
🎬 胖咕噜的稞达鸭 :个人主页
🔥 个人专栏 : 《数据结构》《C++初阶高阶》《算法入门》
⛺️技术的杠杆,撬动整个世界!

容器适配器:
适配器是一种设计模式,这种模式是将一个类的接口转换成我们希望的另外一种接口,形象理解为电源插座和交流电的插头,电源接到交流电的插头,通过电线电流进行传输,才可以给手机电脑充电。
**那么在栈和队列的实现中我们该怎么样用到容量适配器来更好的实现?**栈和队列要实现一端插入和删除,我们前面学过的vector,string,这些都可以支持适配器
- 这里我们使用一个容器适配器来实现一个栈,container适配来转换出stack,实现最基本的栈的构造。
cpp
namespace Keda
{
template <class T,class Container>//T代表栈中元素的类型,Container代表底层容器的类型
class stack
{
public:
void push_back(const T& x)//插入一个不可修改的T类型的数据
{
_con.push_back(x);//调用Container底层容器的push_back方法将其插入
}
void pop()
{
_con.pop_back();//用于弹出元素
}
const T& top() const
{
return _con.back();
}
size_t size()const
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}2.这里我们使用一个容器适配器来实现一个队列,container适配来转换出Queue,实现最基本的队列的构造:
cpp
#pragma once
#include<list>
namespace Keda
{
//Container适配转换出stack
template<class T, class Container=list<T>>
class queue
{
public:
void push(const T& x)//定义成员函数,便于向队列中存数据
{
_con.push_back(x);//调用底层容器_con的push_back方法将元素x添加到容器末尾
}
void pop()
{
_con.pop_back();
}
const T& front()const//用于获取队头的引用,函数返回值是常量引用防止外部通过该引用修改队列内的元素
{
return _con.front();//返回容器头部元素的引用
}
const T& back()const//用于获取对尾的引用,函数返回值是常量引用防止外部通过该引用修改队内的元素
{
return _con.back();
}
size_t size()const
{
return _con.size();//用于获取队列的元素个数
}
bool empty()const
{
return _con.empty();//判断队列中是不是空
}
private:
Container _con;//定义了一个私有成员变量,_con,类型是Container,作为实现队列的底层容器
};
}测试:
cpp
#include<iostream>
#include<vector>
#include<list>
using namespace std;
#include"queue.h"
#include"stack.h"
int main()
{
Keda::stack<int, vector<int>>st;
st.push_back(1);
st.push_back(2);
st.push_back(3);
st.push_back(4);
cout << st.top() << endl;
st.pop();
Keda::queue<int, list<int>>q;
q.push(1);
q.push(1);
q.push(1);
q.push(1);
cout << q.front() << endl;
q.pop();
return 0;
}所以可以看出vector和list的区别。
vector和list的区别:!!!面试题
- vector的优点:
1.尾插未删效率不错,支持高效的下标随机访问;
2.物理空间连续,高速缓存利用率高
- vector的缺点:
1.空间不够需要扩容,扩容有一些代价(效率和空间浪费)
2.头部和中间的插入删除效率低
- list的优点
1.按需申请释放空间,不需要扩容
2.支持任意位置的插入删除
- list的缺点:
1.不支持下标的随机访问
这里我们引出缝合怪:deque,是指vector和list的缝合。
- 问题一:那么deque是怎样实现这个缝合的呢?
首先肯定是要结合vector和list的优缺点,vector数组物理空间连续,但是空间不够需要扩容,list物理空间不连续,但是不需要扩容,可以从这个地方寻找突破口。
将每一段数组(buffer)都放置到一个中控数组中,中控数组是一个指针数组,也即是中控数组中最中间分别有一个指针对应每一段数组(buffer),如果我们需要头插,就在第一段数组前面再开一个buffer数组。尾插也是一个道理的,如果需要扩容,那就开一个更大的中控数组,把数据再拷贝下来到这个更大的中控数组中。
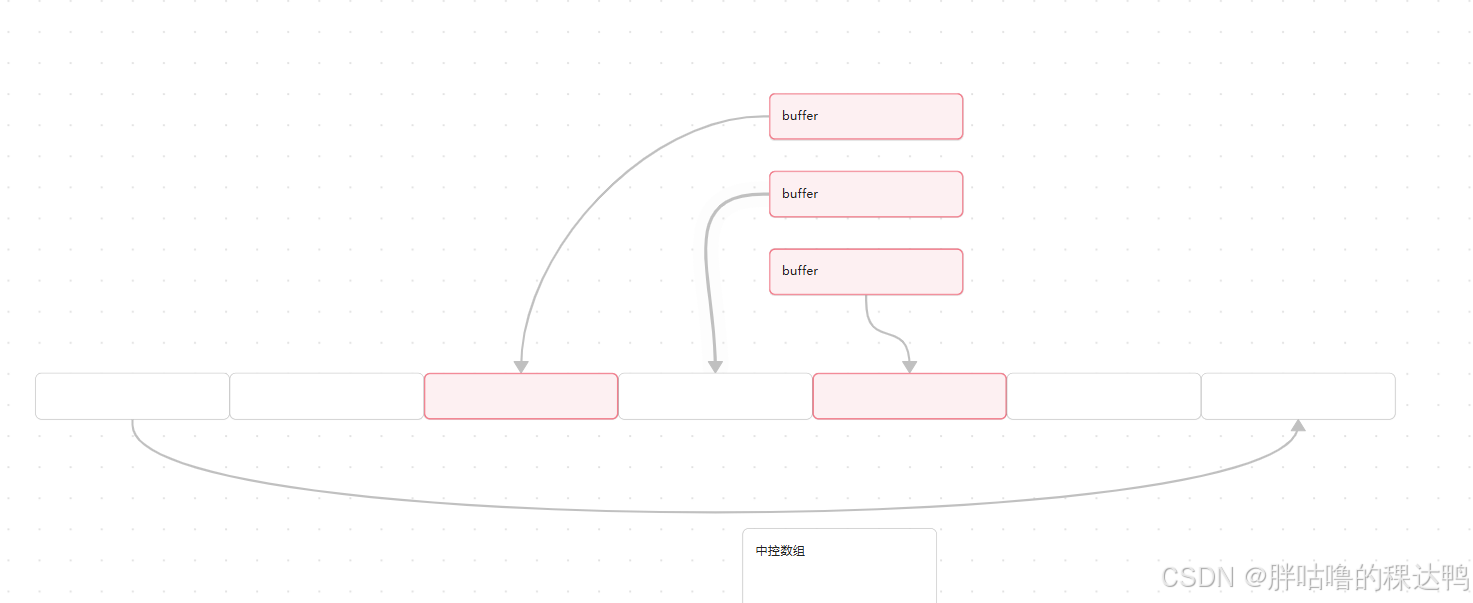
假设每个buffer数组大小是N,如果要获取第i个数据,x=i/N,y=i%N。要找到第i个数据,首先在中控数组中找到这几段数据的起始位置ptr,ptr[x]就默认指向某一段buffer的起始地址,然后具体到ptr[x][y],就可以精准对应出第i个数据。(这个思想类似于C语言中首元素的下标就是首元素的地址)。也相等于*(ptr + x)得到第几个buffer数组,再进行 *(*(ptr+x)+y),就可以精准对应出第i个数据。道理是一样的。
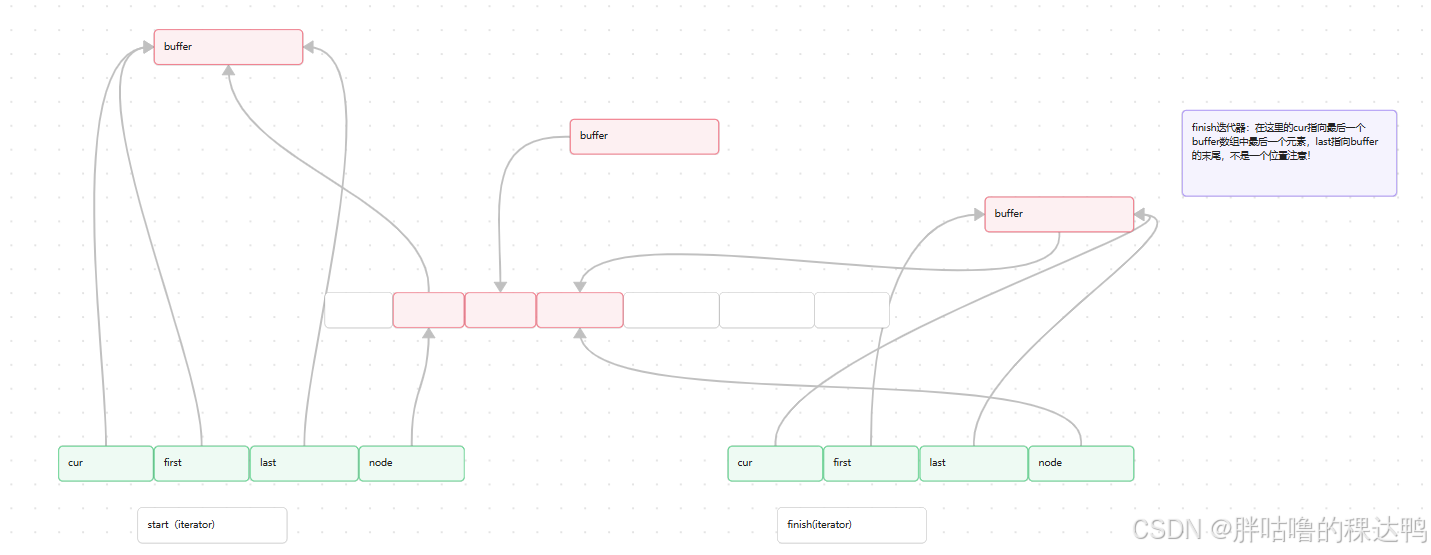
2. 问题2.那么deque是怎么对每一个buffer进行管理的呢?
还是要依靠迭代器,这里我们将进行迭代器的说明,deque的迭代器由四个核心结构组成 cur, first, last, node。
看图理解:
cpp
iterator it=begin();
while(it!=end())
{
cout<<*it<<endl;
++it;
}接着我们来阐述一下迭代器遍历中控数组中buffer的过程:
当it从迭代器begin()位置开始遍历,start()中node 位置指向第一个buffer,然后it指针从buffer位置开始解引用访问,cur从指针从整个buffer的起始位置访问到末尾,cur不停++,cur++这时候it还是没有访问到end()位置,
所以node+1解引用拿到第二个buffer的位置,cur从整个buffer的起始位置一直访问到末尾,再继续判断是否到end()位置,
node+1继续解引用拿到下一个buffer的位置,最后到end()位置就结束循环。所以deque 管理中控数组中的buffer是依靠两个迭代器完成的。
总结:deque
- deque头插尾插效率很高,更甚于vector和list;
- 下标随机访问也还不错,相比vector略胜一筹;
- 中间插入删除效率很低,要挪动数据,时间复杂度是O(N)。
封装就是屏蔽了底层的实现逻辑。
priority_queue
再来实现一个容器适配器:堆的底层是一个数组,这里我们用代码展示一下。
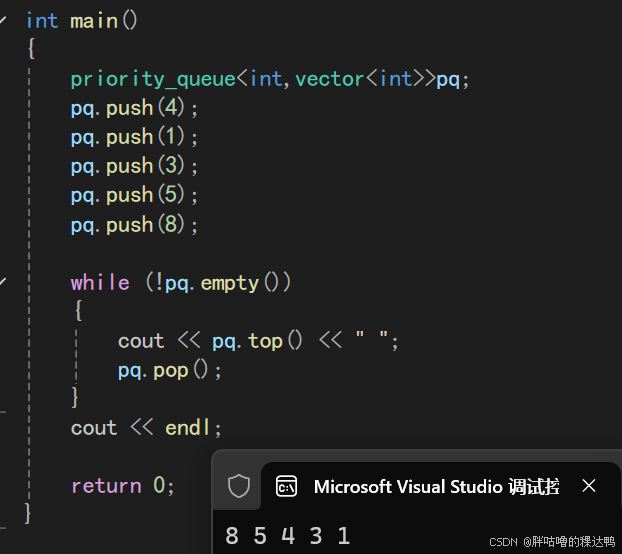
要实现一个大堆:
cpp
int main()
{
priority_queue<int,vector<int>>pq;
pq.push(4);
pq.push(1);
pq.push(3);
pq.push(5);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
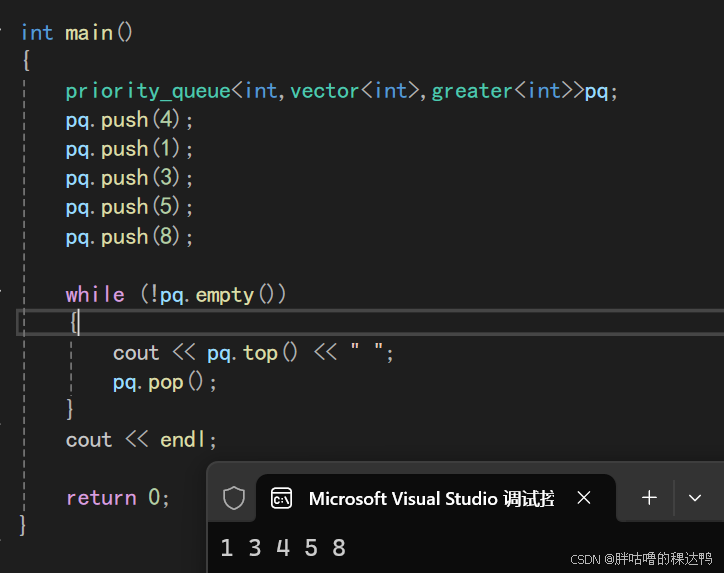
实现一个小堆:
cpp
int main()
{
priority_queue<int,vector<int>,greater<int>>pq;
pq.push(4);
pq.push(1);
pq.push(3);
pq.push(5);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}
接下来我们来实现一个优先级队列:priority_queue,要理解灌插其中的仿函数。
模拟实现priority_queue
优先级队列的底层是堆,将底层的物理结构看作一个完全二叉树
**堆的push操作:**当要插入一个数据,也即是在_con.size()-1的位置插入一个数据,需要沿着这条路径向上调整,先写出大堆,孩子节点大于父亲,就要向上调整。
定义一个parent节点,这个我们在数据结构与算法中学过,带大家回顾一下,child作为子节点,parent作为父节点,当父节点所在的数字小于子节点,就让parent和child 所在的位置交换一下数据,然后parent又作为下一个子节点不停向上调整,直到child<0结束循环。
代码实现:
cpp
void AdjustUp(int child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
Swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size() - 1);
}堆的pop操作 :删除堆的数据,是从最后一个数据开始删除的吗?
不是!是从堆顶的数据开始删除,如果我们直接删除堆顶的数据,那么一切就全部乱套了,堆的结构将不存在,所以我们可以将堆顶的元素跟最后一个子节点进行交换,然后实现不断向下调整的操作,交换_con[0]跟_con[_con.size()-1];这里向下调整AdjustDown,我们已知一个参数为parent,child节点即是parent*2+1;但是有两个孩子对应一个父节点,所以我们假设是左孩子小于右孩子,一旦假设错误,就需要child++,最终目的就是让最大的孩子去跟父节点比较;如果parent<child,就需要向下调整,
代码实现:
cpp
void AdjustDown(int parent)
{
size_t child = parent * 2 + 1;
while (child<_con.size())
{
if (child + 1 < _con.size() && _con[child + 1] > _con[child])
{
++child;
}
if ( _con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}priority_queue模拟实现原码:
cpp
#pragma once
namespace Keda
{
template<class T,class Container=vector<T>>
class priority_queue
{
public:
void AdjustUp(int child)
{
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
Swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size() - 1);
}
void AdjustDown(int parent)
{
size_t child = parent * 2 + 1;
while (child<_con.size())
{
if (child + 1 < _con.size() && _con[child + 1] > _con[child])
{
++child;
}
if ( _con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
const T& top()
{
return _con[0];
}
size_t size()const
{
return _con.size();
}
bool empty()const
{
return _con.empty();
}
private:
Container _con;
};
}仿函数:
重载参数调用的参数列表的括号,可以先用仿函数来实现数字的比大小的操作。
cpp
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
int main()
{
Less<int> LessFunc;
//函数对象
cout << LessFunc(1, 2) << endl;
//相当于
cout << LessFunc.operator()(1, 2) << endl;
}所以说仿函数有什么用呢?
这里我们可以实现一个排序的操作,调用Bubblesort冒泡排序进行分析,如果前一个数字大于后一个数字a[j-1]>a[j],再执行交换两个数字的位置,继续一前一后进行对比,把大的放在后面,这样排序出升序,那么要是想排出降序呢,将a[j-1]<a[j];再进行交换,这样可以,但是我们可以用仿函数实现更便捷的操作;
仿函数的本质是一个类,这个类重载了operator(),它的对象可以像仿函数一样使用;
创建两个类模板,一个Less模板用来实现找到两个数字中最小的值,一个Greater模板用来找两个数字中最大的值,最后各自返回x和y的比较大小。
这里我们就可以对冒泡排序进行改造,template<class Compare> 定义了一个模板,Compare是模板参数,用于接受"比较规则"
在main函数中Less<int> LessFunc; Greater<int>GreaterFunc;定义两个函数对象LessFunc和GreaterFunc,并且实例化处理为int类型的对象,然后在main函数中Bubblesort第一个参数传数组名,第二个参数传具体的数组的大小,第三个参数调用我们写好的仿函数,
想要冒泡排序实现升序,Bubblesort(a, 6, GreaterFunc);实现降序,Bubblesort(a, 6, LessFunc)。
在冒泡排序内部:定义模板来实现升序降序的快速切换,在进行前后元素进行比较的时候,我们不再用传统的如果要实现降序,if(aj-1<aj),前后交换,实现升序,if(aj-1>aj),前后交换;直接if(com(a[j],com[j-1]),想要实现升序,直接在main函数中进行调用Greater,实现降序,调用Less。这也就是我们为什么要进行模板的引用的目的!
cpp
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template<class Compare>
void Bubblesort(int* a, int n,Compare com)//Compare com 用于比较元素的函数对象(或者是可调用的对象)
{
for (int i = 0; i < n; i++)
{
int flag = 0;
for (int j = 1; j < n - i; j++)
{
if (com(a[j],a[j-1]))//注意:这一步就是优化的点睛之笔!!!
{
swap(a[j - 1], a[j]);//升序
flag = 1;
}
if (flag == 0)
{
break;
}
}
}
}
int main()
{
Less<int> LessFunc;
Greater<int>GreaterFunc;
//函数对象
cout << LessFunc(1, 2) << endl;
//相当于
cout << LessFunc.operator()(1, 2) << endl;
int a[] = { 9,3,8,5,4,8 };
Bubblesort(a, 6, LessFunc);//有名对象
Bubblesort(a, 6, GreaterFunc);
Bubblesort(a, 6, Less<int>());//匿名对象
Bubblesort(a, 6, Greater<int>());
}由此,我们也可以实现一个优先级队列priority_queue的插入与删除,在向上调整AdjustUp和向下调整AdjustDown的实现中我们就完全可以实现大堆和小堆的切换,要实现小堆,不用再AdjustUp和AdjustDown内部进行大于小于号的改变,直接在main主函数中进行说明:
Keda::priority_queue<int,vector<int>,Less<int>> pq;最终实现降序,用来实现大堆;
Keda::priority_queue<int,vector<int>,Greater<int>> pq;最终实现升序,用来实现小堆。
完整源码:
cpp
#pragma once
template<class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
namespace Keda
{
template<class T,class Container=vector<T>,class Compare=Less<T>>
class priority_queue
{
public:
void AdjustUp(int child)
{
Compare com;
int parent = (child - 1) / 2;
while (child > 0)
{
//if (_con[child] > _con[parent])//大堆孩子大于父亲要向上调
if(com (_con[parent],_con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size() - 1);
}
void AdjustDown(int parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child<_con.size())
{
//if (child + 1 < _con.size() && _con[child + 1] > _con[child])
if(child+1<_con.size()&& com(_con[child],_con[child+1]))
{
++child;
}
//if ( _con[child] > _con[parent])
if(com(_con[parent],_con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
const T& top()
{
return _con[0];
}
size_t size()const
{
return _con.size();
}
bool empty()const
{
return _con.empty();
}
private:
Container _con;
};
}
cpp
int main()
{
Keda::priority_queue<int,vector<int>,Greater<int>> pq;
pq.push(4);
pq.push(1);
pq.push(3);
pq.push(5);
pq.push(8);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
return 0;
}