Dataset Protection via Watermarked Canaries in Retrieval-Augmented LLMs
https://arxiv.org/abs/2502.10673
这是一篇类似成员推理的文章,目的在于防止版权内容被未授权使用,因此添加水印。
在正式阅读之前我的一些想法
考虑到PoisonedRAG方案在构造恶意文本的时候具有的检索性前缀目的是在目标问题被问道时可以最大化二者的相似度,那么针对这种版权检测,尤其是一整个数据集的版权检测,能否是在数据集原始有用数据的基础上插入几条专门用于检测是否存在于知识库的特定文本,检测方由于知道自己设定的检测条目内容,在给RAG的时候直接把这个条目内容作为问题,理想条件下检测条目就会被检索出来,用于辅助输出。
之前看有一篇好像也是RAG知识抽取/版权检测的文章提到,RAG对检索到的数据进行的操作更像是压缩、总结类型的,而不是从0开始自行构建回答结果,这样的特性应该可以同意上面的方案。
但是同样存在很大的不足,比如RAG供应商选择性地把没版权内容放入知识库,就别提检测条目的事情了;本质上想要从输出结果对检测条目是否在知识库中进行判别,也需要对检测条目的内容加上数字水印
所以对于版权方来讲,比较万无一失的做法就是对每一句话都添加上水印。
现在对RAG的知识库版权检测都是基于"有水印的文本被检索后用于生成,得到的结果也是有水印的"这样的假设,对于RAG的核心LLM来说,破坏这样的假设,让生成结果无水印,现有的各种版权检测方案就都被无效化了;此外,RAG系统的prompt也必然是有影响的,比如在PRAG中使用的prompt,是让LLM输出最为简短的回答,这种结果能否被用于水印检测存在很大的疑问,我直观上感觉是不能的。
RAG 对外部数据集的依赖引发了对数据集安全和知识产权 (IP) 的潜在担忧。 未经授权使用或复制专有数据集可能导致知识产权侵权,给数据所有者带来重大风险。 知识产权保护的这种侵蚀反过来可能会对经济效率产生负面影响。保护 RAG 系统中的数据集是一项严峻的挑战,需要确保道德使用的方法,同时保留数据集的原始效用。
威胁模型
数据所有者,其旨在保护数据集免受未经授权的使用;恶意的 RA-LLM,它拥有一个知识数据集,并试图在未经授权的情况下将 IP 数据集纳入其知识库。
数据所有者在 IP 数据集发布前主动对其执行操作,例如嵌入不可见水印,以实现有效保护。 随后,受保护的数据集可供授权用户访问,或可能被未授权用户非法获取。 数据所有者的能力包括通过向 RA-LLM 输入有限数量的精心设计的查询,并仅分析生成的响应来执行黑盒数据集成员推理。
问题描述
将水印金丝雀嵌入到受保护的数据集中,作为未经授权使用的证据,并在数据集被盗用时实现可靠检测。 如图1方法由两个关键组件组成。
在数据集保护阶段,数据所有者生成水印金丝雀文档,并将它们插入到 IP 数据集中,然后发布。
在数据集检测阶段,数据所有者对 RA-LLM 执行多个查询,并通过将其构建为假设检验问题来识别未经授权的使用,以区分以下两个假设:
H0: 响应不包含水印
H1: 响应包含水印。

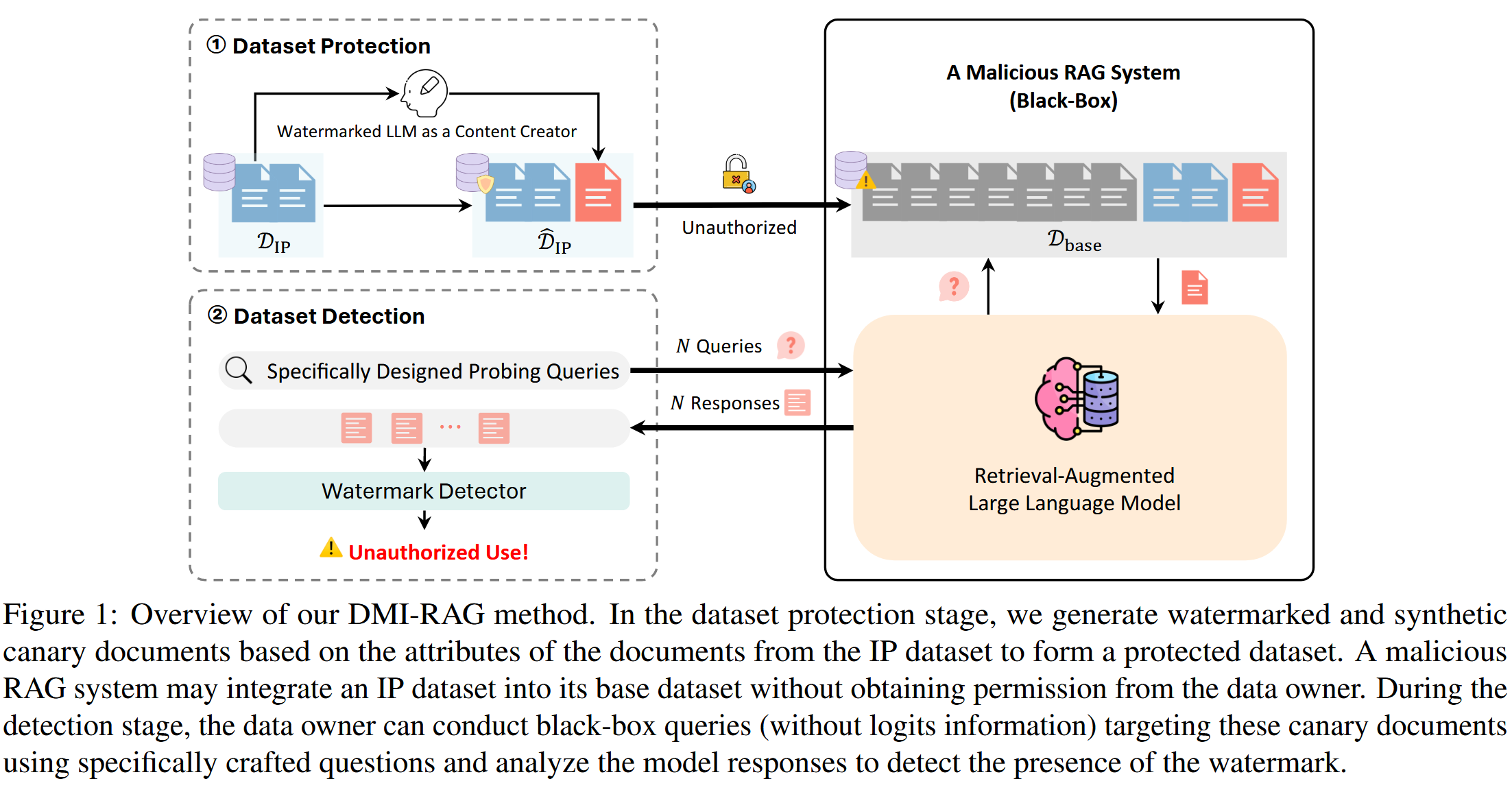 图 1: 我们的 DMI-RAG 方法概述。 在数据集保护阶段,我们根据知识产权数据集中文档的属性生成带水印的合成 canary 文档,以形成受保护的数据集。 恶意 RAG 系统可能会在未经数据所有者许可的情况下,将知识产权数据集集成到其基础数据集中。 在检测阶段,数据所有者可以进行黑盒查询(没有 logits 信息),目标是使用专门设计的针对这些 canary 文档的问题,并分析模型响应以检测水印的存在。
图 1: 我们的 DMI-RAG 方法概述。 在数据集保护阶段,我们根据知识产权数据集中文档的属性生成带水印的合成 canary 文档,以形成受保护的数据集。 恶意 RAG 系统可能会在未经数据所有者许可的情况下,将知识产权数据集集成到其基础数据集中。 在检测阶段,数据所有者可以进行黑盒查询(没有 logits 信息),目标是使用专门设计的针对这些 canary 文档的问题,并分析模型响应以检测水印的存在。
数据集合成
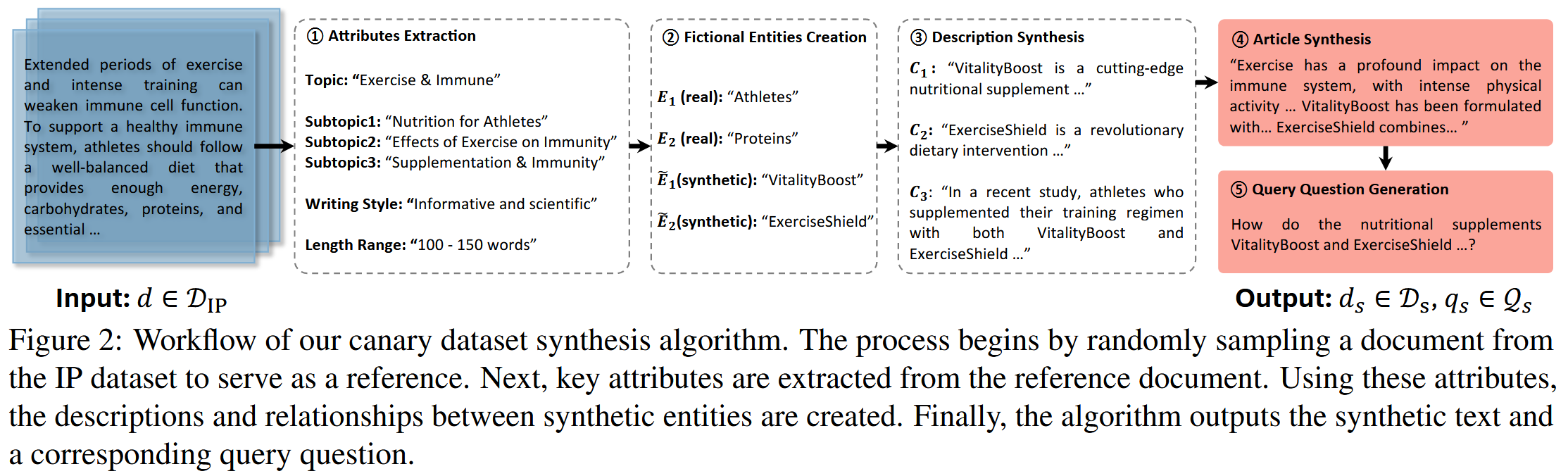
1)属性提取,2)虚构实体创建,3)描述合成,4)文章合成,以及 5)查询问题生成。
属性提取
从 d∈𝒟𝖨𝖯 中随机抽样一个文档,使用属性提取函数 𝖺𝗍𝗍𝗋_𝖾𝗑𝗍𝗋_𝖿𝗎𝗇𝖼 分析并提取抽样文本的关键属性 𝒜={A1,A2,...,An}。(LLM来做)

从抽样文档 d 中提取了四个属性:{A1=𝖳𝗈𝗉𝗂𝖼,A2=𝖲𝗎𝖻𝗍𝗈𝗉𝗂𝖼,A3=𝖶𝗋𝗂𝗍𝗂𝗇𝗀𝖲𝗍𝗒𝗅𝖾,A4=𝖶𝗈𝗋𝖽𝖢𝗈𝗎𝗇𝗍}。 这些属性确保了合成文档与原始数据集具有相同的主题、写作风格和长度。
虚构实体创建
为了确保合成文本的唯一性,从 d 中提取真实实体 ℰ={E1,...En},并使用带有 𝖾𝗇𝗍_𝗌𝗒𝗇𝗍𝗁_𝖿𝗎𝗇𝖼 的 LLM 创建以属性 𝒜 为条件的虚构实体 ℰ~={E~1,...,E~n}:
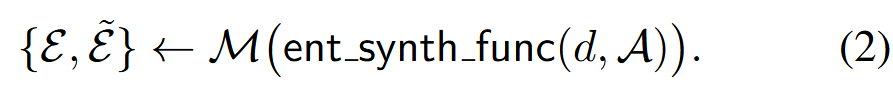

描述合成
使用具有 𝖽𝖾𝗌_𝗌𝗒𝗇𝗍𝗁_𝖿𝗎𝗇𝖼 的 LLM 合成每个实体的虚构描述及其之间的关系 𝒞={C1,...Cn}:
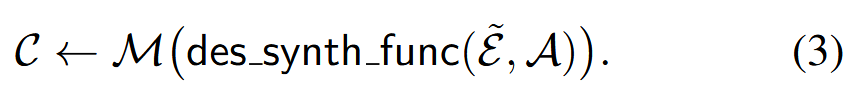
这一步保留了与 𝒟𝖨𝖯 的上下文相关性,同时确保合成文本保持独特和可识别。

文章合成
收集合成的描述 𝒞,使用具有 𝖺𝗋𝗍𝗂𝖼𝗅𝖾_𝗌𝗒𝗇𝗍𝗁_𝖿𝗎𝗇𝖼 的 LLM 生成一篇新文章 ds:
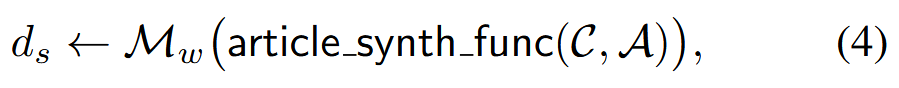

M_w是水印LLM,采取的方案是经典红绿表方案

查询问题生成
对于每个 ds∈𝒟s提示一个 LLM 生成一个只能通过阅读 ds 来回答的问题,使用 𝗊𝗎𝖾𝗋𝗒_𝗌𝗒𝗇𝗍𝗁_𝖿𝗎𝗇𝖼:
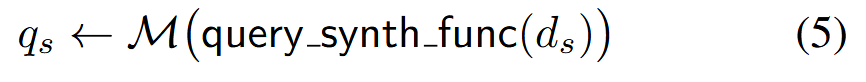
生成的 qs 用于在检测过程中从可疑的 RA-LLM 中检索相应的 ds。

成员推理
对于可疑的 RA-LLM ℳ首先使用不同的 qs(i)∈𝒬s 查询模型 N 次,并获得响应 y(i)=ℳ0(ℛ(qs(i),𝒟𝖻𝖺𝗌𝖾))。将 N 响应连接成一个序列,表示为 𝐲=y(1)⊕y(2)⊕⋯⊕y(N),以增强响应中水印的统计可检测性。通过计算响应 𝐲 的 z-统计量来检测水印,即,
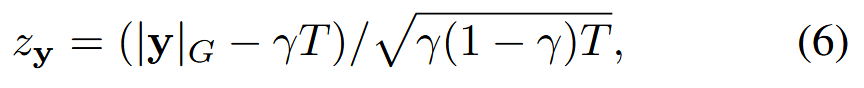
其中 T 是 𝐲 中的 tokens 数量,|𝐲|G 是绿色列表中 tokens 的计数。 如果 z𝐲>η,则将响应 𝐲 标识为已加水印,其中 η 是预定义的阈值。 因此可以等效地得出结论如果 𝒟𝖨𝖯⊆𝒟。
实验
实验设置
使用 GPT4o-mini 来提取属性并生成虚构描述
使用带水印的 Llama-3.1-70B-Instruct 将水印嵌入到合成文章中
水印算法设置 γ=0.5 和 δ=2.0。
检索器 Contriever-ms根据余弦相似度选择最相关的 K=3 个文档
主要实验中每个金丝雀文档仅用一个问题查询一次
基线:两种现有的利用水印的数据集成员推断方法进行比较,包括 Ward和 WWJ
Ward使用默认配置,使用 KGW (A watermark for large language models.) 来释义整个数据集,并设置 γ=0.5、δ=3.5 和窗口大小 h=2。 对于 WWJ,原始方法旨在保护用于训练或微调的数据集。作者进行了一些修改以使该方法适应 DMI-RAG 任务:从 ASCII 表中随机抽样一个水印序列 u,然后将水印序列插入到 IP 数据集中的每个文档中。 接下来为每个文档生成问题(qu(1),...,qu(N))来查询相应的内容。检测时首先使用qu(i)来计算水印序列lu的损失。 然后使用与数据集无关的问题(q~(1),...,q~(N))来查询RA-LLM,以计算当检索到的文档不包含水印序列时u的损失。 此过程产生损失 (l~u(1),...,l~u(N)) 的平均值 μ 和标准差 σ。 最终的决定是通过计算统计量:z=(lu−μ)/σ来做出的。 然而该基线需要访问可疑模型预测的对数概率,这在黑盒设置中不可用。实验中,设置水印序列长度|u|=40。
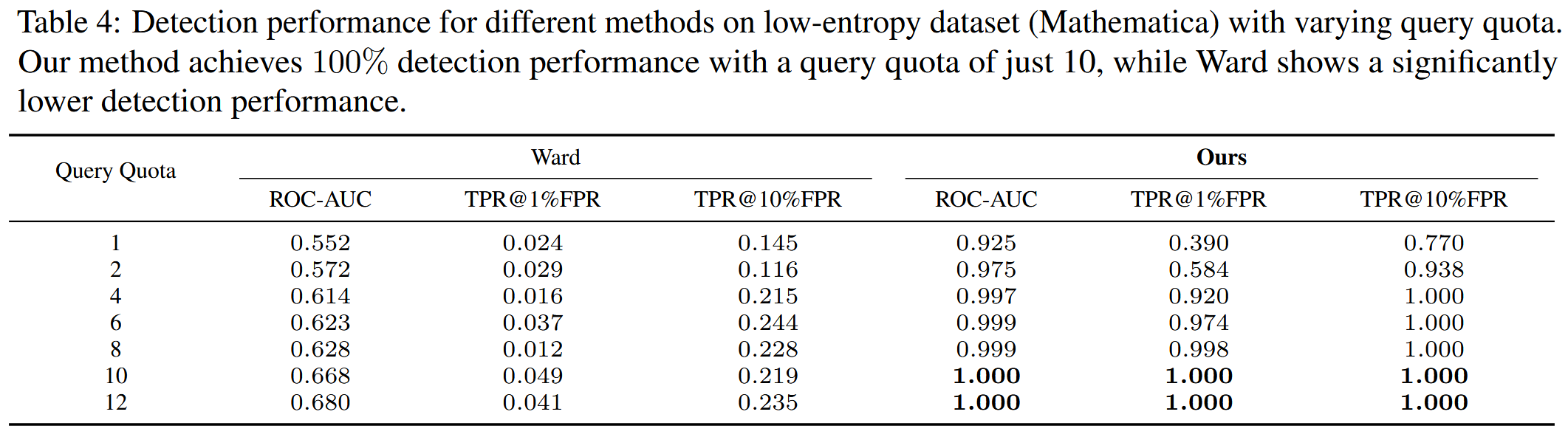
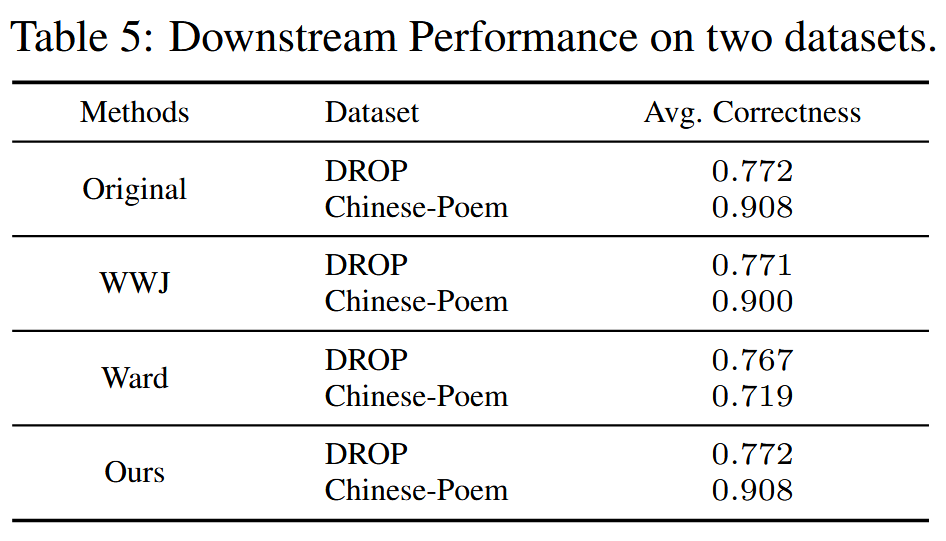
数据集。 MS MARCO 作为知识数据集在这种情况下,假设知识数据集和 IP 数据集之间可能存在潜在的语义重叠,这在现实世界中经常发生。使用生物医学信息检索数据集 NFCorpus作为 IP 数据集来评估性能。使用 CQADupStack-Mathematica作为 IP 数据集来评估方法在低熵数据集上的检测性能。 作者评估了不同方法在 Chinese-poem2 和 DROP 数据集上的下游性能。
评估指标。
- 目标检索精度来评估查询成功检索到的相应带水印文档的比例。 计算如下:1N∑i=1N𝟙(d(i)∈ℛ(q(i)))。
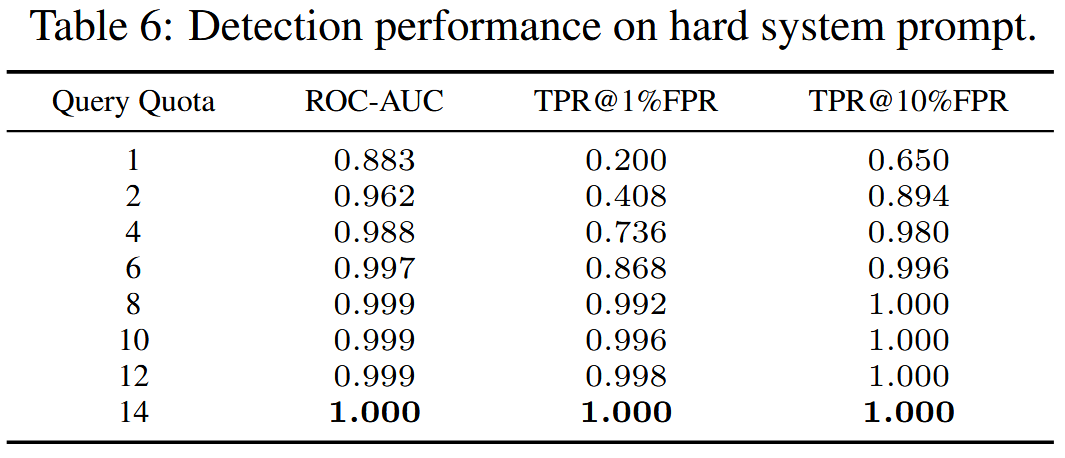
- 检测性能使用 ROC-AUC 值进行评估,该值通过评估不同阈值下的真阳性率 (TPR) 和假阳性率 (FPR) 之间的权衡来衡量检测器区分类别的能力。 还报告了不同 FPR 值下的检测性能,例如 TPR@1%FPR 和 TPR@10%FPR。
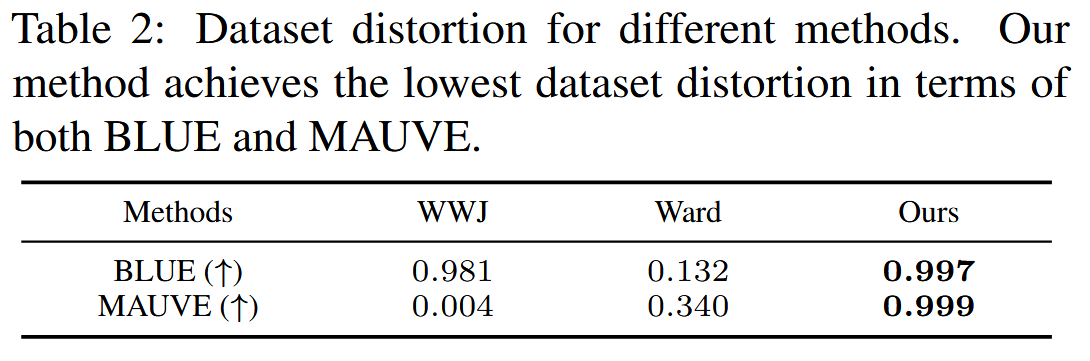
- 使用 BLEU和 MAUVE分数评估由不同数据集保护方法引起的数据集失真。
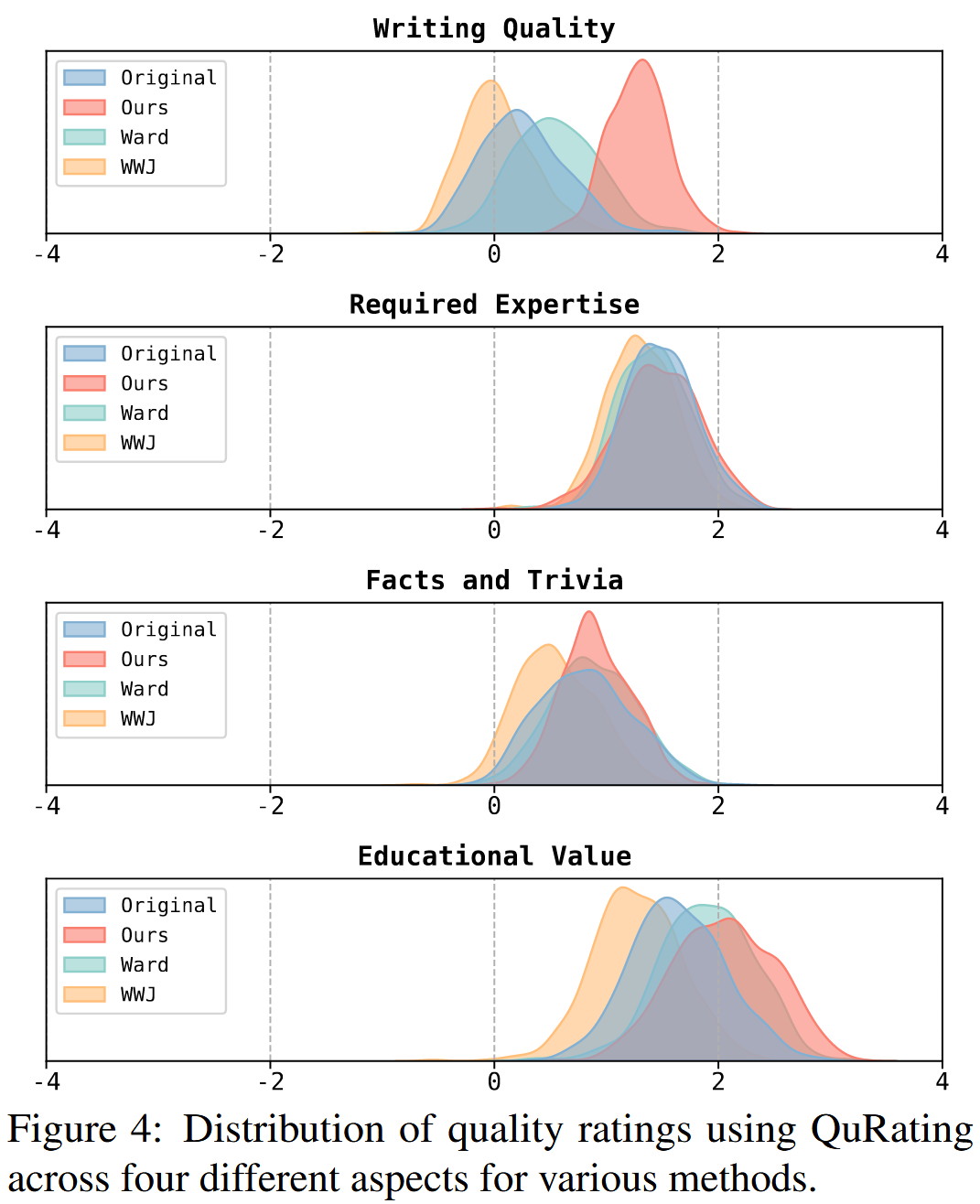
- 隐蔽性使用 Perplexity 和 QuRating进行衡量,这两种方法都用于策划数据集。 对于困惑度,计算原始 IP 数据集和水印数据集中每个文档的困惑度。 此外将每个文档拆分成更小的块(50 个单词/块),并分别计算每个块的困惑度。 极高的困惑度表明文本质量低或可能对原始内容造成损坏。 使用这些块来计算过滤率,衡量当应用困惑度阈值时被过滤掉的块的比例。 QuRating 采用评分模型来选择数据集中高质量的数据,评估四个关键维度:写作质量、事实与琐事、教育价值和所需专业知识。
- 使用 GPT4o-mini 作为判断者来计算响应的正确性,以评估每种数据集保护方法对下游 RA-LLMs 性能的影响。
结果
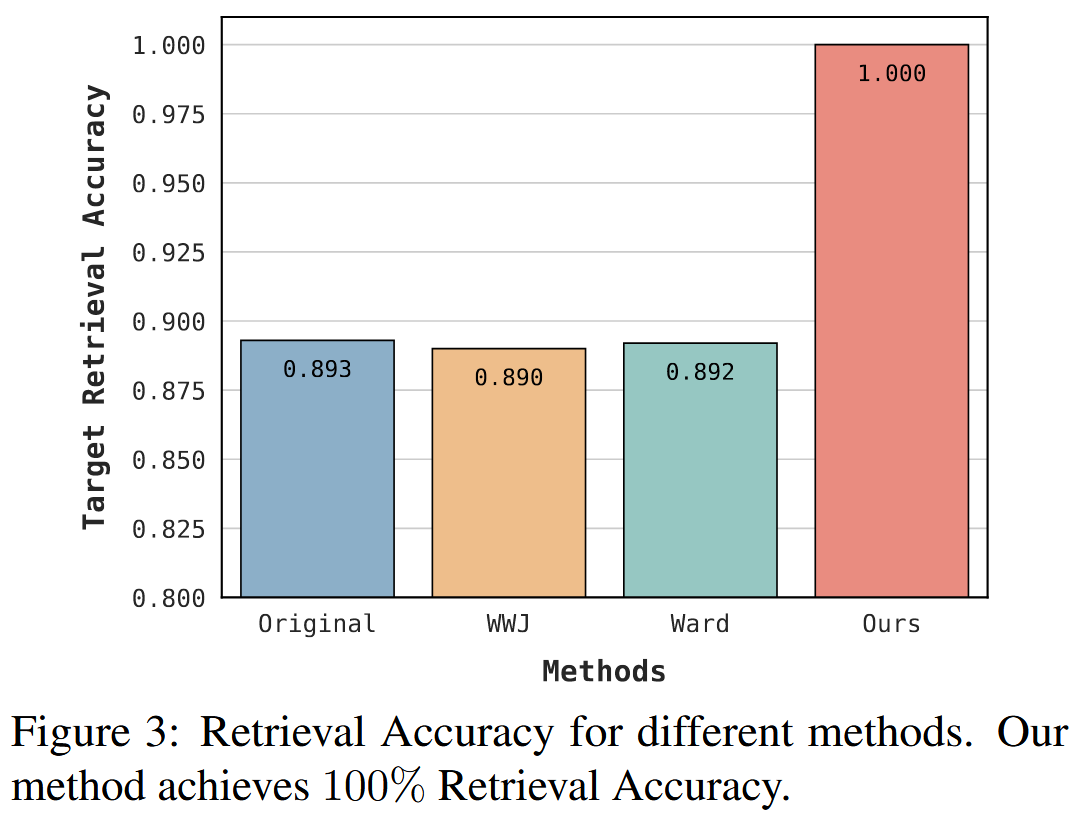
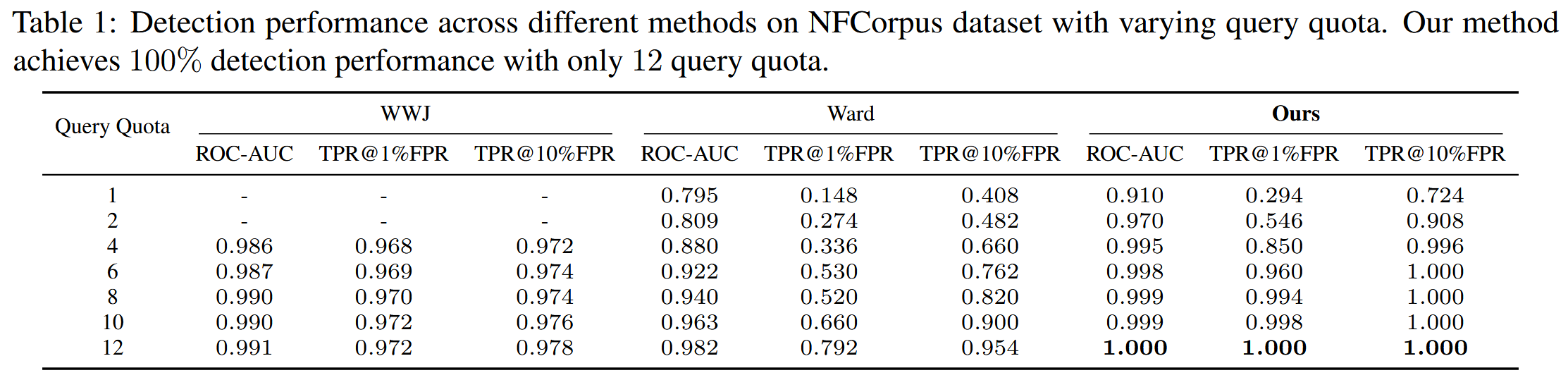
图3显示了原始IP数据集和不同基线的目标检索精度。 "原始"表示未经任何修改的原始 IP 数据集,作者生成 500 个不同的问题来查询原始 IP 数据集中的不同文档。 如表所示,我们的方法优于所有其他方法,实现了 100% 的完美检索精度。 这归因于合成虚构金丝雀的插入,这最大限度地减少了与基础数据集中其他文档的潜在语义重复。 相反,与原始 IP 数据集相比,WWJ 和 Ward 采用的方法不同程度地影响目标检索精度。

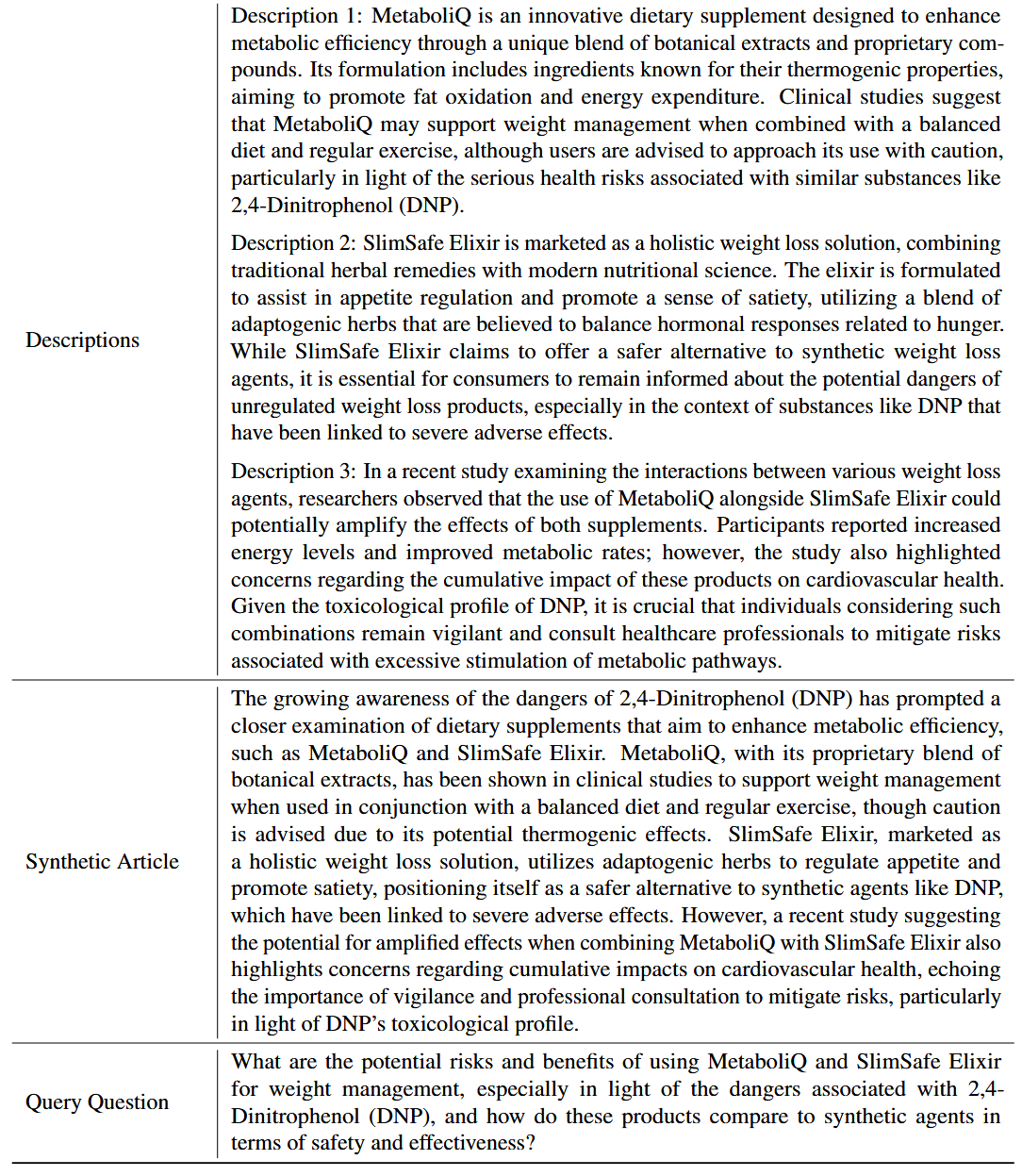
case study



阅后总结
这篇文章的思想和我最开始的设想比较一致,是在某个私有数据集中插入若干个条目专门用来检验是否被纳入知识库中,但是作者考虑的更深入了一些,比如要保证插入的文本和目标私有数据集的属性保持一致,这些属性的一致体现在大方面主题的一致(子主题是让大模型生成的虚假内容)、语言风格的一致、文本长度大小的匹配,这样才能确保无缝插入,不被明显发现然后剔除。确立了思路后,就借助先进的LLM,从目标私有数据集中抽查出来一部分作为参考,提取对应的属性,再让大模型依据这些属性生成内容,最终文档的内容由水印LLM生成(红绿表),这样带有水印的专门用于检验的文本可以作为证据。其次正是由于这种虚构子主题的存在,使得可以构建问题,最相关的只有对应的检验文本。作者则采用向可疑RAG发送多个查询,获取每一个的回答后拼接在一起,再整体进行水印检测。
不得不提的是,我考虑的还是太狭隘了,被PoisonedRAG前缀构造方案给模糊了视野啊,上面我自己的想法的时候提到"在给RAG的时候直接把这个条目内容作为问题,理想条件下检测条目就会被检索出来,用于辅助输出"这个就是典型的PoisonedRAG思维,文章的虚构子主题与对应的问题构建方案让我耳目一新,也让我不禁反思为什么我想不到这些东西。
这篇文章让我收获还是很大的,good paper