1.WordPiece
1.1 基本原理
WordPiece是一种基于统计的子词分词算法,它将单词分解为更小的子词单元
主要特点包括:
将罕见词分解为更小的已知子词
保留常见词作为完整单元
词汇表通过训练数据学习得到
1.2 训练过程
1.2.1 初始化词表
-
将所有字符加入初始词汇表
-
将训练语料中的所有单词按字符拆分并统计频率
"low" → "l", "##o", "##w"
- 在单词开头添加一个特殊的子词前缀(如
##),表示这是一个词的中间或尾部片段。
1.2.2 迭代与合并
与BPE类似,但是算法略有不同:将 pair 的频率除以其单个 token 的频率乘积(互信息)

这个公式衡量的是A和B的互信息。如果A和B经常在一起出现(freq_of_pair 高),而它们各自又不是很常见的字符(freq_of_token1 和 freq_of_token2 不高),那么它们的得分就会很高。这意味着A和B的组合具有很高的"粘性",应该被合并成一个新的子词单元。
该算法优先考虑单个 token 在词表中不太频繁的 pair 进行合并。
1.2.3 终止
重复步骤3,直到词汇表达到预定大小,或者下一次合并的得分低于某个阈值
1.3 特殊符号
1.3.1 常见符号
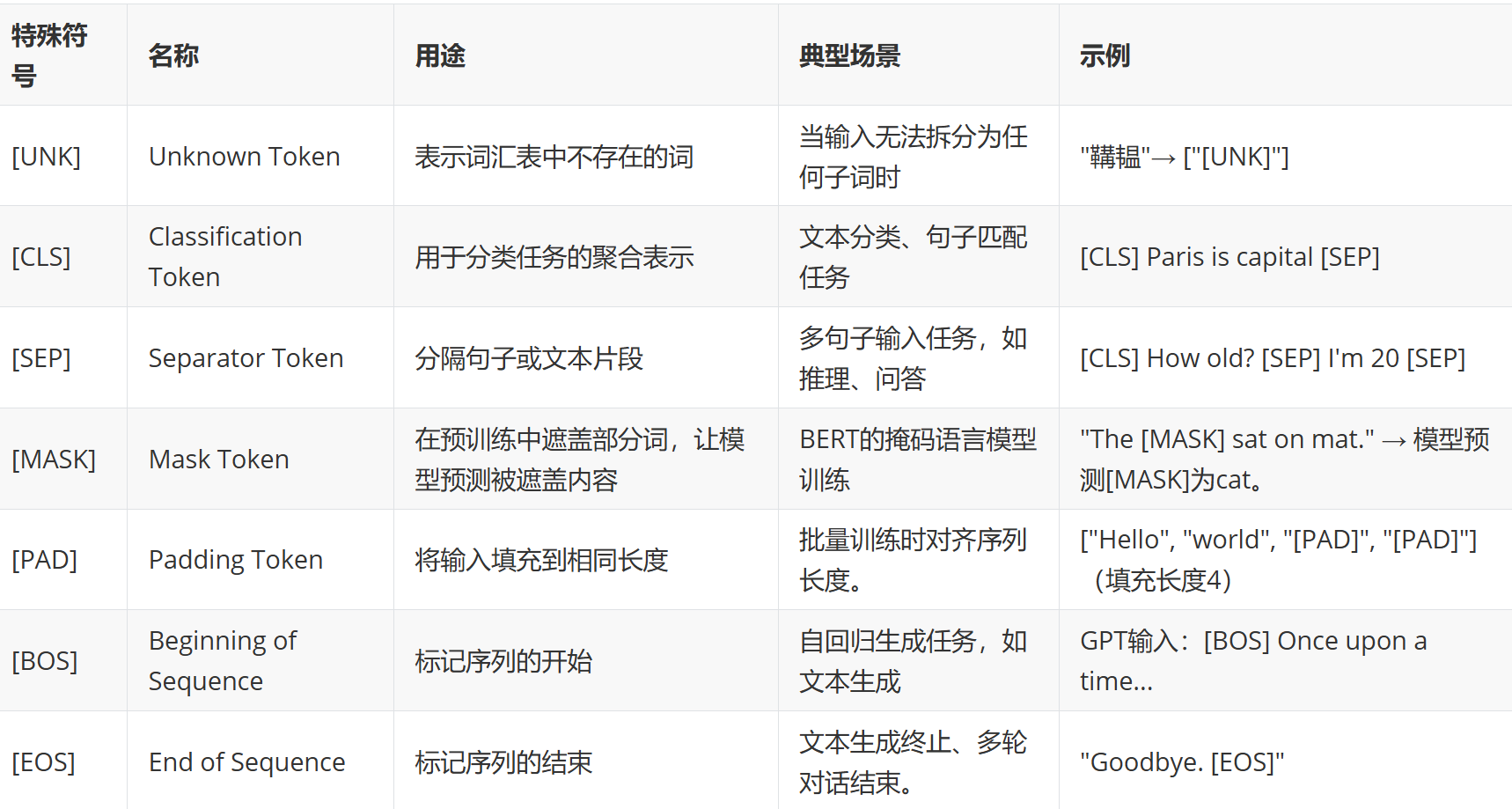
1.3.2 关键说明
-
模型依赖性
-
BERT类模型:主要使用
[CLS],[SEP],[MASK],[PAD]。 -
GPT类模型:常用
[BOS],[EOS],[PAD]。
-
-
分词策略
[UNK]应尽量避免,WordPiece/BPE会优先拆分子词(如"happiness"→["happy", "##ness"])。
-
特殊符号的嵌入
- 这些符号在模型中有对应的嵌入向量,与普通词同等处理,但功能不同。
1.3.3 存在意义
-
结构化输入:明确序列边界(如SEP)和任务类型(如CLS)。
-
鲁棒性:处理变长输入(PAD)、未知词(UNK)。
-
任务适配:支持分类(CLS)、生成(EOS)、预训练(MASK)等不同需求。
1.3.4 其他特殊符号
GPT系列使用的BBPE分词器,其特殊符号更倾向于使用简洁的符号,并且在训练开始时就被永久地加入词汇表。
-
<|endoftext|>: 这是GPT系列中一个多功能的特殊符号。它同时充当:
-
文档分隔符:在训练时,用于拼接多个独立文档。
-
序列结束: 表示一个序列或回合的结束。
-
在聊天模型中,它常被用作"轮次"的分隔符。
-
系统、用户、助手角色标记: 在ChatGPT等对话模型中,会使用特殊的符号来标记对话中的不同角色,例如:
-
system: 表示系统提示。
-
user: 表示用户说的话。
-
assistant: 表示模型(助手)的回复。
这些符号帮助模型理解对话的轮次和上下文,从而生成符合其"助手"身份的回复。
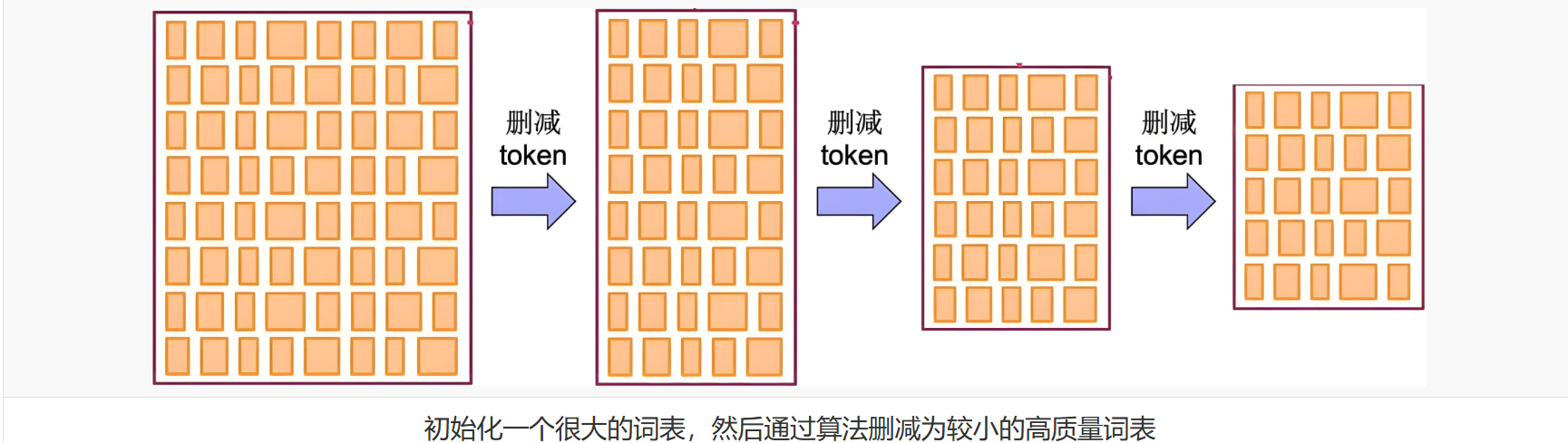
2.Unigram
与 BPE 和 WordPiece这两种常见的分词算法相比,Unigram 的工作方式恰恰相反:它首先构建一个庞大的词汇表,而后从词汇表中逐步删除词元 (token),直到达到预期的词汇表规模。
构建这个初始词汇表有几种方法:
-
选取已经分好词的单词中最常见的子串
-
在原始语料库上应用 BPE 算法,并设置一个较大的词汇表阈值。
在训练阶段的每一轮:
-
Unigram 算法都会根据当前词汇表计算整个语料库的损失值 (loss)。
-
对词汇表中的每个词元,算法会计算如果移除该词元,整体损失值会增加多少
-
并找出那些移除后损失增加最少的词元。
整个训练过程相当耗费计算资源,为加快训练速度,每次不只删除一个词元,而是会删除前p%造成损失增加最小的 的词元 (p 是超参数,通常设为 10% 或 20%)。这个过程会不断重复,直到词汇表缩小到目标大小。
2.1 基本思想
从大词汇表开始,逐步删除低概率的子词,保留最有效的组合。
3.SentencePiece
把一个句子当成一个词来分成多个subword。
SentencePiece是一种子词分词算法,广泛用于NLP预处理阶段,尤其适用于如BERT、T5、GPT等模型的训练数据构建。它的核心思想是:不依赖于空格等人为定义的分词边界,而是通过概率建模自动学习最优的子词单元,以提升模型对OOV和低频词的鲁棒性。
3.1 与BWU的比较
-
BPE、WordPiece、Unigram假设输入文本使用空格来分隔,但并非所有语言都如此,如中文、韩文、日文等。
-
可以使用特定语言的pre-tokenizer分词,但每种语言都要学习一个,不太通用。
3.2 基本思想
-
统一处理:SentencePiece将整个文本视为一个字符序列,包括空格,避免语言特有的预处理步骤。
-
学习子词:SentencePiece使用 Unigram 或 BPE 算法自动学习最优"子词"词汇表,这些子词诸如字符、常见词根、词缀等。
-
概率建模:如Unigram会学一个子词表,计算句子在不同子词组合下的概率,并保留能最大化语料可能性的子词拆分方式。
-
句子表示:训练好模型后,可将任意输入句子拆分成词表中的子词序列,这就避免了OOV问题。
3.3 工作流程
替换空格:将文本中的空格替换为特殊符号 ▁。现在文本变成了一个长的、包含 ▁ 的字符串。
输入: "I love machine learning."
转换: "I▁love▁machine▁learning."
字符拆分:将整个字符串分解成单个字符的列表(包括 ▁)。
分解:
['I', '▁', 'l', 'o', 'v', 'e', '▁', 'm', 'a', 'c', 'h', 'i', 'n', 'e', '▁', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', '.']应用子词算法(以BPE为例):
统计所有相邻字符对的频率。
合并最高频的对,比如 'l' 和 'o' -> 'lo'。
更新序列为
['I', '▁', 'lo', 'v', 'e', '▁', 'm', 'a', 'c', 'h', 'i', 'n', 'e', '▁', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', '.']不断重复此过程,合并出如 'lo' 和 've' -> 'love','le' 和 'ar' -> 'lear',最终 'lear' 和 'n' -> 'learn' 等。
生成词汇表:经过成千上万次合并后,我们会得到一个包含基础字符和所有高频片段的最终词汇表。例如,词汇表可能包含:
["I", "▁", "love", "▁m", "achine", "▁l", "earn", "ing", ".", ...]编码与解码:
编码(Tokenize):对于一个新句子,先进行空格替换和字符拆分,然后应用学习到的合并规则,贪婪地尝试用词汇表中最大的可能单元来切分它。
输入: "I learn." -> "I▁learn."
分词结果: "I", "▁l", "earn", "." (假设 "▁l" 和 "earn" 在词汇表中)
解码(Detokenize):将分词结果简单连接起来:"I" + "▁l" + "earn" + "." = "I▁learn.",然后将 ▁ 替换回空格,得到 "I learn."。
4.如何选择
-
BPE/WordPiece:适合通用场景,BPE更简单,WordPiece更注重语义。
-
Unigram:需要概率化分词时使用。
-
SentencePiece:处理非空格分隔语言(如中文)或需要端到端分词时。