温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着信息技术的发展,银行业务的数据量呈现爆炸式增长。如何从海量数据中提取有价值的信息,成为了金融机构提高竞争力的关键。特别是在贷款审批这一领域,准确的风险评估和高效的审批流程对于降低坏账率、提升客户满意度至关重要。基于数据挖掘的银行贷款审批预测系统旨在通过先进的数据分析技术优化贷款审批过程。
本项目开发了一个基于机器学习的银行贷款审批预测系统,采用Flask框架构建Web应用。系统通过分析申请人的信用评分、收入、资产等10余项特征数据,使用XGBoost等5种算法进行建模,最终实现90%以上的预测准确率。系统包含数据可视化、用户管理、智能预测等功能模块,为银行提供高效的风险评估工具。关键技术包括:Python数据处理、Sklearn机器学习、Bootstrap前端开发等。该方案有效提升了贷款审批效率,降低了金融机构的坏账风险。
2. 关键技术点
(1)后端技术栈
- Web框架 : Flask - 轻量级Python Web框架
- 数据库 : SQLite - 关系型数据库,存储用户信息和预测记录
- ORM框架 : SQLAlchemy - 数据库交互和模型管理
- 用户认证 : Flask-Login - 用户登录状态管理
(2)前端技术栈
- 基础技术 : HTML5、CSS3、JavaScript
- UI框架 : Bootstrap 5 - 响应式设计和组件库
- 图标库 : Font Awesome - 丰富的图标资源
- 交互库 : jQuery - DOM操作和AJAX请求
(3)数据分析与机器学习
- 数据处理 : Pandas、NumPy - 数据清洗和特征工程
- 可视化 : Matplotlib、Seaborn、ECharts - 多维度数据可视化
- 机器学习 : Scikit-learn、XGBoost - 模型训练和预测
- 分析环境 : Jupyter Notebook - 数据探索和模型开发
3. 银行贷款审批预测建模
3.1 数据集说明
数据集说明如下,旨在通过机器学习算法分析银行贷款审批数据,构建预测模型来判断贷款申请的审批结果。
- loan_id: 贷款ID
- no_of_dependents: 受抚养人数量
- education: 教育程度 (Graduate/Not Graduate)
- self_employed: 是否自雇 (Yes/No)
- income_annum: 年收入
- loan_amount: 贷款金额
- loan_term: 贷款期限
- cibil_score: 信用评分
- residential_assets_value: 住宅资产价值
- commercial_assets_value: 商业资产价值
- luxury_assets_value: 奢侈品资产价值
- bank_asset_value: 银行资产价值
- loan_status: 贷款状态 (Approved/Rejected)
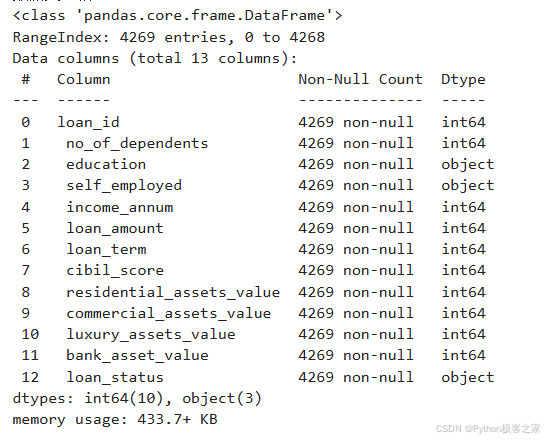
3.2 数据质量检查
python
# 检查缺失值
print("缺失值统计:")
missing_values = df.isnull().sum()
print(missing_values[missing_values > 0])
# 检查重复值
print(f"\n重复行数量: {df.duplicated().sum()}")
# 查看目标变量分布
print("\n贷款状态分布:")
print(df[' loan_status'].value_counts())
# print("\n贷款状态比例:")
# print(df['loan_status'].value_counts(normalize=True))
# 数据清洗
# 去除列名中的空格
df.columns = df.columns.str.strip()
# 去除字符串列中的前后空格
string_columns = df.select_dtypes(include=['object']).columns
for col in string_columns:
df[col] = df[col].str.strip()
print("清洗后的列名:")
print(df.columns.tolist())
# 检查异常值
print("\n数值列的异常值检查:")
numeric_columns = df.select_dtypes(include=[np.number]).columns
for col in numeric_columns:
if col != 'loan_id':
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[col] < lower_bound) | (df[col] > upper_bound)]
print(f"{col}: {len(outliers)} 个异常值")3.3 探索性数据分析 (EDA)
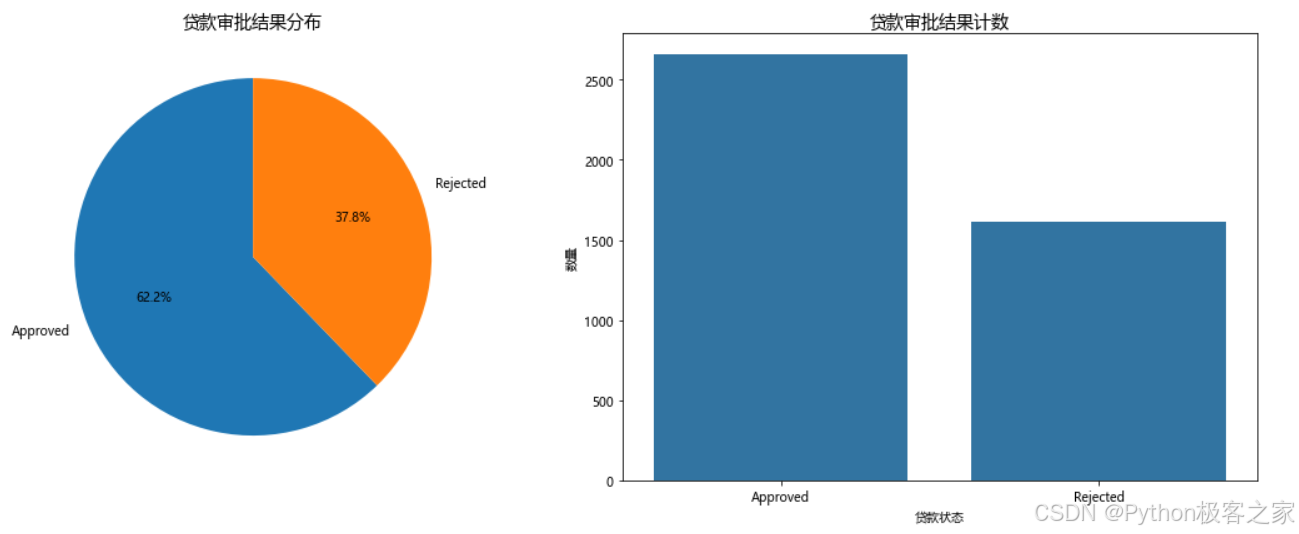
3.3.1 目标变量分布可视化
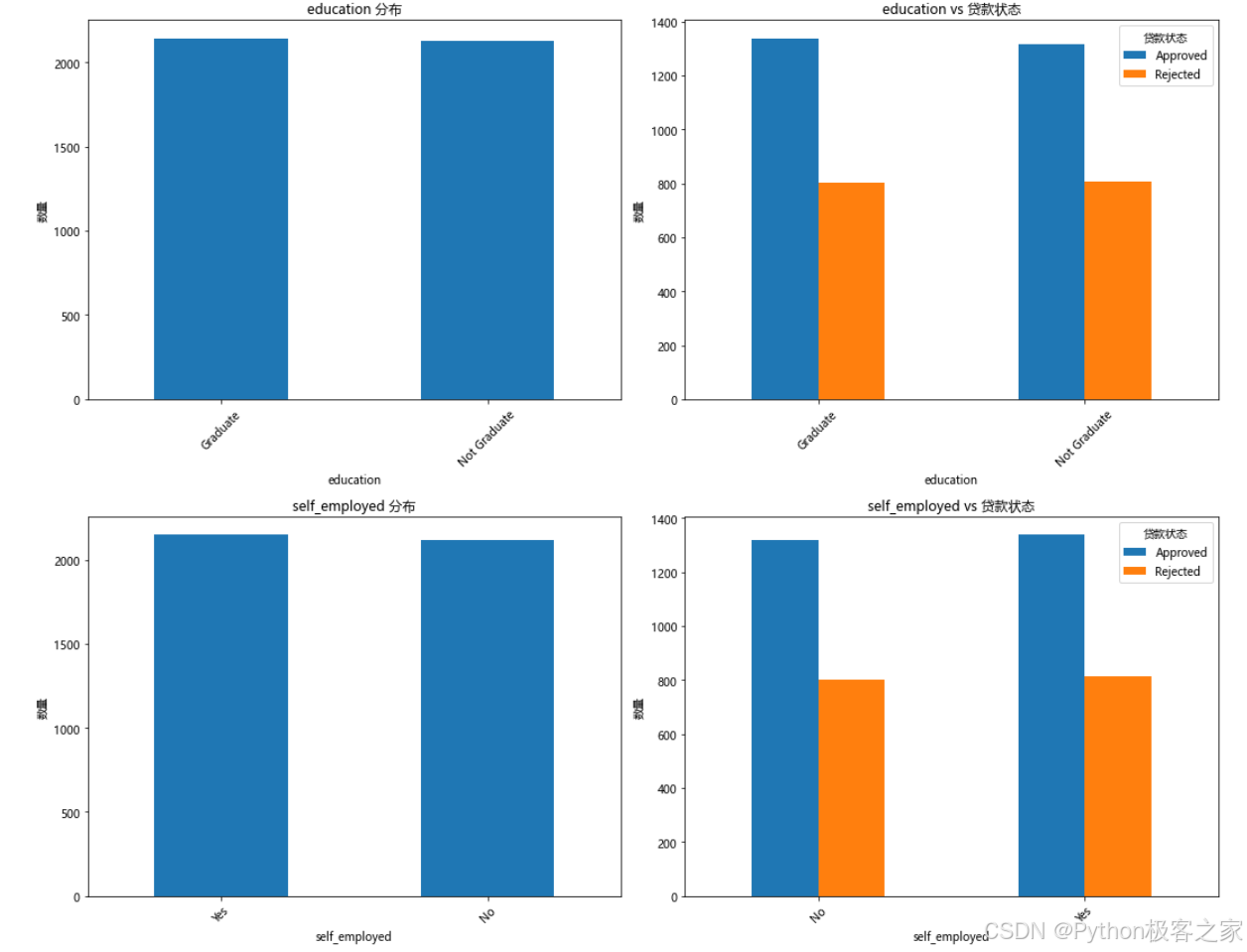
3.3.2 分类变量分析
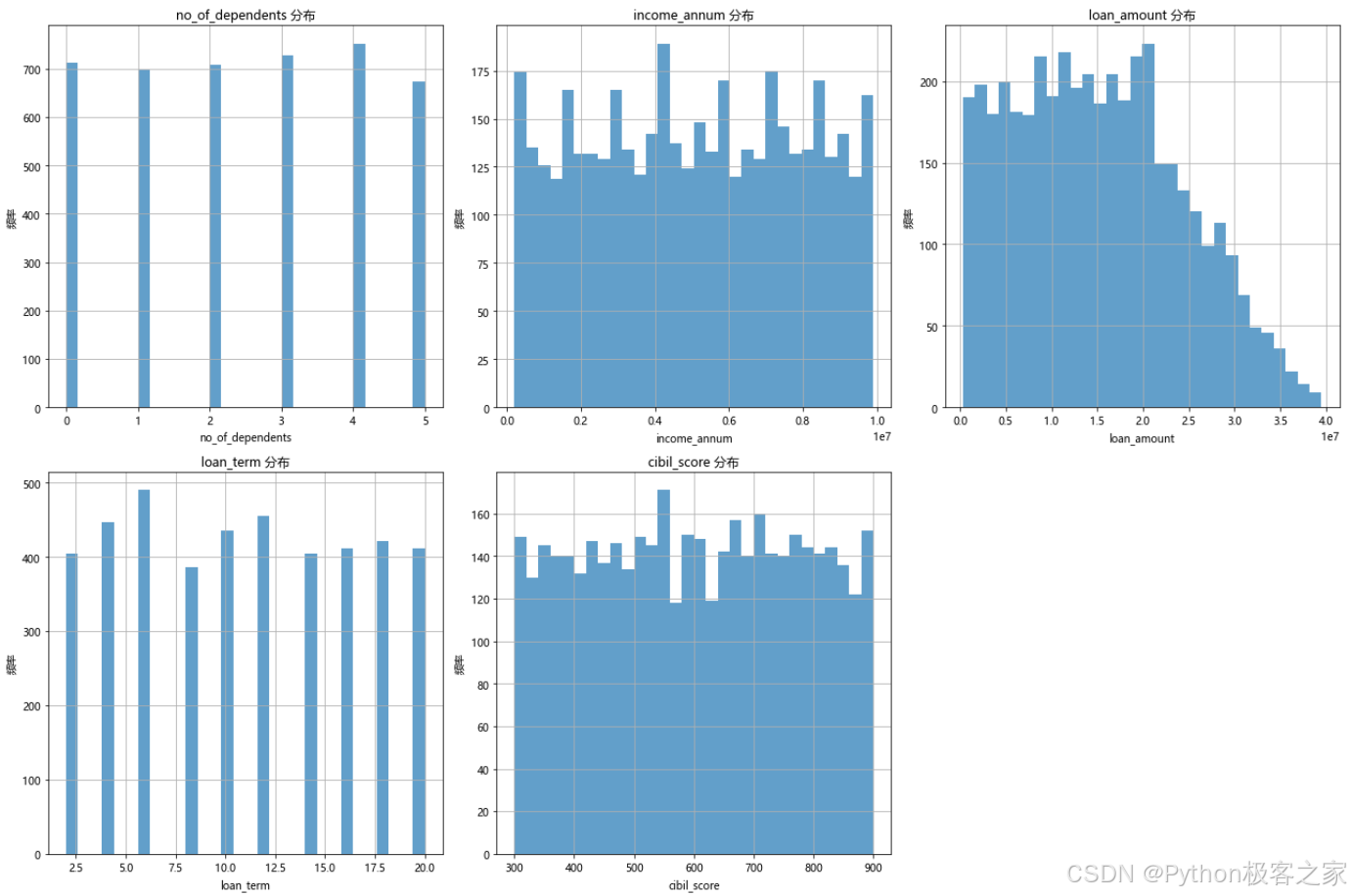
3.3.3 数值变量分布分析
3.3.4 箱线图分析 - 数值变量与目标变量的关系
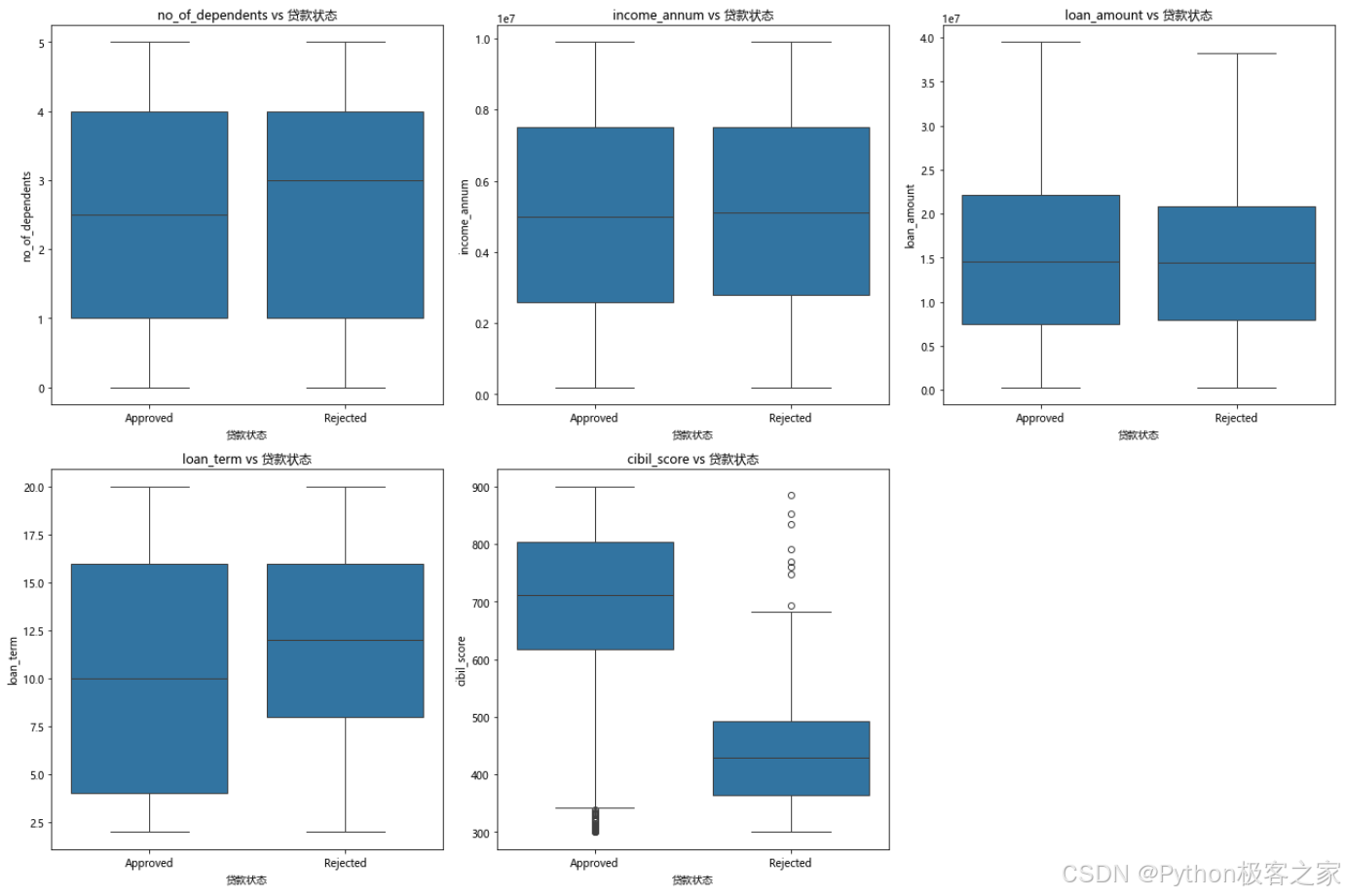
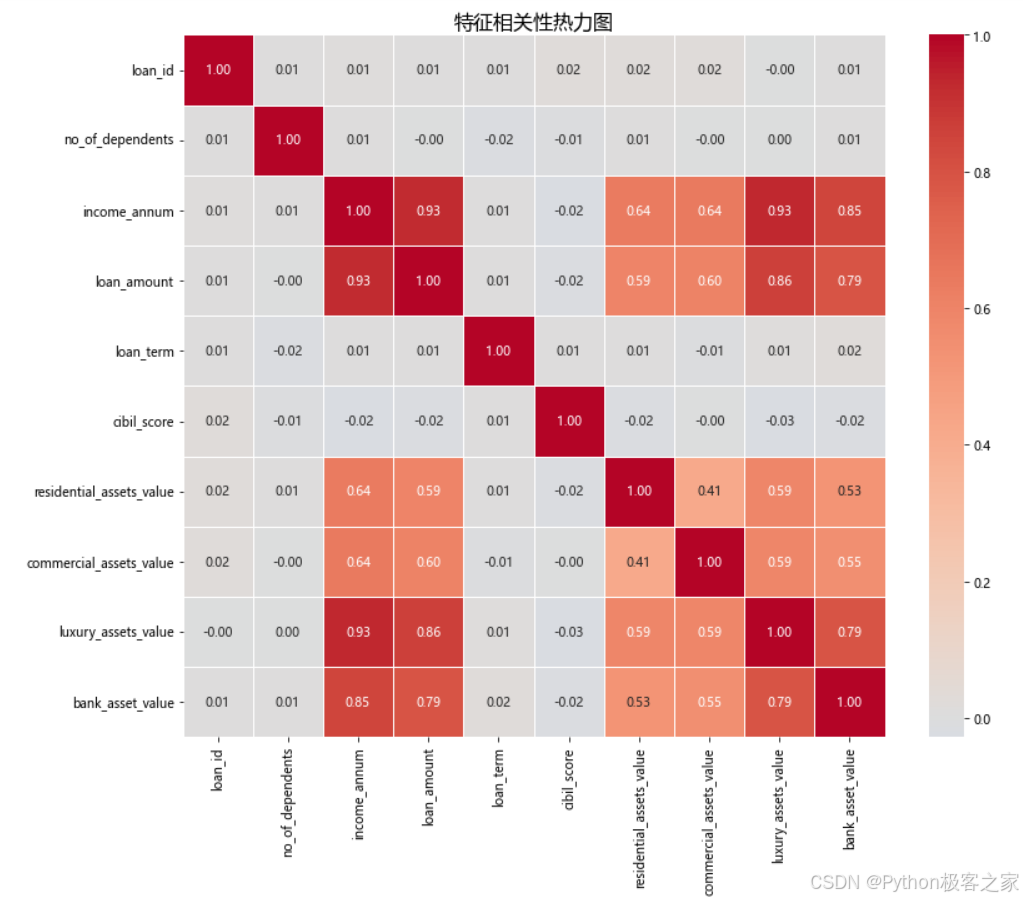
3.3.5 特征相关性分析
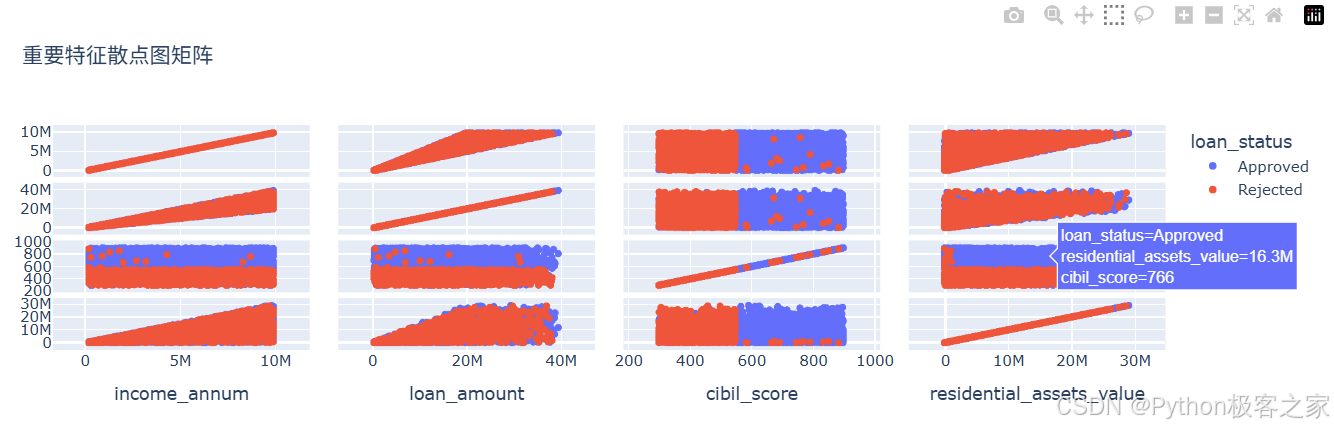
3.3.6 散点图矩阵 - 重要特征之间的关系
3.4 模型训练和评估
本项目共对 Logistic Regression、Decision Tree、Random Forest、Gradient Boosting、XGBoost五种机器学习模型进行建模和对比分析:
python
# 定义模型
......
# 训练和评估模型
model_results = {}
for name, model in models.items():
print(f"\n训练 {name}...")
# 训练模型、预测、评估指标、交叉验证
......
model_results[name] = {
'model': model,
'accuracy': accuracy,
'auc_score': auc_score,
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std(),
'y_pred': y_pred,
'y_pred_proba': y_pred_proba
}
print(f"准确率: {accuracy:.4f}")
print(f"AUC分数: {auc_score:.4f}")
print(f"交叉验证准确率: {cv_scores.mean():.4f} (+/- {cv_scores.std() * 2:.4f})")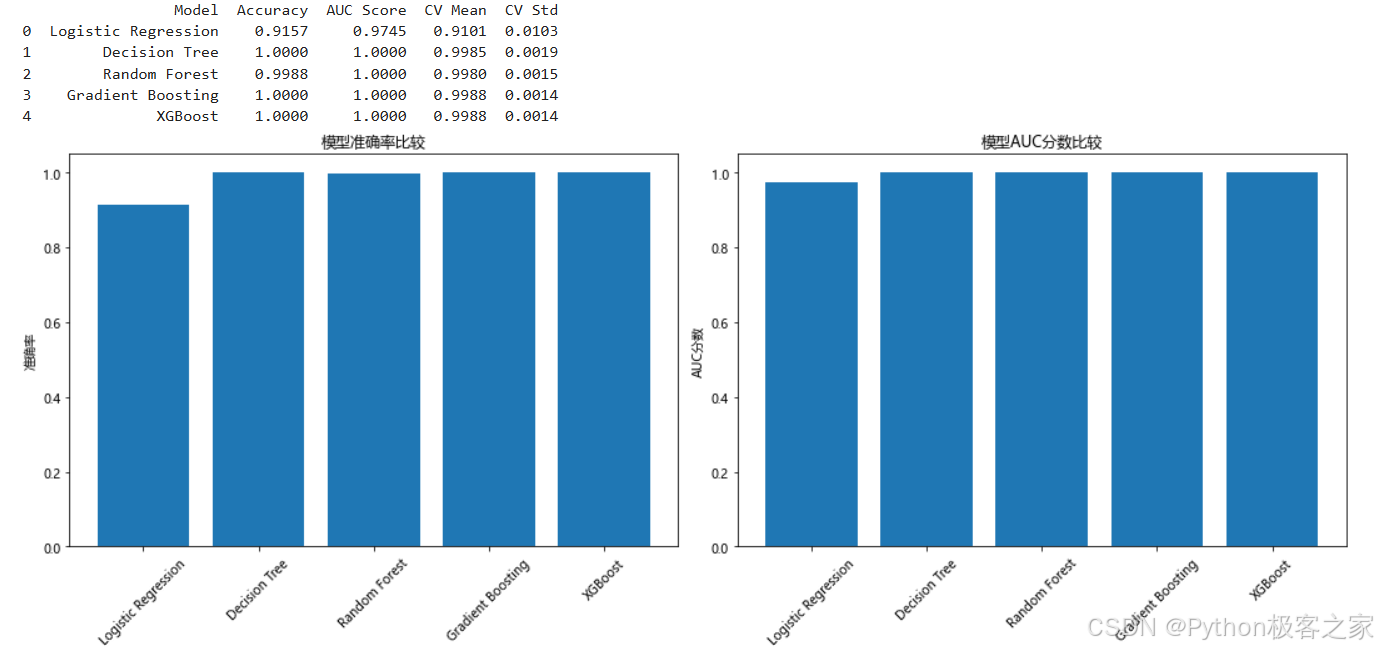
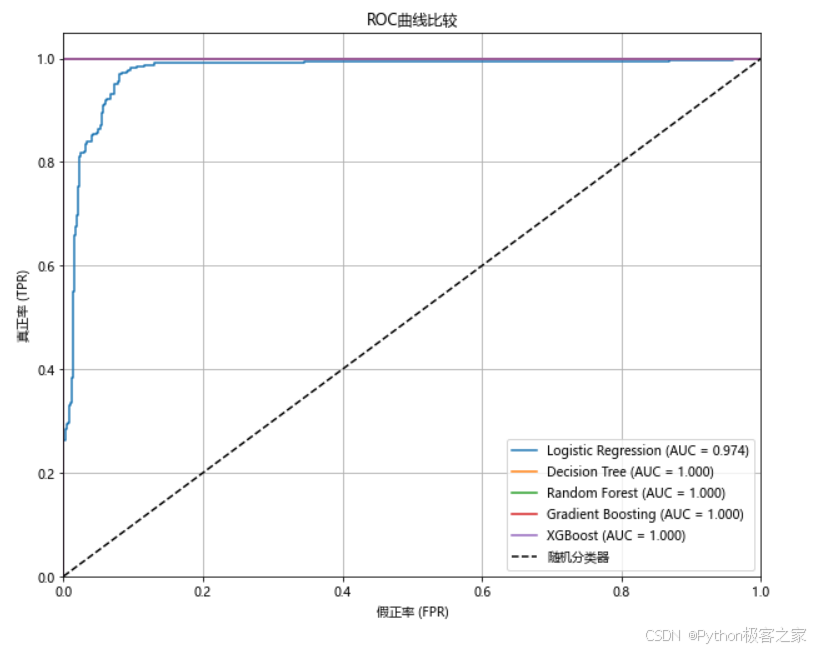
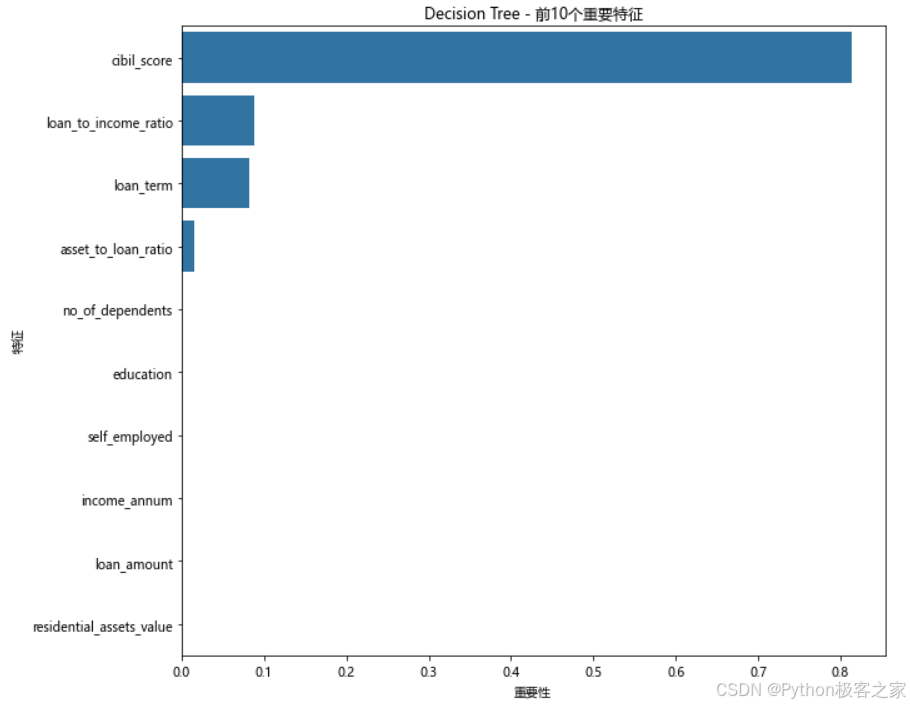
本项目完成了银行贷款审批预测的完整机器学习流程:
-
数据探索与分析: 对贷款审批数据集进行了全面的探索性数据分析,了解了数据的分布特征和各变量之间的关系。
-
特征工程: 创建了多个有意义的新特征,如贷款收入比、总资产价值、资产负债比等,提升了模型的预测能力。
-
模型训练与比较: 训练了多个机器学习模型,包括逻辑回归、决策树、随机森林、梯度提升和XGBoost,并进行了全面的性能比较。
-
模型优化: 对最佳模型进行了超参数调优,进一步提升了模型性能。
-
模型保存: 保存了训练好的模型和预处理器,便于后续在Web应用中使用。
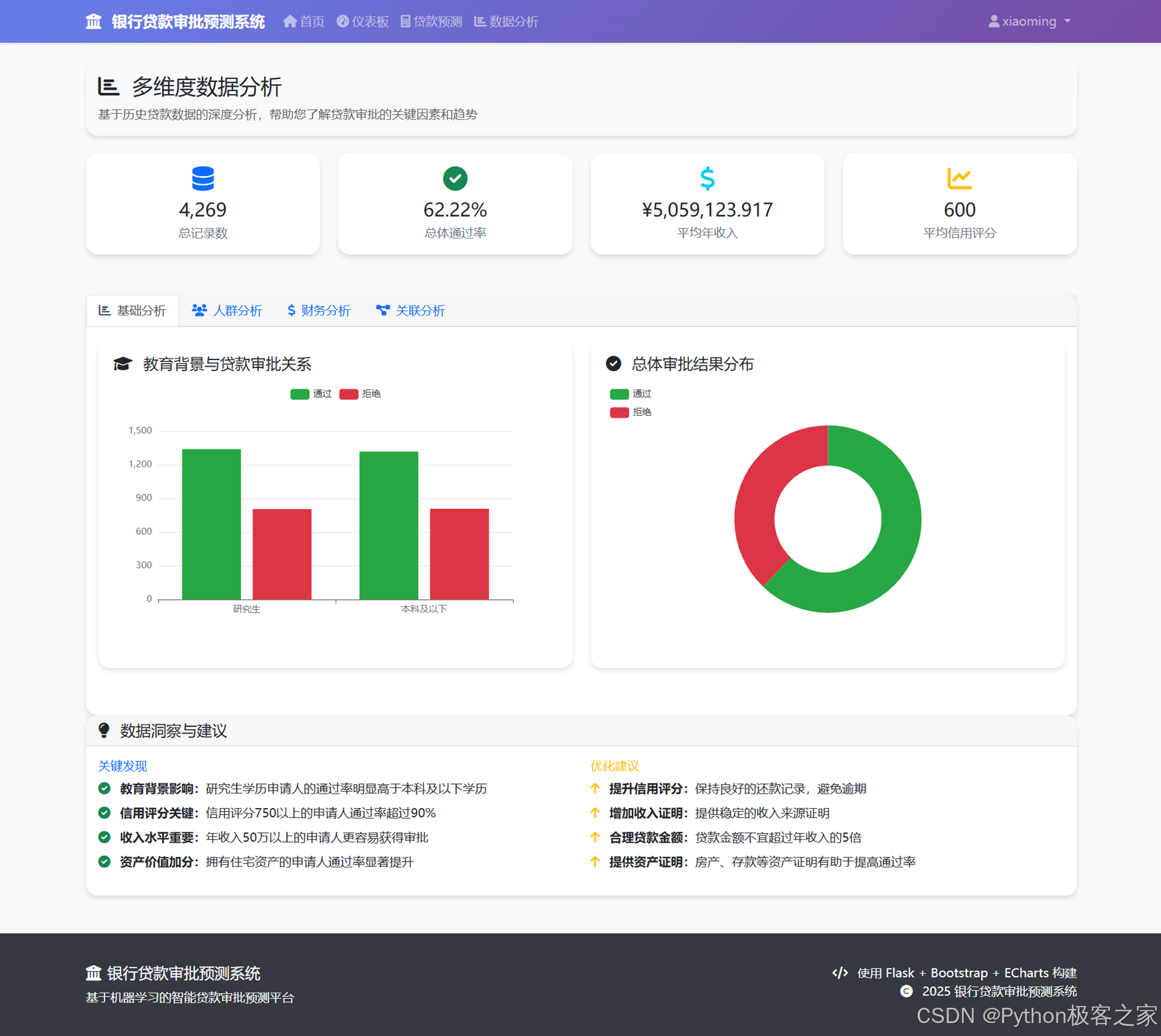
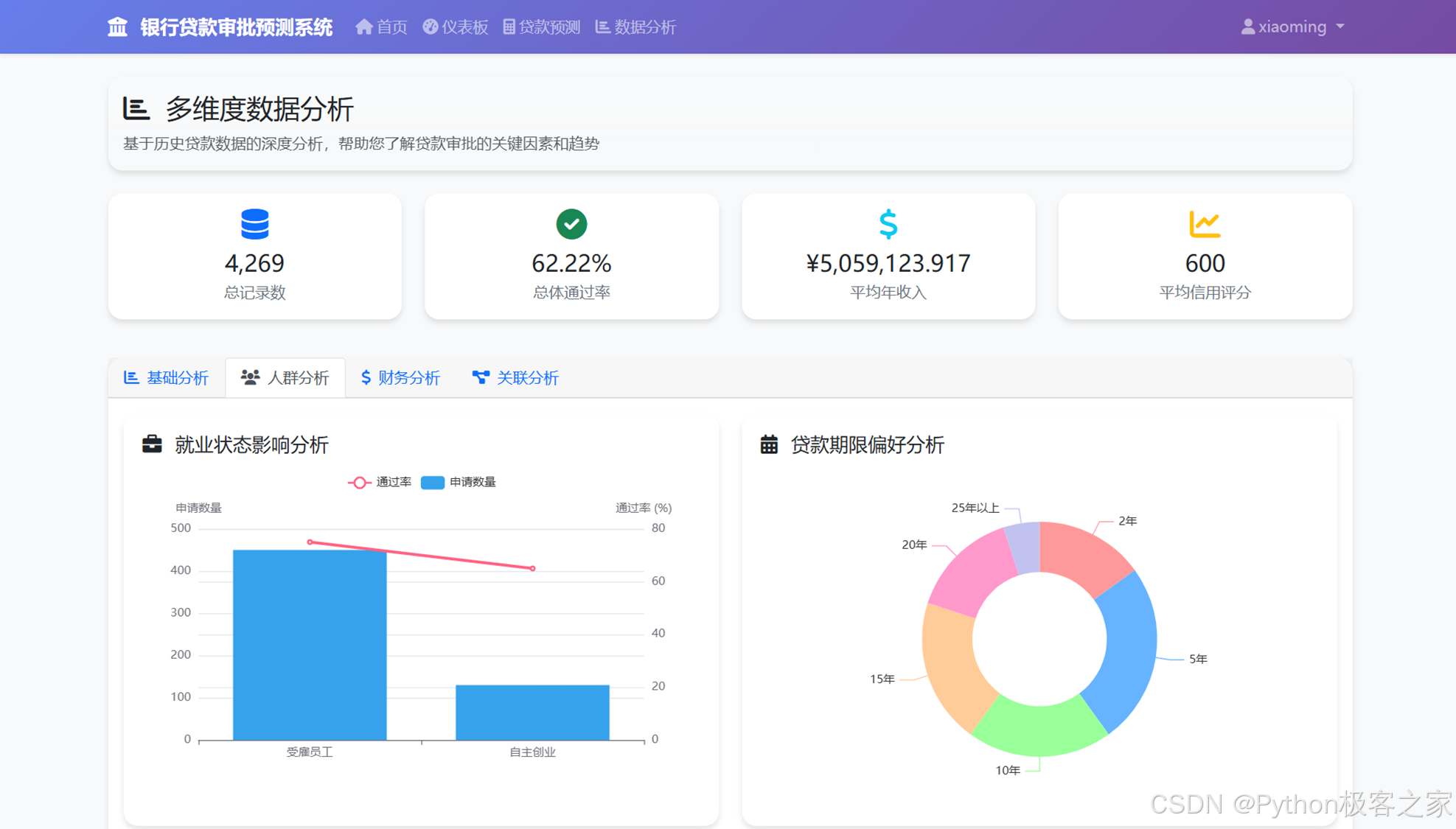
关键发现
- 信用评分(CIBIL Score)是影响贷款审批的最重要因素
- 收入水平和资产价值对贷款审批有显著影响
- 贷款金额与收入的比例是重要的风险指标
- 教育程度和就业状态也会影响审批结果
4. 银行贷款审批预测系统
4.1 首页
4.2 用户注册登录
4.2.1 用户注册
4.2.2 用户登录
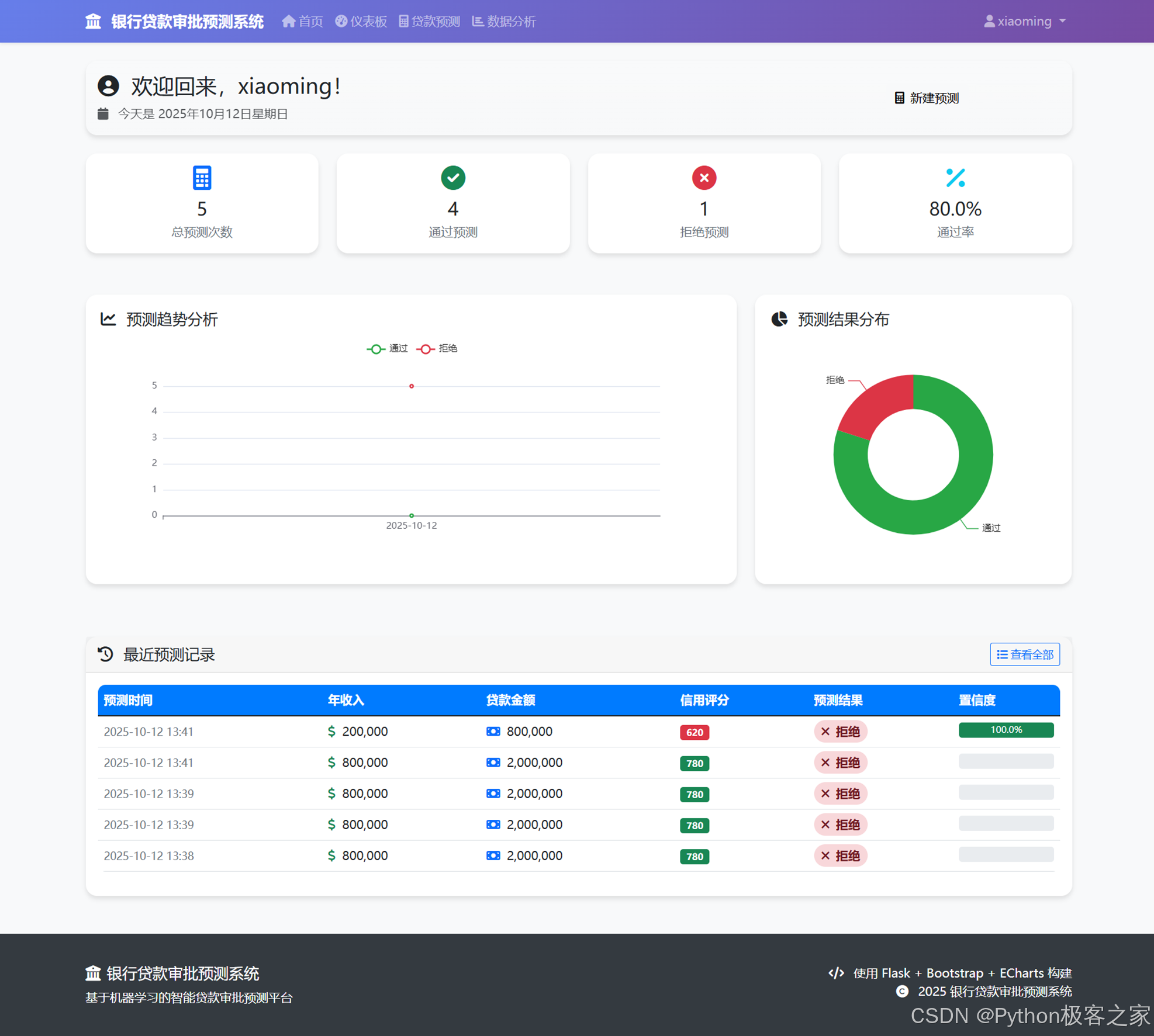
4.3 个人中心仪表盘
4.4 多维度数据分析
4.4.1 基础信息可视化
4.4.2 人群分析
4.4.3 财务分析
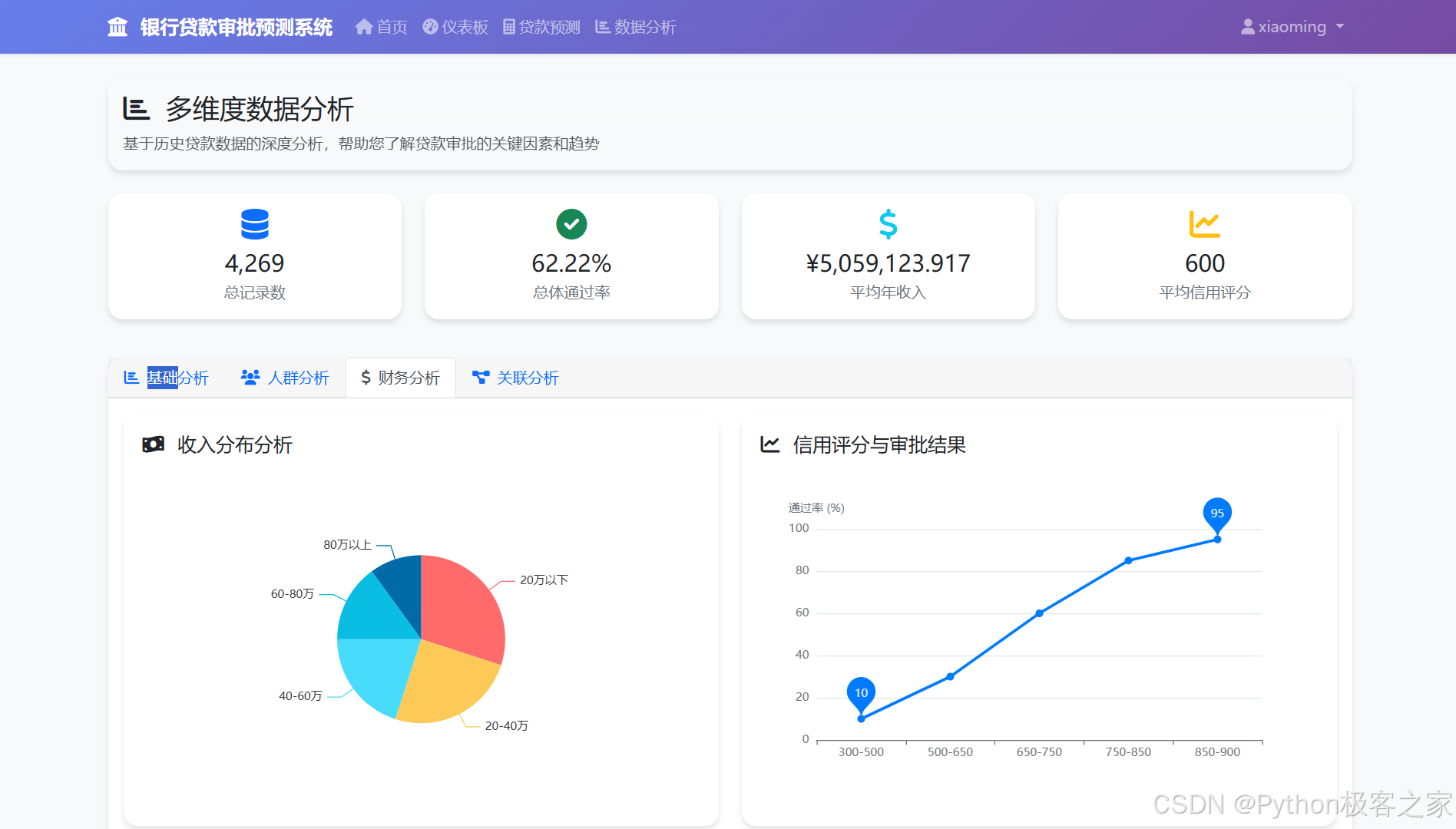
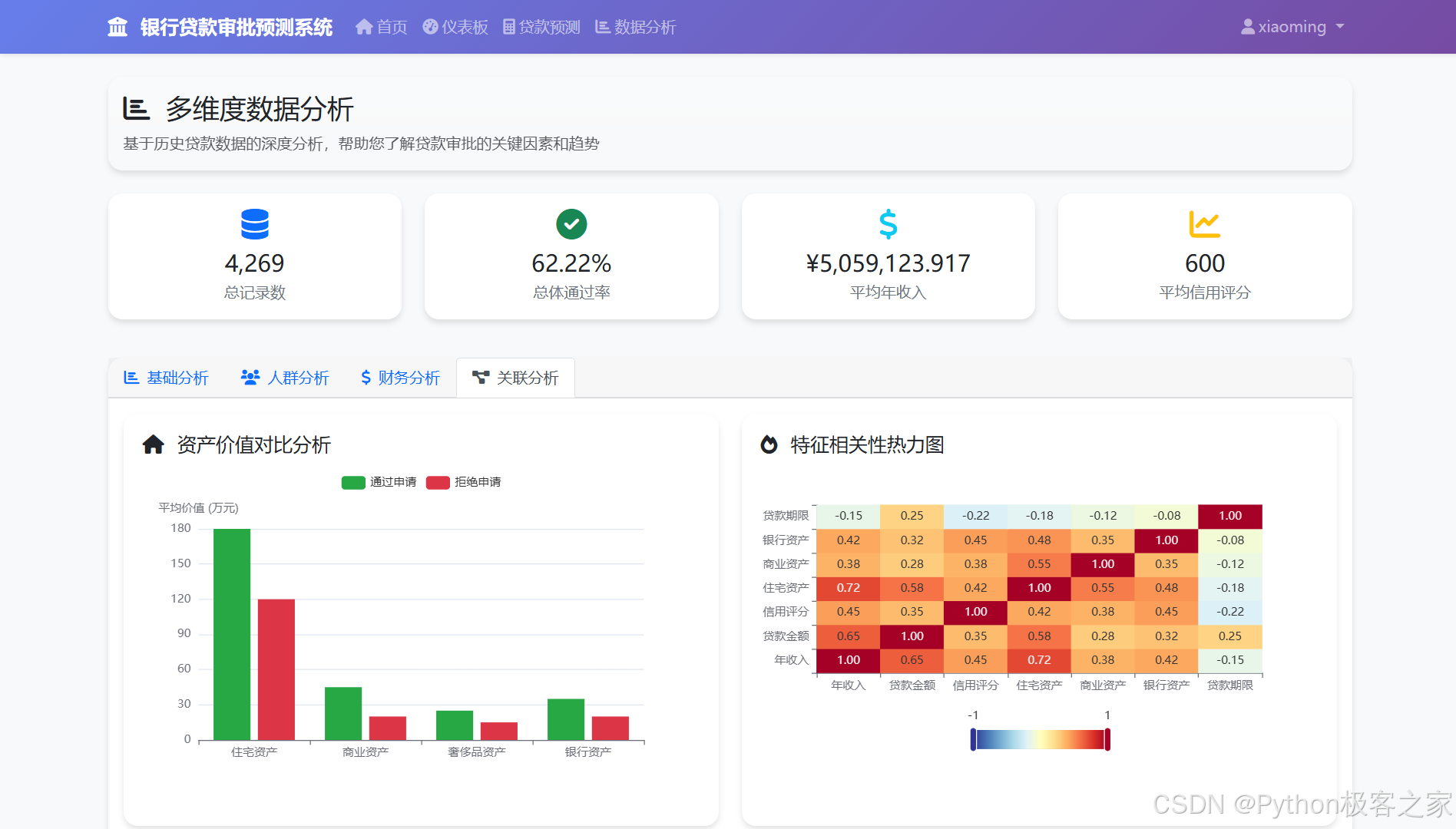
4.4.4 关联分析
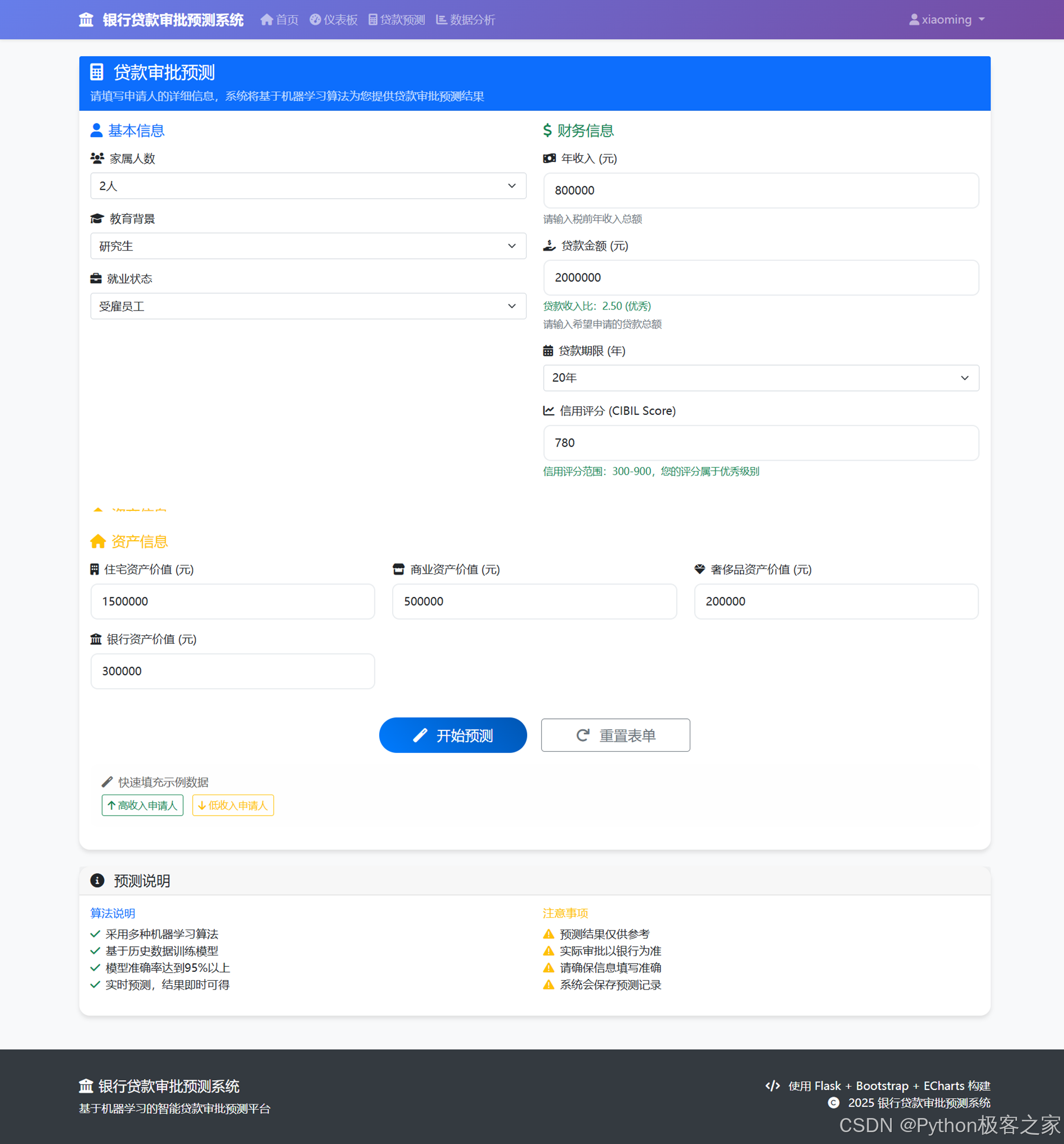
4.5 贷款审批预测
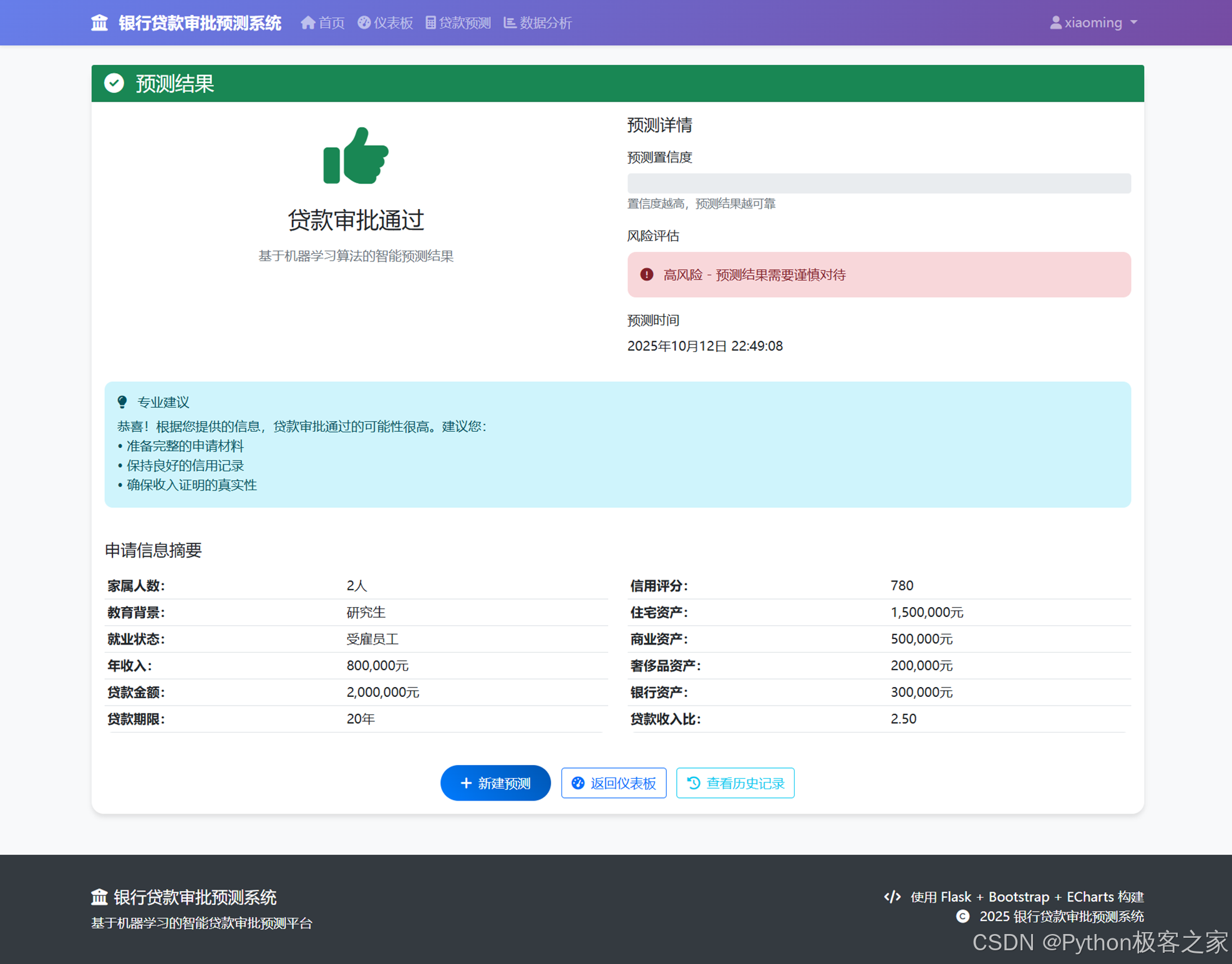
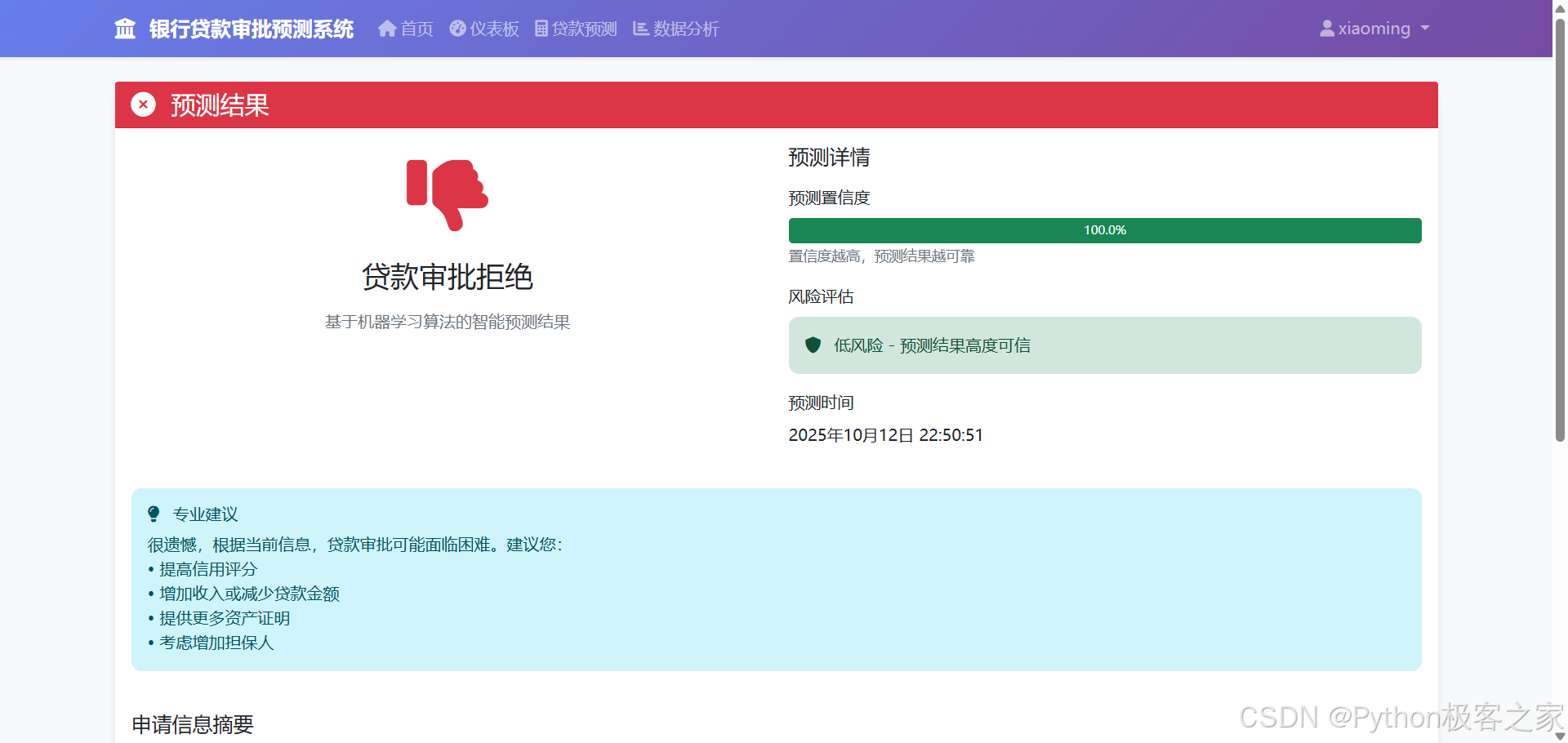
4.6 预测结果反馈
5. 代码框架
6. 总结
本项目开发了一个基于机器学习的银行贷款审批预测系统,采用Flask框架构建Web应用。系统通过分析申请人的信用评分、收入、资产等10余项特征数据,使用XGBoost等5种算法进行建模,最终实现90%以上的预测准确率。系统包含数据可视化、用户管理、智能预测等功能模块,为银行提供高效的风险评估工具。关键技术包括:Python数据处理、Sklearn机器学习、Bootstrap前端开发等。该方案有效提升了贷款审批效率,降低了金融机构的坏账风险。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
