标题:VIDM: Video Implicit Diffusion Models
作者:Kangfu Mei, Vishal M. Patel
单位:Johns Hopkins University
发表:2023 年,AAAI(AAAI Conference on Artificial Intelligence)
论文链接 :https://arxiv.org/pdf/2212.00235
代码链接 :https://github.com/MKFMIKU/VIDM
项目链接 :https://kfmei.page/vidm/
关键词:视频生成、扩散模型(Diffusion Models)、隐式条件建模(Implicit Condition Modeling)、位置组归一化(Positional Group Normalization)、采样空间截断(Sampling Space Truncation)、鲁棒性惩罚(Robustness Penalty)、Fréchet 视频距离(FVD)
一、研究背景与动机
视频生成的核心挑战在于同时建模空间维度的帧质量 与时间维度的运动连续性。在 VIDM 提出之前,主流视频生成方法主要分为两类,但均存在明显局限:
1. 传统生成模型的局限
- GAN-based 方法:如 MoCoGAN-HD、StyleGAN-V 等,虽能生成一定质量的视频,但存在训练不稳定、模式崩溃(Mode Collapse)问题,且难以精准建模视频的时空动态变化,生成的长视频易出现帧间不连续。
- 其他生成范式: autoregressive 模型(如 VideoGPT)依赖帧间逐次生成,计算成本高;时间序列模型(如 TATS)则在高分辨率视频生成任务中表现力不足。
2. 扩散模型的机遇与挑战
扩散模型(如 DDPM)通过 "加噪 - 去噪" 的迭代过程,在图像生成领域实现了超越 GAN 的质量与多样性,但直接迁移到视频生成面临两大核心问题:
- 时空建模难题:视频是 3D 时空数据(帧宽 × 帧高 × 时间步),传统 2D 扩散模型无法捕捉帧间运动关联,易生成 "静态图像序列" 而非连贯视频。
- 条件机制设计:扩散模型的性能高度依赖条件信息的利用,如何设计适配视频运动的条件机制,是实现高质量视频生成的关键。
基于此,VIDM 提出了 "分离建模内容与运动" 的思路,通过隐式条件机制将运动信息融入扩散过程,同时引入多项优化策略解决上述难题,显著提升了生成视频的质量与连续性。
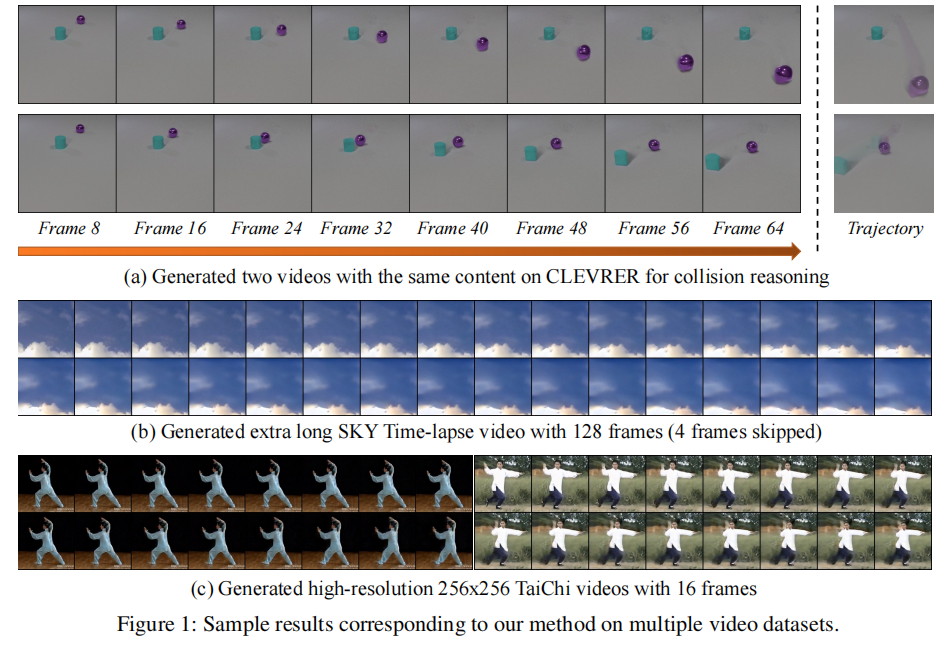
二、核心方法:VIDM 的技术框架
VIDM 的整体架构分为内容生成器(Content Generator) 与运动生成器(Motion Generator) 两部分,前者负责生成高质量初始帧,后者负责基于初始帧与隐式运动条件生成后续帧,最终通过自回归方式构建完整视频。整体框架如图2所示:
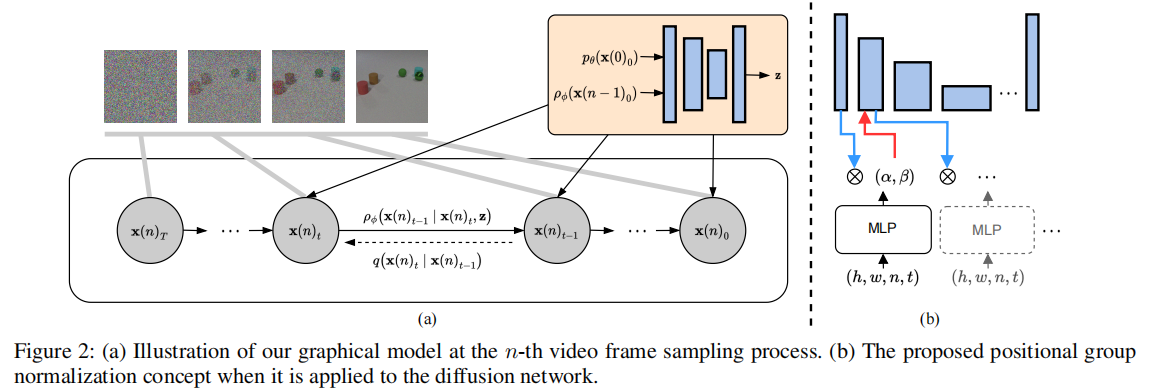
图 2:(a)第 n 帧采样过程的图形模型;(b)位置组归一化(PosGN)在扩散网络中的应用示意图
2.1 基础扩散模型:DDPM 的扩展
VIDM 基于去噪扩散概率模型(DDPM)构建,其核心是通过迭代去噪过程,将高斯噪声逐步映射为真实视频数据。DDPM 的核心公式如下:
- 加噪过程 :将干净帧
逐步添加噪声,得到t时刻的含噪帧
- 去噪过程 :通过网络
VIDM 在 DDPM 基础上,针对视频生成场景进行了三项关键改进,解决了扩散模型在视频任务中的固有缺陷。
2.2 内容生成器:高质量初始帧的保障
内容生成器的目标是生成清晰、真实的第一帧(),为后续运动生成提供高质量基础。为提升生成质量,VIDM 引入两项优化策略:
(1)采样空间截断(Sampling Space Truncation)
扩散模型虽生成多样性高,但易出现物体质量差的问题。VIDM 借鉴 StyleGAN 的截断技巧,在每个扩散步骤中,将含噪帧与一个可学习常数c (维度与
一致)拼接,隐式限制噪声的采样空间。
- 改进后的去噪网络输入变为
- 优势:无需修改网络结构,即可提升帧的细节质量,避免生成模糊或畸形的物体。
(2)鲁棒性惩罚(Robustness Penalty)
传统 DDPM 使用 Dropout 抑制过拟合,但 Dropout 的效果依赖数据集,且易损害模型通用性。VIDM 用Charbonnier 惩罚项 替代 Dropout,修改损失函数为:其中
(实验验证该值最优)。
- 优势:保持损失函数可微性的同时,自适应抑制过拟合,提升内容生成的鲁棒性。
2.3 运动生成器:连贯视频的核心
运动生成器通过自回归方式生成后续帧(),核心是隐式建模帧间运动信息,确保视频的时空连续性。VIDM 为此设计了三项关键技术:
(1)位置组归一化(Positional Group Normalization, PosGN)
传统归一化方法(如 GroupNorm)忽略了视频的时空位置信息,导致模型无法捕捉帧间运动关联。PosGN 将 4D 时空坐标(h:高度,w:宽度,n:帧索引,t:扩散时间步)编码为调制参数,融入特征归一化过程:
- 通过 MLP(带正弦激活函数)将 4D 坐标映射为仿射参数
- 用
- 优势:借鉴隐式神经表示(INR)的坐标编码思想,让模型感知时空位置,为运动连续性建模提供基础。其计算成本与普通 AdaGN 接近,不增加过多负担。
(2)隐式运动条件(Implicit Motion Condition)
为精准捕捉帧间运动,VIDM 引入光流类隐式特征作为条件。具体步骤如下:
- 使用预训练的光流估计网络(SpyNet),计算初始帧
- 将z作为运动生成器的条件,输入去噪网络
- 优势:无需显式预测光流,通过隐式特征z编码运动信息,避免光流估计误差对生成结果的影响,同时确保帧间运动的连贯性。
(3)自适应特征残差(Adaptive Feature Residual)
为简化运动建模难度,VIDM 引入一个额外编码器,基于初始帧
与扩散时间步t生成内容特征残差r 。运动生成器不再直接生成完整帧,而是学习生成 "残差 + 基础内容",即:
- 优势:将复杂的帧生成任务拆解为 "基础内容 + 运动残差",降低模型学习难度,提升运动建模的精准度。
2.4 VIDM 的完整流程
VIDM 的视频生成过程分为训练 与推理两个阶段,核心流程由算法 1(运动学习)与算法 2(视频生成)定义:
算法 1:运动生成器训练流程

- 输入随机帧
- 随机采样扩散时间步
- 用 SpyNet 计算隐式运动特征
- 生成含噪帧
- 最小化损失
算法 2:视频生成推理流程

- 对每个帧索引
- 若
- 若
- 计算隐式运动特征
- 从噪声
- 计算隐式运动特征
- 若
- 拼接所有
三、实验验证:性能与消融分析
为验证 VIDM 的有效性,论文在 4 个主流视频数据集上进行了实验,对比当前 SOTA 方法,并通过消融实验分析核心组件的作用。
3.1 实验设置
- 数据集:涵盖不同分辨率与运动类型的视频,包括:
- UCF-101(101 类人类动作,256×256 分辨率);
- TaiChi-HD(太极拳动作,128×128 分辨率);
- Sky Time-lapse(天空延时视频,256×256 分辨率);
- CLEVRER(合成物体交互视频,256×256 分辨率)。
- 评价指标:
- FVD(Fréchet Video Distance):衡量生成视频与真实视频的分布差异,值越小越好(核心指标);
- FID(Fréchet Inception Distance):衡量帧的空间质量,值越小越好;
- IS(Inception Score):衡量生成帧的多样性与真实性,值越大越好。
- 基线方法:包括 GAN-based 方法(MoCoGAN-HD、StyleGAN-V、DIGAN)、扩散模型(VDM)、Transformer 方法(TATS)等 12 种当前 SOTA。
3.2 主实验结果:超越 SOTA
(1)定量结果
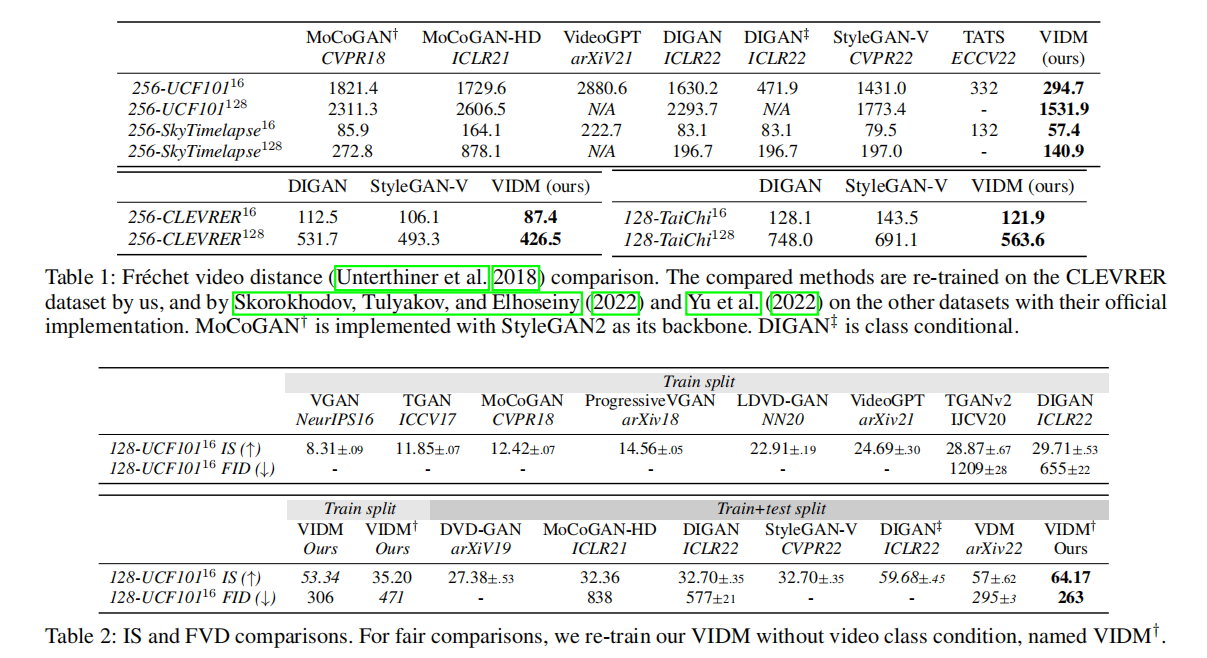
论文通过表 1 与表 2 展示了 VIDM 与基线方法的 FVD、IS、FID 对比,核心结论如下:
- 在所有数据集上,VIDM 的 FVD 值均显著低于基线方法。例如:
- 256×256 UCF-101(16 帧):VIDM 的 FVD 为 294.7,远低于 DIGAN 的 471.9 与 StyleGAN-V 的 1431.0;
- 256×256 Sky Time-lapse(16 帧):VIDM 的 FVD 为 57.4,优于 DIGAN 的 83.1 与 StyleGAN-V 的 79.5;
- 长视频任务(128 帧)中,VIDM 优势更明显。例如 256×256 CLEVRER(128 帧):VIDM 的 FVD 为 426.5,低于 DIGAN 的 531.7 与 StyleGAN-V 的 493.3。
- 空间质量指标(FID/IS)上,VIDM 同样表现优异。例如 128×128 UCF-101(16 帧):VIDM 的 IS 为 64.17,高于 DIGAN 的 59.68 与 VDM 的 57.0。
(2)定性结果
图 3 展示了 VIDM 与基线方法在 3 个数据集上的视觉对比,可见 VIDM 生成的视频:
- 帧内细节更清晰(如 UCF-101 中的人物动作、Sky Time-lapse 中的云层纹理);
- 帧间运动更连贯(如 TaiChi-HD 中的太极拳连贯动作),无明显跳变或静态帧问题。

图 3:VIDM 与基线方法在 256-UCF101、128-TaiChi、256-Sky Time-lapse 数据集上的定性对比(每 2 帧展示 1 帧)
3.3 消融实验:核心组件的必要性
为验证内容生成器的 "采样空间截断""鲁棒性惩罚" 与运动生成器的 "PosGN""隐式运动条件" 的作用,论文设计了消融实验,结果如表 3 所示。
(1)内容生成器消融(表 3a)
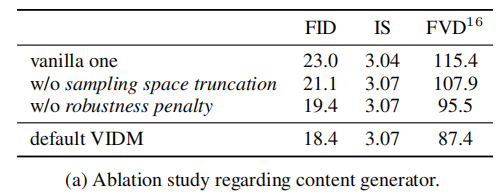
- 结论:移除 "采样空间截断" 或 "鲁棒性惩罚" 会导致 FID 升高、FVD 升高,证明两项优化均能提升内容生成质量,且共同作用时效果最优。
(2)运动生成器消融(表 3b)
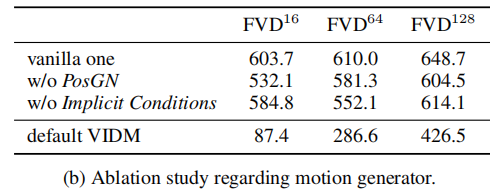
- 结论:
- 移除 PosGN 或隐式运动条件,FVD 显著升高,尤其在长视频(64 帧、128 帧)中,证明两项组件对运动连续性至关重要;
- 仅用 PosGN(无隐式条件):虽能生成不同帧,但运动不连贯;仅用隐式条件(无 PosGN):无法捕捉时空位置信息,生成静态帧序列;
- 图 4 展示了不同消融设置的 latent 特征与对应视频,直观证明完整 VIDM 的 latent 更稳定,生成视频更连贯。

图 4:不同消融设置下的 latent 特征可视化与对应生成视频帧对比
四、创新点与局限性
4.1 核心创新点
- 分离式内容 - 运动建模:首次在扩散模型中通过两个生成器分别建模内容与运动,简化视频生成的复杂度,同时提升帧质量与运动连续性。
- 隐式运动条件机制:基于光流类隐式特征而非显式光流,避免光流估计误差,精准编码帧间运动信息,为扩散模型提供有效的运动指导。
- PosGN 与优化策略:位置组归一化(PosGN)将时空坐标融入特征调制,结合采样空间截断、鲁棒性惩罚,解决了扩散模型在视频生成中的质量与过拟合问题。
4.2 局限性
- 计算效率低:扩散模型的迭代去噪过程(通常 T=1000 步)导致视频生成速度慢,尤其在高分辨率、长视频任务中,难以满足实时需求。
- 伦理风险:高质量视频生成能力可能被用于制作 Deepfake,带来虚假信息传播等社会问题(论文提及需配合 Deepfake 检测技术应对)。
五、总结与展望
VIDM 作为扩散模型在视频生成领域的重要探索,通过 "分离建模 + 隐式条件" 的思路,突破了传统方法在时空连续性建模上的瓶颈,为视频生成提供了新的技术范式。其核心贡献不仅在于提出了具体的模型架构,更在于验证了 "扩散模型 + 隐式条件" 在视频生成中的有效性,为后续研究提供了以下方向:
- 效率优化:通过减少扩散步数(如快速扩散)、模型压缩等方式,提升 VIDM 的生成速度;
- 多模态条件扩展:将文本、音频等模态作为条件,实现 "文本 - 视频""音频 - 视频" 的跨模态生成;
- 更高分辨率与更长视频:进一步提升模型对超高清(4K/8K)、超长(1000 + 帧)视频的生成能力。
总体而言,VIDM 的工作为视频生成技术开辟了新的道路,其设计思想对扩散模型在其他时空数据(如 3D 点云、医学影像序列)上的应用也具有重要的借鉴意义。