目录
Hadoop
狭义解释
Apache的一个用Java语言实现的开源软件框架,是一个存储和计算大规模数据的软件平台。
核心组件**:**
HDFS(分布式文件系统):解决海量数据存储
MapReduce(分布式运算编程框架):解决海量数据计算
YARN(作业调度和集群资源管理的框架):解决资源任务调度
广义解释
Hadoop通常是指Hadoop生态圈,由很多大数据组件构建而成。
包括:Linux、zookeeper、Hadoop、hive、hbase、redis、elk、kadka、java、scala、python、impala、kudu、spark、flink、相关工具等
Hadoop不同版本
1.x
mapreduce:数据计算;资源管理
hdfs:数据存储,自动备份
2.x
mapreduce:数据计算
yarn:资源管理,分担了压力
hdfs:数据存储
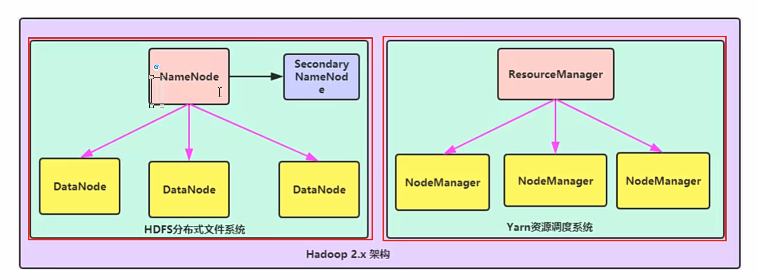
hdfs、yarn解释:
NameNode:集群中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要用于Hadoop中元数据信息的辅助管理
元数据:描述数据属性的信息,用来支持(如指示存储位置、历史数据、资源查找、文件记录)等功能。
DataNode:集群中的从节点,主要用于存储集群当中的各种数据
ResourceManager:接受用户的计算请求任务,负责集群的资源分配NodeManager:负责执行主节点分配的任务
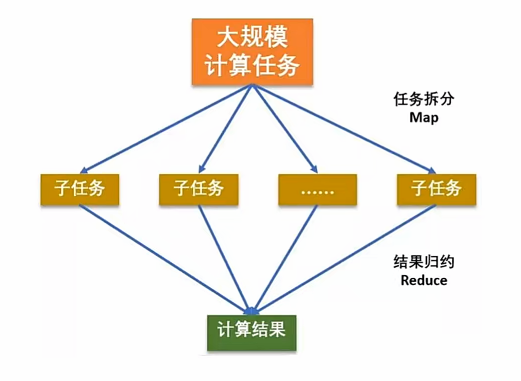
mapreduce特点:
MapReduce是一个计算框架,map负责分布式计算,reduce负责将分布式计算的结果合并
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度
3.x
支持多个NameNode
优化了YARN时间线服务和MapReduce性能
引入纠删码技术,降低了冷数据的存储成本
Hadoop集群搭建简介
集群简介
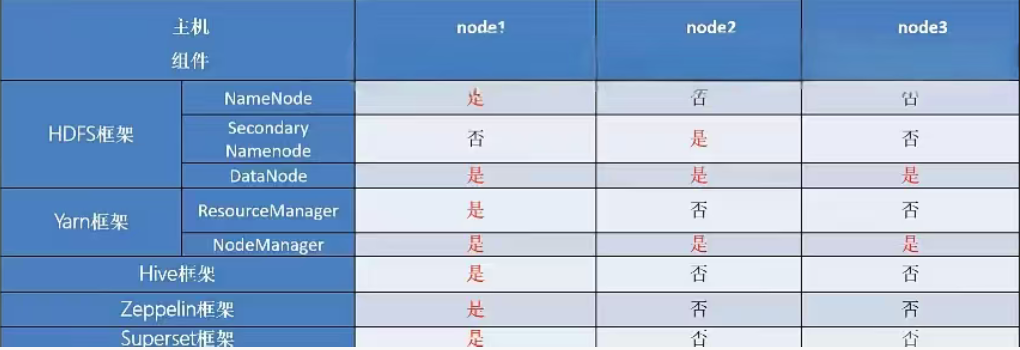
Hadoop集群:包括HDFS集群和YARN集群,两者逻辑上分离,物理上在一起
HDFS集群:NameNode、DataNode、SecondaryNameNode
YARN集群:ResourceManager、NodeManager
集群搭建方式
单机模式(Standalone mode)
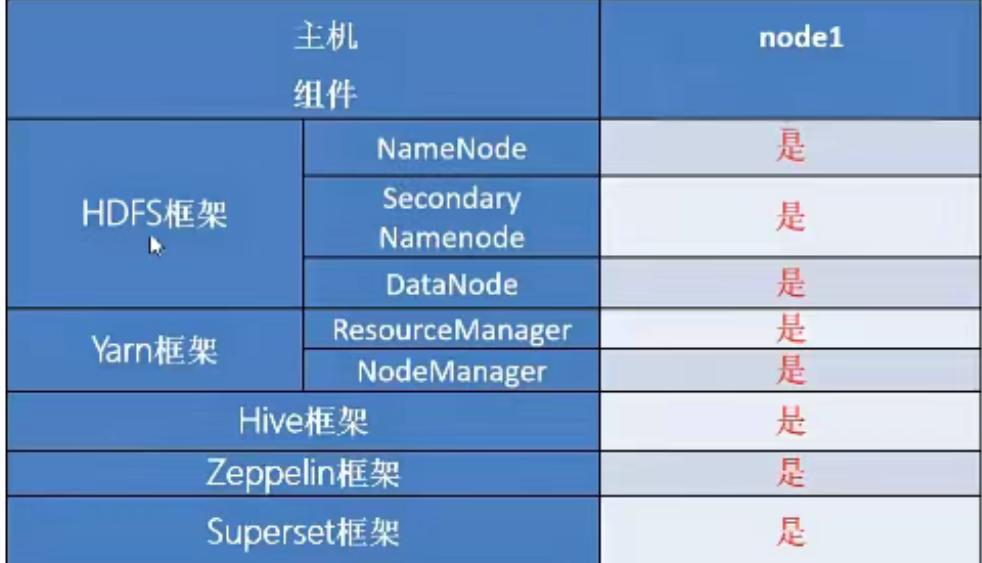
1个机器上运行HDFS的NameNode和DataNode、YARN的ResourceManger和NodeManager,主要用于学习和调试。
集群模式(Cluster mode)
主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同机器上。