois), dim=0) # 候选框
zeros = Variable(torch.zeros(negative_count), requires_grad=False).int()
if config.GPU_COUNT:
zeros = zeros.cuda()
roi_gt_class_ids = torch.cat([roi_gt_class_ids, zeros], dim=0)
# 2. 负样本偏移量
zeros = Variable(torch.zeros(negative_count,4), requires_grad=False)
if config.GPU_COUNT:
zeros = zeros.cuda()
deltas = torch.cat([deltas, zeros], dim=0)
# 3. 负样本掩码
zeros = Variable(torch.zeros(negative_count,config.MASK_SHAPE[0],config.MASK_SHAPE[1]), requires_grad=False)
if config.GPU_COUNT:
zeros = zeros.cuda()
masks = torch.cat([masks, zeros], dim=0)
# 正样本有
elif positive_count > 0:
rois = positive_rois
# 负样本有
elif negative_count > 0:
# 1. 负样本候选框
rois = negative_rois
zeros = Variable(torch.zeros(negative_count), requires_grad=False)
if config.GPU_COUNT:
zeros = zeros.cuda()
roi_gt_class_ids = zeros
# 2. 负样本偏移量
zeros = Variable(torch.zeros(negative_count,4), requires_grad=False).int()
if config.GPU_COUNT:
zeros = zeros.cuda()
deltas = zeros
# 3. 负样本掩码
zeros = Variable(torch.zeros(negative_count,config.MASK_SHAPE[0],config.MASK_SHAPE[1]), requires_grad=False)
if config.GPU_COUNT:
zeros = zeros.cuda()
masks = zeros
# 没有正负样本
else:
rois = Variable(torch.FloatTensor(), requires_grad=False)
roi_gt_class_ids = Variable(torch.IntTensor(), requires_grad=False)
deltas = Variable(torch.FloatTensor(), requires_grad=False)
masks = Variable(torch.FloatTensor(), requires_grad=False)
if config.GPU_COUNT:
rois = rois.cuda()
roi_gt_class_ids = roi_gt_class_ids.cuda()
deltas = deltas.cuda()
masks = masks.cuda()
return rois, roi_gt_class_ids, deltas, masks1.7 classifier
梗概: 这一步是对候选框进行第二阶段分类(分具体的类别)和回归。
现在我们有了一堆候选框,接下来我们需要对每个候选框进行分类和回归。这一步是通过一个分类器和一个回归器来完成的。分类器用于判断候选框中是否包含目标,回归器用于预测候选框中目标的边界框。
调用部分:
python
# Network Heads
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rois)说明: 其中输入来着p2-p5,不包含p6
python
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [p2_out, p3_out, p4_out, p5_out, p6_out]
mrcnn_feature_maps = [p2_out, p3_out, p4_out, p5_out]实现部分:
python
class Classifier(nn.Module):
def __init__(self, depth, pool_size, image_shape, num_classes):
super(Classifier, self).__init__()
self.depth = depth
self.pool_size = pool_size
self.image_shape = image_shape
self.num_classes = num_classes
self.conv1 = nn.Conv2d(self.depth, 1024, kernel_size=self.pool_size, stride=1)
self.bn1 = nn.BatchNorm2d(1024, eps=0.001, momentum=0.01)
self.conv2 = nn.Conv2d(1024, 1024, kernel_size=1, stride=1)
self.bn2 = nn.BatchNorm2d(1024, eps=0.001, momentum=0.01)
self.relu = nn.ReLU(inplace=True)
self.linear_class = nn.Linear(1024, num_classes)
self.softmax = nn.Softmax(dim=1)
self.linear_bbox = nn.Linear(1024, num_classes * 4)
def forward(self, x, rois):
x = pyramid_roi_align([rois]+x, self.pool_size, self.image_shape)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = x.view(-1,1024)
mrcnn_class_logits = self.linear_class(x) # 分类
mrcnn_probs = self.softmax(mrcnn_class_logits)
mrcnn_bbox = self.linear_bbox(x)
mrcnn_bbox = mrcnn_bbox.view(mrcnn_bbox.size()[0], -1, 4)
return [mrcnn_class_logits, mrcnn_probs, mrcnn_bbox]1.7.1 ROIAlign
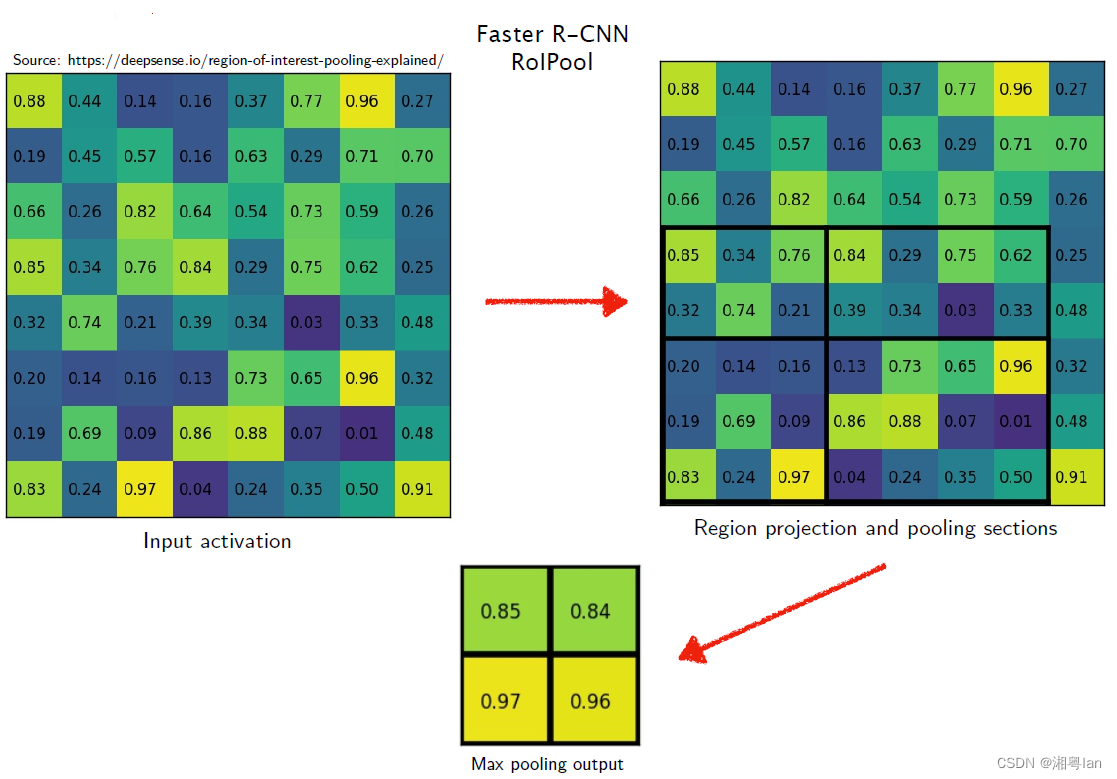
先说ROI Pooling,我们会用之前的候选框进行分类和回归,具体来说就是用候选框裁剪局部特征,然后做分类和回归。裁剪下来的局部特征图,大小的不一样的,所以会缩放到一个相同的尺度,这就是之前ROI Pooling要做的事。
再说裁剪,之前的一般单尺度的,即在backbone的某一个特征图上进行裁剪,现在是多尺度的,一种思路是上面我们得到的候选框在所有特征图上进行一次裁剪,另一种思路根据候选框的大小和特征图的大小进行分配,小的候选框在分辨率高的候选框上裁剪,大的候选框在分辨率低的特征图裁剪。
最后说ROIAlign,原图到特征图有一个缩放,那么候选框从原图到特征图上的变换,也会有一个缩放,比如缩放4倍,而候选框在原图上长宽为45×45,那么这里除不尽会存在一次取整操作,会丢失精度(特征图的候选变换为11×11)。上面我们提到会将裁剪结果pooling到7×7。这里从11到7又除不尽,有会丢失信息。
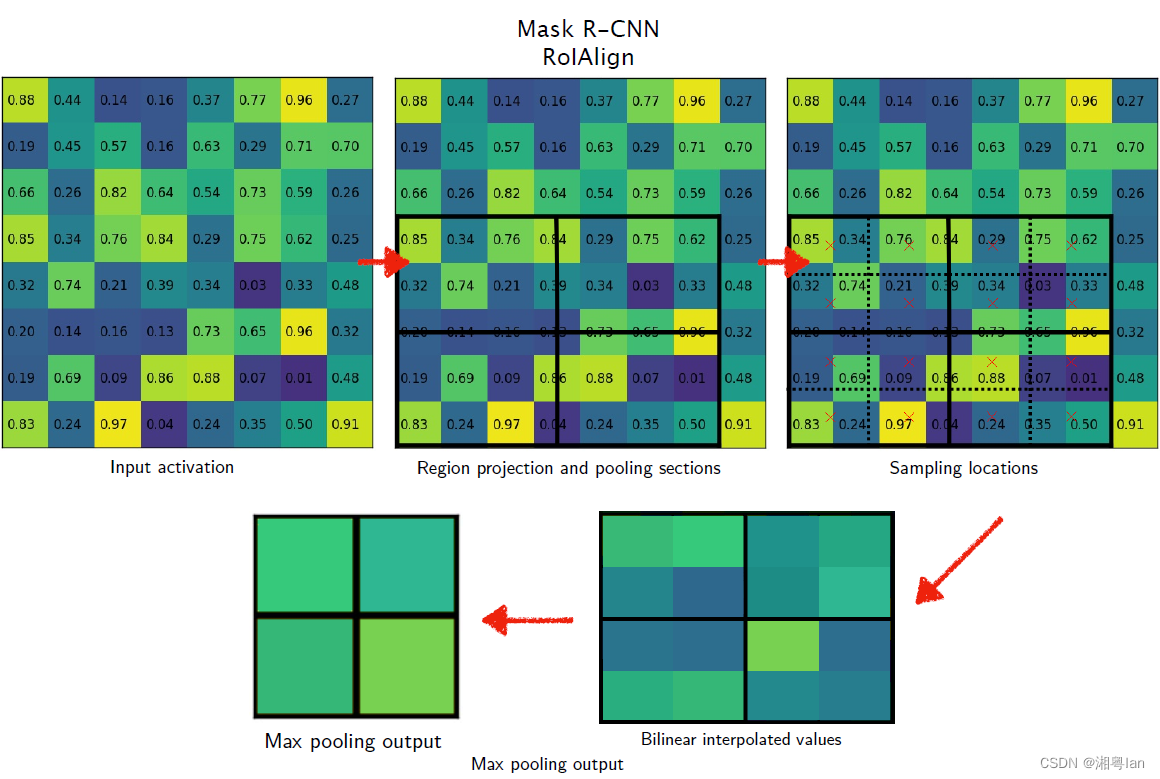
所以Mask-rcnn中提出了ROIAlign。
1.7.1.1 ROIAlign
原始的ROI Pooling
ROIAlign
1.7.1.2 分配规则
具体的分配的规则是根据公式,
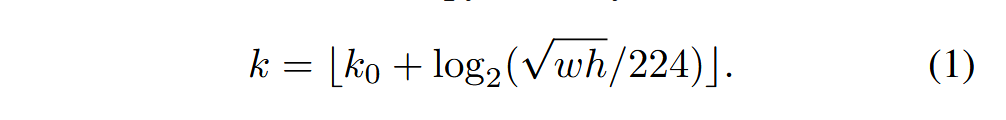
公式 1 来源于论文《Feature Pyramid Networks for Object Detection》的第 4.2 节。
该公式在 特征金字塔网络(Feature Pyramid Networks, FPN) 中用于 目标检测 应用,特别是当 FPN 被集成到 Fast R-CNN 检测器中时。
公式 1 及其作用
公式 (1) 的核心功能是确定 感兴趣区域 (Region-of-Interest, RoI) 应该从 FPN 的哪个特征金字塔层级 P k P_k Pk 中提取特征。
公式 (1):
k = ⌊ k 0 + log 2 ( w h 224 ) ⌋ (1) k = \left\lfloor k_0 + \log_2\left(\frac{\sqrt{wh}}{224}\right) \right\rfloor \quad \text{(1)} \text{} k=⌊k0+log2(224wh )⌋(1)
公式组成部分详解
| 符号 | 含义 | 解释与设定 | 来源 |
|---|---|---|---|
| k k k | 目标金字塔层级索引 | RoI 被分配到的 FPN 特征层级 P k P_k Pk 的索引。例如, P 2 , P 3 , P 4 , P 5 P_2, P_3, P_4, P_5 P2,P3,P4,P5 等。 | |
| w w w 和 h h h | RoI 的宽度和高度 | RoI 在输入图像上的尺寸。 w h \sqrt{wh} wh 代表 RoI 的尺度(即面积的平方根)。 | |
| 224 | 规范尺寸 | ImageNet 预训练时的标准输入尺寸。 | |
| k 0 k_0 k0 | 基准层级 | 规范尺寸 RoI 的目标映射层级。如果一个 RoI 的面积 w × h w \times h w×h 等于 22 4 2 224^2 2242,它将被映射到 P k 0 P_{k_0} Pk0 层。 | |
| ⌊ ... ⌋ \lfloor \dots \rfloor ⌊...⌋ | 向下取整函数 | 确保 k k k 是一个整数索引,用于确定最终的特征层级。 (原文使用 b ... c b\dots c b...c 符号,通常表示取整操作) | |
| 设定值 | 在 ResNet-based Faster R-CNN 系统中,由于 C 4 C_4 C4 层被用作单尺度特征图的基准,因此 k 0 k_0 k0 被设定为 4。 |
公式背后的机制与直觉*
该公式将 FPN 视为一个类似于 特征化图像金字塔 的结构,并据此调整了区域检测器(如 Fast R-CNN)的分配策略。
核心思路是:将小尺度的 RoI 映射到 FPN 中分辨率更高(索引 k k k 更小)的特征层,并将大尺度的 RoI 映射到分辨率较低但语义信息更强(索引 k k k 更大)的特征层。
直觉解释:
- RoI 尺度与规范尺寸的比率: w h 224 \frac{\sqrt{wh}}{224} 224wh 计算了当前 RoI 的尺度与规范尺度 224 之间的比率。
- 对数变换: log 2 ( ... ) \log_2(\dots) log2(...) 将该比率转换为以 2 为底的对数,这实际上反映了 RoI 尺度相对于基准尺度(224)的变化了多少个"八度"(即 2 的幂次)。
- 层级确定:
- 如果 RoI 的尺度恰好是规范尺寸 224 × 224 224 \times 224 224×224,则 log 2 ( ... ) = 0 \log_2(\dots)=0 log2(...)=0,此时 k = k 0 = 4 k = k_0=4 k=k0=4。
- 如果 RoI 的尺度较小(例如,尺度是 224 的一半),则 log 2 ( 1 2 ) = − 1 \log_2(\frac{1}{2}) = -1 log2(21)=−1。此时 k = k 0 − 1 = 3 k = k_0 - 1 = 3 k=k0−1=3,RoI 被分配到更高分辨率的 P 3 P_3 P3 层。
- 这确保了不同大小的 RoI 能够从与其尺度最匹配的特征图层级中提取特征,这对于多尺度目标检测(尤其是检测小目标)至关重要。
这种分配策略使得 FPN 能够利用卷积网络固有的金字塔结构,为所有尺度的 RoI 提供 语义信息丰富 的特征。
总结性比喻
理解公式 (1) 可以想象它像一个物流中心的自动分拣系统:
如果 FPN 是一个多层货架(金字塔层级 P k P_k Pk),每个货架对应一个分辨率(从小到大)。公式 (1) 就像一个条形码扫描仪:它扫描包裹(RoI)的尺寸,并立即计算出该包裹应该投放到哪个标准货架( P k P_k Pk),以确保小包裹被分配到精细的低层货架(高分辨率特征图),而大包裹被分配到粗糙的高层货架(低分辨率、高语义特征图)。这样,每个包裹都能得到最合适的处理,对应到目标检测中就是每个 RoI 都能提取到最适合其尺度的特征。
python
def pyramid_roi_align(inputs, pool_size, image_shape):
"""Implements ROI Pooling on multiple levels of the feature pyramid.
Params:
- pool_size: [height, width] of the output pooled regions. Usually [7, 7]
- image_shape: [height, width, channels]. Shape of input image in pixels
Inputs:
- boxes: [batch, num_boxes, (y1, x1, y2, x2)] in normalized
coordinates.
- Feature maps: List of feature maps from different levels of the pyramid.
Each is [batch, channels, height, width]
Output:
Pooled regions in the shape: [num_boxes, height, width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
# Currently only supports batchsize 1 input : [rois,feature maps]
for i in range(len(inputs)):
inputs[i] = inputs[i].squeeze(0)
# Crop boxes [batch, num_boxes, (y1, x1, y2, x2)] in normalized coords
boxes = inputs[0] # 归一化以后的boxes
# Feature Maps. List of feature maps from different level of the
# feature pyramid. Each is [batch, height, width, channels]
feature_maps = inputs[1:] # 不同的特征图 p2~p5
# ----------------------------------------------------------------------------------------------
# 根据ROI的面积,分配到不同的特征图上进行roi align操作
# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = boxes.chunk(4, dim=1)
h = y2 - y1
w = x2 - x1
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
image_area = Variable(torch.FloatTensor([float(image_shape[0]*image_shape[1])]), requires_grad=False)
if boxes.is_cuda:
image_area = image_area.cuda()
roi_level = 4 + log2(torch.sqrt(h*w)/(224.0/torch.sqrt(image_area)))
roi_level = roi_level.round().int()
roi_level = roi_level.clamp(2,5)
# Loop through levels and apply ROI pooling to each. P2 to P5.
pooled = []
box_to_level = []
for i, level in enumerate(range(2, 6)):
ix = roi_level==level
if not ix.any():
continue
ix = torch.nonzero(ix)[:,0]
level_boxes = boxes[ix.data, :] # 当前层特征图对应的boxes
# Keep track of which box is mapped to which level
box_to_level.append(ix.data)
# Stop gradient propogation to ROI proposals
level_boxes = level_boxes.detach()
# Crop and Resize
# From Mask R-CNN paper: "We sample four regular locations, so
# that we can evaluate either max or average pooling. In fact,
# interpolating only a single value at each bin center (without
# pooling) is nearly as effective."
#
# Here we use the simplified approach of a single value per bin,
# which is how it's done in tf.crop_and_resize()
# Result: [batch * num_boxes, pool_height, pool_width, channels]
ind = Variable(torch.zeros(level_boxes.size()[0]),requires_grad=False).int()
if level_boxes.is_cuda:
ind = ind.cuda()
# 当前层的特征图
feature_maps[i] = feature_maps[i].unsqueeze(0) #CropAndResizeFunction needs batch dimension
# 将不同大小的rois裁剪并resize到相同大小
pooled_features = CropAndResizeFunction(pool_size, pool_size, 0)(feature_maps[i], level_boxes, ind)
pooled.append(pooled_features)
# Pack pooled features into one tensor
pooled = torch.cat(pooled, dim=0)
# Pack box_to_level mapping into one array and add another
# column representing the order of pooled boxes
box_to_level = torch.cat(box_to_level, dim=0)
# Rearrange pooled features to match the order of the original boxes
_, box_to_level = torch.sort(box_to_level) # 按照原始boxes的顺序重新排列
pooled = pooled[box_to_level, :, :]
return pooled1.8 mask
调用部分
输入和上面的分类相同,p2-p5
python
# Create masks for detections
mrcnn_mask = self.mask(mrcnn_feature_maps, rois)注意最后使用的时sigmoid,对每一个类进行分类
实现部分
python
# Mask branch
class Mask(nn.Module):
def __init__(self, depth, pool_size, image_shape, num_classes):
super(Mask, self).__init__()
self.depth = depth
self.pool_size = pool_size
self.image_shape = image_shape
self.num_classes = num_classes
self.padding = SamePad2d(kernel_size=3, stride=1)
self.conv1 = nn.Conv2d(self.depth, 256, kernel_size=3, stride=1)
self.bn1 = nn.BatchNorm2d(256, eps=0.001)
self.conv2 = nn.Conv2d(256, 256, kernel_size=3, stride=1)
self.bn2 = nn.BatchNorm2d(256, eps=0.001)
self.conv3 = nn.Conv2d(256, 256, kernel_size=3, stride=1)
self.bn3 = nn.BatchNorm2d(256, eps=0.001)
self.conv4 = nn.Conv2d(256, 256, kernel_size=3, stride=1)
self.bn4 = nn.BatchNorm2d(256, eps=0.001)
self.deconv = nn.ConvTranspose2d(256, 256, kernel_size=2, stride=2)
self.conv5 = nn.Conv2d(256, num_classes, kernel_size=1, stride=1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU(inplace=True)
def forward(self, x, rois):
x = pyramid_roi_align([rois] + x, self.pool_size, self.image_shape)
x = self.conv1(self.padding(x))
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(self.padding(x))
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(self.padding(x))
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(self.padding(x))
x = self.bn4(x)
x = self.relu(x)
x = self.deconv(x)
x = self.relu(x)
x = self.conv5(x)
x = self.sigmoid(x)
return x1.9 损失
调用部分
python
# Run object detection
rpn_class_logits, rpn_pred_bbox, target_class_ids, mrcnn_class_logits, target_deltas, mrcnn_bbox, target_mask, mrcnn_mask = \
self.predict([images, image_metas, gt_class_ids, gt_boxes, gt_masks], mode='training')
rpn_class_loss, rpn_bbox_loss, mrcnn_class_loss, mrcnn_bbox_loss, mrcnn_mask_loss = compute_losses(rpn_match, rpn_bbox, rpn_class_logits, rpn_pred_bbox, target_class_ids, mrcnn_class_logits, target_deltas, mrcnn_bbox, target_mask, mrcnn_mask)
loss = rpn_class_loss + rpn_bbox_loss + mrcnn_class_loss + mrcnn_bbox_loss + mrcnn_mask_loss1.9.1 主体
一阶段会有一个rpn_match,正负样本的概念。
分类时,正负样本起作用,中立样本不起作用;
回归时,只有正样本起作用。
python
def compute_losses(rpn_match, rpn_bbox, rpn_class_logits, rpn_pred_bbox, target_class_ids, mrcnn_class_logits, target_deltas, mrcnn_bbox, target_mask, mrcnn_mask):
rpn_class_loss = compute_rpn_class_loss(rpn_match, rpn_class_logits) # rpn class
rpn_bbox_loss = compute_rpn_bbox_loss(rpn_bbox, rpn_match, rpn_pred_bbox) # rpn box
mrcnn_class_loss = compute_mrcnn_class_loss(target_class_ids, mrcnn_class_logits) # class
mrcnn_bbox_loss = compute_mrcnn_bbox_loss(target_deltas, target_class_ids, mrcnn_bbox) # box
mrcnn_mask_loss = compute_mrcnn_mask_loss(target_mask, target_class_ids, mrcnn_mask) # mask
return [rpn_class_loss, rpn_bbox_loss, mrcnn_class_loss, mrcnn_bbox_loss, mrcnn_mask_loss]1.一阶段class
python
def compute_rpn_class_loss(rpn_match, rpn_class_logits):
"""RPN anchor classifier loss.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_class_logits: [batch, anchors, 2]. RPN classifier logits for FG/BG.
"""
# Squeeze last dim to simplify
rpn_match = rpn_match.squeeze(2)
# Get anchor classes. Convert the -1/+1 match to 0/1 values.
anchor_class = (rpn_match == 1).long()
# Positive and Negative anchors contribute to the loss,
# but neutral anchors (match value = 0) don't.
indices = torch.nonzero(rpn_match != 0)
# Pick rows that contribute to the loss and filter out the rest.
rpn_class_logits = rpn_class_logits[indices.data[:,0],indices.data[:,1],:]
anchor_class = anchor_class[indices.data[:,0],indices.data[:,1]]
# Crossentropy loss
loss = F.cross_entropy(rpn_class_logits, anchor_class)
return loss2. 一阶段box
python
def compute_rpn_bbox_loss(target_bbox, rpn_match, rpn_bbox):
"""Return the RPN bounding box loss graph.
target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))].
Uses 0 padding to fill in unsed bbox deltas.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
"""
# Squeeze last dim to simplify
rpn_match = rpn_match.squeeze(2)
# Positive anchors contribute to the loss, but negative and
# neutral anchors (match value of 0 or -1) don't.
indices = torch.nonzero(rpn_match==1)
# Pick bbox deltas that contribute to the loss
rpn_bbox = rpn_bbox[indices.data[:,0],indices.data[:,1]]
# Trim target bounding box deltas to the same length as rpn_bbox.
target_bbox = target_bbox[0,:rpn_bbox.size()[0],:]
# Smooth L1 loss
loss = F.smooth_l1_loss(rpn_bbox, target_bbox)
return loss3. 二阶段class
python
def compute_mrcnn_class_loss(target_class_ids, pred_class_logits):
"""Loss for the classifier head of Mask RCNN.
target_class_ids: [batch, num_rois]. Integer class IDs. Uses zero
padding to fill in the array.
pred_class_logits: [batch, num_rois, num_classes]
"""
# Loss
if target_class_ids.size():
loss = F.cross_entropy(pred_class_logits,target_class_ids.long())
else:
loss = Variable(torch.FloatTensor([0]), requires_grad=False)
if target_class_ids.is_cuda:
loss = loss.cuda()
return loss4. 二阶段box
只计算正样本box
python
def compute_mrcnn_bbox_loss(target_bbox, target_class_ids, pred_bbox):
"""Loss for Mask R-CNN bounding box refinement.
target_bbox: [batch, num_rois, (dy, dx, log(dh), log(dw))]
target_class_ids: [batch, num_rois]. Integer class IDs.
pred_bbox: [batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]
"""
if target_class_ids.size():
# Only positive ROIs contribute to the loss. And only
# the right class_id of each ROI. Get their indicies.
positive_roi_ix = torch.nonzero(target_class_ids > 0)[:, 0]
positive_roi_class_ids = target_class_ids[positive_roi_ix.data].long()
indices = torch.stack((positive_roi_ix,positive_roi_class_ids), dim=1)
# Gather the deltas (predicted and true) that contribute to loss
target_bbox = target_bbox[indices[:,0].data,:]
pred_bbox = pred_bbox[indices[:,0].data,indices[:,1].data,:]
# Smooth L1 loss
loss = F.smooth_l1_loss(pred_bbox, target_bbox)
else:
loss = Variable(torch.FloatTensor([0]), requires_grad=False)
if target_class_ids.is_cuda:
loss = loss.cuda()
return loss5. mask
只计算正样本mask的损失
python
def compute_mrcnn_mask_loss(target_masks, target_class_ids, pred_masks):
"""Mask binary cross-entropy loss for the masks head.
target_masks: [batch, num_rois, height, width].
A float32 tensor of values 0 or 1. Uses zero padding to fill array.
target_class_ids: [batch, num_rois]. Integer class IDs. Zero padded.
pred_masks: [batch, proposals, height, width, num_classes] float32 tensor
with values from 0 to 1.
"""
if target_class_ids.size():
# Only positive ROIs contribute to the loss. And only
# the class specific mask of each ROI.
positive_ix = torch.nonzero(target_class_ids > 0)[:, 0] # 正样本索引
positive_class_ids = target_class_ids[positive_ix.data].long() # 正样本类别ID
indices = torch.stack((positive_ix, positive_class_ids), dim=1) #
# Gather the masks (predicted and true) that contribute to loss
y_true = target_masks[indices[:,0].data,:,:] # 真实掩码
y_pred = pred_masks[indices[:,0].data,indices[:,1].data,:,:] # 预测掩码
# Binary cross entropy
loss = F.binary_cross_entropy(y_pred, y_true)
else:
loss = Variable(torch.FloatTensor([0]), requires_grad=False)
if target_class_ids.is_cuda:
loss = loss.cuda()
return loss1.10 推理阶段
1.10.1 分类和回归
分类和回归使用的proposal层的结果。我们在前面说了,训练时proposal输出2k候选框(后面经过detection_target_layer只会产生200个用于训练),推理时1k。
python
# Network Heads
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rpn_rois)
# Detections
# output is [batch, num_detections, (y1, x1, y2, x2, class_id, score)] in image coordinates
detections = detection_layer(self.config, rpn_rois, mrcnn_class, mrcnn_bbox, image_metas)
python
def detection_layer(config, rois, mrcnn_class, mrcnn_bbox, image_meta):
"""Takes classified proposal boxes and their bounding box deltas and
returns the final detection boxes.
Returns:
[batch, num_detections, (y1, x1, y2, x2, class_score)] in pixels
"""
# Currently only supports batchsize 1
rois = rois.squeeze(0)
_, _, window, _ = parse_image_meta(image_meta)
window = window[0]
detections = refine_detections(rois, mrcnn_class, mrcnn_bbox, window, config)
return detections对rois进行筛选和过滤,对1k个proposals的候选框进行筛选,最终只保留100个。
具体,
- 每个roi对应的类,以及类得分和类对应的(dx,dy,log(dh),log(dw))
- 对候选框应用得到的偏移量进行调整
- 转到图像坐标,并裁剪超出区域
- 剔除背景,得分小于0.7的过滤,以及每个类分别进行nms
- 保留前N个
python
def refine_detections(rois, probs, deltas, window, config):
"""Refine classified proposals and filter overlaps and return final
detections.
Inputs:
rois: [N, (y1, x1, y2, x2)] in normalized coordinates
probs: [N, num_classes]. Class probabilities.
deltas: [N, num_classes, (dy, dx, log(dh), log(dw))]. Class-specific
bounding box deltas.
window: (y1, x1, y2, x2) in image coordinates. The part of the image
that contains the image excluding the padding.
Returns detections shaped: [N, (y1, x1, y2, x2, class_id, score)]
"""
# ----------------------------------------------------------------------------------------------
# 每个roi对应的类,以及类得分和类对应的(dx,dy,log(dh),log(dw))
# Class IDs per ROI
_, class_ids = torch.max(probs, dim=1) # 类的索引
# Class probability of the top class of each ROI
# Class-specific bounding box deltas
idx = torch.arange(class_ids.size()[0]).long()
if config.GPU_COUNT:
idx = idx.cuda()
class_scores = probs[idx, class_ids.data] # 类得分
deltas_specific = deltas[idx, class_ids.data] # 类对应的(dx,dy,log(dh),log(dw))
# ----------------------------------------------------------------------------------------------
# 对候选框应用得到的偏移量进行调整
# Apply bounding box deltas
# Shape: [boxes, (y1, x1, y2, x2)] in normalized coordinates
std_dev = Variable(torch.from_numpy(np.reshape(config.RPN_BBOX_STD_DEV, [1, 4])).float(), requires_grad=False)
if config.GPU_COUNT:
std_dev = std_dev.cuda()
refined_rois = apply_box_deltas(rois, deltas_specific * std_dev) # 调整后的框
# ----------------------------------------------------------------------------------------------
# 转到图像坐标,并裁剪超出区域
# Convert coordiates to image domain
height, width = config.IMAGE_SHAPE[:2]
scale = Variable(torch.from_numpy(np.array([height, width, height, width])).float(), requires_grad=False)
if config.GPU_COUNT:
scale = scale.cuda()
refined_rois *= scale # 转换到图像域
# Clip boxes to image window
refined_rois = clip_to_window(window, refined_rois) # 裁剪到图像边界
# Round and cast to int since we're deadling with pixels now
refined_rois = torch.round(refined_rois) # 四舍五入
# TODO: Filter out boxes with zero area
# ----------------------------------------------------------------------------------------------
# 剔除背景,得分小于0.7的过滤,以及每个类分别进行nms
# Filter out background boxes
keep_bool = class_ids>0 # 剔除背景框
# Filter out low confidence boxes ,置信度小于0.7的剔除
if config.DETECTION_MIN_CONFIDENCE:
keep_bool = keep_bool & (class_scores >= config.DETECTION_MIN_CONFIDENCE)
keep = torch.nonzero(keep_bool)[:,0]
# Apply per-class NMS, 每个类分别进行nms
pre_nms_class_ids = class_ids[keep.data]
pre_nms_scores = class_scores[keep.data]
pre_nms_rois = refined_rois[keep.data]
for i, class_id in enumerate(unique1d(pre_nms_class_ids)):
# Pick detections of this class
ixs = torch.nonzero(pre_nms_class_ids == class_id)[:,0]
# Sort
ix_rois = pre_nms_rois[ixs.data]
ix_scores = pre_nms_scores[ixs]
ix_scores, order = ix_scores.sort(descending=True)
ix_rois = ix_rois[order.data,:]
class_keep = nms(torch.cat((ix_rois, ix_scores.unsqueeze(1)), dim=1).data, config.DETECTION_NMS_THRESHOLD)
# Map indicies
class_keep = keep[ixs[order[class_keep].data].data]
if i==0:
nms_keep = class_keep
else:
nms_keep = unique1d(torch.cat((nms_keep, class_keep)))
keep = intersect1d(keep, nms_keep)
# ----------------------------------------------------------------------------------------------
# Keep top detections,保留前N个
roi_count = config.DETECTION_MAX_INSTANCES
top_ids = class_scores[keep.data].sort(descending=True)[1][:roi_count]
keep = keep[top_ids.data]
# Arrange output as [N, (y1, x1, y2, x2, class_id, score)]
# Coordinates are in image domain.
result = torch.cat((refined_rois[keep.data],
class_ids[keep.data].unsqueeze(1).float(),
class_scores[keep.data].unsqueeze(1)), dim=1)
return result1.10.2 mask预测
python
# Convert boxes to normalized coordinates
# TODO: let DetectionLayer return normalized coordinates to avoid
# unnecessary conversions
h, w = self.config.IMAGE_SHAPE[:2]
scale = Variable(torch.from_numpy(np.array([h, w, h, w])).float(), requires_grad=False)
if self.config.GPU_COUNT:
scale = scale.cuda()
detection_boxes = detections[:, :4] / scale
# Add back batch dimension
detection_boxes = detection_boxes.unsqueeze(0)
# Create masks for detections
mrcnn_mask = self.mask(mrcnn_feature_maps, detection_boxes)1.10.3 最终输出
最终输出detection和mask,detection中为y1,x1,y2,x2,class_id,score
python
if mode == 'inference':
# Network Heads
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rpn_rois)
# Detections
# output is [batch, num_detections, (y1, x1, y2, x2, class_id, score)] in image coordinates
detections = detection_layer(self.config, rpn_rois, mrcnn_class, mrcnn_bbox, image_metas)
# --------------------------------------------------------------------------------------
# 对框进行标准化
# Convert boxes to normalized coordinates
# TODO: let DetectionLayer return normalized coordinates to avoid
# unnecessary conversions
h, w = self.config.IMAGE_SHAPE[:2]
scale = Variable(torch.from_numpy(np.array([h, w, h, w])).float(), requires_grad=False)
if self.config.GPU_COUNT:
scale = scale.cuda()
detection_boxes = detections[:, :4] / scale # 标准化
# Add back batch dimension
detection_boxes = detection_boxes.unsqueeze(0)
# Create masks for detections
mrcnn_mask = self.mask(mrcnn_feature_maps, detection_boxes)
# Add back batch dimension
detections = detections.unsqueeze(0)
mrcnn_mask = mrcnn_mask.unsqueeze(0)
return [detections, mrcnn_mask]1.11 总结
一阶段rpn输入的是p2-p6,
二阶段的分类和mask输入的是p2-p5
分类是Pooling成7×7,mask是Pooling成14×14
1.11.1 rpn
rpn阶段的样本准备,首先排除"多物体"(crowd)
1. 正负样本划分与偏移量计算: 负样本和anchor的iou<0.3;正样本iou>0.7和每个gt_box对应的最大的anchor。正样本标记为1,负样本标记 为-1,其他标记为0。具体见1.5.1
其中正负样本数不超过一半。
计算正样本的偏移量。负样本不需要计算偏移量。
偏移量计算是gt_box相对对应的anchor的偏移量,如:
python
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / a_h,
(gt_center_x - a_center_x) / a_w,
np.log(gt_h / a_h),
np.log(gt_w / a_w),
]rpn分类时,是区分正负样本,所以会忽略掉其他样本0,如:
(可以参考一阶段class损失计算)
python
indices = torch.nonzero(rpn_match != 0)对box的回归值是只计算正样本的,如(
可参考一阶段的box)
python
# Positive anchors contribute to the loss, but negative and
# neutral anchors (match value of 0 or -1) don't.
indices = torch.nonzero(rpn_match==1)至此,我们对anchor进行了粗分类和粗回归。
1.11.2 proposals
对上面的粗分类结果进行筛选。保留部分候选框(训练2k,推理1k),主要有:
- 对前景得分进行排序
- 筛选前6k个anchor
- 对anchor用回归得到的偏移量进行调整,生成候选框
- 超过边界的候选框进行裁剪
- 应用nms,保留2k个
- 对得到的候选框进行归一化操作
至此,我们得到了2k个归一化以后的候选框。
1.11.3 detection_target(训练阶段)
对proposals得到的2k个候选框进一步筛选得到200个,正样本为iou>0.5,负样本为iou<0.5,正负样本1:3。
找到这些候选框对应的gt,然后获取相对偏移量,以及gt_mask。
具体见1.6
python
rois, target_class_ids, target_deltas, target_mask = \
detection_target_layer(rpn_rois, gt_class_ids, gt_boxes, gt_masks, self.config)1.11.4 分类、回归和mask(训练阶段)
对上面得到的200个候选框进行分类mask操作。
上面我们有200个不同大小的候选框了,然后我们用候选框在特征图上裁剪局部特征,对这个特征送入分类网络,由于 我们的候选框大小不同,所以需要缩放到同一个大小,ROI-Pooling,本文对此进行了改进,提出了ROIAlign。
说明:
- 由于是多尺度的,根据候选框的大小不同,不同大小的候选框会在不同的特征图是上进行裁剪。
- 一阶段(rpn部分)用的特征图是p2-p6,这里(二阶段)用的是p2-p5
python
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rois)
# Create masks for detections
mrcnn_mask = self.mask(mrcnn_feature_maps, rois)1.11.5 损失(训练阶段)
损失分为一阶段和二阶段,具体看1.9
python
def compute_losses(rpn_match, rpn_bbox, rpn_class_logits, rpn_pred_bbox, target_class_ids, mrcnn_class_logits, target_deltas, mrcnn_bbox, target_mask, mrcnn_mask):
# 一阶段
rpn_class_loss = compute_rpn_class_loss(rpn_match, rpn_class_logits) # rpn class
rpn_bbox_loss = compute_rpn_bbox_loss(rpn_bbox, rpn_match, rpn_pred_bbox) # rpn box
# 二阶段
mrcnn_class_loss = compute_mrcnn_class_loss(target_class_ids, mrcnn_class_logits) # class
mrcnn_bbox_loss = compute_mrcnn_bbox_loss(target_deltas, target_class_ids, mrcnn_bbox) # box
mrcnn_mask_loss = compute_mrcnn_mask_loss(target_mask, target_class_ids, mrcnn_mask) # mask
return [rpn_class_loss, rpn_bbox_loss, mrcnn_class_loss, mrcnn_bbox_loss, mrcnn_mask_loss]1.11.6 分类和回归(推理阶段)
和训练一样,二阶段用的是p2-p5的特征图。
推理时,proposals层只产生1k候选框,对这1k候选框进行分类和回归
python
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rpn_rois)1.11.7 应用分类和回归(推理阶段)
对rois进行筛选和过滤,对1k个proposals的候选框进行筛选,最终只保留100个。
对proposals得到的1k个候选框应用上面分类和回归的偏移量进行调整。
python
# Detections
# output is [batch, num_detections, (y1, x1, y2, x2, class_id, score)] in image coordinates
detections = detection_layer(self.config, rpn_rois, mrcnn_class, mrcnn_bbox, image_metas)具体见1.10.1:
- 每个roi对应的类,以及类得分和类对应的(dx,dy,log(dh),log(dw))
- 对候选框应用得到的偏移量进行调整
- 转到图像坐标,并裁剪超出区域
- 剔除背景,得分小于0.7的过滤,以及每个类分别进行nms
- 保留前N个
1.11.8 mask(推理阶段)
对上面调整后的候选框,在特征图上裁剪,再mask
python
# --------------------------------------------------------------------------------------
# 对框进行标准化
# Convert boxes to normalized coordinates
# TODO: let DetectionLayer return normalized coordinates to avoid
# unnecessary conversions
h, w = self.config.IMAGE_SHAPE[:2]
scale = Variable(torch.from_numpy(np.array([h, w, h, w])).float(), requires_grad=False)
if self.config.GPU_COUNT:
scale = scale.cuda()
detection_boxes = detections[:, :4] / scale # 标准化
# Add back batch dimension
detection_boxes = detection_boxes.unsqueeze(0)
# Create masks for detections
mrcnn_mask = self.mask(mrcnn_feature_maps, detection_boxes)1.11.9 小结
- rpn对每个anchor进行分类和归回;
rpn阶段(划分正负(anchor)样本判定是,>0.7,<0.3),正负样本都不超过一半;
回归只针对正样本。
训练阶段:
-
proposals筛选保留2k个框;
-
detection_target_layer进一步对proposals进行筛选,保留200个,正负候选框比为1:3(>0.5为正样本,<0.5为负样本);
-
对上面的200个进行分类、回归和mask;
推理阶段:
-
proposals筛选保留1k个框;
-
对上面1k个框先分类(和训练的顺序稍有不同);
-
根据结果对框进一步筛选,保留100个;
-
对这个100个框进行mask计算。
1.11.10 流程图
1. 推理流程(Inference)
┌─────────────────────────────────────────────────────────────────┐
│ 输入图像 (H×W×3) │
└──────────────────────────────┬──────────────────────────────────┘
│
▼
┌──────────────────────┐
│ 图像预处理 │
│ - 尺寸调整 │
│ - 归一化 │
│ - 填充到固定尺寸 │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Backbone (ResNet) │
│ 特征提取 │
│ C2, C3, C4, C5 │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ FPN │
│ 多尺度特征融合 │
│ P2, P3, P4, P5, P6 │
└──────────┬───────────┘
│
┌──────────┴───────────┐
│ │
▼ ▼
┌───────────────────┐ ┌───────────────────┐
│ RPN │ │ Anchor 生成 │
│ - 分类 │ │ (5尺度×3比例) │
│ - 回归 │ │ = 15锚点/位置 │
└──────────┬─────────┘ └──────────┬────────┘
│ │
└──────────┬─────────────┘
│
▼
┌──────────────────────┐
│ Proposal Layer │
│ - NMS │
│ - Top-K 选择 │
│ 输出: 1000个ROI │
└──────────┬───────────┘
│
┌──────────┴───────────┐
│ │
▼ ▼
┌───────────────────┐ ┌───────────────────┐
│ ROI Align │ │ ROI Align │
│ 7×7 (分类/回归) │ │ 14×14 (掩码) │
└──────────┬────────┘ └──────────┬────────┘
│ │
┌──────────┴──────────┐ │
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 分类头 │ │ 回归头 │ │ 掩码头 │
│ FC → 类别 │ │ FC → 4个参数 │ │ Conv → 28×28 │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
└──────────┬───────┴──────────────────┘
│
▼
┌────────────────┐
│ Detection Layer│
│ - 类别选择 │
│ - 框精调 │
│ - NMS │
│ - 阈值过滤 │
└────────┬───────┘
│
▼
┌────────────────┐
│ 后处理 │
│ - 坐标映射 │
│ - 掩码上采样 │
│ - 裁剪 │
└────────┬───────┘
│
▼
┌─────────────────────────────┐
│ 最终输出 │
│ - rois: [N, 4] │
│ - class_ids: [N] │
│ - scores: [N] │
│ - masks: [H, W, N] │
└─────────────────────────────┘2. 训练流程(Training)
输入图像 + GT标注
│
├─→ RPN 分支
│ ├─→ RPN 分类损失 (前景/背景)
│ └─→ RPN 回归损失 (仅正样本)
│
├─→ Detection Target Layer
│ └─→ 采样 ROI (正负样本平衡)
│
└─→ ROI 分支
├─→ 分类损失
├─→ 回归损失 (仅正样本)
└─→ 掩码损失 (仅正样本,逐像素)3. 数据流维度变化
输入: [H, W, 3]
↓
Backbone:
C2: [H/4, W/4, 256]
C3: [H/8, W/8, 512]
C4: [H/16, W/16, 1024]
C5: [H/32, W/32, 2048]
↓
FPN:
P2: [H/4, W/4, 256]
P3: [H/8, W/8, 256]
P4: [H/16, W/16, 256]
P5: [H/32, W/32, 256]
P6: [H/64, W/64, 256]
↓
RPN:
输出: [num_anchors, 2] (分类)
[num_anchors, 4] (回归)
↓
Proposals:
[1000, 4] (推理)
[2000, 4] (训练)
↓
ROI Align:
分类/回归: [1000, 7, 7, 256]
掩码: [1000, 14, 14, 256]
↓
分类头:
[1000, num_classes]
↓
回归头:
[1000, num_classes, 4]
↓
掩码头:
[1000, num_classes, 28, 28]
↓
Detection Layer:
[max_detections, 6] (y1, x1, y2, x2, class, score)
↓
最终输出:
rois: [N, 4]
class_ids: [N]
scores: [N]
masks: [H, W, N]4. 关键模块说明
4.1 Backbone (ResNet)
- 作用: 提取图像特征
- 输出: 5个不同尺度的特征图
- 选择: ResNet50 或 ResNet101
4.2 FPN (Feature Pyramid Network)
- 作用: 融合多尺度特征,提升小目标检测
- 方法: 自顶向下路径 + 横向连接
- 优势: 单一特征图 → 多尺度特征金字塔
4.3 RPN (Region Proposal Network)
- 作用: 生成候选目标区域
- 输入: FPN 特征图 + 锚点
- 输出: 候选框 (Proposals)
- 特点: 共享 Backbone 特征,计算高效
4.4 ROI Align
- 作用: 从特征图中提取固定大小的 ROI 特征
- 优势: 相比 ROI Pooling,避免量化误差
- 输出: 7×7 (分类/回归) 或 14×14 (掩码)
4.5 检测头 (Detection Heads)
- 分类头: 预测类别
- 回归头: 精调边界框
- 掩码头: 生成像素级掩码
4.6 后处理
- NMS: 去除重复检测
- 阈值过滤: 去除低置信度检测
- 坐标映射: 映射回原始图像尺寸
- 掩码处理: 上采样、裁剪、阈值化
5. 训练策略
5.1 阶段1: 仅训练 RPN
- 冻结 Backbone
- 训练 RPN 生成高质量候选区域
5.2 阶段2: 仅训练检测头
- 冻结 Backbone 和 RPN
- 使用固定候选区域训练检测头
5.3 阶段3: 端到端微调
- 解冻所有层
- 联合优化所有模块
6. 性能指标
- 检测精度: mAP (mean Average Precision)
- 分割精度: mAP (mask)
- 速度: FPS (Frames Per Second)
7. 应用场景
- 实例分割: 检测并分割每个目标实例
- 目标检测: 仅使用检测框(忽略掩码)
- 关键点检测: 扩展掩码头为关键点预测
- 姿态估计: 结合人体关键点检测