目录
[一、 原始数据介绍](#一、 原始数据介绍)
[二、 数据预处理(数据准备)](#二、 数据预处理(数据准备))
[2.1 像素级分布统计分析](#2.1 像素级分布统计分析)
[2.2 数据展平](#2.2 数据展平)
[2.3 特征缩放](#2.3 特征缩放)
[2.4 数据裁剪](#2.4 数据裁剪)
[5.1 模型性能总结](#5.1 模型性能总结)
[5.2 模型性能分析](#5.2 模型性能分析)
[5.3 核函数选择与参数优化](#5.3 核函数选择与参数优化)
[5.4 未来研究方向](#5.4 未来研究方向)
一、 原始数据介绍
MNIST数据集是一个广泛用于机器学习和计算机视觉领域的经典手写数字识别数据集。该数据集由美国国家标准与技术研究所(NIST)发起整理,包含大量手写数字图像,被广泛应用于各种算法的测试和评估。MNIST数据集的规模和多样性使其成为机器学习和深度学习算法的重要基准测试数据集。
MNIST数据集的下载和使用非常简便,官方网站提供了四个文件的下载:训练集图像、训练集标签、测试集图像和测试集标签。这些文件以字节形式存储,需通过特定程序读取。
- 下载地址 :MNIST数据集
以下是加载数据的关键代码:
1.1解析图片的代码
import struct
import numpy as np
from tqdm import tqdm
def jiexi_image(path):
# 用二进制读取
data = open(path, 'rb').read()
offset = 0
fmt_header = '>iiii'
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, data, offset)
print(f'魔数: {magic_number}, 图片数量: {num_images}张, 图片大小: {num_rows}*{num_cols}')
image_size = num_rows * num_cols
offset += struct.calcsize(fmt_header)
fmt_image = '>' + str(image_size) + 'B'
images = np.empty((num_images, num_rows, num_cols))
# 使用tqdm添加进度条
for i in tqdm(range(num_images), desc='解析图片'):
images[i] = np.array(struct.unpack_from(fmt_image, data, offset)).reshape((num_rows, num_cols))
offset += struct.calcsize(fmt_image)
return images1.2解析标签的代码
def jiexi_label(path):
data = open(path, 'rb').read()
offset = 0
fmt_header = '>ii'
magic_number, num_images = struct.unpack_from(fmt_header, data, offset)
print(f'魔数: {magic_number}, 图片数量: {num_images}张')
offset += struct.calcsize(fmt_header)
fmt_image = '>B'
labels = np.empty(num_images)
# 使用tqdm添加进度条
for i in tqdm(range(num_images), desc='解析标签'):
labels[i] = struct.unpack_from(fmt_image, data, offset)[0]
offset += struct.calcsize(fmt_image)
return labels运行结果:
-
MNIST数据集包含70,000张28x28像素的手写数字灰度图像,分为训练集和测试集两部分:
-
训练集:60,000张图像
-
测试集:10,000张图像
-
-
每个图像对应一个标签,标签范围为0到9,表示图像中的手写数字。
-
每张图像由28x28个像素点构成,每个像素点用一个灰度值表示,灰度值介于0到255之间。
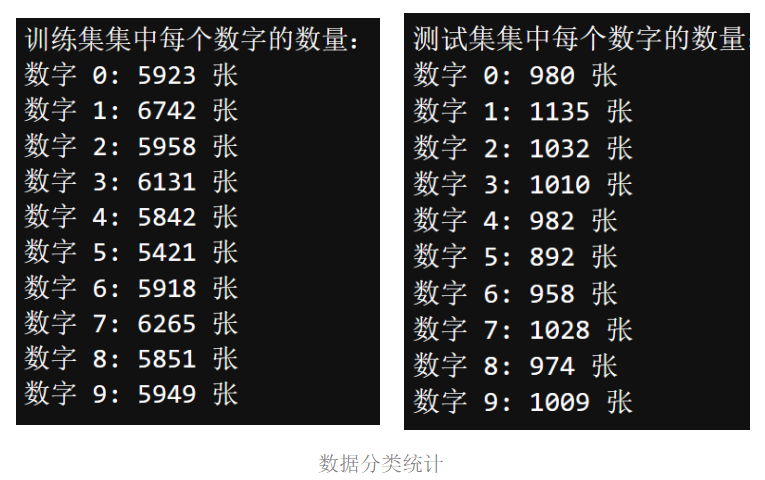
数据分类统计:
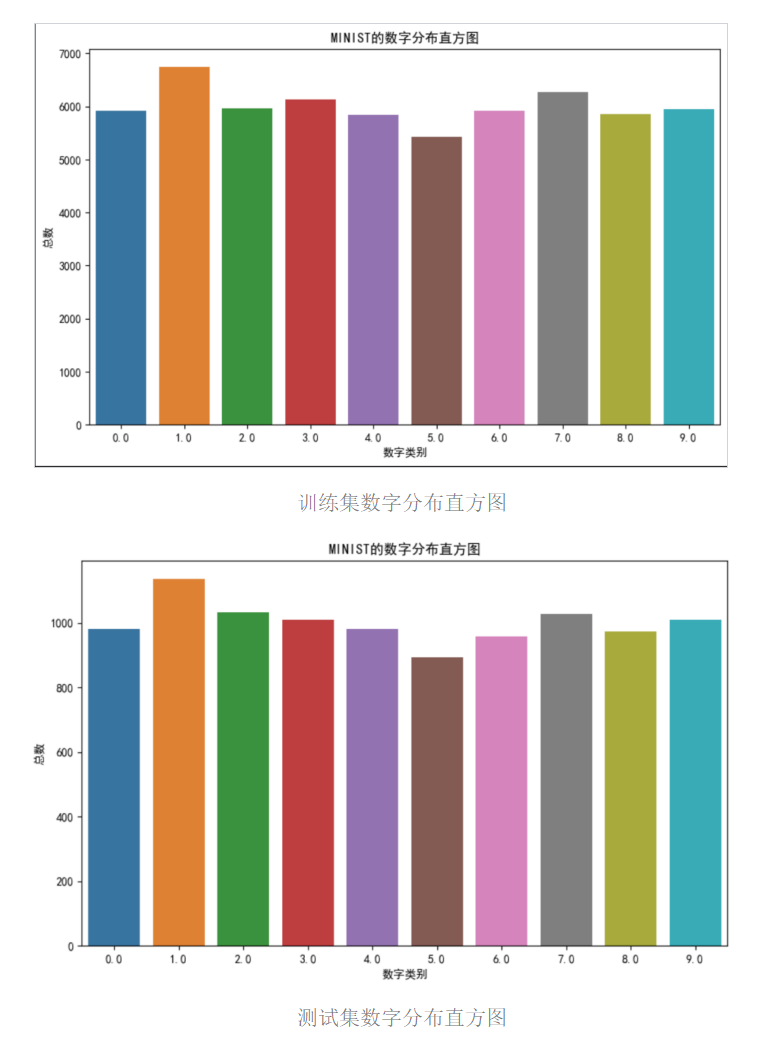
- 数据集包含10个类别(0-9),各类别的数字分布如下图所示。
部分数据可视化:
- 数据集中的部分图像示例如下图所示。

二、 数据预处理(数据准备)
2.1 像素级分布统计分析
首先对每个数字标识的图像样本进行了像素级的分布统计分析。基于统计结果,采用热图这一可视化工具来展示像素值的分布情况。热图通过颜色编码的方式直观地表示数据的密集程度,其中颜色的深浅变化对应于数据分布的密集与稀疏。
热图绘制代码:
import matplotlib.pyplot as plt
def plot_heatmaps(dist):
num_classes = dist.shape[0]
num_rows = dist.shape[1]
num_cols = dist.shape[2]
# 创建子图
fig, axes = plt.subplots(nrows=num_classes, ncols=1, figsize=(8, 2 * num_classes))
# 如果只有一张图,axes不是数组,需要将其转换为数组
if num_classes == 1:
axes = [axes]
for i in range(num_classes):
ax = axes[i]
# 绘制热图
im = ax.imshow(dist[i], cmap='hot', interpolation='nearest')
ax.set_title(f'Class {i}')
ax.axis('off') # 不显示坐标轴
# 添加颜色条
fig.colorbar(im, ax=ax)
plt.tight_layout()
plt.show()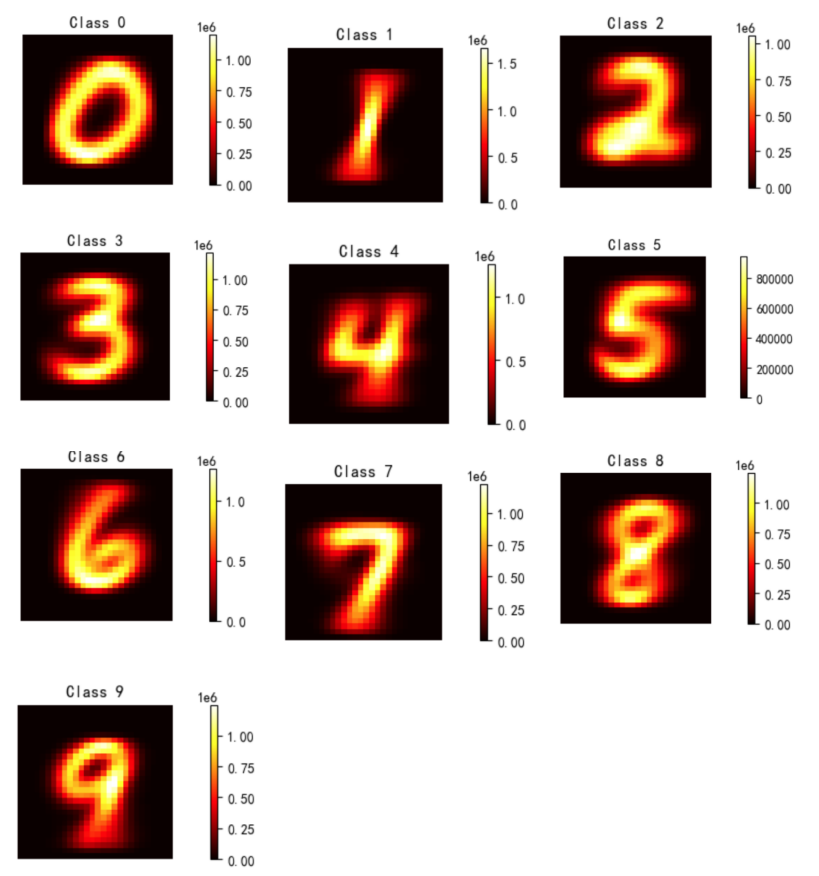
分析结果:
-
热图显示图像数据的像素分布呈现出一定的规律性,未发现显著的异常数据点。
-
数据集中的图像样本在像素分布上具有较高的一致性和稳定性,无需进行额外的数据清洗步骤。
2.2 数据展平
在图像识别任务中,原始图像通常以二维数组的形式存在,而大多数机器学习算法要求输入数据为一维向量形式。因此,将二维图像数据展平成一维向量是实现算法输入要求的前提。对于一个28x28的图像,其包含784个像素点,数据展平操作即将这些像素点的值从二维结构中释放出来,重新组织成一个长度为784的一维数组。
数据展平代码:
train_images = train_images.reshape(train_images.shape[0], -1)
test_images = test_images.reshape(test_images.shape[0], -1)2.3 特征缩放
特征缩放(Feature Scaling)是数据预处理的关键环节,对模型的性能和训练效率具有显著影响。本研究采用Z-score标准化(Standard Scaling)方法,对像素值进行特征缩放,以期达到均值为0,方差为1的标准化效果。这种转换有助于消除不同像素值之间的量纲差异,使得模型能够更加关注于特征之间的相对关系,而非其绝对大小。
特征缩放代码:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
selected_train_images = scaler.fit_transform(selected_train_images)
selected_test_images = scaler.transform(selected_test_images)2.4 数据裁剪
为了减少模型训练的时间复杂度,同时保持数据集的代表性,本研究对原始数据集进行了裁剪。具体而言,对于每个类别,随机选取1000个训练样本,组成一个包含10,000个样本的训练集;对于测试集,从每个类别中随机选取100个样本,组成一个包含1,000个样本的测试集。
划分数据集代码:
import numpy as np
unique_labels = np.unique(train_labels)
selected_train_images = []
selected_train_labels = []
for label in unique_labels:
label_indices = np.where(train_labels == label)[0]
selected_indices = np.random.choice(label_indices, 1000, replace=False)
selected_train_images.extend(train_images[selected_indices])
selected_train_labels.extend(train_labels[selected_indices])
selected_test_images = []
selected_test_labels = []
for label in unique_labels:
label_indices = np.where(test_labels == label)[0]
selected_indices = np.random.choice(label_indices, 100, replace=False)
selected_test_images.extend(test_images[selected_indices])
selected_test_labels.extend(test_labels[selected_indices])
# 转换为numpy数组
selected_train_images = np.array(selected_train_images)
selected_train_labels = np.array(selected_train_labels)
selected_test_images = np.array(selected_test_images)
selected_test_labels = np.array(selected_test_labels)三、模型评估标准介绍
在现实世界的应用中,机器学习模型的性能评估需要在捕获少数类的能力与将多数类错误分类的代价之间寻找平衡。一个优秀的模型应当在尽可能识别少数类的同时,保持对多数类的高准确率。为了全面评估模型在这方面的能力,本研究引入了两个关键的模型评估指标:混淆矩阵(Confusion Matrix)和ROC曲线。
3.1混淆矩阵
混淆矩阵是衡量分类模型性能的基本工具,通过一个简单的表格形式展示模型预测结果与实际标签之间的关系。主对角线上的值表示正确分类的样本数量,非对角线上的值表示错误分类的样本数量。
绘制混淆矩阵代码:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
print("绘制混淆矩阵...")
cm = confusion_matrix(selected_test_labels, predicted_test_labels)
ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=unique_labels).plot()
plt.title("混淆矩阵")
plt.show()3.2ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是评估二分类模型性能的重要工具,通过展示不同阈值下模型的假阳性率(FPR)和真正率(TPR)之间的关系来评估模型性能。
绘制ROC曲线代码:
from sklearn.preprocessing import label_binarize
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
print("绘制ROC曲线...")
n_classes = len(unique_labels)
y_test = label_binarize(selected_test_labels, classes=unique_labels)
y_score = model.predict_proba(selected_test_images)
# 计算每个类别的ROC曲线和AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制所有类别的ROC曲线
plt.figure()
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label=f'Class {unique_labels[i]} (area = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()四、模型训练
本研究中,将28x28像素的图像展开为784维的一维向量,每个像素点的灰度值被视为一个独立的特征。支持向量机(SVM)作为一种监督学习算法,其核心优势在于能够通过核技巧有效地处理高维数据。SVM的性能在很大程度上取决于所选择的核函数及其参数。
针对不同的核函数,本研究训练了三组SVM模型,以评估它们在图像识别任务中的表现。具体而言,选择了线性核、多项式核和高斯核(径向基函数核)作为研究对象。
4.1线性核SVM
线性核SVM适用于线性可分的数据集,其核函数为特征向量的点积。在本研究中,使用线性核SVM来评估数据集的线性可分性,并确定其在图像识别任务中的基线性能。
训练代码:
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
print("训练SVM模型...")
model = OneVsRestClassifier(SVC(kernel='linear', probability=True))
model.fit(selected_train_images, selected_train_labels)
# 测试模型
print("测试模型...")
predicted_test_labels = model.predict(selected_test_images)
accuracy = np.mean(predicted_test_labels == selected_test_labels)
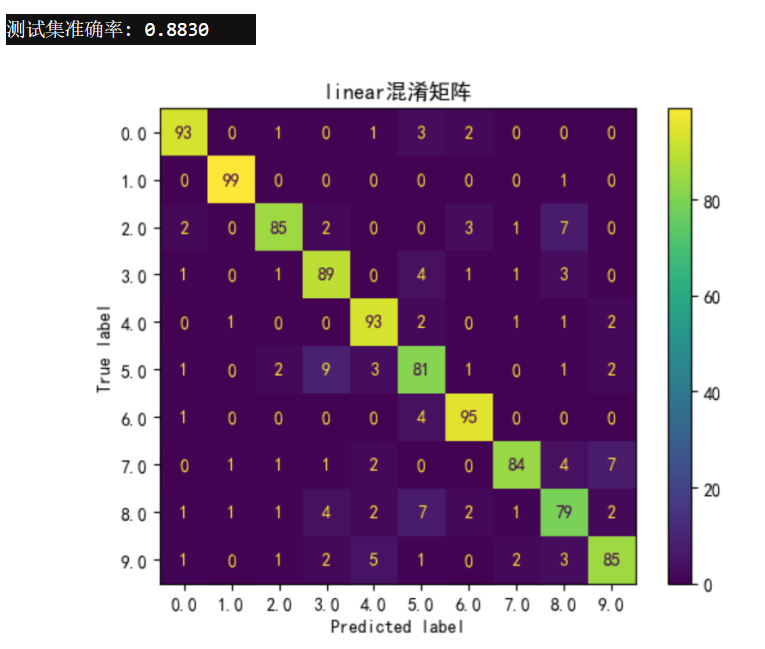
print(f"测试集准确率: {accuracy:.4f}")运行结果:
-
测试集准确率:0.8830
-
模型在识别数字8时表现不佳,而在识别数字1时表现最佳。
-
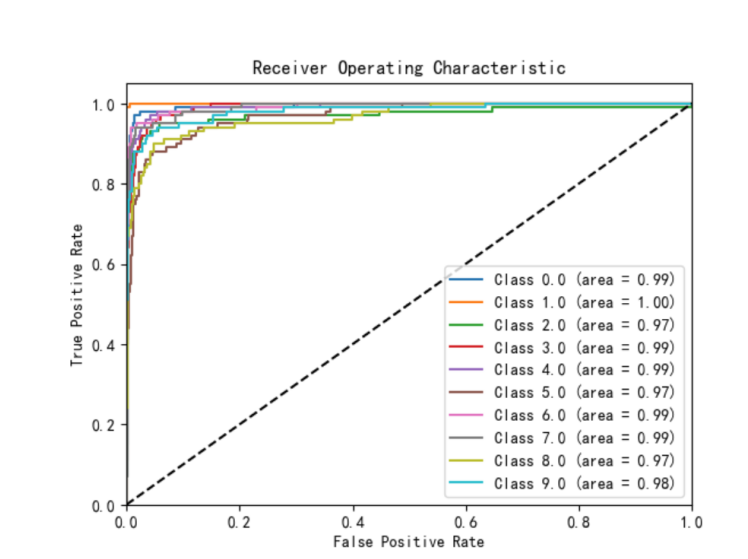
混淆矩阵和ROC曲线如下图所示:
4.2多项式核SVM
多项式核SVM能够处理非线性数据,通过将特征空间映射到更高维的空间来实现非线性分类。本研究中,调整多项式核的阶数和系数,以寻找最佳的分类性能。
训练代码:
model = OneVsRestClassifier(SVC(kernel='poly', degree=3, coef0=1, probability=True))
model.fit(selected_train_images, selected_train_labels)
# 测试模型
predicted_test_labels = model.predict(selected_test_images)
accuracy = np.mean(predicted_test_labels == selected_test_labels)
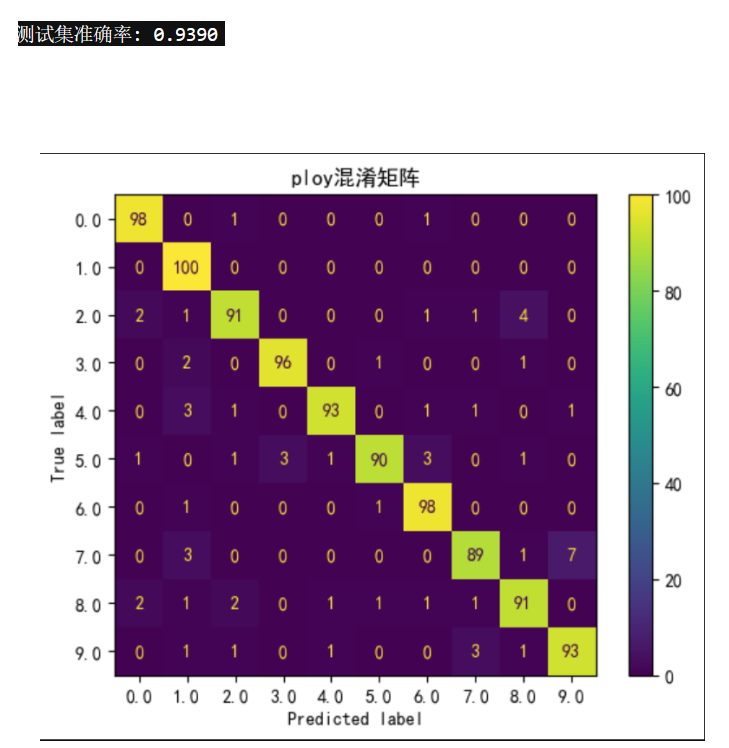
print(f"测试集准确率: {accuracy:.4f}")运行结果:
-
测试集准确率:0.9250
-
模型在识别数字1时表现最佳,但在识别数字7和5时效果不佳。
-
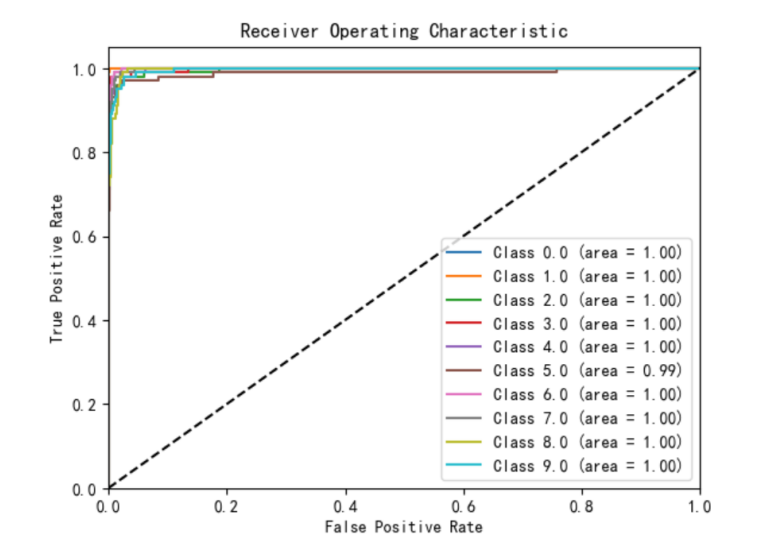
混淆矩阵和ROC曲线如下图所示:
4.3高斯核SVM
高斯核SVM(径向基函数核)是一种处理非线性数据的强大工具。通过调整高斯核的γ(gamma)参数,可以控制决策边界的曲率,从而适应数据的复杂性。
训练代码:
model = OneVsRestClassifier(SVC(kernel='rbf', gamma=0.01, probability=True))
model.fit(selected_train_images, selected_train_labels)
# 测试模型
predicted_test_labels = model.predict(selected_test_images)
accuracy = np.mean(predicted_test_labels == selected_test_labels)
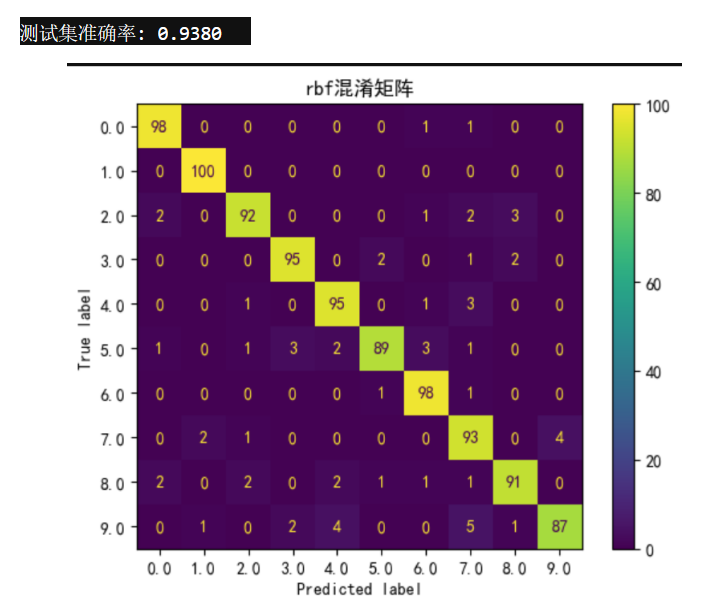
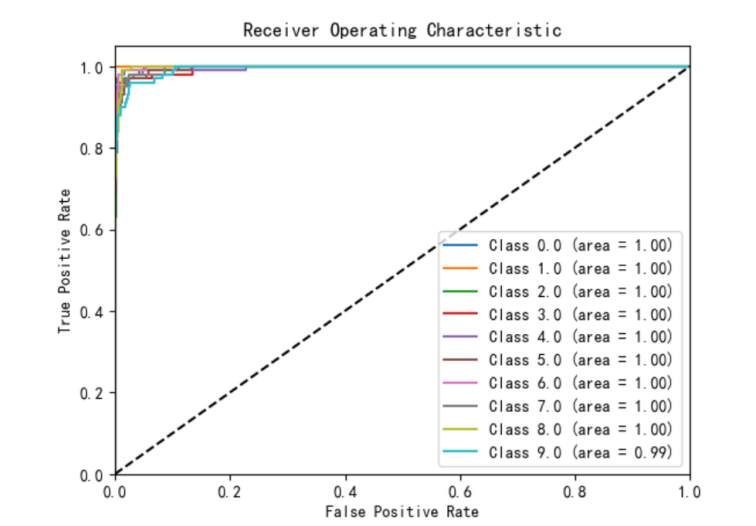
print(f"测试集准确率: {accuracy:.4f}")运行结果:
-
测试集准确率:0.9310
-
模型在识别数字1时表现最佳,但在识别数字7和5时效果稍差。
-
混淆矩阵和ROC曲线如下图所示:
五、模型结果与分析
5.1 模型性能总结
在本次课程设计中,我们针对手写数字识别的实际问题进行了深入研究,并成功实现了模型的预期目标。通过训练不同核函数的SVM模型,我们得到了以下结果:
| 核函数类型 | 测试集准确率 |
|---|---|
| 线性核 | 0.8830 |
| 多项式核 | 0.9250 |
| 高斯核 | 0.9310 |
5.2 模型性能分析
-
线性核SVM:
-
适用于线性可分的数据集,但MNIST数据集是非线性可分的,因此线性核的性能较低。
-
模型在识别结构简单的数字(如1)时表现较好,但在复杂数字(如8)上表现不佳。
-
-
多项式核SVM:
-
多项式核通过将特征空间映射到更高维,能够处理非线性数据。
-
模型在识别数字1时表现最佳,但在区分形状相似的数字(如7和9)时存在局限性。
-
-
高斯核SVM:
-
高斯核通过调整γ参数,能够更好地适应数据的复杂性。
-
模型在所有核函数中表现最优,但对某些复杂数字(如7和5)的识别仍存在一定的误差。
-
5.3 核函数选择与参数优化
-
核函数选择:核函数的选择对模型性能有显著影响。线性核适用于简单线性问题,多项式核和高斯核则更适合处理非线性数据。高斯核在本实验中表现最优。
-
参数优化:多项式核的阶数(degree)和系数(coef0),以及高斯核的γ参数对模型性能有重要影响。通过调整这些参数,可以进一步优化模型性能。
5.4 未来研究方向
-
深度学习方法:
-
考虑使用深度学习方法,如卷积神经网络(CNN),进一步提高手写数字识别的性能。
-
CNN能够自动提取图像特征,对复杂图像的识别效果更好。
-
-
模型可解释性:
-
探索模型的决策过程,提升模型的可解释性。
-
可解释性研究有助于理解模型如何做出预测,从而提高模型的可信度。
-
-
实际应用:
-
将模型应用于实际场景,如邮票手写邮编识别。
-
通过数字图像处理技术,将邮票上的数字图像处理为28x28像素大小,输入模型进行识别。
-
六、结论
本研究成功实现了手写数字识别的目标,并深入探讨了核函数选择、参数优化对模型性能的影响。实验结果表明,高斯核SVM在MNIST数据集上表现最优,达到了93.10%的测试集准确率。未来的研究将聚焦于深度学习方法的应用和模型可解释性的提升,以进一步推动手写数字识别技术的发展。