
论文链接:https://arxiv.org/pdf/2510.02283
项目链接:https://self-forcing-plus-plus.github.io/
亮点直击
识别视野扩展瓶颈: 揭示了自回归模型在扩展生成视野时的主要障碍,即训练与推理过程中时间性和监督的双重不匹配。这一见解为克服生成长度的先前限制提供了明确的目标。
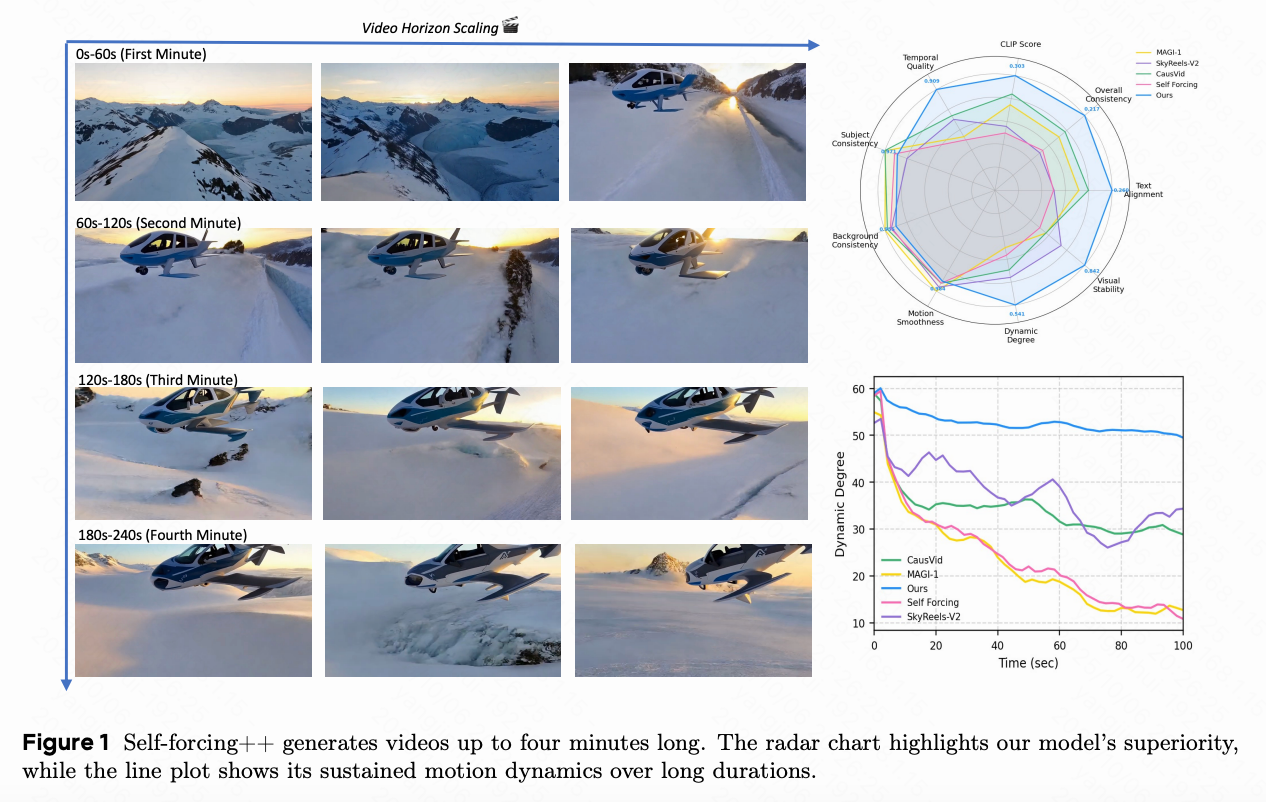
简单解决方案: 提出了一个名为 Self-Forcing++ 的简单训练框架。通过超越教师的视野进行生成,并在学生模型自身的长时间、错误累积的展开轨迹上进行校正,Self-Forcing++ 将高质量视频生成扩展到 100 秒,远远超越了之前的SOTA方法,并且无需重用重叠帧。
最先进性能和视野可扩展性: Self-Forcing++ 在长视频生成方面实现了SOTA性能,涵盖了不同的时长(例如 10 秒、50 秒、100 秒)。此外,本文发现了一个显著的可扩展特性:通过扩大训练计算量,本文的模型生成能力可以扩展到数分钟,这在以前被认为是难以实现的壮举。
总结速览
解决的问题
扩散模型在生成高质量图像和视频时,由于对transformer架构的依赖,导致计算成本高昂,尤其是在长视频生成方面。现有方法在将生成视野扩展到长视频时,常因训练与推理的不匹配而导致质量下降。
提出的方案
提出了一种名为 Self-Forcing++ 的简单训练框架,通过利用教师模型的丰富知识来指导学生模型,从自生成的长视频中抽取样本片段进行校正,以减轻长视野视频生成中的质量下降。
应用的技术
-
自回归模型:通过自回归形式生成长视频。
-
Self-Forcing++ 框架:在学生模型自身的长时间、错误累积的展开轨迹上进行校正。
-
利用教师模型的知识:从自生成的视频中抽取片段指导学生模型。
达到的效果
-
在保持时间一致性的同时,将视频长度扩展到教师能力的20倍。
-
避免了过度曝光和错误累积问题,不需要重新计算重叠帧。
-
能够生成长达4分钟15秒的视频,比基线模型长50倍。
-
在标准和改进的基准测试中,显著优于基线方法,在不同时长的视频生成中实现了最先进的性能。
-
通过扩大训练计算量,模型的生成能力可以扩展到数分钟,突破了之前的技术限制。
方法
本节详细介绍了用于长视频生成的方法。本文首先回顾了双向模型转换为流式自回归生成器的过程。在此基础上,本文引入了针对长视频合成的创新策略。完整的生成过程在算法1中形式化。

背景
视频扩散模型虽然强大,但通常需要沿多步噪声计划进行去噪,这使得生成过程计算密集。减轻这种计算负担的一种常见策略是将基础模型提炼为几步生成器。该领域的主要方法包括分布匹配(DM)和一致性模型(CM)。在 CausVid 和 Self-Forcing 的方法基础上,本文将原始双向教师模型提炼为一个几步生成器,然后将其转换为自回归模型。这一转换通过训练学生模型来复制从教师采样的常微分方程(ODE)轨迹来实现。本文将此过程称为初始化阶段。Self-Forcing 方法通过使用分布匹配蒸馏(DMD)损失等技术,在自生成的长达五秒的展开中训练提炼模型,从而扩展了这一方法。虽然这种技术有效地减轻了 CausVid 中存在的过度曝光伪影,但它表现出一个关键限制:在生成超出其受限训练视野的序列时,生成质量显著下降。
超越教师的限制进行扩展训练
动机 正如前面讨论的,教师模型仅在五秒视频片段上进行训练。因此,基于提炼的方法如 CausVid 和 Self-Forcing 仅在这个有限的时间窗口内强制学生与教师的分布对齐。这种受限的训练目标导致在生成超出这五秒视野时,质量急剧下降。尽管存在这种性能崩溃,本文做出了一个关键观察:超出训练视野展开的视频通常保留结构一致性,即使这种一致性表现为不良伪影,如运动停滞(Self-Forcing 中的常见失败模式)。这表明核心问题并不是自回归机制的根本崩溃,自回归机制正确利用历史 KV 缓存来保持上下文。相反,主要问题是在扩展展开期间自回归错误的累积。这些错误累积并最终表现为运动丢失、场景冻结以及视觉保真度的灾难性下降。这一见解促使本文引入一种简单但有效的方法来减轻错误累积,这将在以下部分中描述。
反向噪声初始化 将学生-教师提炼扩展到长视野视频生成的一个核心挑战在于噪声初始化策略。在短视野设置中(即对于长度最多为 帧的视频),学生模型可以直接在从教师采样的完整轨迹上进行监督,每个轨迹都源于随机噪声。然而,对于长视野生成,从纯随机噪声初始化的轨迹与前面的视频内容脱节,导致基本的上下文不匹配,因为采样的噪声不保留先前生成帧的时间依赖性。基于上述观察,本文将噪声重新添加到去噪后的潜在向量中,并将其用作起始噪声,这也被证明可以提升提炼性能。虽然类似的重新注入噪声技术在之前的工作中已有应用,但本文的动机和应用是不同的。他们主要用于短视频提炼,主要是为了增强单次生成的质量或规避对真实训练数据的需求。本文利用它作为一种机制来在长视频中强制时间一致性。具体来说,学生模型首先展开为一个包含 个干净帧的序列,其中 , 表示教师可以可靠生成的最大视野,如 5 秒。然后,本文根据相同的扩散噪声计划 将噪声重新注入学生的展开中。形式上,给定由学生生成的干净轨迹 ,生成被扰动为:
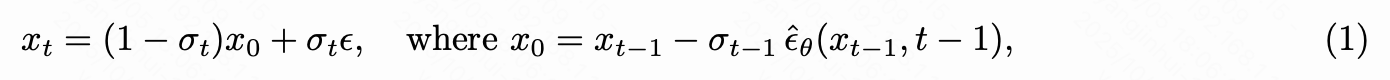
其中, 表示高斯噪声, 是由参数 表示的噪声预测网络。该网络用作计算教师和学生分布的初始状态。此方法确保学生模型和教师模型之间的分布差异是在保留时间一致性并根据规定的噪声计划正确构建的轨迹上进行评估的。
扩展分布匹配提炼 本文将训练扩展到长视频的策略基于以下观察:虽然双向教师模型仅在短的五秒片段上进行训练,但它从训练数据中隐含地捕获了"世界"的基础数据分布。从这个角度来看,任何短的、连续的视频片段都可以被视为有效、较长视频序列的边缘分布的一个样本。这一直觉激发了本文核心方法的扩展。由于本文的基线方法 Self-Forcing 将训练持续时间限制在前 帧(通常约为 5 秒),本文指示学生模型展开到 帧,其中 。然后,本文从生成的序列中均匀采样一个长度为 的连续窗口,并在此窗口内计算学生和教师模型之间的分布差异。这个滑动窗口提炼过程形式化为方程(2):
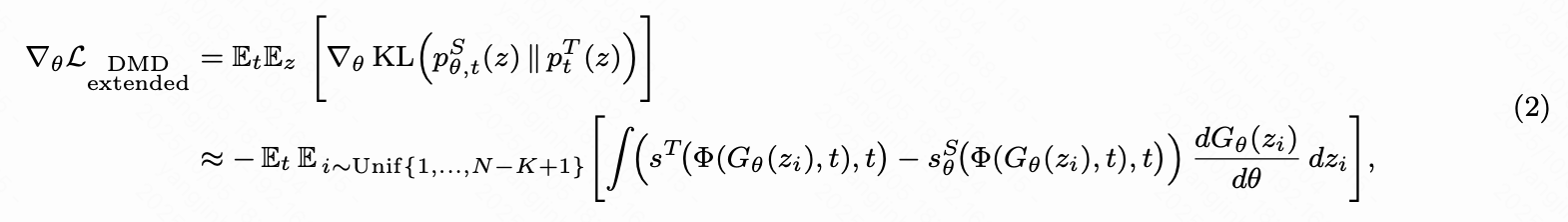
这里, 表示在给定潜变量 时学生生成器的展开, 是在时间步 的变换过程。 和 分别表示在时间 的学生和教师分布,对应的分数为 和 。本文从长度为 的学生展开中均匀采样起始索引 ,并提取一个长度为 的窗口。然后,训练学生以最小化其分布与教师分布在该窗口上的平均 KL 散度。窗口大小 通常选择为与教师模型最初训练生成的范围相匹配。
备注: 双向扩散可以被视为在不同去噪时间步中逐步恢复降级目标的过程。本文的方法通过让短期教师在不同的时间帧逐步恢复学生的降级展开,并将这些校正知识提炼回学生模型,从而将这一理念适应于自回归视频生成。
使用滚动 KV 缓存进行训练 尽管在推理时使用 KV 缓存,CausVid 仍然依赖于重新计算重叠帧,并遭受严重的过度曝光问题。Self-Forcing 尝试解决这一问题,但通过在训练期间使用固定缓存而在推理时使用滚动缓存,引入了训练-推理不匹配。虽然这通过掩盖第一个潜在帧部分缓解,但不匹配仍导致长视频中的显著误差累积和时间闪烁。相比之下,本文的方法通过在训练和推理期间使用滚动 KV 缓存自然消除了这种不匹配。在训练时,该缓存用于展开远超教师监督范围的序列以计算上述扩展 DMD。因此,本文的方法极大地简化了整个过程,不需要重新计算重叠帧或潜在帧掩码。
通过 GRPO 改善长期平滑性
使用滑动窗口或稀疏注意力机制进行长序列生成的生成模型常见缺点是长期记忆的逐渐丧失。这种退化通常表现为时间不一致性,例如对象突然出现或消失,或不自然的快速场景转换。尽管本文提出的方法已经取得了强劲的结果,但本文展示了当这种现象出现时,群体相对策略优化(GRPO),一种强化学习技术,可以在自回归视频生成框架中使用。每步重要性权重 ,其中 表示在时间步 对输出 的策略函数,可以根据方程(1)计算,而整体生成概率可以计算为当前自回归展开中的所有对数概率之和,本文在第 8.4 节中展示。为了引导优化过程朝着时间平滑的输出,本文遵循先前的工作,使用连续帧之间光流的相对大小作为运动连续性的代理。
长视频评估的新指标
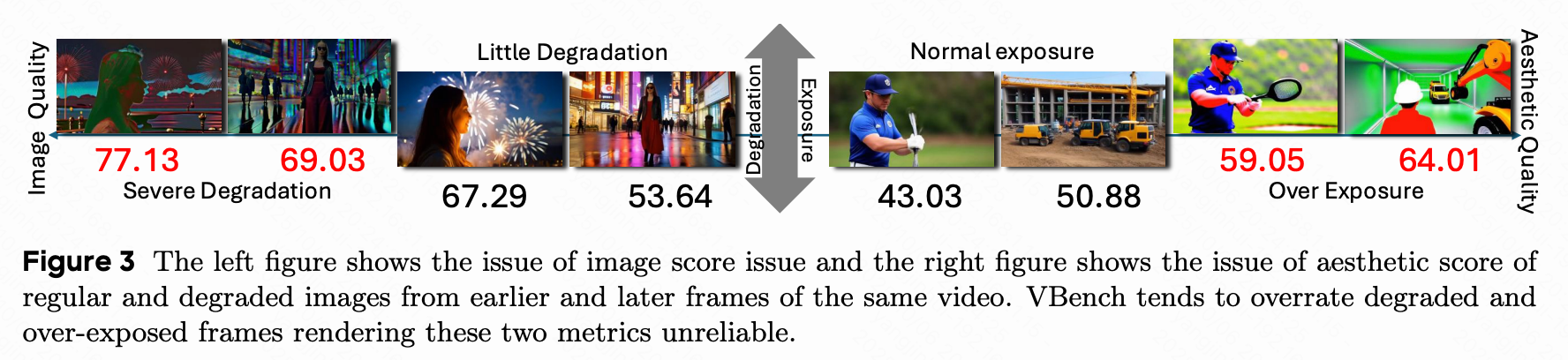
大多数先前的工作依赖 VBench 来评估长视频生成中的图像和美学质量。然而,本文发现过时的评估模型使得基准偏向于过度曝光的视频(例如,CausVid)和退化的长视频(例如,Self-Forcing),导致不准确的评分。为了解决这个问题,本文采用了 Gemini-2.5-Pro,这是一种具有强大推理能力的最先进视频多模态大模型。本文的协议定义了关键的长视频问题,如过度曝光和误差累积,提示 Gemini-2.5-Pro 在这些轴上对视频进行评分,并将结果汇总为一个 0 到 100 的尺度,称为视觉稳定性,以便进行一致的比较。更多细节见下图 3。
实验
设置
基线方法 本文包括以下基线方法,如 NOVA、Pyramid Flow、SkyReelsV2-1.3B、MAGI-1-4.5B(蒸馏至16步用于长视频生成)、CausVid 和 Self-Forcing,这两者都是与本文类似的 1.3B 蒸馏少步生成器。额外的两个最先进的双向模型 LTX-Video 和 Wan2.1 也被纳入参考。
评估指标 本文在两个主要设置下进行评估。第一个设置遵循一般的 VBench 协议,该协议使用 946 个提示在 16 个维度上测量 5 秒短视频的生成质量。第二个设置检查模型在使用 CausVid 中使用的相同提示集(由 MovieGen 的 128 个提示组成)时,将生成扩展到 50/75/100 秒的能力。在此设置中,性能通过 VBench Long 和本文提出的改进评估指标进行评估。
长视频生成中的实证结果
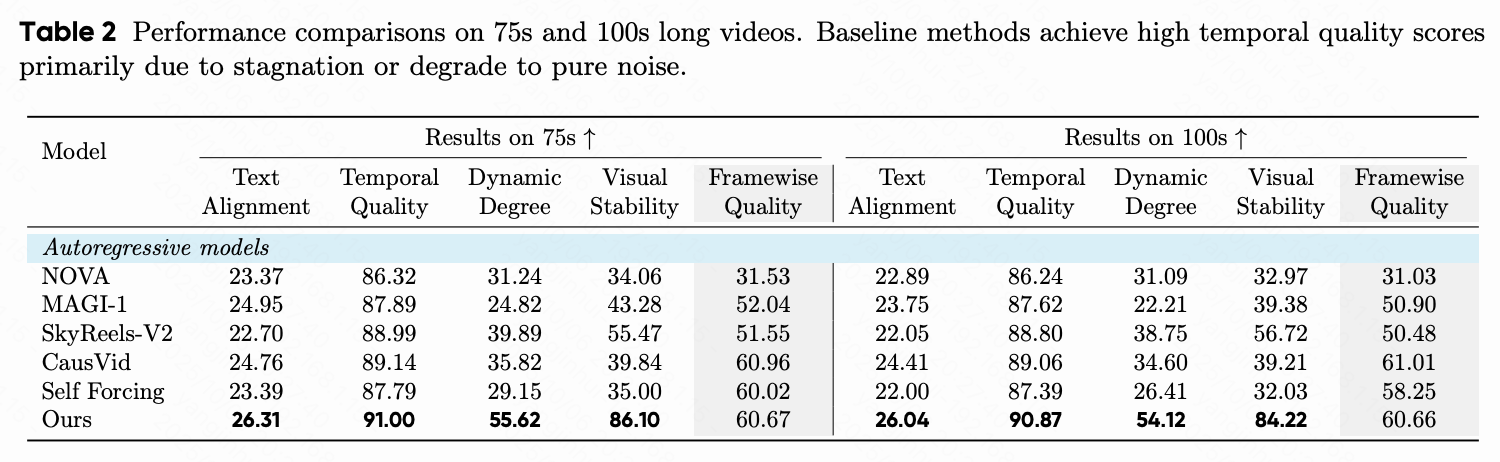
定量和定性结果分别展示在下表 1 和下表 2,以及下图 1 和下图 4 中。本文的方法在短期生成中表现出竞争力,并在生成范围扩展时显示出显著优势。
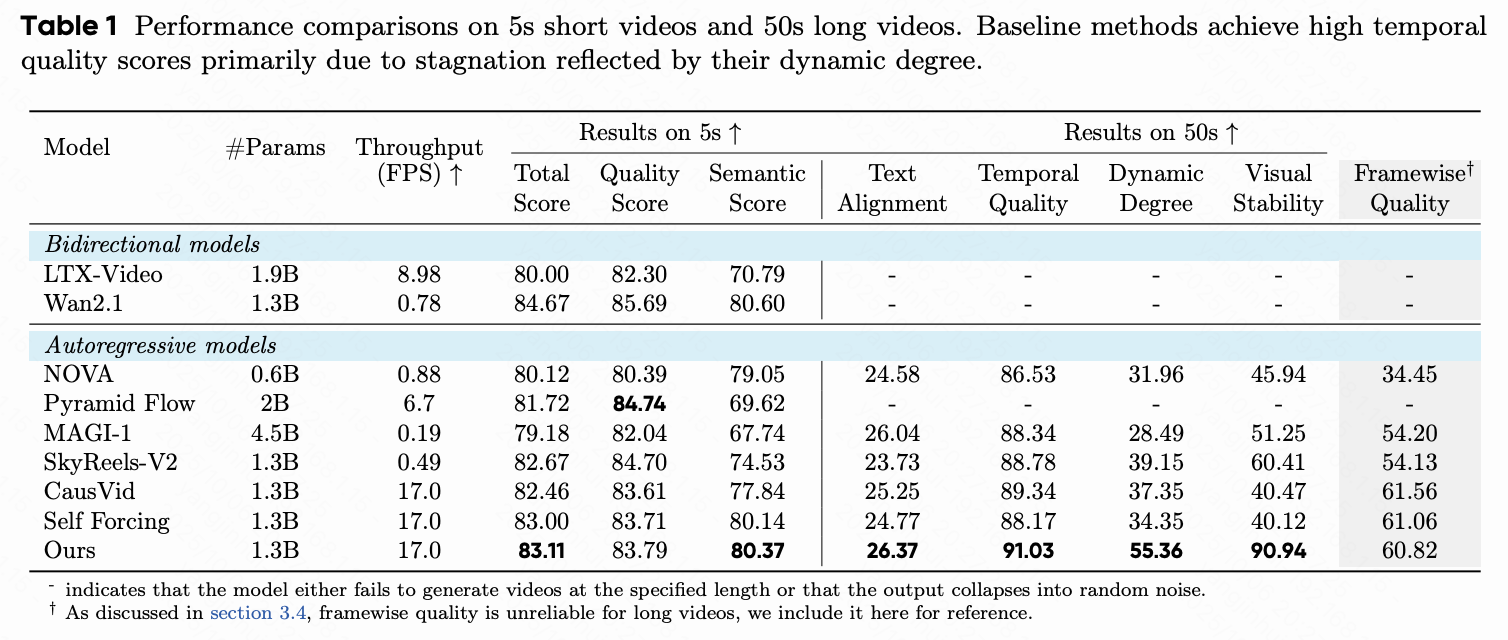

短期(5秒):尽管没有专门针对初始 5 秒进行训练,本文的模型在短片上表现与 Self-Forcing 相当,取得了 80.37 的语义得分和 83.11 的总得分,均超过了其余基线。
长期(50秒/75秒/100秒):在长期生成中,本文方法的优越性更加明显。本文观察到关键指标的一致改进。例如,本文的模型在 100 秒视频中实现了 26.04 的文本对齐得分和 54.12 的动态程度,分别比依赖于重计算重叠帧的 CasuVid 高出 6.67% 和 56.4%,并比本文的基线方法 Self-Forcing 高出 18.36% 和 104.9%,如图 4 所示。这表明本文的方法有效地减轻了长时间展开中的错误积累。
相比之下,基线方法在生成长视频时表现出显著的退化。其主要失败模式包括:i) 运动崩溃:虽然保持了短期时间结构,但其视频经常崩溃为几乎静态的序列,这在其低动态程度得分中得以体现。然而,本文的方法在整个序列中保持了连贯的运动。ii) 保真度退化:基线方法通常遭遇曝光不稳定的问题。例如,CausVid 趋向于过度曝光,而 Self-Forcing 视频则逐渐变暗。本文的模型保持了稳定的亮度和视觉质量。Self-Forcing 的这种退化是由于没有明确的长时间训练导致的累积错误的直接后果。尽管一些扩散强制方法如 SkyReels 显示出从噪声崩溃中偶尔恢复的迹象,但结果内容保真度较低。
消融研究
注意力窗口的长度
缓解 Self-Forcing 的训练-推理不匹配的一种简单方法是缩短训练期间的注意力跨度,使模型在有限的时间范围内接触到更多样的缓存状态。例如,一个 5 秒的片段对应于 21 个潜在帧;通过减少注意力窗口,模型被迫多次滑动注意力。如下表 3 所示,并在下图 7 中可视化,较小的窗口带来了适度的提升。例如,视觉稳定性在 9 个潜在帧的窗口下从 40.12 提升到 52.50。然而,这以增加的不一致性为代价,因为模型现在依赖于比原来的 21 帧历史少得多的上下文。


GRPO 与光流奖励的效果
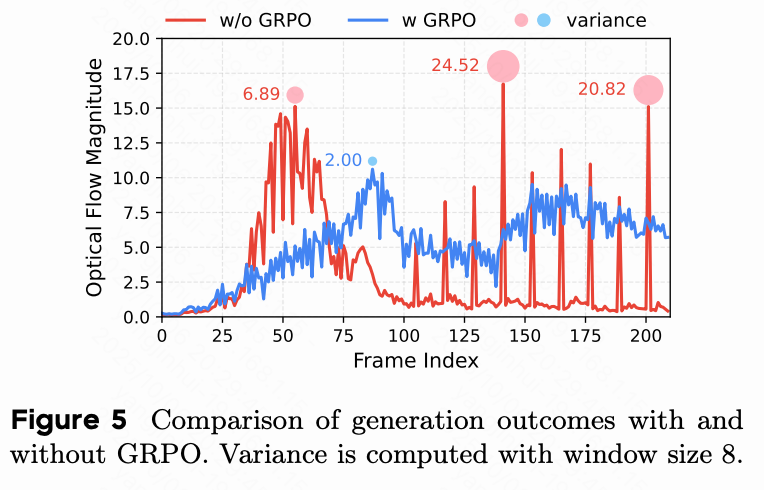
在这里,通过检查光流幅度(一个时间稳定性的代理)展示其增强时间一致性的有效性。如下图 5 所示,没有使用 GRPO 生成的视频可能会出现突然的场景转换。这些转换表现为光流幅度的尖锐峰值,这是推理期间使用滚动窗口机制所导致的伪影。通过促进更平滑的时间过渡,本文的 GRPO 方法有效地抑制了这些峰值。这显著提高了生成视频的长程一致性和整体感知质量。
训练预算扩展
最后,研究了扩展训练预算对模型长时间视频生成能力的影响。如下图 6 所示,本文的模型在 ODE 初始化后,仅表现出生成短而低保真度片段的初步能力。本文建立了一个基线(1×预算),即生成一个连贯的 5 秒视频所需的训练。在这个规模下,扩展生成会导致显著的时间闪烁和错误积累,这与 Self-Forcing 的失败模式相似。将预算增加到 4×使模型能够在更长的时间范围内保持语义连贯性,成功渲染出像指定大象这样的连贯主体。在 8×时,模型开始生成更详细的背景和更语义准确的主体,尽管运动动态仍然有限且时间质量退化持续。进一步扩展到 20×带来了显著的改进,生成的高保真视频在超过 50 秒内保持稳定。值得注意的是,在 25×预算下,模型成功生成了一个 255 秒的视频,几乎没有质量损失。这些发现表明,扩展训练预算是实现高质量、长时间视频合成的可行途径,避免了对难以获取的大规模真实视频数据集的依赖。

结论
本文介绍了 Self-Forcing++,这是一种在自回归长视频生成中减轻错误积累的方法。通过利用短视频教师来指导学生在其自生成的长时间片段上,本文的方法学会在不需要长视频监督的情况下纠正错误。实验表明,本文的方法显著将视频长度扩展到超过 4 分钟(比基线提高了 50 倍),同时保持高保真度。本文还提出了一种新的指标,视觉稳定性,以解决现有长视频评估基准中的关键偏差。本文的贡献为更稳健和可扩展的长视频合成铺平了道路。
局限性和未来工作
尽管本文的方法有效,但它继承了自迫基础和基础 Wan2.1-T2V-1.3B 模型的某些局限性。主要缺点包括与教师强制相比较慢的训练速度以及缺乏长期记忆,这可能导致在长时间遮挡的区域出现内容偏离。为了解决这些挑战,本文确定了几个有前景的未来方向。首先,为了解决自回滚的高训练成本,本文将探索训练过程的并行化。其次,为了进一步减轻长序列中的质量退化,本文计划研究控制潜在向量保真度的技术。这包括对存储在 KV 缓存中的潜在表示进行量化,或对 KV 缓存进行归一化以防止分布偏移。最后,本文旨在将长期记忆机制整合到本文的自回归框架中,本文相信这对于实现真正的长程时间一致性至关重要。
讨论
接下来,讨论与本文相关的并发工作并强调它们的关键差异。Rolling Forcing 扩展了 Rolling Diffusion 的概念,通过对不同的视频帧应用逐渐变化的噪声水平。它集成了注意力沉帧以平衡短期和长期一致性,同时通过采样不重叠的帧提高了训练效率。LongLive 基于 Self Forcing,引入了 KV 重新缓存以进行提示切换并利用干净的上下文。它进一步采用注意力沉帧,通过在教师视野之外重复应用 DMD 来减轻错误积累。本文的方法与 LongLive 最为接近,本文也将 DMD 以窗口化的方式整合到长自回滚序列中,并使用干净的上下文,详见前文。然而,与 LongLive 不同,本文的简化设计避免依赖注意力沉帧来对抗错误积累,这被证明是 LongLive 的一个关键设计。
Rolling Forcing 和 LongLive 以及本文的方法都能够生成长达数分钟的高质量视频,这标志着自回归长视频生成相比于之前方法的显著进步。
参考文献
1 Self-Forcing++: Towards Minute-Scale High-Quality Video Generation