
2024.10
1.摘要
background
当前开源的大型多模态模型(LMMs)领域存在一个明显的"偏科"现象:大多数模型专注于提升单一场景(如单图像理解)的性能,而能够同时在单图像、多图像和视频这三个核心视觉场景中都表现出色的通用模型非常罕见。这与GPT-4V等先进闭源模型的全能表现形成了鲜明对比。现有工作通常为每个场景单独设计和训练模型,导致技术碎片化,无法实现跨场景的能力迁移。
innovation
本文的核心贡献是提出了一个名为LLaVA-OneVision 的模型家族,并通过一个统一的、精心设计的数据和训练配方 ,成功打造了首个在单图像、多图像和视频三大场景下都能达到SOTA性能的开源单一模型。
1. 统一视觉表示与任务迁移: 论文的一个核心洞察是,通过巧妙设计视觉表示,可以促进不同模态/场景之间的能力迁移。例如,将单张高分辨率图像处理成一个长的图块序列,使其在形式上 "模仿"视频(帧序列),从而让仅在图像上训练的能力能够零样本迁移到视频理解任务上。这种设计思想是实现"OneVision"的关键。
2. 大规模高质量数据整合: 论文整合了从LLaVA-NeXT系列博客中积累的大量高质量、多样化的指令微调数据,涵盖了单图像(3.2M)、多图像和视频(混合1.6M)。这套数据不仅规模大,而且经过精心筛选和平衡,为训练一个全能模型提供了坚实的基础。
3. 课程学习训练策略: 提出了一套分阶段的课程学习策略(Stage-1, 1.5, 2),从基础的图文对齐,到注入高质量知识,再到大规模多场景指令微调,逐步提升模型的综合能力。
好处与对比: 相比于之前为每个场景训练一个专用模型(如专门的视频LMM或多图LMM),LLaVA-OneVision作为一个单一模型 ,不仅在各自领域都达到了顶尖水平,还展现出了强大的跨场景任务迁移 和能力涌现。例如,模型能将在单图像中学到的OCR和指代表达理解能力,自动应用到视频中的视觉提示任务上,这是专用模型无法做到的。
- 方法 Method
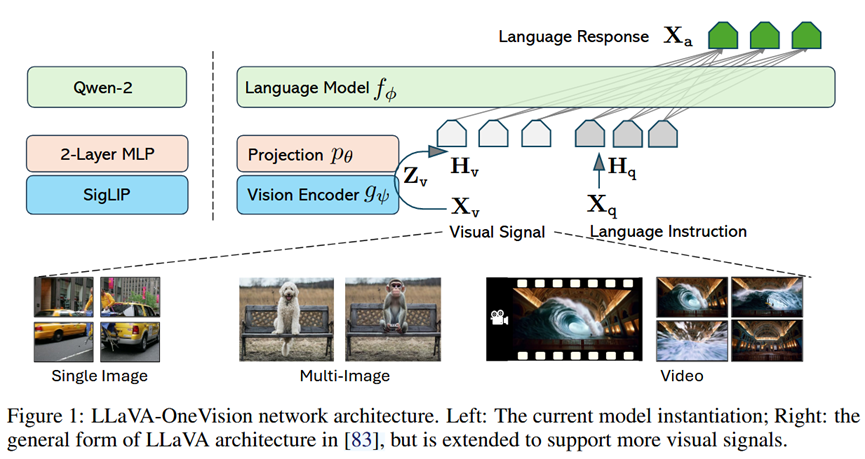
本文的方法论核心是一个数据驱动、分阶段训练的统一框架,而不是模型结构的根本性创新。
**总体 Pipeline:**整个流程遵循一个"先专后通"的课程学习原则。
输入: 单张图片、多张图片序列或视频,以及对应的文本指令。
输出: 针对指令的文本回答。
各部分详解:
1.网络架构 (Minimalism Design):
基本架构继承自LLaVA系列:Vision Encoder (SigLIP) + Projector (2-layer MLP) + LLM (Qwen-2)。这种简约设计旨在最大化利用预训练模型的强大能力。
2.视觉表示 (Visual Representations for Transfer):
单图像: 采用Higher AnyRes策略。高分辨率图像被切分成多个图块(Crops),每个图块都通过视觉编码器,形成一个模仿视频帧序列的"长视觉序列"。这被认为是实现图->视频能力迁移的关键。
多图像: 每张图片都被独立编码,然后拼接在一起。
视频: 从视频中采样帧(最多32帧),每帧经过编码器后,通过双线性插值减少token数量,以平衡性能和计算成本。
关键点在于,通过调整token分配策略(如图3所示),使得不同场景下的最大视觉token数量大致相当,为跨场景学习创造了公平的基础。
3.数据策略 (Data Strategy):
高质量知识注入: 强调"质量高于数量",使用大量合成数据(占99.8%)来扩充模型知识,包括从早期模型生成的更详细的图像描述(Re-Captioned Data)、文档/OCR数据和多语言数据。
视觉指令微调数据: 精心收集和整理了海量的指令数据,并根据视觉输入(单图/多图/视频)、指令类型、回答形式三个维度进行系统分类和平衡。
4.训练策略 (Training Strategies):
Stage-1: 语言-图像对齐 (Language-Image Alignment): 冻结Vision Encoder和LLM,只训练Projector,使用558K图文对数据进行基础的视觉-语言对齐。
Stage-1.5: 高质量知识学习 (High-Quality Knowledge Learning): 在4M高质量知识数据上微调整个模型,注入世界知识、OCR能力等。
Stage-2: 视觉指令微调 (Visual Instruction Tuning): 这是核心阶段,分为两步:
(a) 单图像训练: 先在3.2M的单图像指令数据上进行微调,打造一个强大的单图像能力基座。
(b) OneVision训练: 在此基础上,用一个包含单图像、多图像和视频的1.6M混合数据集进行进一步微调,将能力泛化到所有场景。
- 实验 Experimental Results
数据集:
训练: 使用了总计近5M的知识学习数据和4.8M的指令微调数据。
评测: 在涵盖单图像、多图像、视频三大领域的数十个主流基准上进行了全面评估,如MMBench, MathVista, LLaVA-Interleave Bench, MVBench, EgoSchema等。
实验结论:
1.全能SOTA性能: LLaVA-OneVision(特别是72B版本)在几乎所有评测的基准上都显著优于之前的开源模型,无论是在单图像、多图像还是视频领域。其性能在多个基准上超越了GPT-4V,并接近GPT-4o。
2.阶段性训练的有效性: 实验结果(如Table 4和5中"SI"模型与最终模型的对比)表明,在进行了OneVision阶段的混合数据训练后,模型在多图像和视频任务上的性能得到了显著提升,证明了该训练策略的有效性。
3.强大的任务迁移与能力涌现: 论文用大量案例(S1-S9)展示了模型惊人的涌现能力。例如:
将在单图中学到的图表理解能力,迁移到多图场景,实现图表联合推理(S1)。
将在单图中学到的OCR和指代理解能力,组合起来完成复杂的Set-of-Mark Prompting(S3)。
将在多图中学到的"找不同"能力,泛化到视频场景,分析两个视频的差异(S5)。
将在单图像学到的能力直接用于理解视频中的视觉提示(S8)。
- 总结 Conclusion
本文的核心信息是,通过精心设计的统一框架和数据策略,完全可以训练一个在多种视觉场景(单图、多图、视频)中都表现卓越的通用多模态模型。更重要的是,这种联合训练不仅能提升各个场景的性能,还能通过任务迁移和组合,催生出单一专用模型所不具备的、全新的"涌现能力",为构建更通用的视觉助手铺平了道路。