一、项目背景与目标
(一)背景
Speech Commands 数据集是语音识别领域经典的开源数据集,包含 35 个类别(如数字、指令词等)的短语音片段,适合用于基础语音识别模型的开发与验证。本项目基于该数据集,聚焦数字 0-9 的识别任务,搭建并训练语音识别模型,学习从数据准备到模型部署的完整流程。
(二)目标
- 实现 Speech Commands 数据集的自动下载与预处理,筛选出数字 0-9 的语音数据。
- 构建基于 CNN + LSTM 的混合语音识别模型,完成模型训练与评估。
- 借助 Gradio 搭建简单交互界面,实现语音识别功能的快速演示。
二、环境准备
(一)依赖库安装
torch安装
datasets默认使用torchcodec加载音频,请确保torch和python和torchcodec版本匹配。
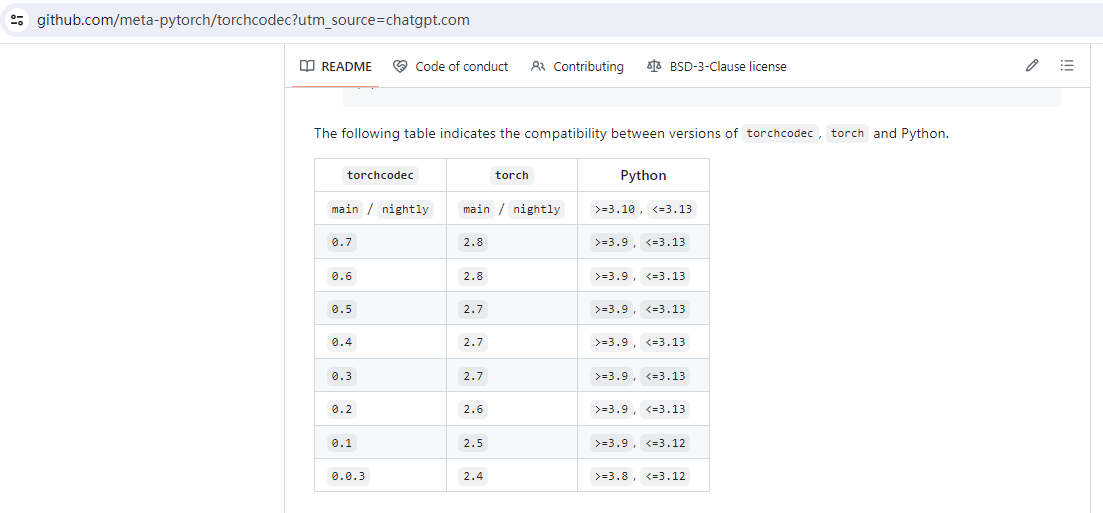
我这里使用kaggle跑,默认kaggle使用torch2.6版本太低导致加载音频各种不兼容,为了兼容升级torch到2.8并且安装torchcodec=0.7
在终端执行以下命令,安装项目所需 Python 依赖库:
bash
#这是cpu的版本
!pip uninstall -y torch torchvision torchaudio torchcodec
!pip install torch==2.8.0 torchvision torchaudio torchcodec==0.7 datasets matplotlib gradio 如果是gpu可以到pytorch官网 首先查看gpu cuda版本:nvidia-smi,然后官网找到版本后的运行命令安装
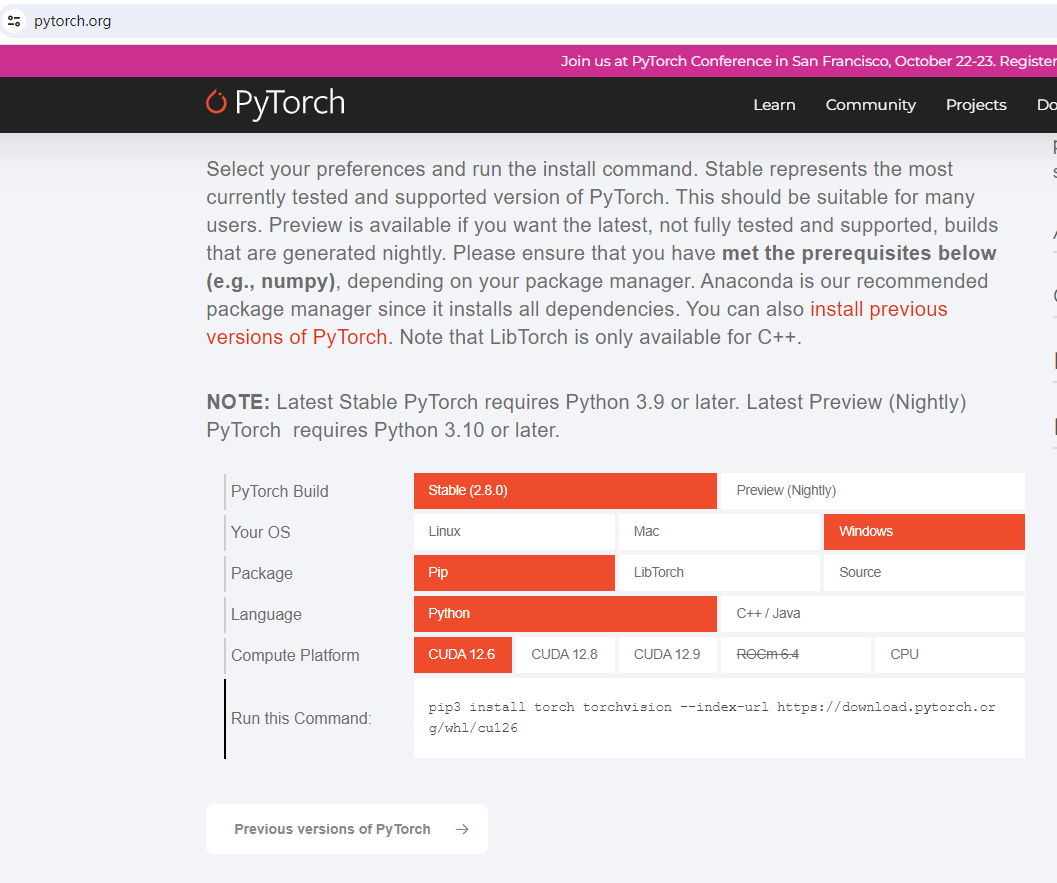
我这里
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126依赖说明:
torch:深度学习框架,用于模型构建与训练。torchaudio:处理音频数据,提供特征提取等功能。datasets:加载与处理 Hugging Face 数据集。matplotlib:可视化数据分布、训练曲线等。gradio:快速构建交互演示界面。
查看torchcodec下加载ffpmeg的so
!ls /usr/local/lib/python3.11/dist-packages/torchcodec
_core libtorchcodec_custom_ops5.so
decoders libtorchcodec_custom_ops6.so
encoders libtorchcodec_custom_ops7.so
_frame.py libtorchcodec_pybind_ops4.so
__init__.py libtorchcodec_pybind_ops5.so
_internally_replaced_utils.py libtorchcodec_pybind_ops6.so
libtorchcodec_core4.so libtorchcodec_pybind_ops7.so
libtorchcodec_core5.so __pycache__
libtorchcodec_core6.so _samplers
libtorchcodec_core7.so samplers
libtorchcodec_custom_ops4.so version.py安装ffmpeg
注意ffmpeg只支持4-7版本
使用conda安装
!curl -Ls https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -xvj bin/micromamba
!./bin/micromamba shell init -s bash --root-prefix ./micromamba
!./bin/micromamba install "ffmpeg<8" -c conda-forge -y
查看版本
! ffmpeg --version使用apt安装
!apt update
!apt install ffmpeg -y
查看版本
! ffmpeg --version诊断环境是否正常
import os
import sys
import platform
import torch
import torch
print(torch.__config__.show())
print("=== PyTorch GPU 支持检查 ===")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
print(f"CUDA 版本: {torch.version.cuda}")
if torch.cuda.is_available():
print(f"GPU 设备数量: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("✗ 没有可用的 CUDA GPU")
def deep_diagnosis():
print("=== 深度诊断 ===")
print(f"Python 版本: {sys.version}")
print(f"平台: {platform.system()} {platform.release()}")
print(f"os 模块文件: {os.__file__}")
# 检查 os 模块的所有属性
print(f"os 模块属性数量: {len(dir(os))}")
# 检查特定于 Windows 的方法是否存在
windows_specific = ['add_dll_directory', 'GetLongPathName', 'GetShortPathName']
for method in windows_specific:
exists = hasattr(os, method)
print(f"os.{method}: {'✓' if exists else '✗'}")
# 检查平台标识
print(f"sys.platform: {sys.platform}")
print(f"os.name: {os.name}")
# 检查模块加载路径
print(f"os 模块来自: {os.__spec__ if hasattr(os, '__spec__') else 'N/A'}")
deep_diagnosis()
import os
import sys
def setup_linux_library_path():
"""设置 Linux 库路径"""
ffmpeg_bin_path = r"/usr/lib/x86_64-linux-gnu"
# 找到 PyTorch 库路径
try:
import torch
pytorch_lib_path = os.path.join(os.path.dirname(torch.__file__), 'lib')
print(f"PyTorch 库路径: {pytorch_lib_path}")
# 添加到 LD_LIBRARY_PATH
current_ld_path = os.environ.get('LD_LIBRARY_PATH', '')
if pytorch_lib_path not in current_ld_path:
os.environ['LD_LIBRARY_PATH'] = pytorch_lib_path + os.pathsep + current_ld_path
print("✓ 已设置 LD_LIBRARY_PATH")
current_ld_path = os.environ.get('LD_LIBRARY_PATH', '')
os.environ['LD_LIBRARY_PATH'] = ffmpeg_bin_path + os.pathsep + current_ld_path
except ImportError:
print("✗ 未找到 PyTorch")
# 应用设置
setup_linux_library_path()
print(os.environ['LD_LIBRARY_PATH'])
# 现在尝试加载你的库
import ctypes
try:
lib = ctypes.CDLL('/usr/local/lib/python3.11/dist-packages/torchcodec/libtorchcodec_core4.so')
print("✓ 库加载成功!")
except Exception as e:
print(f"✗ 库加载失败: {e}")(二)硬件要求
- CPU 环境:普通 4 核及以上 CPU(如 i5 系列)可完成训练,训练 10 轮约 1 - 2 小时;若 CPU 性能较低(如 2 核),时间会相应增加。
- GPU 环境(可选):支持 CUDA 的 NVIDIA GPU(如 GTX 1050 及以上)可加速训练,10 轮训练时间可缩短至 10 - 20 分钟,需额外安装对应 CUDA 版本的 PyTorch。
三、数据集处理
(一)数据集介绍
Speech Commands 数据集包含 train(训练集 )、validation(验证集 )、test(测试集 )三个划分,每个语音片段为 1 秒左右的单词语音,采样率 16000Hz,涵盖 35 个类别,本项目聚焦其中数字 0-9 的识别。
(二)数据集下载与加载
1. 数据集下载函数
python
import os
import tarfile
import urllib.request
from datasets import load_dataset
# Speech Commands 官方下载 URL 模板
DL_URL = "https://s3.amazonaws.com/datasets.huggingface.co/SpeechCommands/{version}/{version}_{split}.tar.gz"
# 支持的版本
VERSIONS = ["v0.01", "v0.02"]
def download_and_extract(version="v0.02", data_dir="./speech_commands"):
"""自动下载并解压 Speech Commands 数据集"""
os.makedirs(data_dir, exist_ok=True)
splits = ["train", "validation", "test"]
extracted_dirs = {}
for split in splits:
url = DL_URL.format(version=version, split=split)
filename = os.path.join(data_dir, f"{version}_{split}.tar.gz")
extract_dir = os.path.join(data_dir, f"{version}_{split}")
if not os.path.exists(extract_dir):
print(f"⬇️ Downloading {url} ...")
urllib.request.urlretrieve(url, filename)
print(f"📦 Extracting {filename} ...")
with tarfile.open(filename, "r:gz") as tar:
tar.extractall(extract_dir)
extracted_dirs[split] = extract_dir
return extracted_dirs函数说明:
- 根据
version(默认v0.02)和data_dir(默认./speech_commands),自动下载train、validation、test三个划分的数据集压缩包。 - 检查本地是否已解压,未解压则先下载再用
tarfile解压,返回各划分的解压目录。
2. 数据集加载函数
python
def load_speech_commands(version="v0.02", data_dir="./speech_commands"):
"""返回 HuggingFace DatasetDict(train/validation/test)"""
extracted_dirs = download_and_extract(version, data_dir)
dataset = {
split: load_dataset("audiofolder", data_dir=extracted_dirs[split], split="train")
for split in extracted_dirs
}
return dataset函数说明:利用 datasets 库的 load_dataset,以 audiofolder 方式加载各划分解压目录的音频数据,返回包含 train、validation、test 数据集的字典。
3. 主程序调用与数据集筛选
python
if __name__ == "__main__":
# 加载完整数据集
dataset = load_speech_commands("v0.02")
print("完整训练集信息:", dataset["train"])
print("完整验证集信息:", dataset["validation"])
print("完整测试集信息:", dataset["test"])
# 只筛选数字 0-9 的类别
digits = {"zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"}
digits_train = dataset["train"].filter(lambda x: x["label"] in digits)
digits_validation = dataset["validation"].filter(lambda x: x["label"] in digits)
digits_test = dataset["test"].filter(lambda x: x["label"] in digits)
print("数字训练集信息:", digits_train)
print("数字验证集信息:", digits_validation)
print("数字测试集信息:", digits_test)代码说明:
- 先加载完整数据集,打印各划分基本信息。
- 通过
filter方法,依据label字段筛选出数字 0-9 对应的语音数据,构建数字识别专用数据集。
(三)数据预处理(特征提取)
1. 定义预处理函数
python
import torch
import torchaudio.transforms as T
# 统一采样率
sample_rate = 16000
# 定义梅尔频谱图转换器
mel_transform = T.MelSpectrogram(
sample_rate=sample_rate,
n_fft=1024,
n_mels=64,
hop_length=256
)
def preprocess_function(examples):
"""
预处理函数:将音频转换为梅尔频谱图并标准化
参数:
examples: 数据集样本,包含音频数据等字段
返回:
处理后的梅尔频谱图(mel)和标签(labels)
"""
# 提取音频张量,若数据集音频存储格式不同,需调整获取方式
wavs = [torch.tensor(wav["array"], dtype=torch.float32) for wav in examples["audio"]]
# 统一采样率(若原始采样率不同,需更完善处理,这里假设原始为 16000Hz 简单示例)
resampler = T.Resample(sample_rate, sample_rate)
wavs = [resampler(wav) for wav in wavs]
# 提取梅尔频谱图,增加通道维度
mels = [mel_transform(wav).unsqueeze(0) for wav in wavs]
# 标准化:计算整体均值和标准差
mel_cat = torch.cat(mels)
mel_mean = torch.mean(mel_cat)
mel_std = torch.std(mel_cat)
mels = [(mel - mel_mean) / mel_std for mel in mels]
return {"mel": mels, "labels": examples["label"]}函数说明:
- 从数据集中提取音频张量,统一采样率(实际需根据原始数据调整,这里简化处理 )。
- 利用
MelSpectrogram将音频转换为梅尔频谱图,增加通道维度适配模型输入。 - 对频谱图进行标准化,提升模型训练稳定性。
2. 应用预处理
python
# 对数字数据集应用预处理
digits_train = digits_train.map(
preprocess_function,
batched=True,
batch_size=32,
remove_columns=digits_train.column_names
)
digits_validation = digits_validation.map(
preprocess_function,
batched=True,
batch_size=32,
remove_columns=digits_validation.column_names
)
digits_test = digits_test.map(
preprocess_function,
batched=True,
batch_size=32,
remove_columns=digits_test.column_names
)
# 转换为 PyTorch 张量格式
digits_train.set_format("torch", columns=["mel", "labels"])
digits_validation.set_format("torch", columns=["mel", "labels"])
digits_test.set_format("torch", columns=["mel", "labels"])代码说明:
- 以批次方式(
batch_size=32)对数字数据集各划分应用预处理,移除原始无关字段。 - 将处理后数据集转换为 PyTorch 张量格式,方便后续模型训练。
四、模型构建
(一)模型架构选择(CNN + LSTM 混合模型)
python
import torch.nn as nn
class SpeechRecognitionModel(nn.Module):
def __init__(self, num_classes=10):
"""
初始化模型
参数:
num_classes: 分类数量,数字 0-9 共 10 类
"""
super().__init__()
# 1. 卷积层:提取局部频率特征
self.cnn = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2))
)
# 2. LSTM 层:处理时间序列特征
self.lstm = nn.LSTM(
input_size=64 * 16,
hidden_size=128,
num_layers=2,
batch_first=True
)
# 3. 分类头:输出分类概率
self.fc = nn.Linear(128, num_classes)
def forward(self, x):
"""
前向传播
参数:
x: 输入的梅尔频谱图,形状 [batch, 1, 64, time]
返回:
分类预测结果
"""
# CNN 处理
x = self.cnn(x)
batch_size, channels, freq, time = x.shape
# 调整形状适配 LSTM 输入:[batch, time, channels×freq]
x = x.permute(0, 3, 1, 2).reshape(batch_size, time, channels * freq)
# LSTM 处理
x, _ = self.lstm(x)
# 取最后一个时间步特征
x = x[:, -1, :]
# 分类输出
logits = self.fc(x)
return logits
# 初始化模型,数字识别共 10 类
model = SpeechRecognitionModel(num_classes=10)模型说明:
- CNN 部分:通过两层卷积提取音频频谱的局部特征,池化层压缩维度,减少计算量。
- LSTM 部分:处理 CNN 输出的时间序列特征,捕捉语音的时序依赖关系。
- 分类头:将 LSTM 输出映射到 10 个数字类别的预测概率。
这个语音识别模型使用LSTM是非常关键且合理的设计,主要原因如下:
-
语音数据的时序特性
语音是时间序列数据:音频信号本质上是随时间变化的连续信号
-
前后依赖关系:一个音素的识别依赖于前面的音素和后面的音素
-
上下文信息:数字发音中,各个部分之间存在强关联
五、模型训练与评估
(一)训练参数设置
python
# 训练参数
batch_size = 32
lr = 1e-3 # 学习率
epochs = 10 # 训练轮数
# 数据加载器
train_loader = torch.utils.data.DataLoader(digits_train, batch_size=batch_size, shuffle=True)
validation_loader = torch.utils.data.DataLoader(digits_validation, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(digits_test, batch_size=batch_size)
# 损失函数(交叉熵,适合分类任务)
criterion = nn.CrossEntropyLoss()
# 优化器(Adam,自适应调整学习率)
optimizer = optim.Adam(model.parameters(), lr=lr)
# 设备设置,自动检测 GPU/CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)(二)训练循环
python
import torch.optim as optim
for epoch in range(epochs):
# 训练模式:启用 dropout、批量归一化等训练专属行为
model.train()
train_loss = 0.0
for batch in train_loader:
# 加载数据到设备(GPU/CPU)
mels = batch["mel"].to(device)
labels = batch["labels"].to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(mels)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
train_loss += loss.item() * mels.size(0)
# 计算训练集平均损失
train_loss /= len(train_loader.dataset)
# 验证集评估:切换为评估模式,关闭 dropout 等
model.eval()
validation_loss = 0.0
correct = 0
with torch.no_grad():
for batch in validation_loader:
mels = batch["mel"].to(device)
labels = batch["labels"].to(device)
outputs = model(mels)
loss = criterion(outputs, labels)
validation_loss += loss.item() * mels.size(0)
# 取预测类别
_, preds = torch.max(outputs, 1)
correct += torch.sum(preds == labels.data)
validation_loss /= len(validation_loader.dataset)
validation_acc = correct.double() / len(validation_loader.dataset)
# 打印训练轮次日志
print(f"Epoch {epoch+1}/{epochs}")
print(f"Train Loss: {train_loss:.4f} | Validation Loss: {validation_loss:.4f} | Validation Acc: {validation_acc:.4f}")流程说明:
- 训练阶段:迭代训练集,计算损失、反向传播更新模型参数,累计训练损失。
- 验证阶段:切换模型为评估模式,关闭梯度计算,计算验证集损失与准确率,评估模型泛化能力。
(三)测试集评估
python
# 测试集评估
model.eval()
test_loss = 0.0
correct = 0
with torch.no_grad():
for batch in test_loader:
mels = batch["mel"].to(device)
labels = batch["labels"].to(device)
outputs = model(mels)
loss = criterion(outputs, labels)
test_loss += loss.item() * mels.size(0)
_, preds = torch.max(outputs, 1)
correct += torch.sum(preds == labels.data)
test_loss /= len(test_loader.dataset)
test_acc = correct.double() / len(test_loader.dataset)
print(f"测试集结果:Loss={test_loss:.4f}, Acc={test_acc:.4f}")说明:在测试集上执行与验证集类似的评估流程,得到模型最终的泛化性能指标(损失与准确率 )。
六、模型部署与演示(Gradio 交互界面)
(一)保存模型(可选)
python
# 保存训练好的模型
torch.save(model.state_dict(), "speech_recognition_model.pth")(二)构建交互界面
python
import gradio as gr
# 加载模型(若之前保存过,可直接加载;也可使用训练好的模型实例)
# model.load_state_dict(torch.load("speech_recognition_model.pth", map_location=device))
model.eval()
def recognize_speech(audio):
"""
语音识别函数,对接 Gradio 界面
参数:
audio: Gradio 传入的音频数据,格式为 (采样率, 波形数组)
返回:
识别结果文本
"""
if audio is None:
return "请录制或上传语音"
sr, wav = audio
wav = torch.tensor(wav, dtype=torch.float32)
# 预处理(与训练时一致)
resampler = T.Resample(sr, sample_rate)
wav = resampler(wav)
mel = mel_transform(wav).unsqueeze(0).unsqueeze(0) # 增加批次和通道维度
# 注意:需使用训练时的均值和标准差,这里需提前保存并加载,示例简化处理
mel_mean = torch.mean(torch.cat([batch["mel"] for batch in train_loader]))
mel_std = torch.std(torch.cat([batch["mel"] for batch in train_loader]))
mel七、数据集大小、训练时长、GPU 需求
(一)、数据集大小(以 Speech Commands v0.02 为例)
1. 原始数据规模
-
总样本量 :约 10 万条语音(
v0.02版本含 35 个类别,每个类别约几千条) -
单条语音 :1 秒时长,采样率 16000Hz → 单条音频大小约
16000 * 2 bytes = 32KB(PCM 16 位编码) -
总容量:plaintext
10万条 * 32KB ≈ 3.2GB(未压缩)
实际下载为 tar.gz 压缩包,解压后约 2GB 左右
2. 数字子集(0-9)规模
- 样本量 :每个数字约 4000-5000 条 → 总约 4-5 万条
- 容量 :约
4万 * 32KB ≈ 1.28GB(解压后)
(二)、训练时长估算
训练时长受 模型复杂度 、batch size 、GPU 性能 影响极大,以下分场景对比:
1. 模型复杂度(以你的 CNN+LSTM 为例)
- 参数量 :约 100 万参数(轻量级模型,适合入门)
- 计算量:每轮训练需处理约 5 万条样本(数字子集),属于低计算量任务
2. 不同 GPU 训练时长(数字子集,10 轮)
| GPU 型号 | 典型场景 | 单轮时长 | 10 轮总时长 | 显存需求 |
|---|---|---|---|---|
| 无 GPU(纯 CPU) | 4 核笔记本 CPU | 30-60 分钟 | 5-10 小时 | --- |
| NVIDIA GTX 1060 | 入门游戏显卡 | 3-5 分钟 | 30-50 分钟 | 2-3GB |
| NVIDIA RTX 3060 | 中端显卡 | 1-2 分钟 | 10-20 分钟 | 3-4GB |
| NVIDIA A100 | 数据中心显卡 | 10-20 秒 | 2-3 分钟 | 5-6GB |
关键影响因素
- batch size :越大越快,但受显存限制(你的代码用
batch_size=32,很保守) - 数据增强:若添加音频加噪、变速等,时长会增加 20%-50%
- 模型深度:若换成 Wav2Vec 等大模型,时长会飙升 10 倍以上
(三)、GPU 需求与选型建议
1. 最低需求:无需 GPU
- 纯 CPU 可跑:你的轻量级模型 + 小 batch size(32),4 核 CPU 能跑通(只是慢)
- 适合场景:仅想验证流程、样本量极小(<1 万条)
2. 推荐 GPU:千元级显卡足够
- 性价比之选 :GTX 1060 / RTX 3050(2000 元以内二手卡)
- 显存 6GB,能轻松容纳
batch_size=128(比 32 快 3 倍) - 10 轮训练仅需 30 分钟,适合个人学习
- 显存 6GB,能轻松容纳
3. 企业级需求:按需扩容
- 大模型 / 大数据:A100(40GB 显存)或多卡集群
- 但你的场景不需要:数字识别任务简单,千元卡足够
(四)、完整训练成本总结
| 需求类型 | 硬件建议 | 训练时长(10 轮) | 成本(硬件 / 云 GPU) |
|---|---|---|---|
| 纯体验(能跑通) | 4 核 CPU | 5-10 小时 | 0(已有电脑) |
| 快速验证 | GTX 1060(二手) | 30-50 分钟 | 1500 元(显卡) |
| 极致效率 | RTX 3060 | 10-20 分钟 | 3000 元(显卡)/ 10 元(云 GPU 按次) |