如今文本生成图像与视频已不再是天方夜谭。然而,当大多数模型仍在为生成画面的清晰度与稳定性而努力时,一个更为棘手的挑战浮出水面:如何精准、一致地生成以「人物」为核心的高质量视频?对此,清华大学与字节跳动联合推出了一个名为 HuMo 的统一 HCVG 框架。它专为「创造人」而生,旨在攻克这一核心难题。
HuMo-17B 真正实现了「三位一体」生成。它不再仅仅依赖文本指令,而是将文本、图像与音频三大模态融为一体,作为驱动视频生成的源泉。这意味着,你可以上传一张人物照片,搭配一段描述动作的文本和一首背景音乐,模型便能生成一个既保持人物外貌高度一致、动作符合描述,又与音乐节奏同步的连贯视频。
教程链接:https://go.openbayes.com/a7ZXE
使用云平台:OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
登录 OpenBayes.com,在「公共教程」页面,选择一键部署 「HuMo-17B:三模态协同创作」教程。
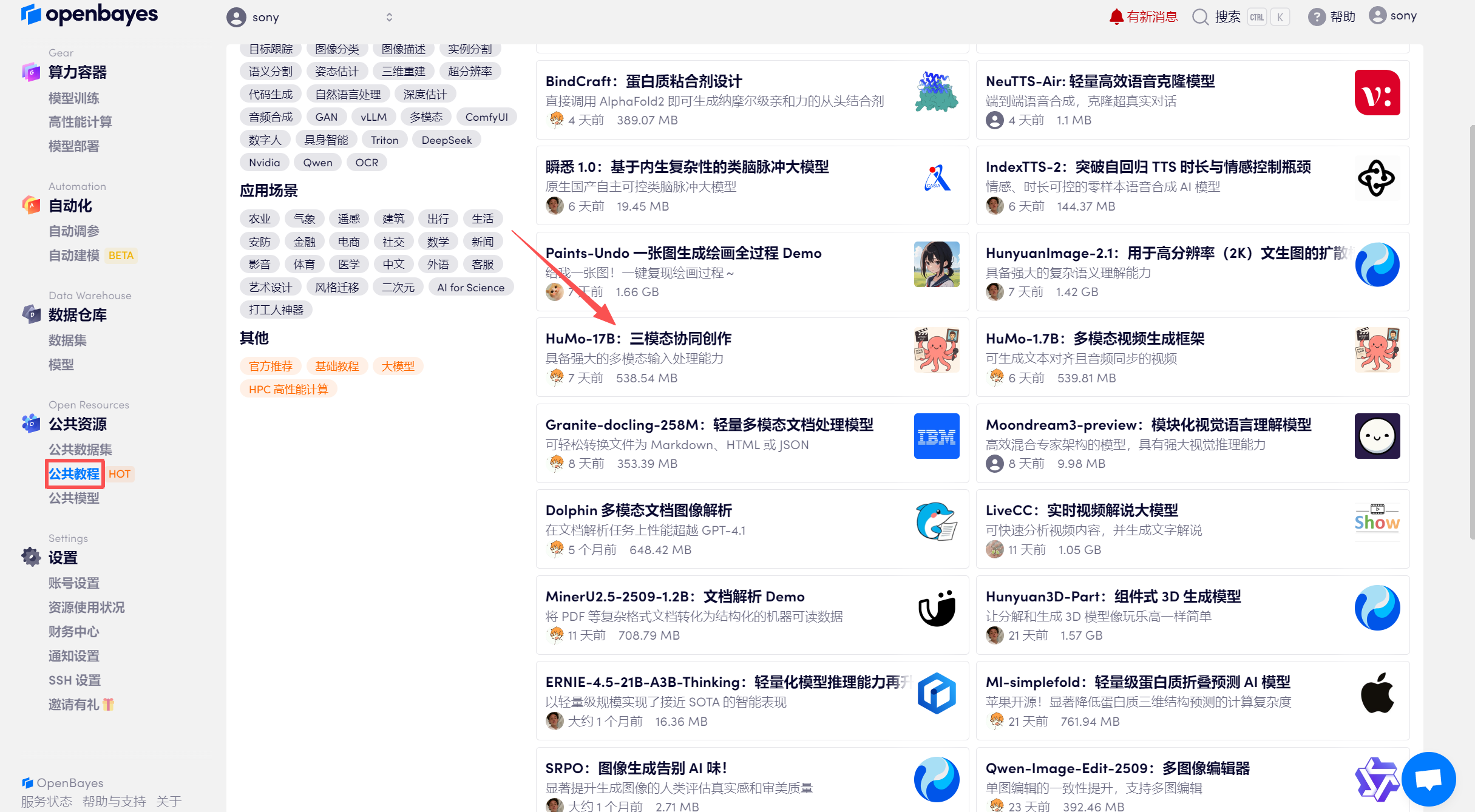
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
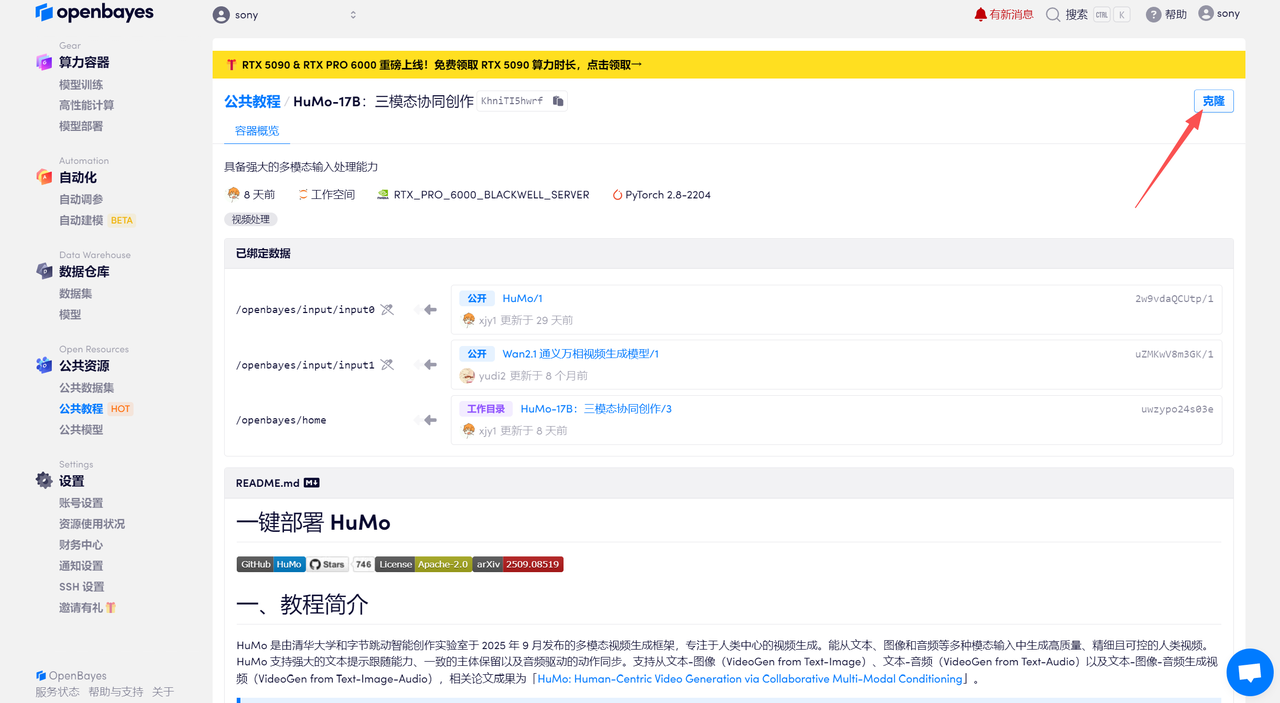
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
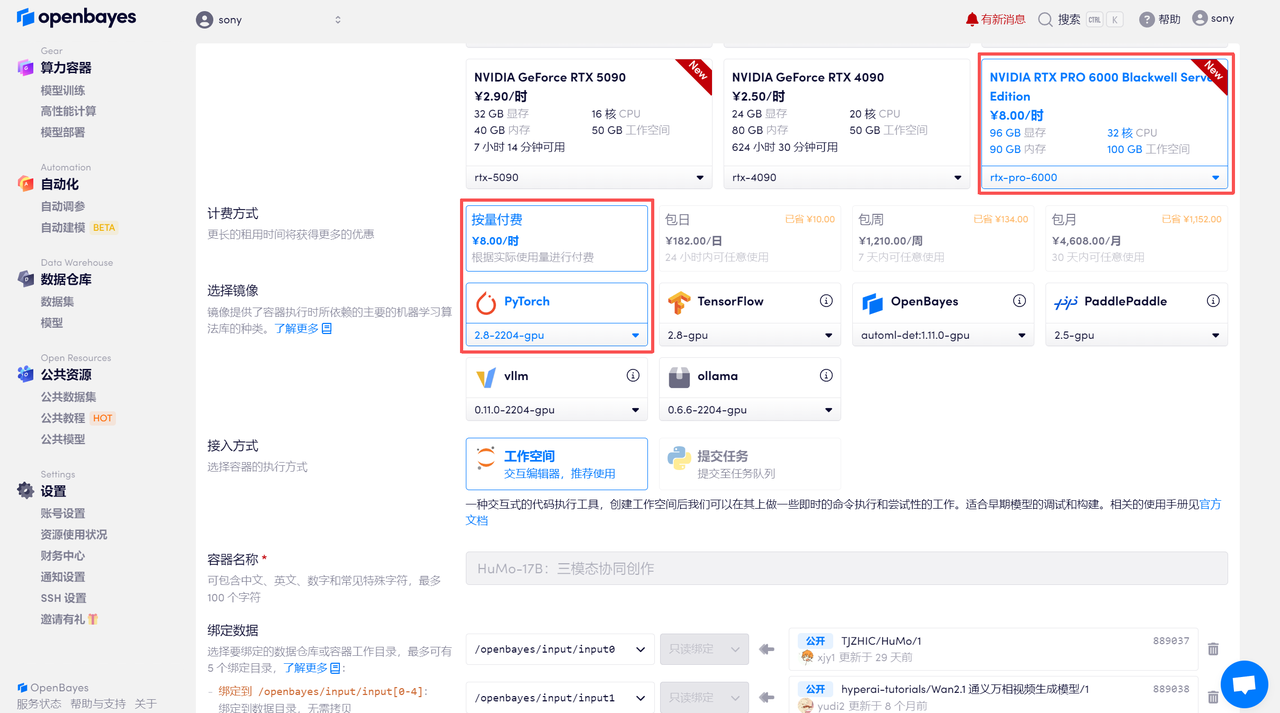
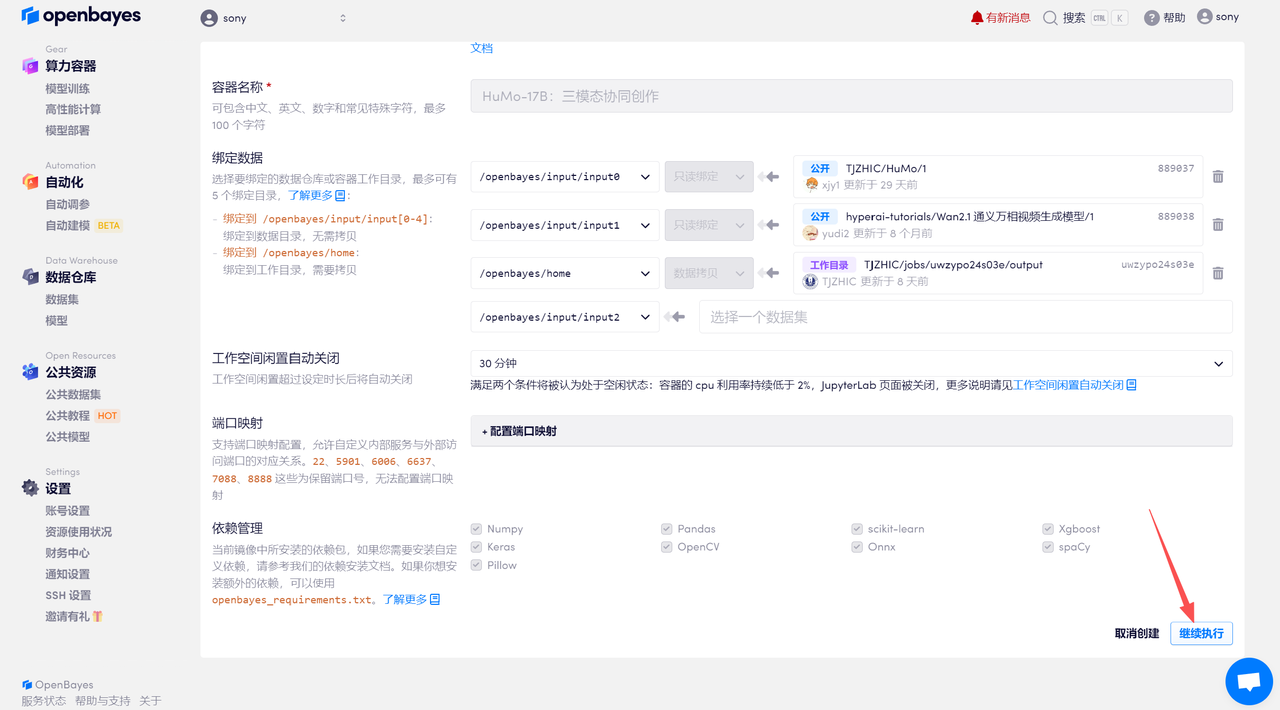
待系统分配好资源,当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。
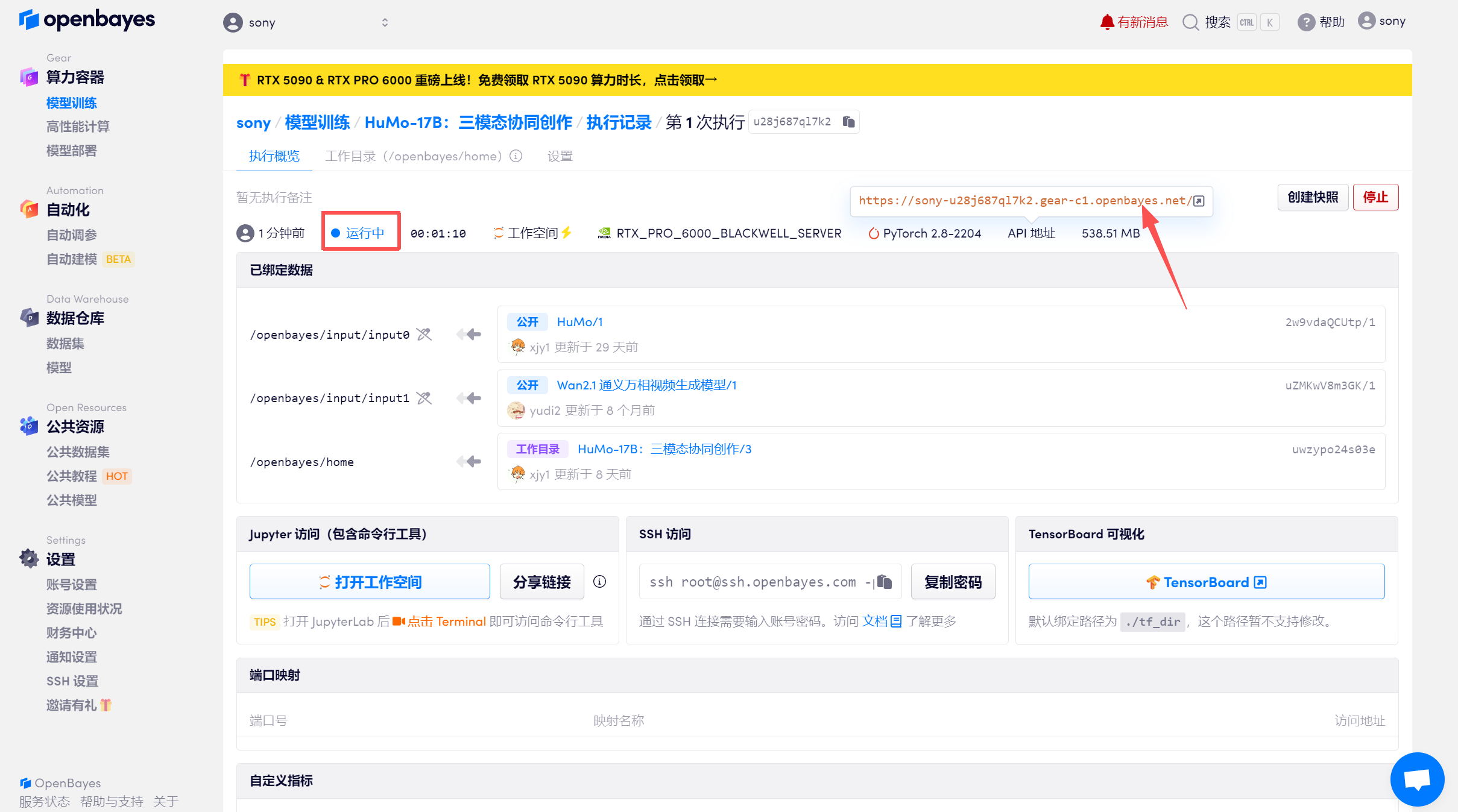
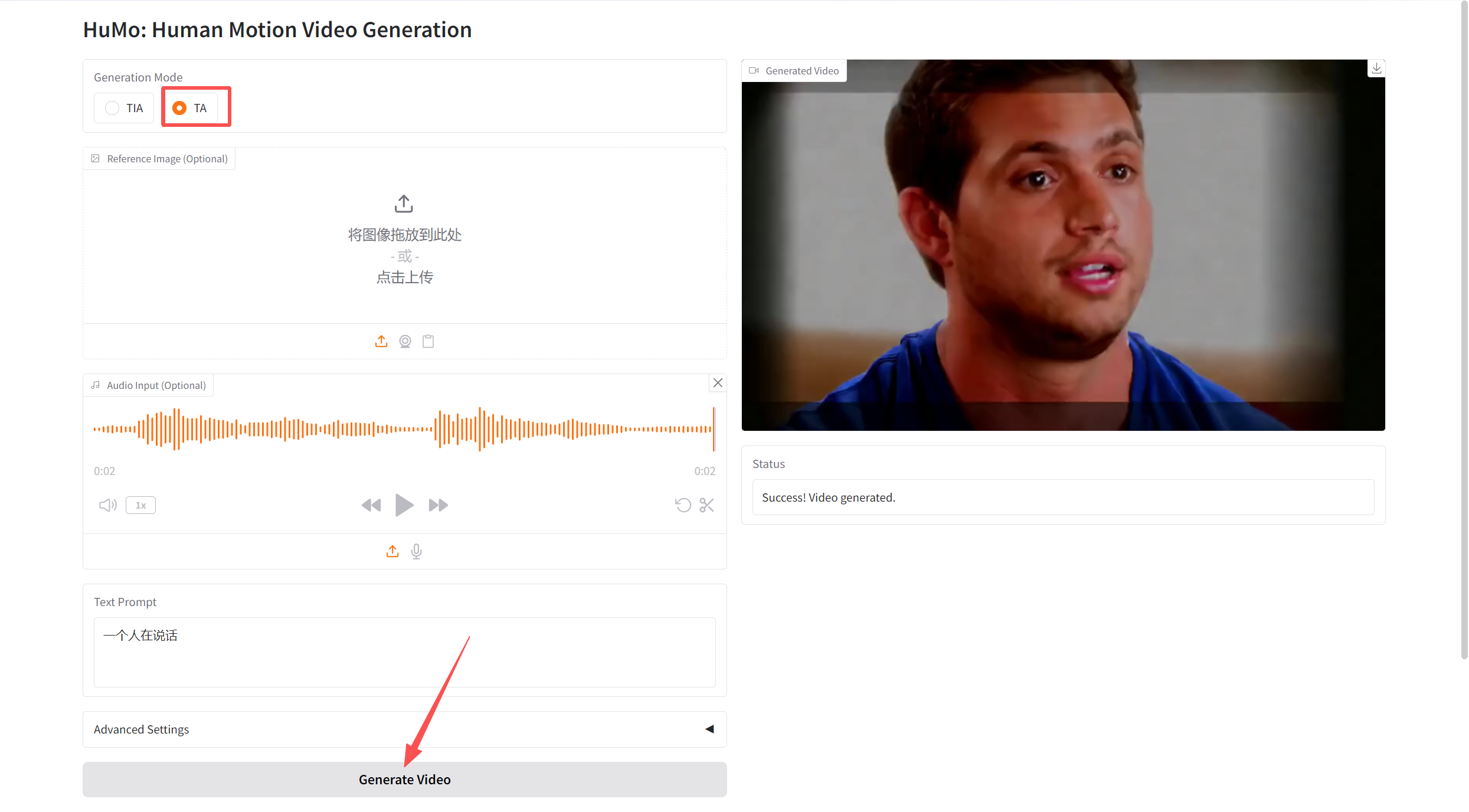
文本-图像-音频生成视频(VideoGen from Text-Image-Audio,TIA)
进入 Demo 页面后,在「Generation Mode」中选择「TIA」,然后上传图像,音频并输入文本,点击「Generate Video」生成。
参数说明
-
Height:设置视频的高度。
-
Width:设置视频的宽度。
-
Frames:设置视频的帧数。
-
Text Guidance Scale:文本引导缩放比例,用于控制文本提示对视频生成的影响。
-
Image Guidance Scale:图像引导缩放比例,用于控制图像提示对视频生成的影响。
-
Audio Guidance Scale:音频引导缩放比例,用于控制音频提示对视频生成的影响。
-
Sampling Steps:采样步数,用于控制视频生成的质量和细节。
-
Random Seed:随机种子,用于控制视频生成的随机性。
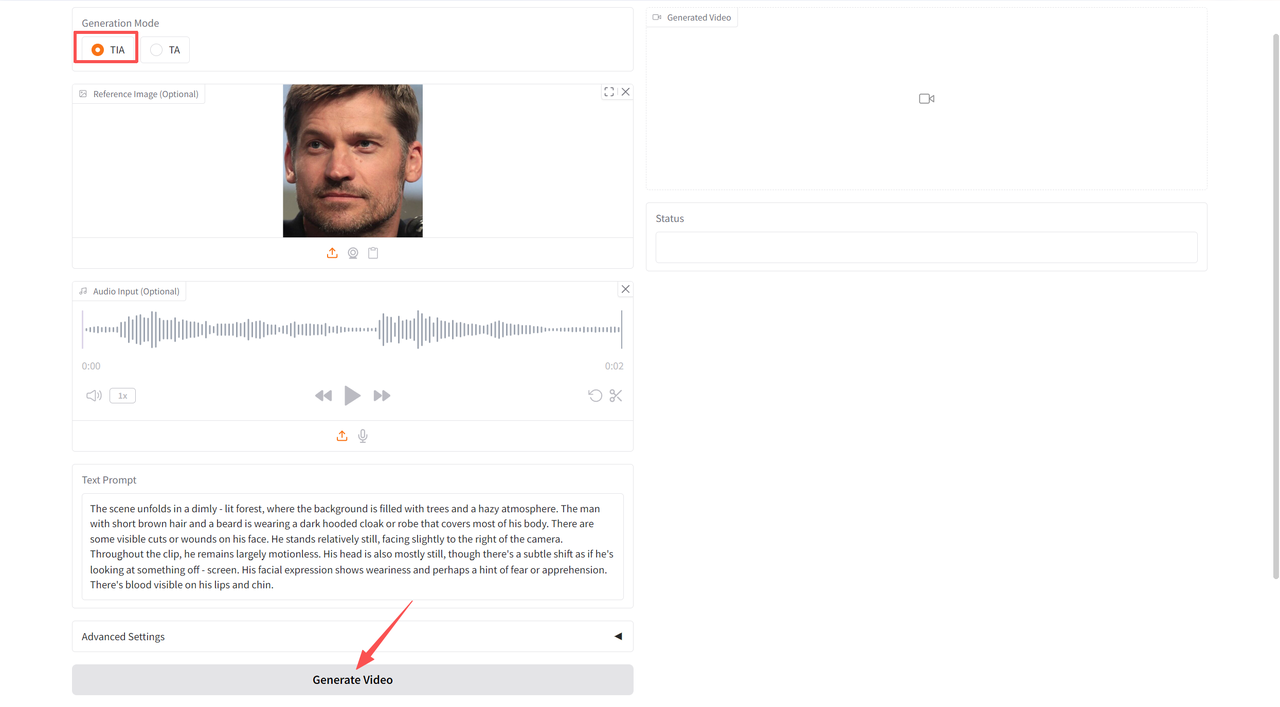
文本-音频生成视频(VideoGen from Text-Audio,TA)
在「Generation Mode」中选择「TIA」,然后上传音频并输入文本,点击「Generate Video」生成。