概述
注意力机制,指的是深度神经网络中的一个层,主要功能是学习大范围全局的特征,衡量事物之间的相似性。类似于信息路由器,决定输入序列的嵌入向量中哪些部分对输出的向量有贡献。
注意力有很多种实现方式(机制,Attention Mechanism,简称AM),最简单的是点积注意力,相似度的计算是注意力机制最核心的思想。
注意力机制有多种形式,可在多领域和架构中使用,而不仅是Transformer。编码器将输入序列编码为固定长度的向量,并使用解码器解码该向量,从而生成输出序列。问题在于,如果编码器无法动态地捕捉到所输入的每个单词的上下文信息,就无法正确地对与上下文相关的单词进行编码。
通过引入注意力机制,模型可在每个时间步中为输入序列中不同位置的词分配不同的注意力权重。这使得模型能够更加灵活地有选择地关注输入序列中的重要部分,从而更好地捕捉上下文相关性。
注意力机制的本质就是向量之间的点积、加权和计算。
概念
注意力跨度,Attention Span,指模型正在处理的先前词条的数量。如果一个头的注意力跨度为5,这意味着该头仅在当前位置前的最后5个词条上运行注意力。
注意力空间,Attention Space,每个头所覆盖的词条的数量,是一个整数,因此无法微分。不可微分意味着不能通过训练来直接学习那个参数。
注意力掩码,Attention Mask,用于避免模型在计算注意力分数时,将不相关的单词考虑进来。掩码操作可以防止模型学习到不必要的信息。
填充,Padding,在NLP任务中经常会将不同长度的文本输入模型。为了能够批量处理这些文本,需要将它们填充至相同的长度。
填充掩码,Padding Mask,避免在计算注意力分数时,将填充位置的单词考虑进来。
加入掩码机制后,会把将注意力权重矩阵与一个注意力掩码矩阵相加,使得不需要的信息所对应的权重变得非常小(接近负无穷)。然后,通过应用softmax函数,将不需要的信息对应的权重变得接近于0,从而实现忽略它们的目的。
后续注意力掩码,Subsequent Attention Mask,简称后续掩码,也叫前瞻掩码(Look-aheadMasking),为了在训练时为解码器遮蔽未来的信息。
掩码函数,Mask Function,或Masking Function,也叫屏蔽函数,公式 m z ( x ) = min max \[ 1 R ( R + z − x ) , 0 , 1 ] m_z(x) = \min\left \\max\\left\[ \\frac{1}{R}(R + z - x), 0 \\right, 1 \right] mz(x)=minmax\[R1(R+z−x),0,1]
R R R是超参数,控制斜坡部分的倾斜程度,公式示意图如下
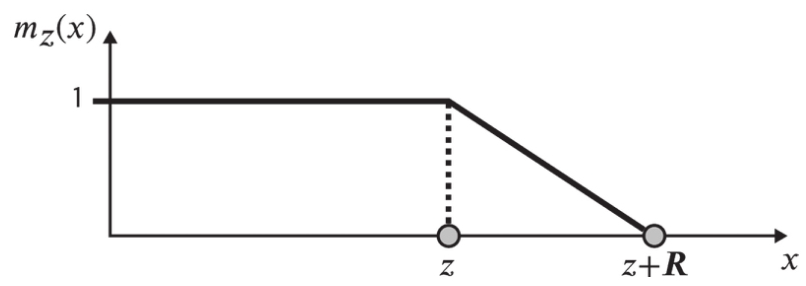
如果两个词条之间的距离 x x x足够大, m z ( x ) m_z(x) mz(x)的值将为零,这意味着不再做这两个词条之间的注意力计算。 m z ( x ) m_z(x) mz(x)函数是分段平滑的,可得到其梯度,并为每个注意头调整 z z z值。 z z z越大,注意头就会看到更多词条。
注意力权重,在某些论文或博客中,有时会将相似度得分称为原始权重。这是因为它们实际上是在计算注意力权重之前的中间结果。严格来说,相似度得分表示输入序列中不同元素之间的关联性或相似度,而权重则是在应用某些操作(如缩放、掩码和归一化)后得到的归一化值。为避免混淆,通常,将未处理的值称为得分,并在经过处理后称为权重。
常见AM
一些常见的注意力机制:
- 加性注意力(Additive Attention):又称为Bahdanau注意力,在神经机器翻译任务中首次提出。加性注意力使用一个带有激活函数(如
tanh)的全连接层来计算查询和键之间的相似度得分。相较于缩放点积注意力,加性注意力的计算复杂度略高,但在某些场景下可能更适用。 - 全局注意力(Global Attention):在计算注意力权重时,会考虑所有输入序列的元素。常用于Seq2Seq模型,如RNN编码器-解码器模型。全局注意力机制可捕捉输入序列的全局信息,但计算成本较高。
- 局部注意力(Local Attention):相对于全局注意力,局部注意力仅在输入序列的一个窗口内计算注意力权重。专注于输入序列的局部结构,可降低计算成本。可进一步细分为硬局部注意力(Hard Local Attention)和软局部注意力(Soft Local Attention),区别在于选择窗口的方式。
- 自适应注意力(Adaptive Attention):一种动态调整注意力权重的机制,可根据输入序列自动决定更关注全局信息还是局部信息。因此,自适应注意力机制能够在不同的上下文中自适应地调整模型的行为,提高模型的泛化能力。
- 分层注意力(Hierarchical Attention):一种在多个层次上计算注意力权重的机制。这种机制可以帮助模型捕捉不同层次的抽象特征。例如,在处理文本时,分层注意力可以先关注单词级别的信息,然后再关注句子级别的信息。
- 因果注意力(Causal Attention):一种通过后续掩码来避免模型提前获取未来信息的注意力机制。在生成型任务(如文本生成、语音合成等)中,其目的是确保模型在生成当前位置的输出时,只能关注到当前位置及其之前的位置,而不能关注到之后的位置。这是因为在实际生成任务中,模型在生成某个位置的输出时,是不知道之后位置的信息的。有助于提高模型的性能和鲁棒性。
这些注意力机制并不互斥,可根据任务需求和具体场景进行选择和组合。
点积注意力
Dot-Product Attention,作为其他注意力机制的基础,在神经网络中并没有实际应用。
Python实现代码:
py
import torch
import torch.nn.functional as F
# 1. 创建两个张量
x1 = torch.randn(2, 3, 4) # 形状(batch_size, seq_len1, feature_dim)
x2 = torch.randn(2, 5, 4) # 形状(batch_size, seq_len2, feature_dim)
# 2. 计算原始权重
raw_weights = torch.bmm(x1, x2.transpose(1, 2)) # 形状(batch_size, seq_len1, seq_len2)
# 3. 用softmax函数对原始权重进行归一化
attn_weights = F.softmax(raw_weights, dim=2) # 形状(batch_size, seq_len1, seq_len2)
# 4. 将注意力权重与x2相乘,计算加权和
attn_output = torch.bmm(attn_weights, x2) # 形状(batch_size, seq_len1, feature_dim)代码解读:
- 两个张量具有不同的序列长度;
batch_size:表示批次大小,在训练过程中,数据通常是一批批进行处理feature_dim:表示特征维度,通常也代表词嵌入维度;两个张量的特征维度必须要一致。维度不一致,无法进行点积计算,需要先进行线性变换,使其特征维度相同transpose:此函数用于对 x 2 x2 x2的后两个维度进行转置操作,即将其形状从(batch_size, seq_len2, feature_dim)变为(batch_size,feature_dim, seq_len2)torch.bmm:PyTorch中的函数,全称为批量矩阵乘法(Batch Matrix Multiplication)。它用于对存储在三维张量中的一批矩阵执行矩阵乘法。接收两个三维张量作为输入,分别为(batch_size, M, N)和(batch_size, N, P),并返回三维张量为(batch_size, M, P)。在计算过程中,它将逐个执行两个输入张量的矩阵乘法,并将结果存储在输出张量中torch.bmm可替换为torch.matmul,后者可用于多种类型的矩阵乘法,包括点积、向量与矩阵的乘法及矩阵与矩阵的乘法等。并不要求输入矩阵必须为三维张量,对输入形状的要求更加灵活;会根据输入矩阵的维度自动判断执行哪种类型的矩阵乘法,同时支持进行广播计算softmax:沿着seq_len2方向(即dim=2)对原始权重进行归一化,也就是把x2中每个位置对应的元素相似度的值归一化,使得所有权重之和为1。求得x1对x2中每一个位置的关注程度(当然也可以反其道而行之)attn_weights:注意力权重的值在0和1之间,且每一行的和为1- 注意力权重与
x2相乘,得到注意力分布的加权和。权重(或权值)是一个标量,表示某个元素在计算中的相对重要性
attn_weights可用于了解x1中各个位置与x2中各个位置之间的关系,这里的关注程度来自原始权重矩阵(相似度得分)通过softmax函数归一化得到的概率分布,其形状为(batch_size,seq_len1,seq_len2)。而attn_output则是基于注意力权重对x2中的各个位置向量进行加权求和后得到的新向量。这个新向量的维度和x1相同,形状为(batch_size,seq_len1,feature_dim),第三维重新回归到x1的特征空间,在这个新的特征空间中反映出x1中每个位置关注x2中各个位置的加权信息。这两者在注意力机制中扮演不同的角色,共同帮助模型关注输入序列中的关键部分,并在序列到序列任务中提高模型的性能。
问题:当向量很大时,它们的点积值也会变得非常大。
缩放点积注意力
Scaled Dot Product Attention,为了解决上述问题而提出。可用于解决梯度消失问题。类似于单位方差归一化,对点击进行缩放,确保任何维度的向量都具有大致相同的对齐得分。
缩放点积注意力在计算注意力权重之前,会将点积结果也就是原始权重除以一个缩放因子,得到缩放后的原始权重。通常,这个缩放因子是输入特征维度的平方根。
Q、K、V
包括:
- 查询(Query):是指当前需要处理的信息。模型根据查询向量在输入序列中查找相关信息
- 键(Key):是指来自输入序列的一组表示。它们用于根据查询向量计算注意力权重。注意力权重反映不同位置的输入数据与查询的相关性
- 值(Value):是指来自输入序列的一组表示。它们用于根据注意力权重计算加权和,得到最终的注意力输出向量,其包含与查询最相关的输入信息。
注意力机制通过计算查询向量与各个键向量之间的相似性,为每个值向量分配一个权重。然后将加权的值相加,也就是将每个值向量乘以其对应的权重(即注意力分数),得到一个蕴含输入序列最相关信息的输出向量。
在缩放点积注意力中,K和V向量的维度不一定需要完全相同。K和V的序列长度维度应该相同,因为它们描述同一个序列的不同部分。然而,它们的特征(或隐藏层)维度可以不同。V向量的第二个维度则决定最终输出张量的特征维度,这个维度可以根据具体任务和模型设计进行调整。
而K向量的序列长度维度(在这里是第2维)和Q向量的序列长度维度可以不同,因为它们可以来自不同的输入序列,但是,K向量的特征维度需要与Q向量的特征维度相同,因为它们之间要计算点积。
在实践中,K和V的各个维度通常是相同的,因为它们通常来自同一个输入序列并经过不同的线性变换。
自注意力
Self Attention,自注意力就是自己对自己的注意,它允许模型在同一序列中的不同位置之间建立依赖关系。
一个最简单的自注意力机制示例代码:
py
import torch
import torch.nn.functional as F
x = torch.randn(2, 3, 4)
# 计算原始权重,形状为(batch_size, seq_len, seq_len)
raw_weights = torch.bmm(x, x.transpose(1, 2))
# 用softmax函数对原始权重进行归一化,形状为(batch_size, seq_len, seq_len)
attn_weights = F.softmax(raw_weights, dim=2)
# 计算加权和,形状为(batch_size, seq_len, feature_dim)
attn_outputs = torch.bmm(attn_weights, x)在自注意力中,只需要对输入序列进行不同的线性变换,得到Q、K和V向量,然后应用缩放点积注意力。
窗口注意力
Windowed Attention
MHA
Multi-Head Attention,多头注意力机制,是Transformer架构的核心组成部分,其原理是将输入数据通过不同头进行多次注意力计算,然后将这些计算结果拼接起来,再通过一个线性变换得到最终输出。
能够同时从不同的子空间中提取特征信息,从而捕捉到输入数据中更丰富、更复杂的特征关系,可以提高模型捕捉长距离依赖和不同语义层次的能力。
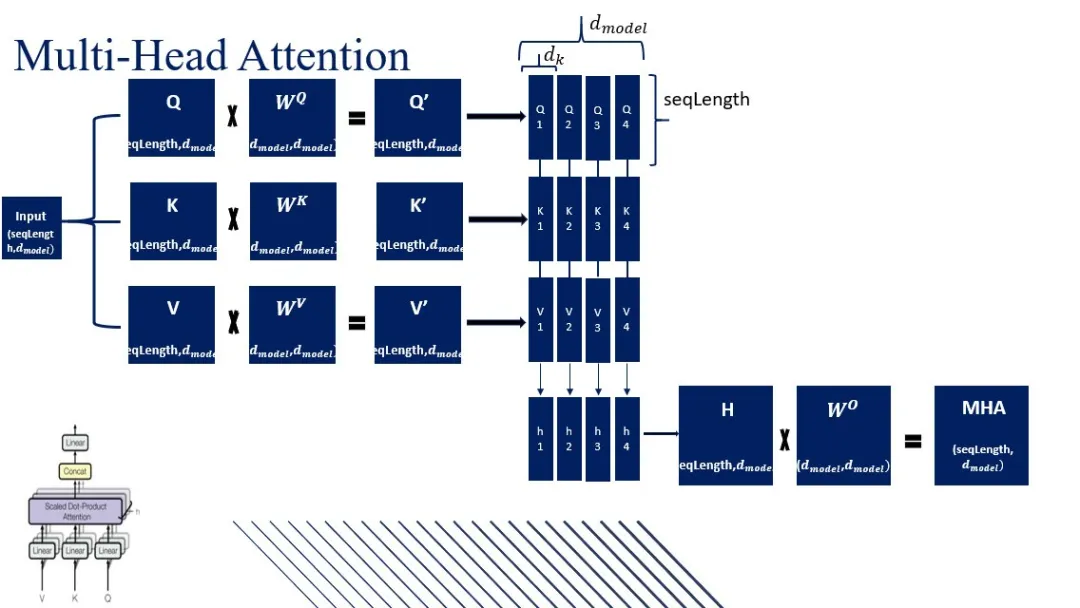
计算过程
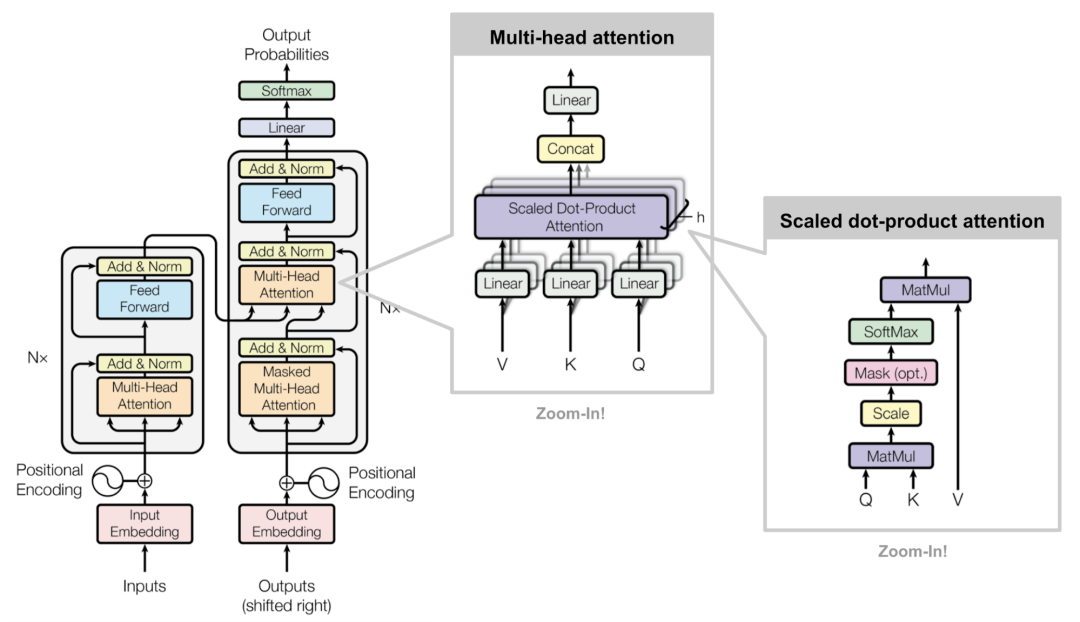
假设输入数据为Q(查询向量)、K(键向量)和V(值向量),每个头的注意力计算公式
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
其中 d k d_k dk是键向量维度,用于缩放点积结果,防止梯度消失或爆炸。
在MHA中,将输入数据分别通过不同的线性变换得到多个头的Q、K和V,然后对每个头分别进行上述缩放点积注意力(Scaled Dot-Product Attention)计算,最后将所有头的输出拼接起来,并通过一个线性变换得到最终结果
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O \mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}\left(head_1,...,head_h\right)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中 h h h是头的数量, W O W^O WO输出的线性变换矩阵。
优点
- 能够捕捉到输入数据中不同位置之间的长距离依赖关系,这对于处理序列数据尤为重要,例如在自然语言处理任务中,能够更好地理解句子中单词之间的语义关系。
- 通过多个头的并行计算,能够从不同的子空间中提取信息,从而捕捉到更丰富的特征和模式,提高模型的表达能力和泛化能力。
局限性:
- 计算复杂度较高,尤其是当输入数据的维度和头的数量较大时,计算量会显著增加,这可能会导致训练和推理速度较慢,限制其在大规模数据和实时应用中的使用;
- 由于每个头的注意力权重是独立学习的,可能会出现一些头学到相似的特征,导致冗余性增加,降低模型的效率和可解释性。
实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h, dropout=0.1):
"""
Args:
d_model: 输入维度(特征维度)
h: 注意力头的数量
dropout: Dropout概率
"""
super().__init__()
self.d_model = d_model
self.h = h
self.d_k = d_model // h # 每个头维度
# 定义线性变换层
self.W_q = nn.Linear(d_model, d_model) # 查询变换
self.W_k = nn.Linear(d_model, d_model) # 键变换
self.W_v = nn.Linear(d_model, d_model) # 值变换
self.W_o = nn.Linear(d_model, d_model) # 输出融合
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
计算缩放点积注意力
Args:
Q: 查询张量(batch_size, h, seq_len, d_k)
K: 键张量(batch_size, h, seq_len, d_k)
V: 值张量(batch_size, h, seq_len, d_k)
mask: 掩码(可选)
"""
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
output = torch.matmul(attn_weights, V)
return output, attn_weights
def split_heads(self, x):
"""
将输入张量拆分为多头
Args:
x: 输入张量 (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.size()
x = x.view(batch_size, seq_len, self.h, self.d_k) # 拆分为 h 个头
return x.transpose(1, 2) # (batch_size, h, seq_len, d_k)
def forward(self, Q, K, V, mask=None):
"""
Args:
Q: (batch_size, seq_len, d_model)
K: (batch_size, seq_len, d_model)
V: (batch_size, seq_len, d_model)
"""
batch_size = Q.size(0)
# 线性变换并拆分为多头
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 计算注意力并合并多头
attn_output, attn_weights = self.scaled_dot_product_attention(Q, K, V, mask)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 输出融合
output = self.W_o(attn_output)
return output, attn_weightsMQA
Multi-Query Attention,多查询注意力机制,MHA改进版本,旨在减少计算复杂度和内存占用,同时保持模型的性能。核心思想是将多个Q共享一组K和V,而不是为每个查询向量都独立计算一组K和V。
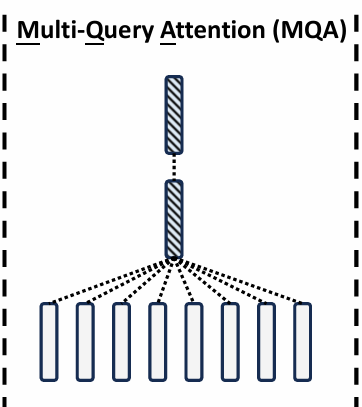
计算过程:
- 将Q通过一个线性变换得到多个查询头 { Q 1 , Q 2 , . . . , Q h } \{Q_1,Q_2,...,Q_h\} {Q1,Q2,...,Qh}。
- 将K和V通过一个共享的线性变换得到一组键向量 { K } \{K\} {K}和值向量 { V } \{V\} {V}。
- 对每个查询头分别进行注意力计算: A t t e n t i o n ( Q i , K , V ) = s o f t m a x ( Q i K T d k ) V \mathrm{Attention}(Q_i,K,V)=\mathrm{softmax}\left(\frac{Q_iK^T}{\sqrt{d_k}}\right)V Attention(Qi,K,V)=softmax(dk QiKT)V
- 将所有查询头的输出拼接起来,并通过一个线性变换得到最终结果: M u l t i Q u e r y ( Q , K , V ) = C o n c a t ( A t t e n t i o n ( Q 1 , K , V ) , . . . , A t t e n t i o n ( Q h , K , V ) ) W O \mathrm{MultiQuery}(Q,K,V)=\mathrm{Concat}\left(Attention(Q_1,K,V),...,Attention(Q_h,K,V)\right)W^O MultiQuery(Q,K,V)=Concat(Attention(Q1,K,V),...,Attention(Qh,K,V))WO
优化点在于减少K和V的计算和存储开销。在MHA机制中,每个查询头都需要独立计算一组K和V,这导致计算复杂度和内存占用较高。而MQA通过共享K和V,显著减少计算量和内存占用,同时能够保持模型的性能。
这种优化在实际应用中具有重要意义。例如,在处理大规模数据集时,MQA能够更快地完成训练和推理过程,提高模型效率。MQA在自然语言处理任务中表现出色,如机器翻译、文本生成等,能够在保持模型性能的同时,降低计算资源的消耗。
GQA
Grouped-Query Attention,分组查询注意力机制,旨在进一步提高计算效率和模型性能。核心思想是将查询向量分组,每组共享一组K和V,而不是为每个查询头都独立计算K和V。
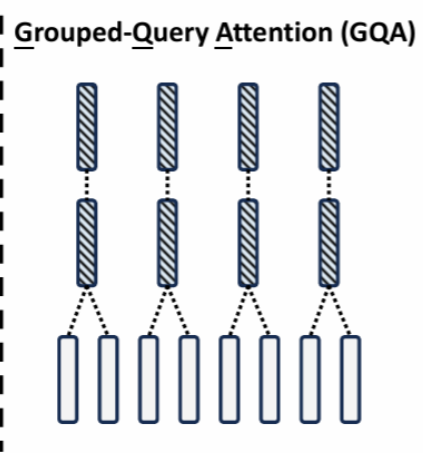
计算过程:
- 将Q分为 g g g组,每组包含 h / g h/g h/g个查询头。
- 对于每组查询头,共享一组键向量 K g Kg Kg和值向量 V g Vg Vg。K和V通过线性变换得到 K g = W K g K , V g = W V g V K_g=W_K^gK,V_g=W_V^gV Kg=WKgK,Vg=WVgV:其中, W K g W_K^g WKg和 W V g W_V^g WVg是针对每组的线性变换矩阵。
- 对于每组中的每个查询头 Q i Q_i Qi进行注意力计算: A t t e n t i o n ( Q i , K g , V g ) = s o f t m a x ( Q i K g T d k ) V g \mathrm{Attention}(Q_i,K_g,V_g)=\mathrm{softmax}\left(\frac{Q_iK_g^T}{\sqrt{d_k}}\right)V_g Attention(Qi,Kg,Vg)=softmax(dk QiKgT)Vg
- 将所有查询头的输出拼接起来,并通过一个线性变换得到最终结果: G r o u p e d Q u e r y ( Q , K , V ) = C o n c a t ( A t t e n t i o n ( Q 1 , K g , V g ) , . . . , A t t e n t i o n ( Q h , K g , V g ) ) W O \mathrm{GroupedQuery}(Q,K,V)=\mathrm{Concat}\left(Attention(Q_1,K_g,V_g),...,Attention(Q_h,K_g,V_g)\right)W^O GroupedQuery(Q,K,V)=Concat(Attention(Q1,Kg,Vg),...,Attention(Qh,Kg,Vg))WO
在计算效率和模型性能方面具有显著优势。通过将查询向量分组并共享K和V,减少K和V的计算和存储开销,同时保持MHA机制的性能。优势:
- 计算效率提升:与MHA相比,减少K和V计算量,显著提高计算效率;
- 内存占用减少:由于K和V的共享,GQA的内存占用大幅减少,这对于内存受限的设备和应用场景具有重要意义;
- 模型性能保持:尽管进行优化,GQA仍然能够保持与MHA相当的性能。在NLP任务中,如机器翻译、文本生成等,GQA能够有效地捕捉输入数据中的复杂特征关系,提高模型的表达能力和泛化能力。
GQA已经被广泛应用于各种DL模型中。例如,在Transformer架构中,GQA可以替代MHA机制,显著提高模型的效率和性能。GQA在CV领域也有应用,如在图像分类和目标检测任务中,GQA能够有效地处理图像特征,提高模型的准确性和效率。
MLA
Multi-Head Latent Attention,多头潜在注意力机制,核心思想是引入潜在空间(latent space),在潜在空间中进行注意力计算,减少计算复杂度,同时捕捉更丰富的特征关系。
计算过程:
- 将Q和K分别通过线性变换映射到潜在空间中,得到潜在查询向量 Q ′ Q' Q′和潜在键向量 K ′ K' K′: Q ′ = W Q Q , K ′ = W K K Q'=W_QQ,K'=W_KK Q′=WQQ,K′=WKK,其中 W Q W_Q WQ和 W K W_K WK是线性变换矩阵。
- 在潜在空间中进行注意力计算: A t t e n t i o n ( Q ′ , K ′ , V ) = s o f t m a x ( Q ′ K ′ T d k ) V \mathrm{Attention}(Q',K',V)=\mathrm{softmax}\left(\frac{Q'K'^T}{\sqrt{d_k}}\right)V Attention(Q′,K′,V)=softmax(dk Q′K′T)V
- 将所有头的输出拼接起来,并通过一个线性变换得到最终结果: M u l t i H e a d L a t e n t ( Q , K , V ) = C o n c a t ( A t t e n t i o n ( Q 1 ′ , K 1 ′ , V ) , . . . , A t t e n t i o n ( Q h ′ , K h ′ , V ) ) W O \mathrm{MultiHeadLatent}(Q,K,V)=\mathrm{Concat}\left(Attention(Q'_1,K'_1,V),...,Attention(Q'_h,K'_h,V)\right)W^O MultiHeadLatent(Q,K,V)=Concat(Attention(Q1′,K1′,V),...,Attention(Qh′,Kh′,V))WO
MLA在MHA基础上引入潜在空间,带来显著效果提升:
- 计算复杂度降低:通过在低维潜在空间中进行注意力计算,显著减少计算量。实验表明,与MHA相比,MLA计算复杂度降低约30%;
- 特征提取能力增强:潜在空间能够捕捉到输入数据中更深层次的特征关系。在NLP任务中,能够更好地理解句子中单词之间的语义关系。在机器翻译任务中,使用MLA的模型BLEU分数比传统MHA模型提高5%。
- 模型泛化能力提升:MLA通过潜在空间的映射,能够更好地处理不同类型的输入数据,提高模型泛化能力。在跨领域任务中,MLA性能表现出色;
- 内存占用减少:由于在潜在空间中进行计算,MLA减少K和V的存储需求。在实际应用中,内存占用比MHA减少约20%,这对于内存受限的设备和应用场景具有重要意义。
在实际应用中,MLA已经被证明在多种任务中表现出色。例如,在文本分类任务中,MLA模型的准确率达到92%,比MHA模型提高3个百分点。在图像识别任务中,MLA机制也被应用于视觉Transformer中,显著提高模型的准确性和效率。
| 机制 | KV缓存需求 | 推理速度 | 模型质量 | 适用场景 |
|---|---|---|---|---|
| MHA | 高 | 较慢 | 高 | 需要高表达能力的场景 |
| MQA | 极低 | 最快 | 较低 | 推理速度要求极高的场景 |
| GQA | 较低 | 较快 | 较高 | 平衡推理速度和模型质量的场景 |
| MLA | 最低 | 高 | 最高 | 高效推理与高质量输出的场景 |
FlashAttention
有精力的可去看论文:
开源(GitHub,19.9K Star,2K Fork)
Paged Attention
分页注意力,借鉴操作系统中的虚拟内存分页(Paging)机制,将原本连续KV Cache内存空间分割成若干个固定大小的内存块(Blocks)。
- 内存块化管理:每个请求的KV Cache不再需要连续的内存空间,而是可以由分散的内存块组成。
- 灵活分配:块化管理使得内存分配更加灵活,能够根据实际需求动态地为每个请求分配所需的内存块。
- 减少碎片:有效地减少内存碎片,提高内存利用率。
- 提高吞吐量:通过更高效的内存管理,能够显著提升模型的吞吐量,尤其是在处理长序列和高并发场景下。
NSA
DeepSeek提出Native Sparse Attention,论文,智能筛选关键信息,专为超长文本处理打造的注意力加速器。
R1遗留问题:
- 长文本建模需求与挑战:长文本建模对下一代LLM至关重要,但标准注意力机制计算复杂度高,处理长序列时成为关键延迟瓶颈,稀疏注意力机制为提高效率提供方向。
- 现有稀疏注意力方法的局限:许多稀疏注意力方法在实际部署中无法实现理论上的加速,且大多仅关注推理阶段,缺乏训练阶段的有效支持。
NSA引入两个核心创新以对应于上述关键需求:
- 硬件对齐的算法设计:NSA通过优化块状稀疏注意力机制,充分利用现代硬件(如GPU的Tensor Core)的计算能力,确保计算与内存访问的平衡,从而在推理和训练阶段实现显著的加速。
- 可训练的稀疏注意力机制:NSA支持端到端训练,能够在减少预训练计算量的同时,保持模型的性能。这使得NSA不仅适用于推理阶段,还能在训练阶段大幅提升效率。
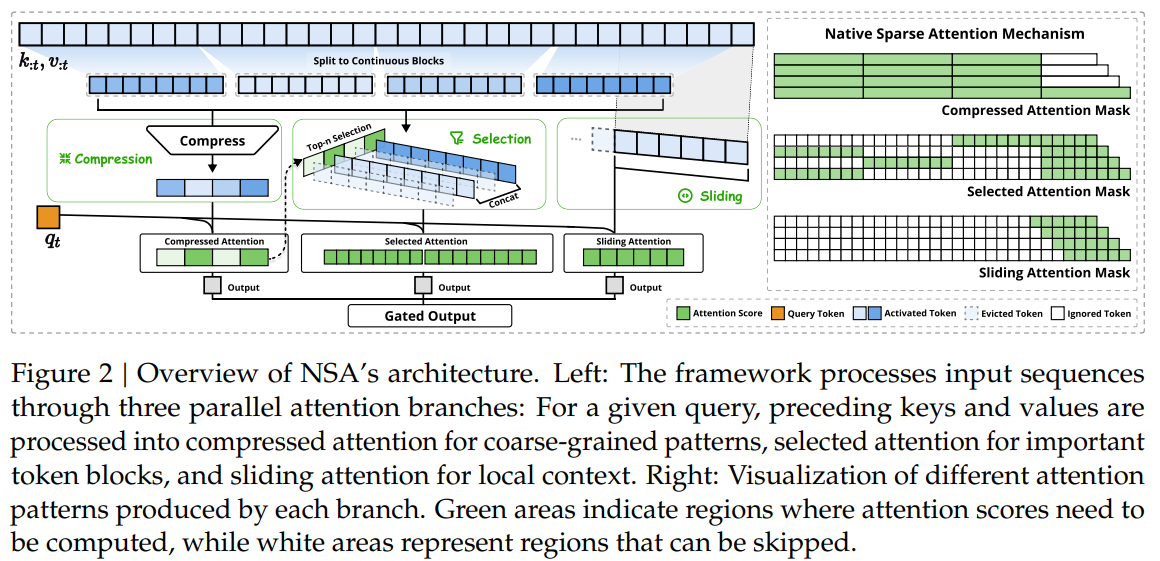
核心组成
- Token Compression:压缩块,动态分层压缩,把长文本分块提炼,留下精华,丢掉冗余。将长序列划分为块,通过MLP压缩为粗粒度表示,保留全局语义。
- Token Selection:选择块,精准捞重点,像学霸划重点,动态锁定关键段落,一个不漏!基于压缩结果动态筛选重要性最高的块,保留细粒度关键信息。
- Sliding Window:滑动窗口块,滑动窗口补细节,局部上下文也不放过,全面理解无死角!强制保留局部邻近tokens,防止模型被局部模式主导。
优势
- 硬件高效性
- 优化内存访问:以块为单位加载KV缓存,显存带宽利用率提升3.2倍
- 计算强度平衡:通过Triton实现定制化核,Tensor Core利用率达93%
- 兼容GQA/MQA架构:共享查询头的KV块,减少重复加载
- 端到端可训练性
- 所有操作(压缩、选择、门控)均为可微分量,支持从零预训练
- 在64k长度序列上,训练速度提升9倍,推理速度提升11.6倍
- 性能表现
- 通用任务:在MMLU、GSM8K等基准测试中,NSA模型(27B参数)平均性能超越全注意力基线3%
- 长文本任务:在64k上下文处理中,KV缓存从48GB压缩至4.3GB,解码延迟降至1.6ms/token
- 推理任务:AIME数学竞赛准确率提升58%,关键中间变量保留概率达92%
Power Retention
Manifest官方博客,Manifest宣布并开源Power Retention(幂注意力)技术,在长上下文场景下的效率远超Transformer模型,且无需牺牲可扩展性与硬件效率。使用pip install retention即可完成安装。
Power Retention是Transformer模型注意力层(attention layer)的即插即用替代方案:只需将flash_attention(q,k,v)替换为power_retention(q,k,v)即可。完成替换后,在处理64K tokens的上下文长度时,训练速度可提升10倍以上,推理速度更是能提升100倍以上;且上下文长度越长,性能提升越显著。
现有架构面临核心问题:
- Transformer太重:自注意力计算量随文本长度呈二次增长,长文本根本跑不动;
- 线性注意力省但效果差:为解决成本问题,研究者提出线性注意力(计算量随长度线性增长),但状态大小固定,无法利用长文本的信息,上下文内学习能力弱;
- 滑动窗口注意力顾此失彼:为平衡成本和效果,滑动窗口注意力(只看最近的一段文本),但会丢失长程信息,上下文内学习能力差。
Manifest提出,一个好的长上下文架构必须满足3个条件:
- 权重-状态均衡:模型计算分两类,用参数算(weights)和用历史信息算(stats),两者比例要接近1:1;
- 硬件要能在GPU上高效运行,尤其是利用GPU的张量核心加速计算,避免内存和带宽瓶颈;
- 上下文内学习能力强模型要能在长文本中实时学习:窗口注意力在100 token后就记不住,而线性注意力能一直记,但状态太小学不深。
公式 a t t n p o w p ( Q , K , V ) i = ∑ j = 1 i ( Q i T K j ) p V j \mathrm{attn}_{\mathrm{pow}}^p(Q, K, V)i = \sum{j=1}^{i} \left( Q_i^T K_j \right)^p V_j attnpowp(Q,K,V)i=j=1∑i(QiTKj)pVj
意在给线性注意力增加一个可调节的状态扩展开关 p p p(幂次): p p p越大,状态扩展得越大;这个参数可根据序列长度和任务复杂度自动调整。例如,短序列使用 m = 2 , 4 m=2,4 m=2,4,长序列如64K采用 m = 8 , 16 m=8,16 m=8,16。试图通过可调节的对称幂状态扩展,解决长上下文训练中成本、效果、硬件效率的三角矛盾。
核心思想是:将动态增长的KV缓存替换为固定大小的记忆体,每个新token被压缩至该记忆体中。记忆体大小可根据任务难度和计算资源动态调整,类似于其他模型的参数规模。例如,大规模训练需要大记忆体,而对推理延迟敏感的场景(如生成大量token)则可使用小记忆体,避免计算成本随token数增长。与传统Transformer相比,Power Retention在工程实现上更简单。传统KV缓存的动态大小导致GPU资源分配困难:用户请求越长,缓存占用越大,调度时需频繁轮换用户以平衡内存,既复杂又浪费。而Power Retention的固定大小记忆体可将GPU内存划分为固定份数(如8份),每个用户占用固定份额,无需动态调整。实测显示,在64k token的上下文中,Power Retention的训练速度比Flash Attention快10倍,推理速度快100倍,显著降低成本和复杂度。
为实现硬件高效性,Manifest开发Vidrial,一个即时CUDA内核生成框架。传统内核优化依赖开发者经验,但Vidrial通过遍历所有可能的硬件配置(如内存拷贝路径、张量核心使用、分块策略等),自动选择最优方案。例如,对于Flash Attention未优化的输入形状(如序列长度1243),Vidrial可通过实测找到最佳配置,速度提升20-30%。
HSAN
多尺度注意力网络,在YOLO里有实践。
参考
- GPT图解:大模型是怎样构建的