引言
MNIST 数据集是手写数字识别的经典 benchmark 数据集,包含 0-9 共 10 类手写数字图像(每张图像尺寸为 28×28)。本文将基于 PyTorch 框架,完整演示从数据准备、数据可视化、神经网络构建到模型训练与结果分析的全流程,帮助新手快速上手 PyTorch 深度学习实践。
一、环境准备与库导入
首先导入所需的第三方库

二、数据准备与预处理
1. 定义超参数
设置训练 / 测试批次大小、学习率、训练轮数等关键超参数:

2. 数据预处理与加载
使用 transforms 对图像进行张量转换 和标准化 ,再通过 DataLoader 生成可迭代的数据集(自动分批、打乱等):
三、源数据可视化
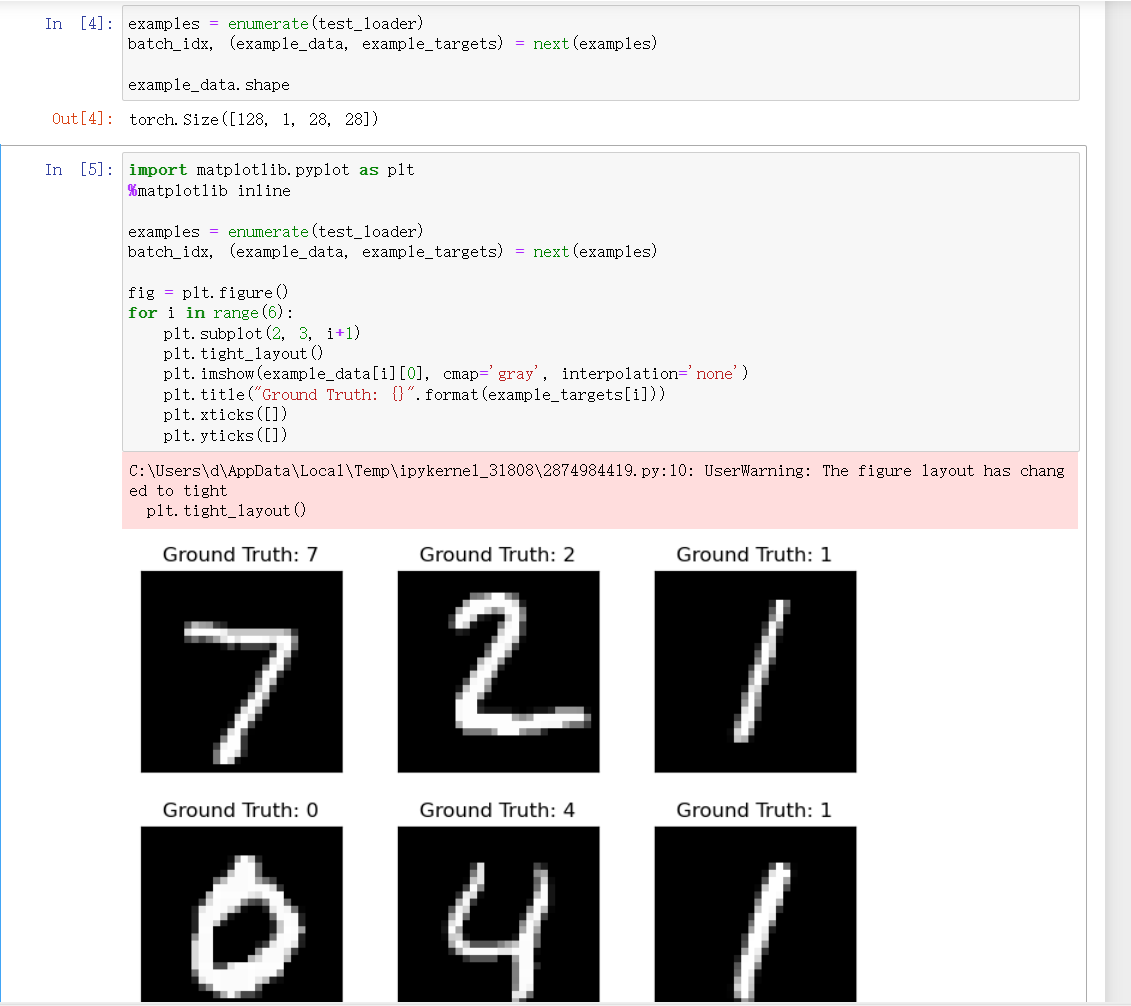
为直观感受数据,我们可视化测试集中的部分样本:
四、构建神经网络模型
定义一个多层感知机(MLP),包含 "展平层 + 两个隐藏层(带 BatchNorm) + 输出层",使用 ReLU 激活函数与 Softmax 输出:

模型输入为 784 维(28×28 展平),经两层隐藏层(300、100 个神经元)后,输出 10 维(对应 0-9 分类)
五、模型实例化与配置
指定设备(GPU/CPU) 、实例化模型,并配置损失函数 与优化器:

六、模型训练与评估
训练过程中记录损失 和准确率,并在测试集上周期性评估模型性能:
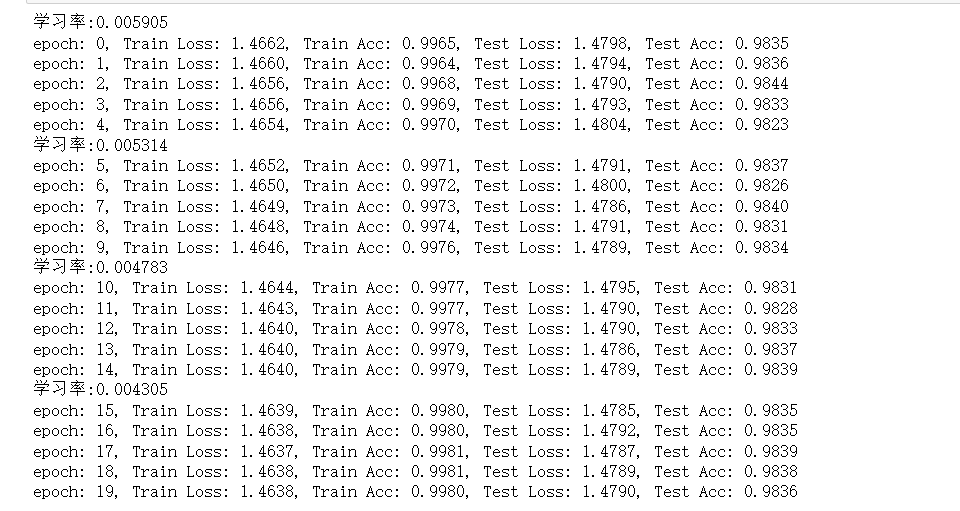
训练过程中,可观察到训练损失逐渐下降 、准确率逐渐上升,测试集性能也随之提升(若过拟合,测试集性能会提前趋于平稳)。
七、训练结果可视化
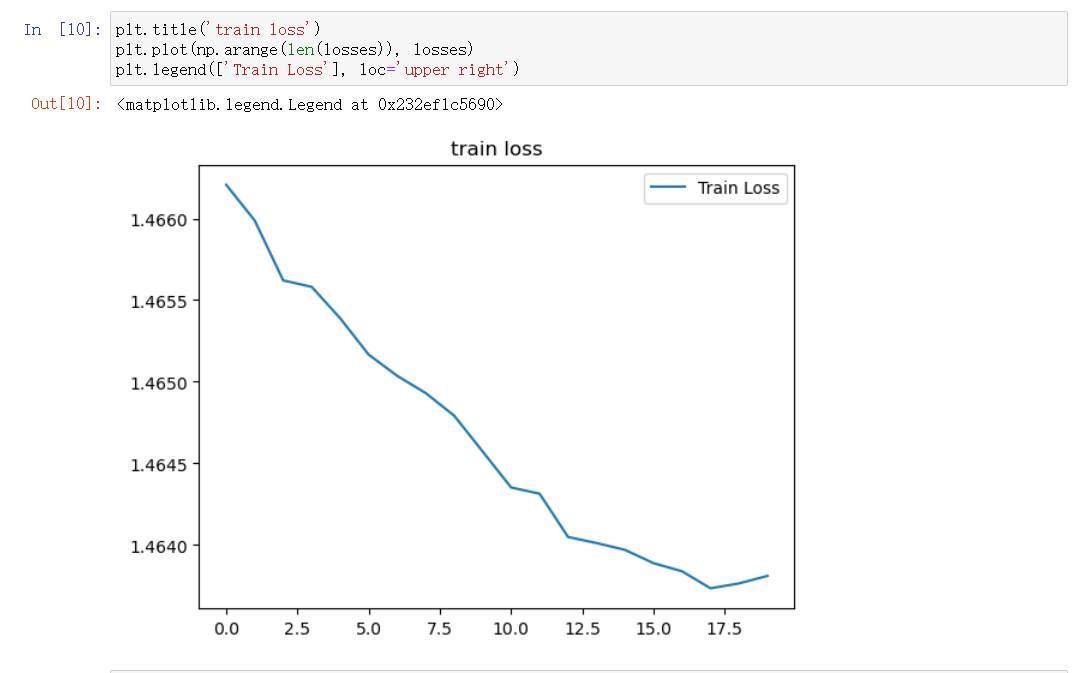
绘制训练损失曲线,直观分析模型收敛过程:
总结
本文基于 PyTorch 完成了 MNIST 手写数字识别的全流程实践,核心环节包括:
数据处理 :加载、预处理 MNIST 数据,通过 DataLoader 批量迭代;
数据可视化:直观展示手写数字样本与真实标签;
模型构建:自定义多层感知机,结合 BatchNorm 加速训练;
训练与评估:使用 SGD 优化器,动态调整学习率,同时记录训练与测试指标;
结果可视化:绘制损失曲线,分析模型收敛过程。