一、YOLO 系列概述
YOLO(You Only Look Once)是由 Joseph Redmon 等人于 2016 年提出的基于深度学习的目标检测算法。它的核心思想是将目标检测问题转化为回归问题,通过一个神经网络直接预测目标的类别和位置。
YOLO 算法把输入图像分成 S*S 个网格,每个网格负责预测该网格内是否存在目标,以及目标的类别和位置信息。而且,YOLO 还采用多尺度特征融合技术,能在不同尺度下检测目标。
和传统目标检测算法(像 R - CNN、Fast R - CNN、Faster R - CNN 等)相比,YOLO 凭借端到端训练方式和单阶段检测特性,可同时处理分类与定位任务,避免了传统方法的多阶段处理过程,所以检测速度更快、准确率更高,广泛应用于实时目标检测和自动驾驶等领域。
经典目标检测方法分为 one - stage(如 YOLO 系列)和 two - stage(如 Faster - rcnn、mask - Rcnn 系列)。

二、one - stage 与 two - stage 优缺点
(一)one - stage
- 优点:识别速度非常快,适合实时检测任务。像在一些对检测速度要求极高的场景,比如视频监控实时分析,one - stage 算法能快速响应。
- 缺点:正确率相对较低。
这里引入两个衡量算法效率的关键指标:
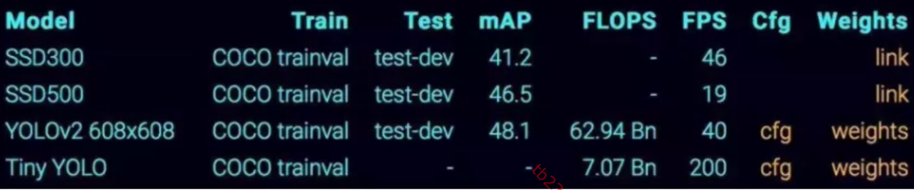
- FLOPs:表示模型进行一次前向传播(处理一张图像)所需的浮点运算次数,和模型计算量、推断速度密切相关。
- FPS:每秒可以处理的图像数量。从给出的模型数据看,Tiny YOLO 每秒能处理 200 张图像,充分体现了其速度优势。
(二)two - stage
- 优点:正确率比较高,识别效果理想。对于一些对检测精度要求严格的场景,如医疗影像中细微病灶的检测,two - stage 算法能更精准地识别。
- 缺点:识别速度比较慢,通常只有 5FPS 左右。
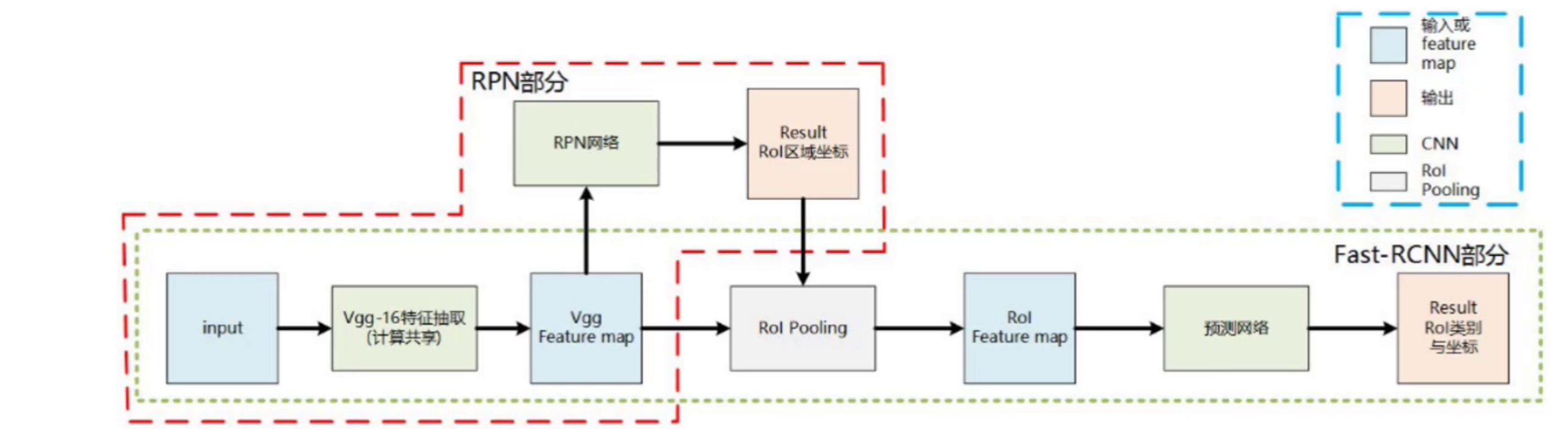
两阶段目标检测器先通过类似 Selective Search 或 EdgeBoxes 等区域提名算法生成候选框,每个候选框经 CNN 模型特征提取后,用分类器过滤,保留与目标物体更相似的候选框;然后在保留的候选框上,用另一个 CNN 模型或类似 SVM 的分类器进行精细分类和回归,预测物体的类别、位置和大小等。代表性的两阶段目标检测算法有 R - CNN 系列及其改进版本 Fast R - CNN、Faster R - CNN、Mask R - CNN 等。
三、YOLO 系列关键指标
(一)mAP 指标
mAP(Mean Average Precision)是目标检测中衡量算法性能的重要指标。要理解 mAP,先得清楚精确率(Precision)和召回率(Recall),以及混淆矩阵中的几个概念:
- TP(True Positive):真正例,即实际为正类且被正确预测为正类的样本数。
- TN(True Negative):真负例,实际为负类且被正确预测为负类的样本数。
- FP(False Positive):假正例,实际为负类却被错误预测为正类的样本数。
- FN(False Negative):假负例,实际为正类却被错误预测为负类的样本数。
精确率公式:\(Precision = \frac{TP}{TP + FP}\),表示预测为正类的样本中实际为正类的比例。
召回率公式:\(Recall = \frac{TP}{TP + FN}\),表示实际为正类的样本中被正确预测为正类的比例。
(二)IOU(Intersection over Union)
IOU 是预测框和真实框面积的交集与并集的比值,公式为 \(IoU = \frac{S_{Ground Truth} \cap S_{Prior box}}{S_{Ground Truth} \cup S_{Prior box}}\)。一般认为只有 \(IoU>0.5\) 的预测框(Prior box)才有价值,它能衡量预测框与真实框的重叠程度,是判断检测结果是否准确的重要依据。

四、总结
YOLO 系列作为 one - stage 目标检测算法的代表,在速度上优势明显,虽在精度上稍逊于 two - stage 算法,但在实时目标检测等领域应用广泛。随着技术发展,YOLO 后续版本不断优化,在速度和精度之间取得更好平衡,持续推动目标检测技术在各行业的应用。