01 研究背景随着人工智能的发展,尤其是大规模语言模型(LLMs)的崛起,研究者一直在探讨这些模型是否能够模仿人类的认知过程。传统的神经网络架构被认为在因果推理、直觉物理学和直觉心理学等领域存在局限性。然而,近年来,视觉处理能力强的大型语言模型引起了学术界对机器能否具备类似人类认知能力的新一轮讨论。本研究评估了当前视觉处理为基础的大型语言模型在直觉物理学、因果推理和直觉心理学领域的表现,通过一系列控制实验,研究这些现代模型在理解复杂的物理交互、因果关系以及对他人偏好的直觉理解方面的能力。研究表明,尽管这些模型在处理和解读视觉数据方面表现出一定的能力,但仍未能达到人类在这些领域的能力水平。研究结果强调,需要将更加健全的因果关系、物理动态和社会认知理解机制纳入现代视觉语言模型中,并且呼吁建立更多基于认知的基准测试。
02 研究方法研究采用了一种源自认知科学的实验范式,将多模态大型语言模型(MLLMs)视为心理学实验的"受试者",系统地评估它们在三个核心认知领域的能力。图 1:领域、任务、方法和模型概述
研究对象与认知领域:直觉物理(Intuitive Physics):评估模型对物理世界基本规律(如稳定性、重力)的理解。因果推理(Causal Reasoning):评估模型从观察中推断因果关系的能力。直觉心理(Intuitive Psychology):评估模型理解和推断他人意图、偏好等心理状态的能力(即"心智理论")。AI模型:选取了五种当前具有代表性的多模态大型语言模型,包括像GPT-4V和Claude 3 Opus这样的闭源顶尖模型,以及Fuyu-8B、Otter等开源模型,涵盖了不同的模型规模和架构。认知领域:研究聚焦于认知科学家Lake等人提出的三个"核心知识"领域:实验任务与流程:研究从认知科学的经典文献中选取了针对上述三个领域的、基于视觉刺激的典型实验任务,并将这些任务转化为对MLLMs的"视觉问答"(Visual Question Answering, VQA)测试。任务来源:实验任务的视觉材料(图片)和问题均来自已发表的、包含人类被试数据的心理学研究。例如,直觉物理任务使用了木块堆叠稳定性的判断;因果推理任务使用了"叠叠乐"(Jenga)游戏和经典的"米歇特(Michotte)小球碰撞"范式;直觉心理任务则使用了"宇航员"和"帮助或阻碍"等场景来测试意图和偏好推断。实验流程:对于每个任务,研究人员首先向模型输入一张图片,然后通过精心设计的、逐步增加认知难度的提示词(prompt)来提问。问题从简单的视觉特征识别(如"背景是什么颜色?")开始,逐步过渡到核心的认知推理问题(如"这个积木塔稳定吗?"或"蓝色智能体是想帮助红色智能体吗?")。这种由浅入深的设计,能够区分模型是仅仅在进行模式匹配,还是具备了更深层次的推理能力。
数据分析与比较:与"地面真实情况"比较:对于有客观正确答案的任务(如判断积木塔是否稳定),研究计算了模型的准确率。与人类行为比较:研究的核心分析方法是将模型的回答与原始心理学实验中的人类被试的回答进行定量比较。对于连续性判断(如责任评分),研究采用了贝叶斯混合效应回归模型,并计算了一个"伪相关系数"(pseudo r value),以量化模型与人类判断的一致性程度。这种直接将AI与人类行为进行对比的方法,能够更深刻地揭示AI在认知模式上与人类的异同。03 主要结果通过在一系列精心设计的认知任务中对五种先进的多模态大型语言模型(MLLMs)进行测试,本研究得出了关于其视觉认知能力的几个核心结论:模型具备一定的视觉处理能力,但仍有局限:在所有任务的初始阶段,即识别简单的视觉特征(如背景颜色、物体数量)时,大多数模型表现良好。然而,即使在这些基础任务上,一些模型也会出现令人意外的错误,且随着场景复杂度的增加,其基础视觉处理能力会下降,这表明它们对视觉世界的理解尚不稳固。图 2:给定真实积木塔图像,五个视觉 LLM 针对复杂性不断增加的任务的结果
直觉物理能力初步显现,但远未及人类水平:在判断积木塔是否稳定的直觉物理任务中,只有最大型的模型(GPT-4V和Claude 3)表现略高于随机猜测水平,但其准确率(约60%)远低于人类被试(约66%)。在与人类判断的一致性方面,也只有GPT-4V显示出微弱但统计上显著的正相关性(r≈0.26),而人类之间的一致性则高得多(r≈0.59)。这表明,尽管模型可能捕捉到了一些与稳定性相关的视觉特征,但它们尚未形成类似人类的、稳健的"物理引擎"。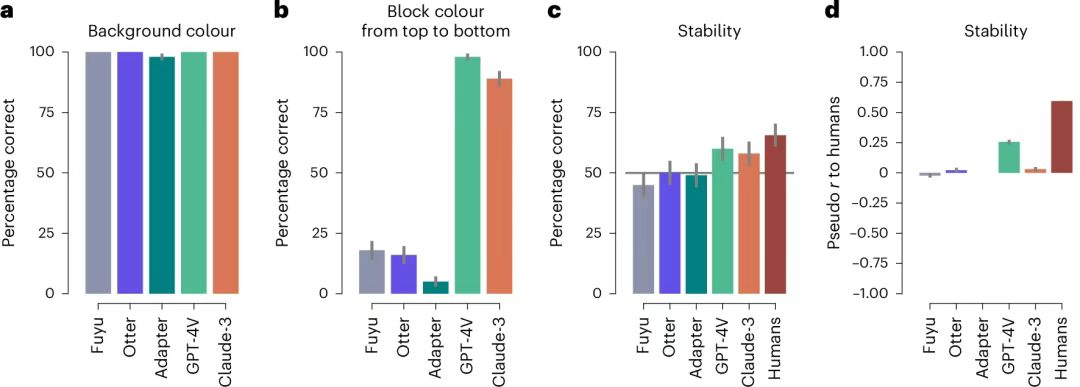
因果推理能力存在,但模式与人类不同:在基于"叠叠乐"和"米歇特小球"的因果推理任务中,大型模型同样能够做出高于随机水平的判断。例如,在判断移除某个积木后会有多少积木倒塌的任务中,GPT-4V的表现接近人类平均水平。然而,在更深层次的反事实推理(如"如果没有A球,B球会怎样?")和责任归因任务中,模型与人类的判断模式出现了显著偏差,甚至呈现负相关,显示出其因果表征与人类存在本质差异。图 3:Jenga 因果推理实验的结果图 4:Michotte 因果推理实验的结果直觉心理能力严重缺失:在需要理解他人意图和偏好的直觉心理任务(如"宇航员选择路径以平衡成本和收益"或"蓝色智能体是在帮助还是阻碍红色智能体")中,所有被测试的MLLMs都表现出严重的能力缺失。它们的回答与人类的判断几乎没有相关性,甚至在某些情况下呈现负相关。这有力地表明,当前的多模态模型尚未发展出类似人类的"心智理论"能力。图 5:直觉心理学结果图 6:直觉心理学在帮助或阻碍任务上的结果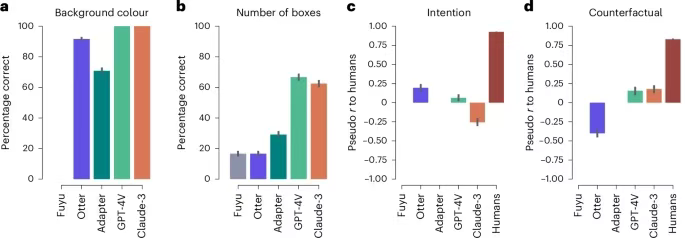
04 研究创新点本研究通过多模态大语言模型(VLMs)在直觉物理学、因果推理和直觉心理学三个核心认知领域的表现,填补了视觉语言模型认知能力的空白,提供了系统性的方法来评估这些模型的视觉认知能力。提出了基于视觉问答任务的评估框架,创新性地将传统认知科学实验任务应用于视觉语言模型中,推动了跨学科的认知评估方法的实施。提出将贝叶斯混合效应回归模型应用于模型与人类数据的对比分析,提供了更精确的模型行为评估方法。通过多领域的测试,展示了现有多模态模型在某些认知任务上的表现,揭示了它们在处理因果推理和直觉心理学任务时的局限性,为未来的模型优化提供了重要的启示。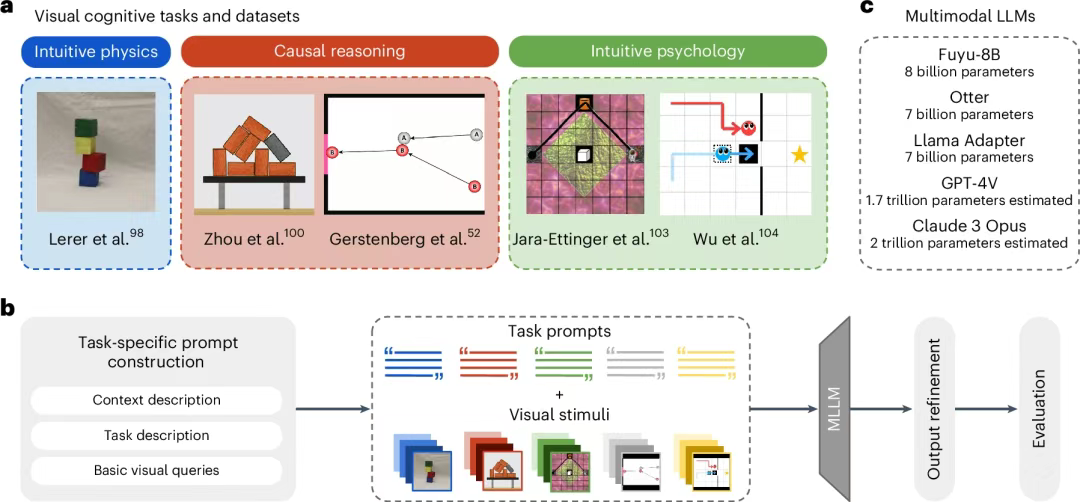
05 实验所用的具体技术、壁垒与仪器信息尖端多模态大型语言模型(MLLMs)的API访问与使用:本研究使用了包括GPT-4V和Claude 3 Opus在内的多种顶尖MLLMs。其中,闭源模型的API(应用程序编程接口)在研究进行期间可能尚未完全公开或费用高昂,获取稳定的访问权限本身就是一个门槛。此外,如何通过API有效地向这些模型提交图文结合的查询,并解析返回结果,需要专业的编程技能。开源模型的部署与运行:对于Fuyu、Otter等开源模型,研究需要在本地服务器上进行部署。这需要配置带有高端GPU(如NVIDIA A100)的计算集群,并具备处理复杂的软件依赖、进行模型安装和调试的专业知识。认知科学实验的程序化实现:将心理学实验中的视觉刺激、任务流程和提问方式,转化为可供AI模型执行的、自动化的"视觉问答"脚本,是一项核心技术挑战。这需要研究人员精心设计提示词(prompt),以确保能够准确地探查模型特定的认知能力,同时避免引入不必要的偏见。高级贝叶斯统计建模:为了将模型的输出与人类被试的判断进行定量比较,研究采用了贝叶斯混合效应回归模型。这是一种相对复杂的统计方法,需要研究人员具备扎实的统计学背景和使用R语言及brms等专业软件包的能力。人类被试数据的采集与处理:除了测试AI,研究还自行招募了107名人类被试,重新进行了一个直觉物理实验,以获取更可靠的对比数据。通过Prolific等在线平台进行规范的心理学实验,包括实验设计、伦理审批、被试招募、数据清洗等,也需要专业的实验心理学知识。