Diffusion Models专栏文章汇总:入门与实战
前言:FlashVSR 是首个实现近实时(17 FPS)、流式处理、支持 1440p 的扩散视频超分辨率模型,通过三阶段蒸馏、局部稀疏注意力和微型条件解码器,兼顾速度、质量与可扩展性。
目录
[阶段 1:联合图像-视频训练(Full-Attention Teacher)](#阶段 1:联合图像-视频训练(Full-Attention Teacher))
[阶段 2:因果稀疏注意力适配(Causal Sparse Attention Adaptation)](#阶段 2:因果稀疏注意力适配(Causal Sparse Attention Adaptation))
[阶段 3:单步蒸馏(One-Step Distillation via DMD)](#阶段 3:单步蒸馏(One-Step Distillation via DMD))
[局部约束稀疏注意力(Locality-Constrained Sparse Attention)](#局部约束稀疏注意力(Locality-Constrained Sparse Attention))
[微型条件解码器(Tiny Conditional Decoder, TC Decoder)](#微型条件解码器(Tiny Conditional Decoder, TC Decoder))
背景和动机

随着移动视频和在线流媒体日益普及,人们对能够实时处理高分辨率、无限长度视频的VSR系统提出了更高要求。但实现高分辨率、高质量且支持实时流式处理的视频超分辨率,尤其是基于扩散模型的VSR,仍然极具挑战性,主要有三大主要障碍:
(1) 分块处理的高前瞻延迟(lookahead latency):受限于内存,大多数方法将长视频切分为重叠的片段并独立处理,这不仅在重叠帧上引入了冗余计算,还因需等待整个片段处理完毕而造成较高的前瞻延迟;
(2) 密集3D注意力机制的高昂计算成本:为获得更优视觉质量,大多数视频生成模型采用全时空注意力机制,其计算复杂度与分辨率呈平方关系,对于长时长、高分辨率视频而言计算开销难以承受;
(3) 训练-测试分辨率差距问题:大多数基于注意力的VSR模型在中等分辨率视频上训练,但应用于更高分辨率(如1440p)时性能显著下降。我们的分析表明,这一差距源于训练与推理阶段位置编码范围不匹配。
方法
三阶段蒸馏训练流程
阶段 1:联合图像-视频训练(Full-Attention Teacher)
- 基础模型:WAN 2.1 视频扩散模型(已预训练于大规模视频生成)。
- 任务适配 :将其用于 VSR,通过引入 LR Proj-In 层(而非原始 VAE 编码器)将低分辨率输入映射到潜在空间。
- 训练数据 :VSR-120K 数据集中的 120k 视频 + 180k 图像(图像视为单帧视频)。
- 注意力机制 :使用 全时空注意力(block-diagonal segment mask),保留完整时空先验。
- 损失函数 :标准 流匹配损失(Flow Matching Loss)。
✅ 此阶段得到一个高质量但计算昂贵的"教师模型"。
阶段 2:因果稀疏注意力适配(Causal Sparse Attention Adaptation)
- 目标 :将教师模型改造为支持 流式处理(streaming)的结构。
- 关键操作 :
- 引入 因果掩码(causal mask):每个 latent 只能关注当前及过去帧,防止未来信息泄露。
- 采用 块稀疏注意力 (block-sparse attention):
- 将 Q/K 划分为不重叠块(如 8×8)。
- 对每个块做平均池化 → 计算 粗粒度块间注意力。
- 选取 top-k 最相关块对 → 仅在这些区域做 细粒度 full attention。
- 结果:计算量降至 10--20%,性能几乎无损。
- LR Proj-In 层 :改造为 因果版本,支持逐帧流式输入。
✅ 此阶段输出一个 稀疏+因果 的中间模型,可流式推理但仍是多步扩散。
阶段 3:单步蒸馏(One-Step Distillation via DMD)
- 目标 :将多步教师模型压缩为 单步学生模型。
- 蒸馏方法 :分布匹配蒸馏(Distribution Matching Distillation, DMD)。
- 关键创新 :并行训练范式 (Parallel Training Paradigm)
- 输入:仅需 当前 LR 帧 + 高斯噪声 ,无需依赖前一帧的预测结果。
- 原因:VSR 是强条件任务(LR 帧已包含内容与运动信息),不像视频生成那样需依赖历史预测帧来保证运动合理性。
- 优势:
- 消除 训练-推理不一致(无需"teacher forcing"或"student forcing")。
- 支持 全并行训练(所有帧可同时处理)。
✅ 最终得到 单步、流式、高质量 的 FlashVSR 主干模型。
局部约束稀疏注意力(Locality-Constrained Sparse Attention)
问题 :当推理分辨率(如 1440p)远高于训练分辨率(如 540p)时,RoPE(旋转位置编码)会出现周期性重复,导致注意力混乱 → 图像模糊、纹理重复。
解决方案:
- 对每个 query 的注意力范围施加 空间局部窗口约束 (local window)。
- 例如:每个 token 只在 ±64 像素邻域内计算注意力。
- 效果 :
- 推理时的位置偏移范围 ≈ 训练时范围 → 对齐 RoPE 的有效区间。
- 避免远距离错误匹配 → 提升高分辨率泛化能力。
- 实现:在稀疏注意力的 top-k 块选择后,进一步限制每个块内的空间范围。
实验表明:该设计显著改善 1440p 推理质量,消除重复纹理(见 Fig. 3)。
微型条件解码器(Tiny Conditional Decoder, TC Decoder)
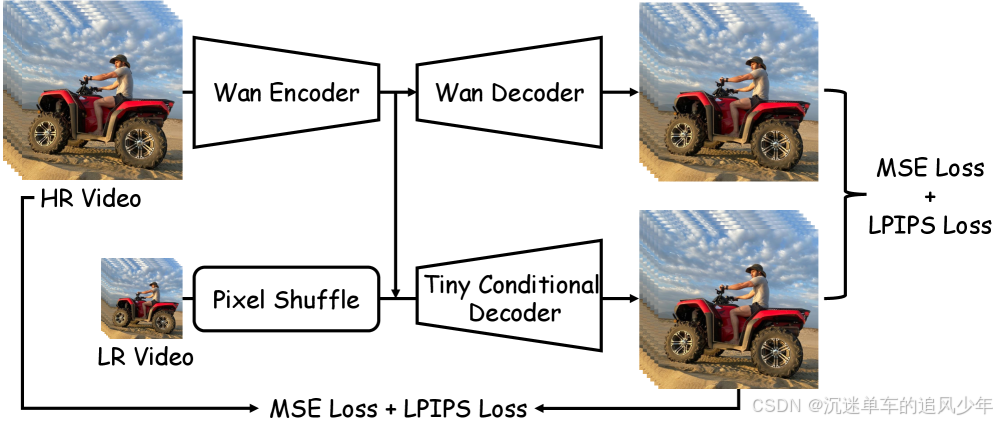
问题 :3D VAE 解码器占推理时间 70%,成为瓶颈(11.13s / 101 帧)。
设计思路:
- 不单纯缩小 VAE ,而是引入 LR 帧作为额外条件,降低解码难度。
- 结构:轻量 U-Net 式解码器,输入为:
- 潜在表示(latent)
- 对应的 低分辨率帧(经下采样对齐)
效果:
- 解码时间 :11.13s → 1.60s (7 倍加速)
- 画质损失极小:PSNR 仅下降 1.5 dB,感知质量几乎无损。
- 优于无条件小解码器:证明 LR 条件的有效性。
大规模数据集构建
为支持大规模训练,作者构建了新数据集:
- 120,000 高质量视频(平均 350 帧,≥1080p)
- 180,000 高清图像(短边 ≥1024px,多为 4K)
- 来源:Pexels, Pixabay, Videvo(专业素材,非网络爬虫)
- 质量过滤 :
- LAION-Aesthetic + MUSIQ:过滤低质量帧
- RAFT 光流:剔除静态/弱运动视频
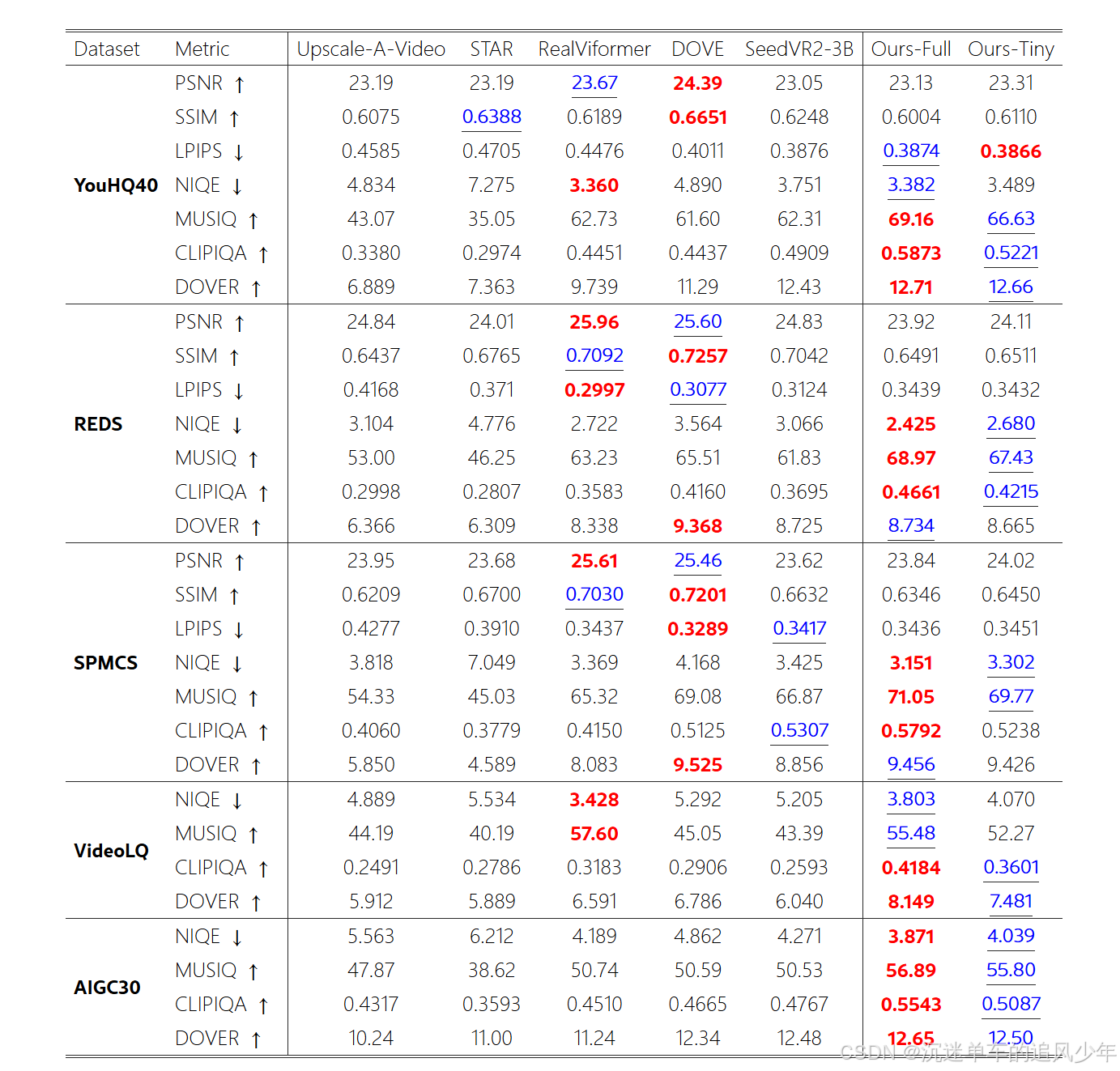
实验结果