前言
矿产勘查的本质上就是是一场在巨大的不确定性中寻求确定性的过程 。从早期探矿依赖个人经验和直觉的"相矿",到后来基于地质理论的知识驱动模型。在漫长的发展中,证据权重法(Weights of Evidence, WofE)的出现开创性地引入了数据驱动的理念,为在地理信息系统(GIS)环境下系统性地整合多源地学信息、进行定量化的成矿预测提供了第一个强大而客观的框架。

尽管证据权重法具有不可磨灭的历史地位,但其赖以成立的数学基石------"条件独立性假设"------与复杂且相互关联的真实成矿地质系统存在着根本性的矛盾。随着现代地球科学进入"大数据"时代,高维度、多源地学数据的爆发式增长使得这一核心假设的局限性日益凸显,甚至达到了其理论框架的断裂点。这一深刻的矛盾,催生并论证了一场势在必行的范式革命:向机器学习的转型。

前排说明:本文旨在探讨地学大数据的发展如何推动成矿预测的进步,而并非深入展开具体算法、数学原理、操作方法,或其在地质大数据中的详细应用。若您对相关算法的使用方法及其在地质大数据中的实践感兴趣,欢迎持续关注 "码上地球------数学地球科学" 获取后续内容。
现实对证据权重法的重拳
在机器学习兴起之前,证据权重法是连接地质理论与海量空间数据的关键桥梁。它成功地将地质学家的定性判断转化为可计算、可重复的定量模型,代表了成矿预测领域的一次重大方法学突破。
证据权重法的核心在于利用已知矿床的空间分布,来量化不同地质要素对成矿的"贡献"或"指示"强度 。该方法的基本构成要素: 证据图层,训练点,权重计算 。最终,通过将所有证据图层的权重进行线性叠加,可以计算出每个空间单元的后验概率,从而生成一张直观的矿产潜力预测图。尽管证据权重法取得了巨大成功,但其优雅简洁的数学形式背后,隐藏着一个深刻且影响深远的理论局限------条件独立性假设。
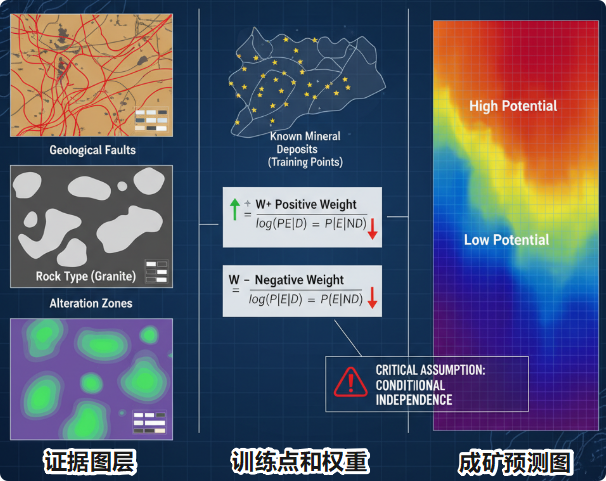
然而现实的成矿作用并非一系列孤立事件的随机叠加,而是一个由多种地质过程在特定时空背景下相互耦合、相互作用形成的复杂系统 。矿床是这个系统演化的最终产物,是岩浆、构造、流体、围岩等多个子系统相互作用的焦点。因此,我们用来进行成矿预测的证据图层------岩性、构造、地球化学、地球物理等------本身就是这个统一成矿系统在不同侧面的地质响应和表达,它们之间必然存在着深刻的内在成因联系。
斑岩型铜矿成矿模式是地质学中研究最为透彻、也最能体现要素间关联性的典范之一。在一个典型的斑岩系统中:
-
岩性与构造的共生: 富含金属的钙碱性或碱性中酸性斑岩体(岩性证据 )的侵位,是成矿的物质和能量来源。而这些岩体的侵位路径往往受到区域性深大断裂或构造薄弱带的控制(构造证据)。
-
岩浆、蚀变与地球化学的联动: 岩浆冷却和流体出溶过程,会在岩体及其围岩中形成规律的、环带状分布的蚀变矿物组合,如中心的钾化带、向外的青磐岩化带等(蚀变证据 )。伴随这些蚀变过程,亲铜元素(Cu, Mo)及其他伴生元素(Au, Ag)会发生富集,同时形成指示性的"探路者"元素(如As, Sb, Bi)异常晕(地球化学证据)。
-
物理性质的响应: 钾化蚀变带由于磁铁矿的形成常表现为磁异常,而岩体本身及相关的构造破碎带则可能表现为重力或电阻率异常(地球物理证据)。
在这个系统中,岩性、构造、蚀变、地球化学和地球物理异常并非独立的变量。它们是同一成矿引擎在不同物理化学条件下的不同表现形式。要求它们在成矿预测中保持条件独立,无异于要求一个人的身高、体重和鞋码相互独立一样,违背了基本的客观规律。
范式转移:机器学习
面对证据权重法在处理复杂地质系统时的内在矛盾,机器学习提供了一种全新的、更为强大的解决方案。它标志着成矿预测从一个强加简化统计框架的时代,进入一个直接从数据中学习复杂内在规律的新纪元。

WofE 与机器学习在分析上存在根本差异。WofE 的本质是相关性建模:它分别量化单个证据(如"靠近断裂")与矿床之间的空间相关性,然后将这些孤立的相关性值进行线性叠加 。它能回答"A与矿床相关吗?"以及"B与矿床相关吗?"这类问题。
相比之下,机器学习,尤其是集成学习算法,执行的是模式识别 。它旨在发现多变量组合下的复杂、非线性模式。它回答的是一个更接近地质学家思维方式的问题:"在何种组合条件下最有可能出现矿床?"。
以随机森林为例,这种算法是现代成矿预测中最受欢迎和最有效的机器学习工具之一 。其强大能力源于其独特的结构------由成百上千棵决策树组成的"森林":
-
模拟非线性关系: 单个决策树通过一系列"是/否"的判断,可以拟合出高度非线性的决策边界,这远比 WofE 的线性叠加更为灵活。
-
捕捉交互作用: 决策树的层级结构天然地能够捕捉特征之间的交互作用。一棵树的深层节点,其决策规则是建立在所有上层节点决策基础之上的,这本身就是一种对条件概率的模拟。
让我们用一个具体的例子来说明这种差异。WofE 模型可能会得出结论:"强磁异常"权重为+2,"北东向断裂"权重为+1.5,"特定岩性"权重为+1。它会将这些权重相加,得到一个综合评分。而随机森林模型则能学习到一条更精细、更符合地质逻辑的规则,例如:"当且仅当 一个区域同时满足 '强磁异常'、'靠近北东向断裂'且'位于特定岩性单元内'这三个条件时,其成矿概率才会极高;缺少任何一个条件,概率都将大幅下降。"
这种从简单的"A+B+C"到复杂的"IF A AND B AND C, THEN..."的转变,是从简单的统计累加到模拟地质专家复杂推理过程的质的飞跃。机器学习算法能够自动地在数据中探索和发现成千上万条类似的复杂规则,从而构建出一个远比WofE 更精细、更准确的预测模型。
数据的洪流
从证据权重法到机器学习的转变,并非仅仅是算法理论的自我演进,其背后更深刻的驱动力,来自于整个地球科学领域数据环境的剧变。可以说,是地学大数据的浪潮,"压垮"了证据权重法的理论根基,同时为机器学习的崛起铺平了道路。
回溯至 WofE 方法发展的黄金时代,成矿预测所依赖的数据源相对有限,可能仅限于几张手绘或初步数字化的地质图、构造图和有限的物化探数据。在这样的"数据稀疏"环境下,WofE 作为一种能从有限信息中提取定量指标的工具,其价值是巨大的,其假设的局限性也未完全暴露。
然而,进入21世纪,勘查技术经历了爆炸式的发展。高精度航空地球物理 (磁、重、放)测量能够覆盖广阔区域,提供海量的三维空间信息 ;多元素、高密度区域地球化学测量 成为常态;高光谱与多光谱遥感技术能够精细识别地表蚀变矿物信息 。一个现代化的区域成矿预测项目,需要整合的图层数量从过去的几个、十几个,激增到现在的数十个乃至上百个 。
在这种"数据丰富"的新常态下,证据权重法的条件独立性假设从一个理论上的瑕疵,演变成了一个实践中无法回避的致命缺陷。随着证据图层数量的增加,这些图层之间保持真实条件独立性的概率呈指数级下降。当处理几十个地球物理、地球化学和遥感变量时,它们之间几乎必然存在着各种程度的相互关联。因此,地学大数据的出现,使得 WofE 的核心假设在实践层面变得彻底站不住脚,其预测结果的可靠性也随之瓦解。
与此同时,这场数据的洪流恰恰为机器学习算法提供了最宝贵的"燃料" 。机器学习模型,尤其是深度学习,是"数据饥渴"的 。它们的性能------即识别复杂、微弱信号和模式的能力------会随着训练数据量的增加、维度的丰富而显著提升。

多源数据融合正是机器学习大放异彩的领域。它能够自动地从上百个变量中学习它们之间复杂的相互关系,识别出哪些是关键的指示信息,哪些是冗余信息,以及哪些变量的组合才能构成最有效的成矿"指纹" 。这些能力是 WofE等传统方法望尘莫及的。因此,这并非两种工具之间的简单选择,而是分析方法为适应数据环境剧变而发生的必然进化。WofE是"数字化地图"时代的产物,而机器学习则是"地学大数据"时代的必然选择。
结语
从统计模型到机器学习的发展,都是由于内部假设与真实成矿系统的复杂性、内在关联性之间存在着不可调和的矛盾。这一矛盾在现代地学大数据环境下被急剧放大,从而使得学者迫切寻找新的范式以提供一个新的解决方案。
在研究过程中,会在不同的地学领域,不同的方向,有不同的解决方案,但是其本质还是大同小异,关于不同算法在不同领域方向的应用实战,我会在单独开一个系列内容。如果感兴趣,欢迎持续关注 "码上地球------数学地球科学" 获取后续内容。

科学探索永无止境,本文仅为笔者个人学习总结。因知识所限,文中若有不当之处,敬请方家斧正。
参考内容
-
Oktavia Suhyani, N. (2025). Machine learning for Earth sciences: using Python to solve geological problems: by Maurizio Petrelli, Switzerland AG, Springer Nature ISBN: 9783031351136.
-
Balaram, V., & Sawant, S. S. (2022). Indicator minerals, pathfinder elements, and portable analytical instruments in mineral exploration studies. Minerals, 12(4), 394.
-
He, B., Chen, J., Chen, C., & Liu, Y. (2012). Mineral prospectivity mapping method integrating multi-sources geology spatial data sets and case-based reasoning.
-
Zhang, N., Zhou, K., & Li, D. (2018). Back-propagation neural network and support vector machines for gold mineral prospectivity mapping in the Hatu region, Xinjiang, China. Earth Science Informatics, 11(4), 553-566.
-
左仁广,成秋明,许莹,杨帆帆,熊义辉,王子烨 & Oliver P.KREUZER.(2024).可解释性矿产预测人工智能模型.中国科学:地球科学,54(09),2917-2928.
-
杨明莉,薛林福,冉祥金,桑学佳,燕群 & 戴均豪.(2021).智能矿产地质调查方法------以甘肃大桥-崖湾地区为例.岩石学报,37(12),3880-3892.
-
滕菲,张燕,张素荣 & 邢怡.(2014).利用证据权重法进行综合信息矿产资源预测------以大兴安岭北部地区为例.地质调查与研究,37(04),269-273+287.