本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。

谷歌云(Google Cloud)于近期发布了一份长达60余页的纲领性文件------《初创公司技术指南:AI Agents》。这并非又一份高谈阔论的行业白皮书,而是一份深入工程实践、充满"代码味"的全栈技术路线图。它系统性地回答了当前所有AI Agent开发者面临的核心挑战:如何从一个充满潜力的原型(Prototype),走向一个稳定可靠、可规模化、负责任的生产级(Production-ready)系统?
这份指南的核心论点是:构建真正有价值的AI Agent,早已超越了模型选型和提示词工程的范畴,它是一门新兴的、跨领域的工程学科 。谷歌为此提出了一个以 Agent Development Kit (ADK) 为核心,以 Vertex AI Agent Engine 为部署底座,以 AgentOps 为运维理念的完整、自洽的技术体系。
本文将对这份重磅指南进行深度编译,旨在为所有大模型领域的技术从业者、创业者和研究者,清晰地呈现谷歌在AI Agent领域的战略布局与最佳实践。
原文可下载:在智泊AI。
核心框架概览
在深入细节之前,我们首先提炼出这份指南所构建的AI Agent技术栈的核心支柱:
- 三大路径 :指南明确了企业与Agent生态的三种互动方式------构建自有Agent (Build) 、使用谷歌预置Agent (Use) 、集成伙伴Agent (Partner) ,三者通过开放协议实现互联互通。
- 五大核心组件 :一个完备的Agent由五个关键部分组成:模型 (Models) 作为大脑,工具 (Tools) 作为手脚,编排 (Orchestration) 作为执行功能,数据架构 (Data Architecture) 作为记忆系统,以及运行时 (Runtime) 作为部署环境。
- 一个开发核心:ADK :Agent Development Kit (ADK) 是谷歌开源的、代码优先的智能体开发框架,是整个技术体系的基石,旨在平衡开发速度与灵活性。
- 两大开放协议:MCP & A2A :通过 模型上下文协议 (Model Context Protocol, MCP) 和 智能体互操作协议 (Agent2Agent, A2A) ,谷歌致力于构建一个开放、可互操作的Agent生态系统,打破框架和平台的壁垒。
- 一个运维理念:AgentOps:将 DevOps 和 MLOps 的思想应用于Agent开发,形成一套系统性的评估、监控和迭代方法论,确保Agent在生产环境中的可靠、安全与合规。
- 一个关键技术:高级RAG :指南强调了"接地"(Grounding)的重要性,并阐述了从基础的 RAG ,到 GraphRAG ,再到具备动态推理和检索能力的 Agentic RAG 的演进路径。
第一部分: AI Agent的核心概念解析
任何成功的工程实践都源于对核心概念的深刻理解。指南的第一部分系统性地拆解了构成一个生产级AI Agent所需的所有基础组件。
Agent生态系统:构建、使用与合作
谷歌云将Agent生态系统划分为三个层次,并通过 MCP 和 A2A 协议实现它们之间的互操作性。
- 构建你自己的Agents (Build your own agents) :
-
- 代码优先 (Code-first) :使用 Agent Development Kit (ADK) ,为需要高度控制Agent行为的开发者和技术团队提供最大的灵活性。
- 应用优先 (Application-first) :使用 Google Agentspace,这是一个低代码/无代码平台,使非技术团队成员也能构建和部署Agent,打破数据孤岛。
- 使用谷歌云Agents (Use Google Cloud agents) :
-
- Gemini Code Assist:面向开发者的AI助手,深度集成于IDE、CLI和GitHub等开发流程中。
- Gemini Cloud Assist:面向Google Cloud环境的AI专家,帮助进行基础设施管理、故障排查和成本优化。
- Gemini in Colab Enterprise:面向数据科学家的AI工作空间,加速数据分析、模型实验和代码生成。
- 引入合作伙伴Agents (Bring in partner agents) :通过Google Cloud Marketplace和Agent Garden,集成第三方或开源的专用Agent,丰富自身应用生态。
关键组件剖析
1. 模型 (Models): Agent的大脑
选择模型并非总是追求最强,而是在能力、速度和成本之间找到特定任务的最优解。指南建议采用分层策略:
- 轻量级模型 (如 Gemini 2.5 Flash-Lite) :用于早期原型设计和高并发、低延迟的任务(如分类、翻译)。
- 平衡型模型 (如 Gemini 2.5 Flash) :在质量、成本和速度之间取得平衡,适用于大多数生产级应用。
- 高级模型 (如 Gemini 2.5 Pro) :用于需要复杂多步推理和前沿代码生成的非结构化任务,此时性能是不可妥协的。
指南强调,强大的认知架构通常采用多个专用Agent,每个Agent根据其子任务动态选择最高效的模型。
2. 工具 (Tools): Agent的手脚
工具是Agent与外部世界交互、执行具体操作的桥梁。它可以是:
- 内部函数与服务:团队编写的专有业务逻辑。
- APIs:连接内部或第三方服务。
- 数据源:查询数据库、向量存储等。
- 其他Agents:在一个多Agent系统中,一个Agent可以将另一个专用Agent作为其工具来使用。
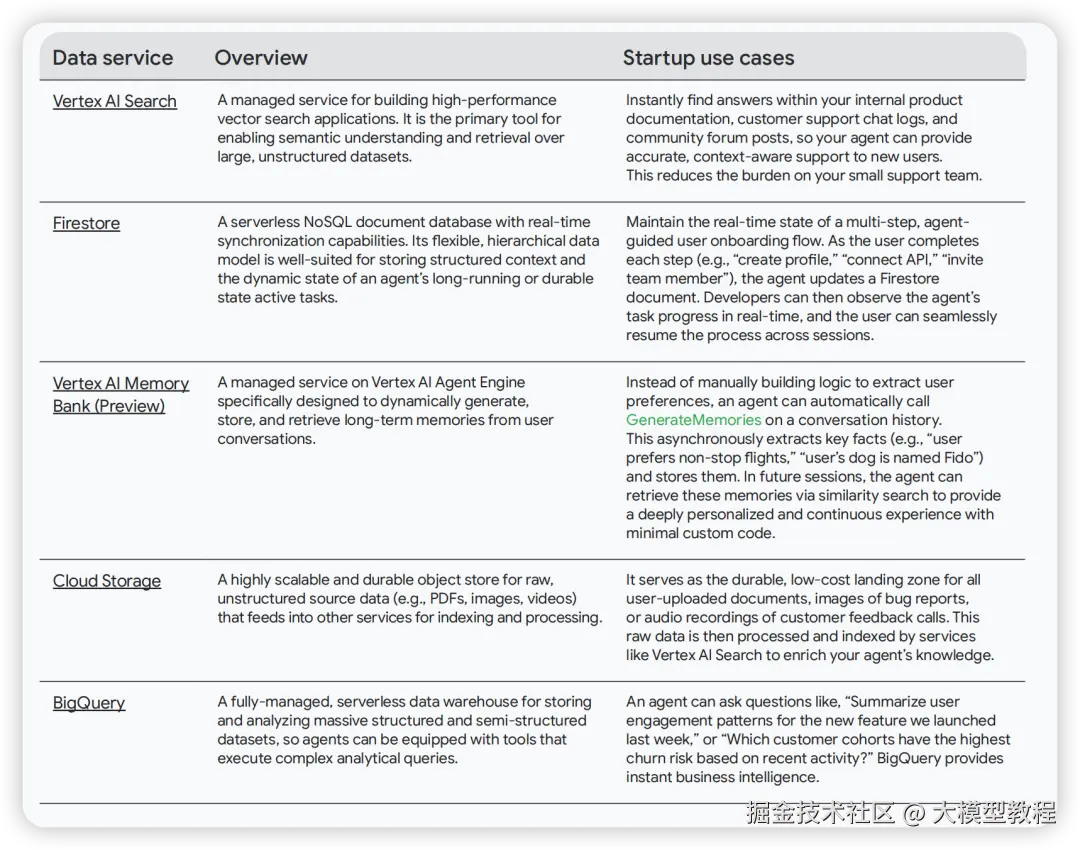
3. 数据架构 (Data Architecture): Agent的记忆
一个强大的Agent必须拥有可靠的记忆系统。指南将其划分为三个层次:
- 长期知识库 (Long-term knowledge base - Grounding & Retrieval) :这是Agent智能、事实性和个性化的基础。
-
- Vertex AI Search: 用于大规模非结构化数据的语义理解和检索(RAG的核心)。
- Firestore: NoSQL数据库,适合存储Agent任务的动态状态和用户交互历史。
- Vertex AI Memory Bank (Preview) : 专为动态生成、存储和检索用户对话中的长期记忆而设计。
- Cloud Storage: 作为原始非结构化数据(PDF、图片等)的持久化存储层。
- BigQuery: 用于复杂分析查询,为Agent提供深度业务洞察力。

Google Big Query 费用优化内部指南
- 工作记忆 (Working memory - Conversational context & short-term state) :管理当前对话或任务所需的瞬时信息,要求极低的延迟。
-
- Memorystore: 基于内存的数据存储,提供亚毫秒级延迟,非常适合缓存高成本操作(如LLM调用、复杂数据库查询)的结果。

- 事务记忆 (Transactional memory - State management & action auditing) :以强一致性和完整性记录关键操作和状态变更,是系统的可信记录。
-
- Cloud SQL: 为单区域事务性工作负载提供强一致性的关系型数据库。
- Cloud Spanner: 全球分布式的、强一致性的关系型数据库,专为需要跨地域高可用和事务完整性的关键应用设计。

4. 编排 (Orchestration): Agent的执行功能
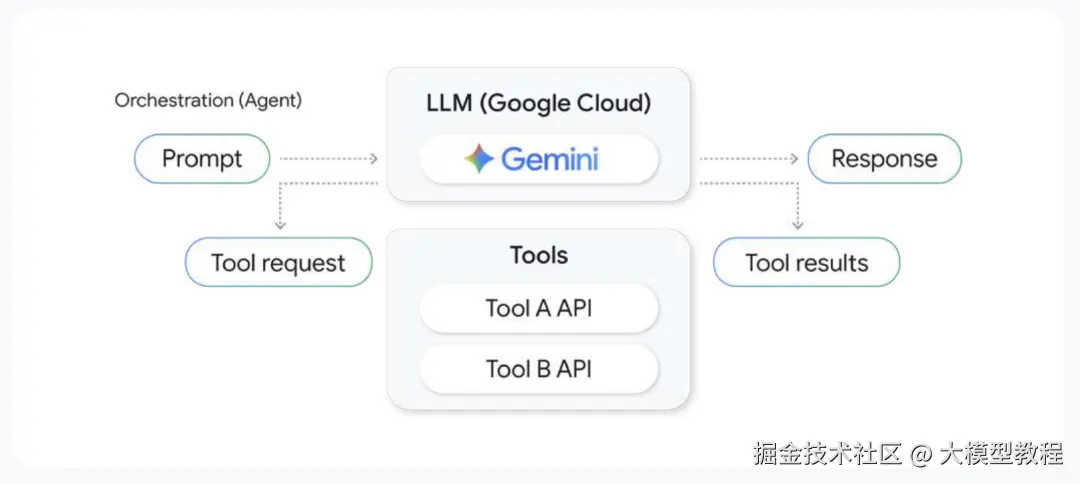
编排是指导Agent完成多步任务的核心逻辑。它决定了需要调用哪些工具、以何种顺序、以及如何组合它们的输出。
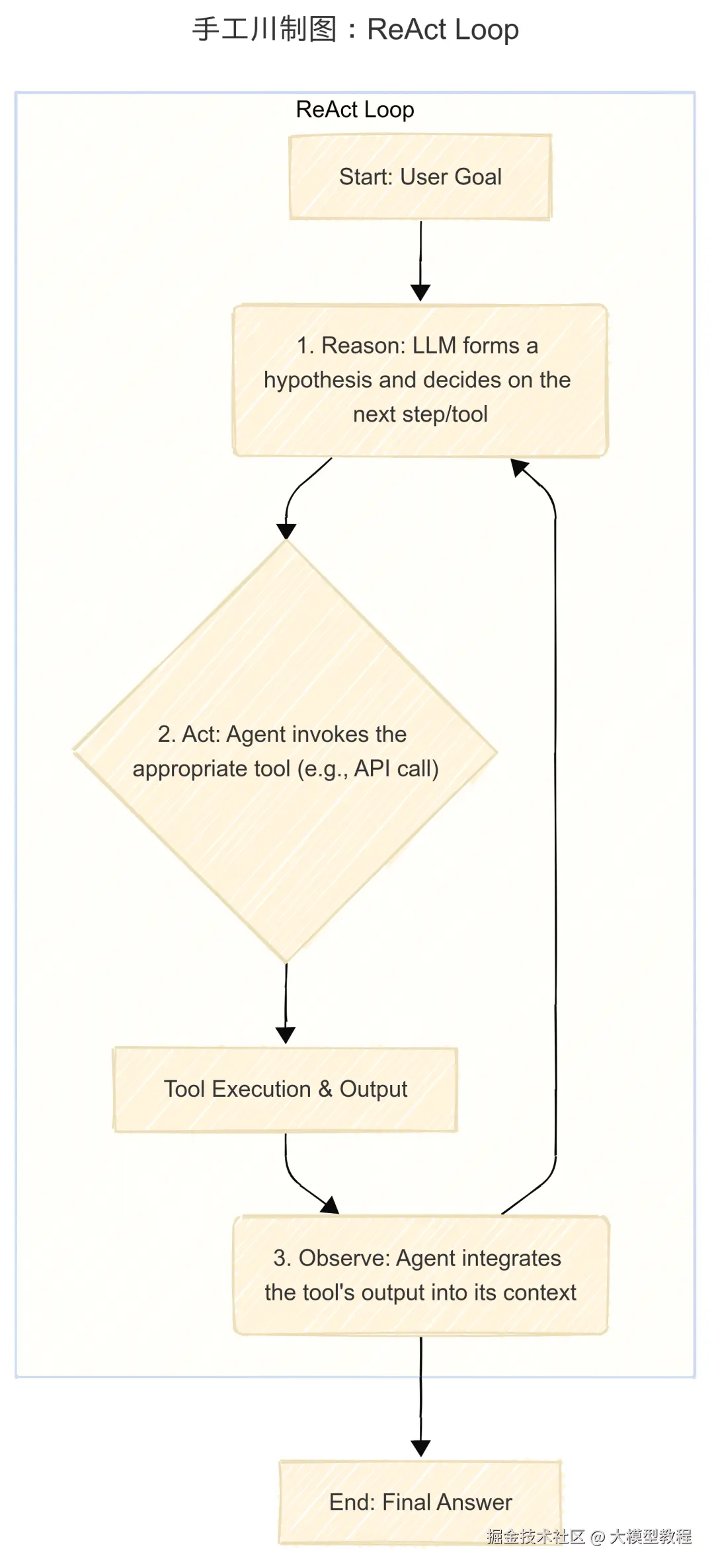
ReAct 框架 (Reason + Action)
ReAct 是由谷歌大脑团队提出的一个经典Agent认知框架,它将大语言模型的"推理"能力和"行动"能力协同起来。Agent 在一个动态的循环中交替生成推理轨迹(thoughts)和任务特定的行动(actions) 。推理帮助模型追踪和更新计划,而行动则从外部工具(如API)中收集信息,以反馈给下一步的推理。这种"思考-行动-观察"的循环模式,极大地增强了Agent解决复杂问题的能力。
指南以 ReAct (Reason + Action) 框架为例,阐述了其工作原理:
5. 运行时 (Runtime): Agent的规模化部署
将Agent原型部署到生产环境需要一个强大的运行时基础设施,指南列出了三个主要选项:
- Vertex AI Agent Engine:为初创团队和小团队设计的全托管、自动伸缩的服务,能将原型在数天内变为可扩展、安全的生产端点。
- Cloud Run:适用于经历快速但不可预测增长的场景,其无服务器架构能有效处理流量峰值,并按实际使用付费。
- Google Kubernetes Engine (GKE) :对于拥有成熟平台工程团队和现有Kubernetes基础设施的公司,GKE提供了最精细的控制粒度,支持复杂的微服务应用。
接地 (Grounding): Agent可信度的基石
Agent的可信度取决于其答案是否基于可验证的事实。指南深入探讨了从基础到前沿的"接地"技术演进。
RAG: 奠基性的第一步
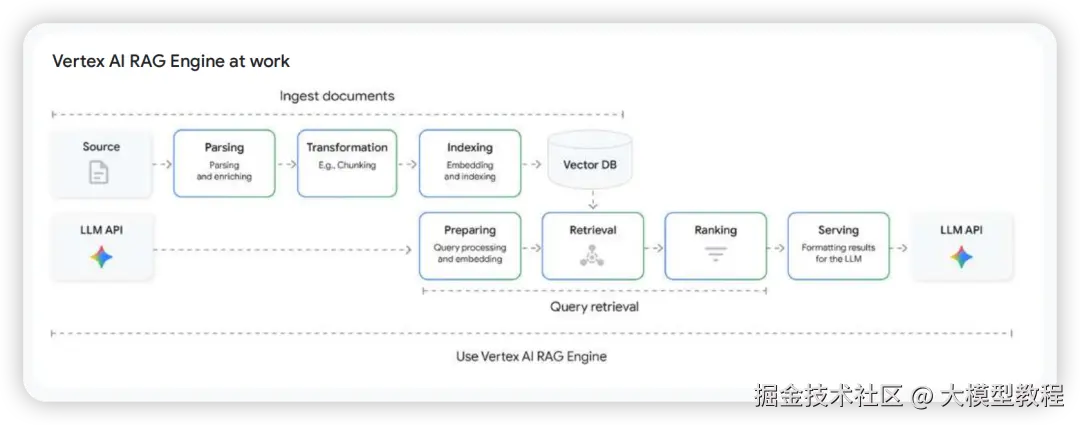
检索增强生成 (Retrieval-Augmented Generation, RAG) 是最基础的接地模式。它通过在生成答案前从外部知识库检索相关信息,并将其作为上下文注入到LLM中,从而有效减少幻觉,并使Agent能够访问最新信息。
GraphRAG: 更智能的接地
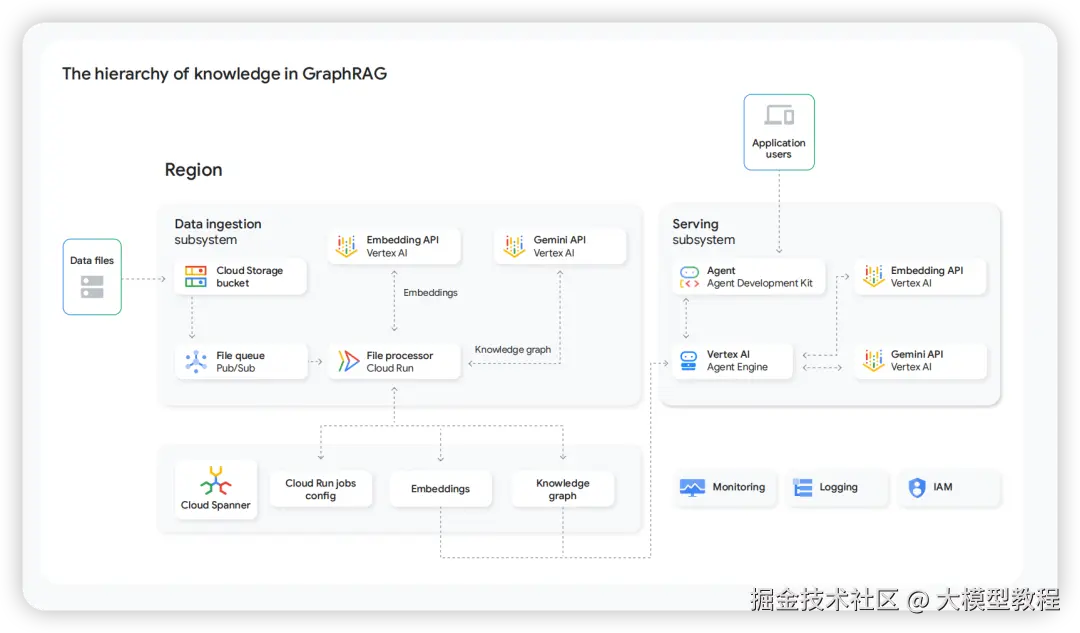
GraphRAG通过构建知识图谱,让Agent不仅能匹配相似的文本片段,更能理解概念之间的关系(例如:"症状 -> 原因 -> 治疗方法"),实现更深层次的、结构化的知识检索。
Agentic RAG: 动态推理与检索
这是接地技术的最终形态。Agentic RAG将Agent从一个被动的数据接收者,转变为一个主动的、有推理能力的知识探索者。Agent能够分析复杂查询,自主制定一个多步骤、多工具的检索计划,并顺序执行,以找到最佳信息。例如,一个Agent可以:
- 分析一张植物照片以识别其物种。
- 然后自主检索该物种的详细养护说明。
- 最后综合信息给出一个完整的、有事实依据的回答。
第二部分: 如何构建AI Agent
本部分聚焦于实践,详细介绍了以ADK为核心的Agent构建工具链。
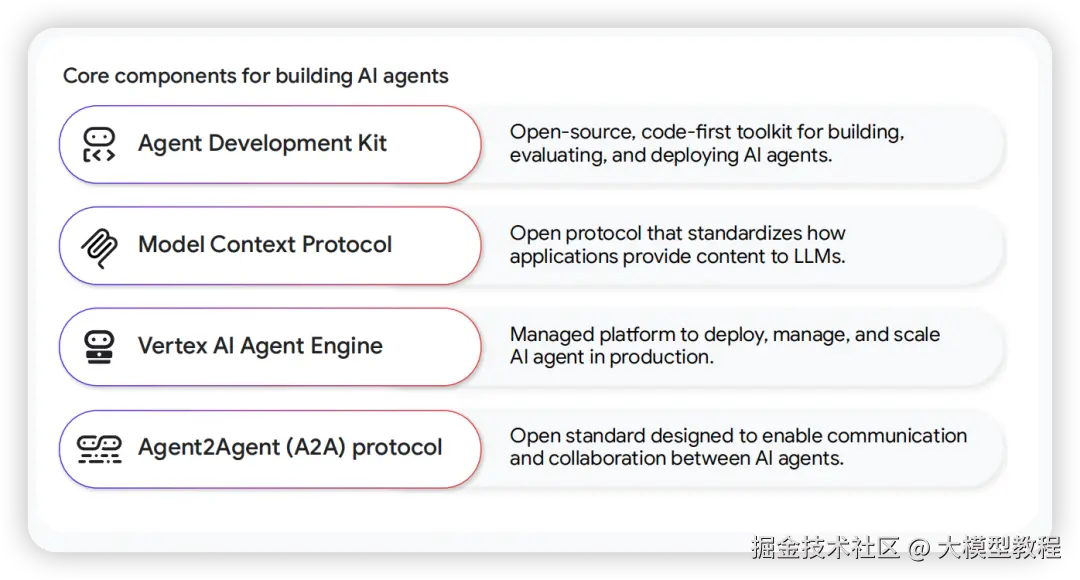
ADK (Agent Development Kit): 完整的构建工具箱
ADK是一个开源的、代码优先的工具包,用于构建、评估和部署AI Agent。它位于低代码平台和完全从零构建之间,旨在为开发者提供最佳的灵活性与效率平衡点。
谷歌 ADK (Agent Development Kit)
ADK 是谷歌开源的一套用于构建AI Agent的框架。与LangChain等通用框架不同,ADK在设计上更侧重于与Google Cloud生态系统的深度集成、多Agent协作的标准化(通过A2A协议),以及对生产环境运维(AgentOps)的原生支持。它提供了一套结构化的方式来定义Agent的行为、工具和编排逻辑。
ADK的核心能力包括:
- 构建复杂、协作的AI系统:ADK原生支持多Agent设计,可以轻松构建由多个专用Agent(如"任务分解Agent"、"代码生成Agent")协作完成复杂工作流的系统。
- 集成现有工具与工作流:ADK拥有丰富的工具生态,可以连接Notion、Slack等生产力工具,并能与LangChain、LlamaIndex等框架的工具进行互操作。
- 确保质量与可靠性:内置的可观测性和评估工具,允许开发者在部署前系统地测试Agent在各种场景下的表现,调试其完整的执行轨迹(包括"思考"过程)。
- 自信地规模化:ADK将Agent打包为标准的Web服务(使用FastAPI),可以轻松容器化并部署到任何地方,从本地测试到Vertex AI Agent Engine等全托管运行时。
ADK核心架构:Agent类型
在ADK中,选择正确的Agent架构是第一步。这通常是在LLM的灵活性和硬编码逻辑的确定性之间做权衡。
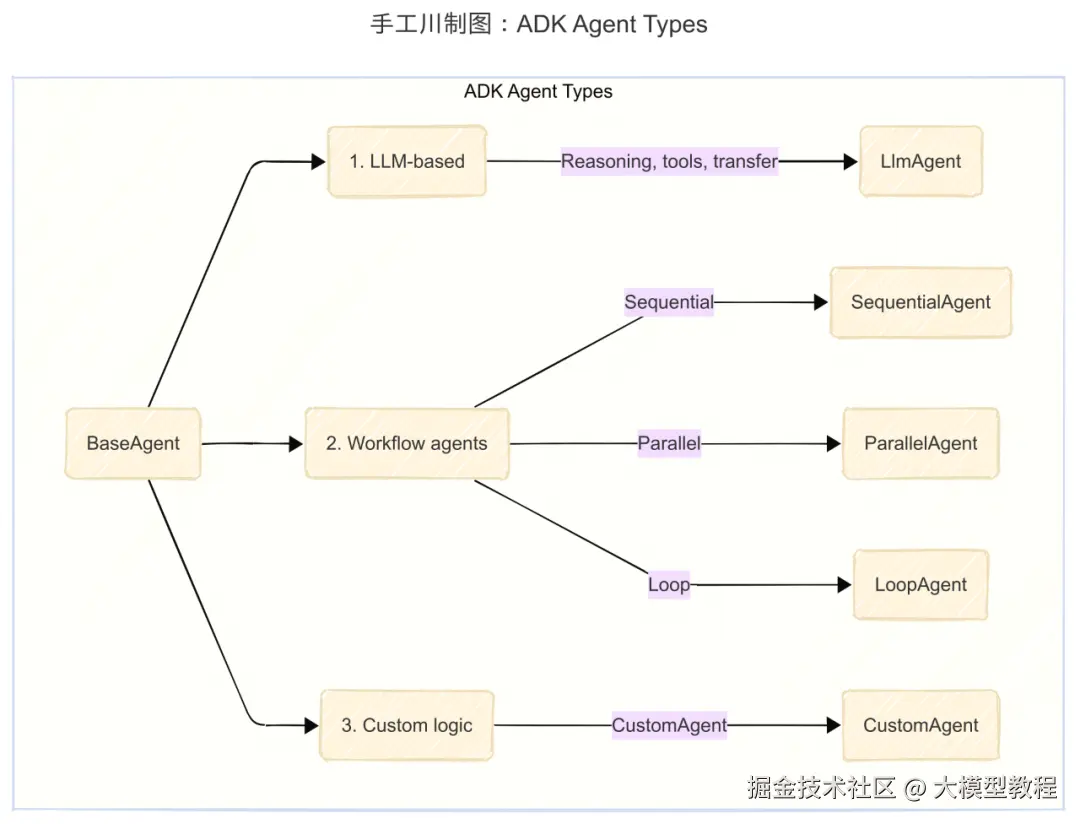
- LLM Agent (LlmAgent) :最常见的类型,使用LLM(如Gemini)进行复杂推理、动态决策和自然语言理解。它是大多数对话式和问题解决型Agent的核心。
- Workflow Agent:这类Agent以预定义的、确定性的模式来编排其他Agent的执行流程。
-
- SequentialAgent:按固定顺序执行子Agent,将前一个的输出作为后一个的输入。
- ParallelAgent:同时执行多个独立的子Agent,用于性能优化。
- LoopAgent:重复执行一系列子Agent,直到满足特定条件或达到迭代次数。
- Custom Agent :通过继承
BaseAgent并编写自定义Python逻辑来控制Agent的行为,适用于那些行为由硬编码规则而非LLM决定的场景。
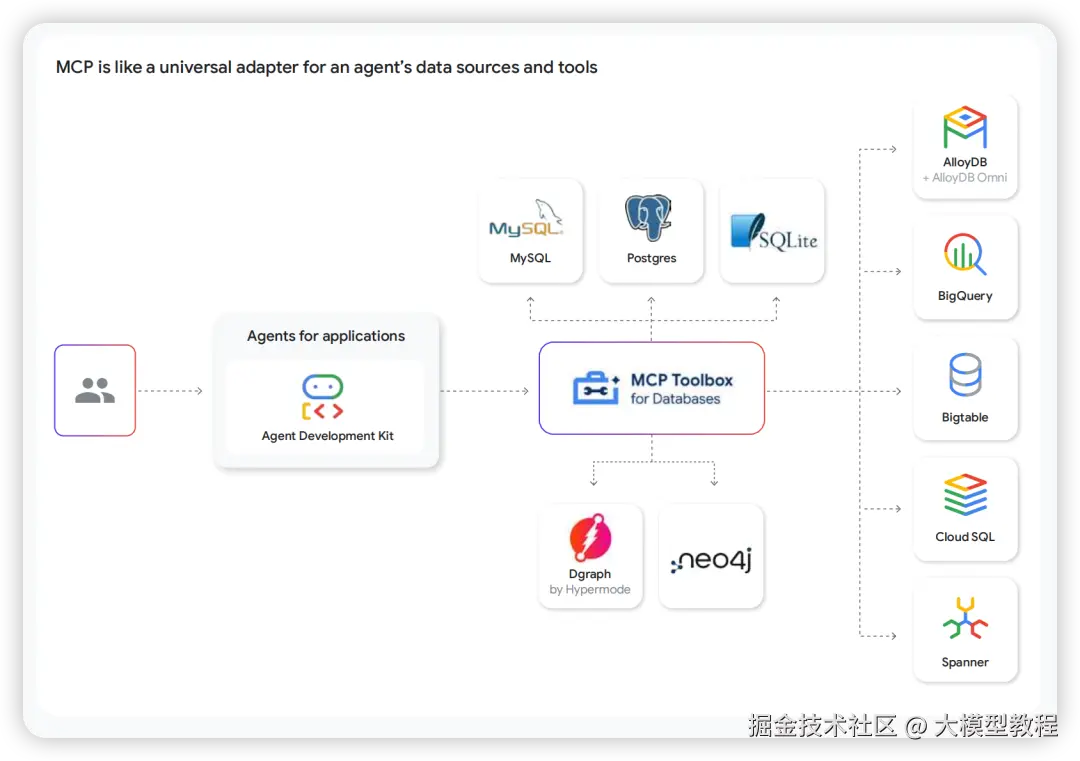
标准化交互:MCP 与 A2A 协议
为了构建一个开放的生态,谷歌大力推广两个开放标准:
MCP (Model Context Protocol) & A2A (Agent2Agent)
- MCP:一个新兴的开放标准,旨在标准化AI/LLM与外部数据源和工具的连接方式。它就像一个通用适配器,让你的Agent可以轻松接入各种数据库和API,而无需为每个都编写定制的集成代码。
- A2A:一个开放标准,旨在实现不同Agent之间的发现、通信和协作,无论它们是由谁构建、使用何种框架。它定义了Agent的"数字名片"(Agent Card)、任务导向的交互架构和多模态通信能力。
这两个协议共同构成了谷歌Agent生态系统的"通用语",确保了无论是谷歌自家的、你自建的还是第三方的Agent,都能够无缝地协同工作。

Google Agentspace:治理与扩展你的Agent团队
当你的创业公司从构建单个Agent发展到部署一个由多个专用Agent组成的"员工队伍"时,管理和治理就成了新的挑战。Google Agentspace 正是为了解决这个问题而设计的平台。它允许你:
- 统一和访问公司数据:通过开箱即用的连接器,打破Sharepoint、Google Workspace、Jira等应用之间的数据孤岛。
- 赋能全员自动化:提供无代码的Agent Designer,让市场、运营等领域的专家可以用自然语言构建自己的自动化工作流。
- 治理和编排Agent舰队:提供一个统一的平台来管理和治理所有来源的Agent(ADK构建的、无代码设计的、合作伙伴的),并通过Agent Gallery进行发现和部署。
第三部分: 确保Agent可靠与负责 (AgentOps)
这是本指南最具价值的部分之一。它直面了LLM系统非确定性带来的挑战,提出了一套严谨的工程方法论来确保Agent的生产级可靠性。
AgentOps
AgentOps (Agent Operations) 是一种将DevOps、MLOps和DataOps的原则应用于AI Agent整个生命周期的运营方法论。它提供了一个系统性的、自动化的、可复现的框架,来处理非确定性的、基于LLM的系统在生产环境中的复杂性,核心关注点包括正确性、性能、安全性和责任。
一个强大的AgentOps策略将Agent的评估体系分解为四个层次化的阶段:
第1层:组件级评估 (确定性单元测试)
- 目标:验证Agent系统中非LLM部分的词法正确性。
- 测试内容:
-
- 工具:在有效、无效和边界输入下的行为是否符合预期。
- 数据处理:解析和序列化函数的鲁棒性。
- API集成:对成功、错误和超时条件的正确处理。
- 实现 :ADK将工具定义为标准的Python函数,可以直接使用
pytest等框架进行单元测试。
第2层:轨迹评估 (程序正确性)
- 目标:验证Agent在ReAct循环中的推理过程是否正确。
- 测试内容:
-
- Reason步骤:Agent是否能正确评估目标和当前状态,形成逻辑自洽的下一步假设?
- Act步骤:Agent是否选择了正确的工具,并正确地生成了参数?
- Observe步骤:Agent是否能正确地将工具输出集成到上下文中,以指导下一步推理?
- 实现:ADK的核心运行时与Google Cloud Trace直接集成,可以捕获并可视化完整的执行轨迹。通过建立一个"黄金标准"提示与预期轨迹的测试集,并将其纳入CI/CD流水线,可以有效防止性能衰退。
第3层:结果评估 (语义正确性)
- 目标:评估ReAct循环结束后,Agent生成的最终用户响应的语义正确性、事实准确性和整体质量。
- 测试内容:
-
- 事实准确性 :答案是否正确,并且可由
Observe步骤中收集到的信息证实? - 有用性和语气:响应是否以适当的风格充分满足了用户的需求?
- 完整性:响应是否包含了所有必要的信息?
- 事实准确性 :答案是否正确,并且可由
- 实现:利用Vertex AI的Gen AI评估服务进行"LLM-as-judge"评分,并结合人工反馈(HITL)进行高质量评估。
第4层:系统级监控 (生产环境)
- 目标:追踪Agent在真实世界中的性能,并检测运营故障或行为漂移。
- 监控内容:工具调用失败率、用户反馈分数、轨迹指标(如每个任务的ReAct循环次数)、端到端延迟等。
- 实现 :ADK Agent在生产环境中会为每次用户交互发射事件和追踪数据。Agent Starter Pack 提供了一套生产级的可观测性堆栈(OpenTelemetry, Cloud Logging, BigQuery, Looker Studio),使团队能够即时追踪性能、分析趋势和调试问题。
AgentOps工具包: ADK 与 Agent Starter Pack
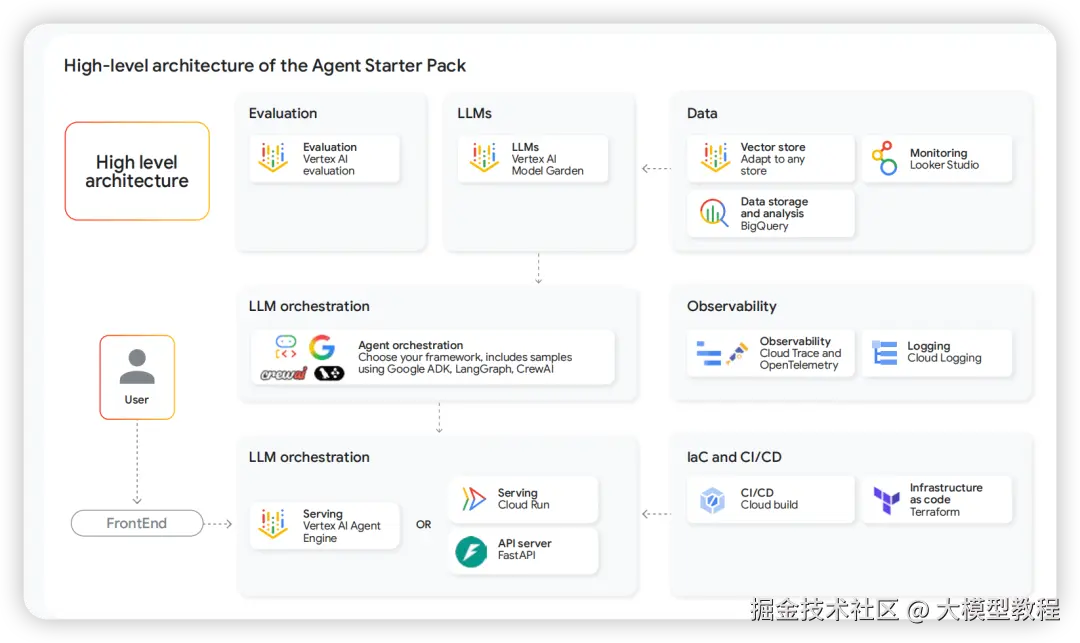
为了加速AgentOps的落地,谷歌提供了 Agent Starter Pack 。它是一个生产就绪的参考实现,通过一个命令 (uvx agent-starter-pack create ...) 就能引导创建一个包含必要基础设施和流水线的新Agent项目。
- ADK负责 :Agent的运行时行为(应用逻辑)。
- Agent Starter Pack负责 :Agent的运营环境(基础设施即代码Terraform、CI/CD流水线Cloud Build等)。
这种应用逻辑与运营环境的明确分离,构成了一个健壮且可扩展的开发流程。
总结与展望
谷歌云的这份《初创公司技术指南》远不止是一份产品说明书。它雄心勃勃地定义了一套关于如何以工程化、系统化的思想构建下一代智能系统的"世界观"和"方法论"。
对于在AI Agent浪潮中探索的创业者和开发者而言,这份指南的价值在于:
- 提供了一张清晰的路线图:它将构建Agent的模糊过程,拆解为一系列明确的、可执行的工程决策,覆盖了从概念到规模化运营的全过程。
- 强调了从"可用"到"可靠"的跃迁:通过引入AgentOps的核心理念和四层评估框架,它指明了通往生产级Agent的必经之路------严谨、自动化、数据驱动的评估与迭代。
- 描绘了一个开放的未来:通过对MCP和A2A等开放协议的拥抱,谷歌展现了其构建一个互联互通的Agent生态的决心,这为初创公司提供了前所未有的合作与整合机遇。
从原型到生产的旅程,是一场关于严谨工程的修炼。这份指南,正是这场修炼的蓝图。它清晰地表明,未来的竞争优势将不仅仅属于那些拥有最强大模型的公司,更属于那些能够以最高的工程效率和可靠性,构建、部署和管理智能体"军团"的团队。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。