PyTorch实战(21)------扩散模型(Diffusion Model)
-
- [0. 前言](#0. 前言)
- [1. 扩散模型图像生成原理](#1. 扩散模型图像生成原理)
-
- [1.1 扩散的工作原理](#1.1 扩散的工作原理)
- [1.2 训练正向扩散模型](#1.2 训练正向扩散模型)
- [1.3 执行逆向扩散(去噪)](#1.3 执行逆向扩散(去噪))
- [2. 使用 PyTorch 构建扩散模型](#2. 使用 PyTorch 构建扩散模型)
-
- [2.1 使用 Hugging Face 加载数据集](#2.1 使用 Hugging Face 加载数据集)
- [2.2 使用 torchvision 处理数据集](#2.2 使用 torchvision 处理数据集)
- [2.3 使用 diffusers 添加噪声](#2.3 使用 diffusers 添加噪声)
- [2.4 定义 UNet 模型](#2.4 定义 UNet 模型)
- [3. 模型训练](#3. 模型训练)
-
- [3.1 定义优化器和学习调度](#3.1 定义优化器和学习调度)
- [3.2 使用 Hugging Face Accelerate 加速训练](#3.2 使用 Hugging Face Accelerate 加速训练)
- [3.3 运行模型训练循环](#3.3 运行模型训练循环)
- [4. 使用(反向)扩散生成逼真图像](#4. 使用(反向)扩散生成逼真图像)
- 小结
- 系列链接
0. 前言
我们已经学习了如何使用生成对抗网络 (Generative Adversarial Network, GAN)生成图像。本节将探讨一种更前沿的图像生成范式------扩散模型 (Diffusion Model)。我们将首先解析扩散模型的工作原理,然后使用 PyTorch 从零开始训练扩散模型以生成逼真图像。通过本节学习,将掌握使用 PyTorch 从零开始训练扩散模型的完整流程。
1. 扩散模型图像生成原理
在生成式人工智能领域,扩散模型通过多阶段渐进式转化实现数据生成,其核心流程如下图所示,从简单噪声出发,经过多次迭代精炼,逐步转化为具有高度真实性的多样化数据样本。该过程通过循环优化噪声分布,最终生成符合目标数据特征的高质量样本:

1.1 扩散的工作原理
从纯噪声生成逼真图像的过程,可以泛化为"从高噪声图像推导低噪声图像"的渐进式优化目标。为实现该目标,我们首先需要训练一个具有逆向特性的深度学习模型,使其能够识别含噪图像中的纯净噪声成分------这一过程称为正向扩散 (forward diffusion),其原理示意如下图所示。

本节使用的深度学习模型是UNet 模型,该模型能够生成与输入保持相同空间维度的输出,UNet 架构如下所示:
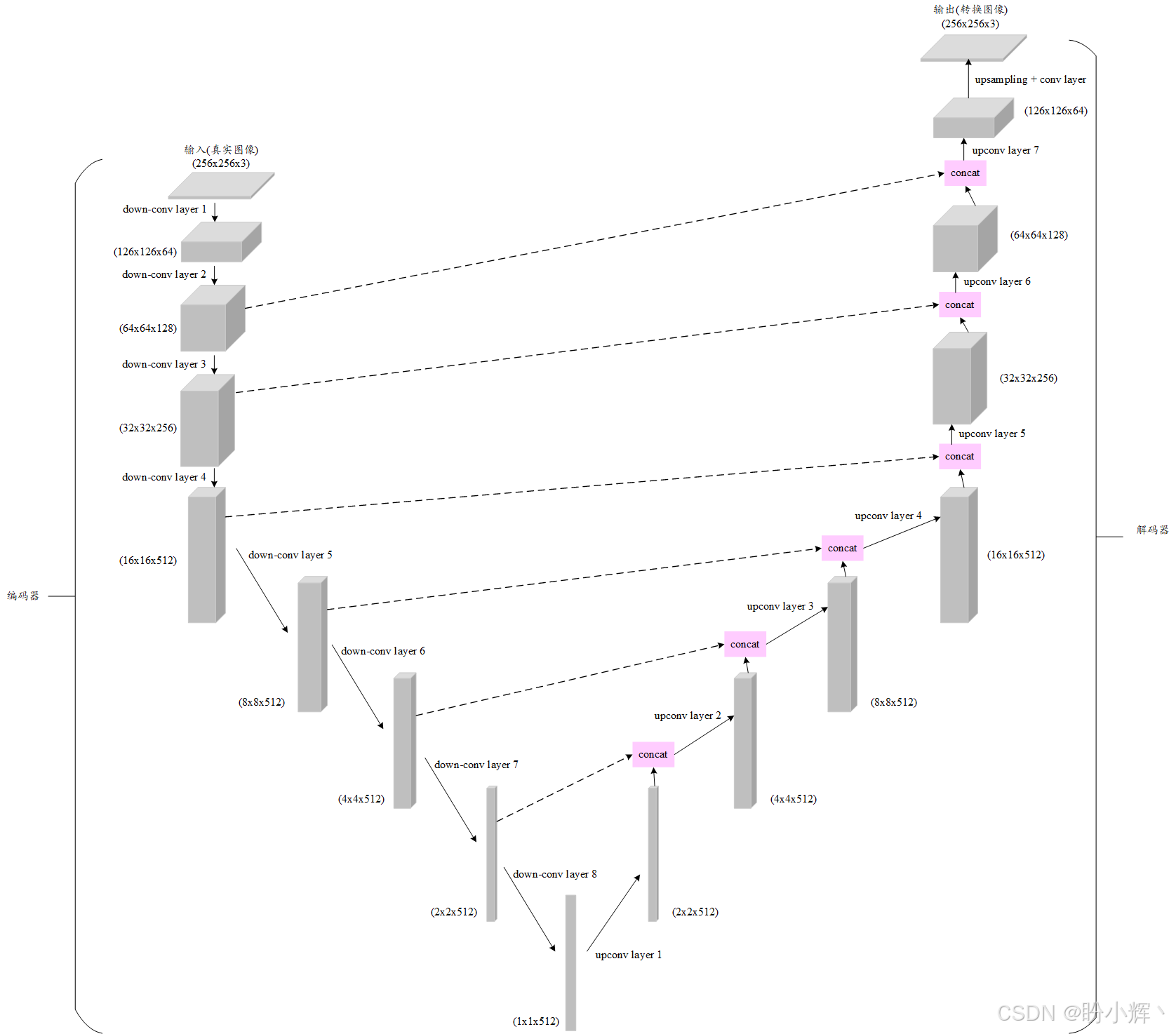
接下来,我们首先理解如何训练 UNet 模型执行正向扩散过程。
1.2 训练正向扩散模型
(1) 为扩散模型准备数据集。我们以下图为例,向图像添加噪声:
python
from PIL import Image
import numpy as np
img = Image.open("./10.jpeg")
width, height = img.size
noise = 256*np.random.rand(height, width, 3)
noisy_img = ((img + noise)/2).astype(np.uint8)
Image.fromarray(noisy_img)输出结果如下所示,使用下图作为 UNet 的输入样本:

(2) 模型输出图像为噪声本身,如下图所示:
python
Image.fromarray(noise.astype(np.uint8))
与以上生成的输入和输出图像对类似,我们可以通过使用不同的真实图像并向其添加噪声来生成大量用于 UNet 模型训练的数据集样本。
(3) 对于每张图像,我们生成不同的随机噪声,以便将各种噪声信号添加到不同的图像中,从而使 UNet 模型能够学习从输入数据中预测各种噪声模式。此外,添加的噪声量也可以变化,以使数据集更加多样化。为了生成带噪声的图像,我们将原始图像与噪声按相等比例(各占 50%)相加。我们可以重复向图像添加噪声,或增加(或减少)噪声量,以生成更多的噪声 UNet 输入样本:
python
noisy_img = ((img + 3*noise)/4).astype(np.uint8)
Image. fromarray(noisy_img)输出结果如下所示:

我们已经掌握了为 UNet 模型构建数据集的方法,接下来将进入模型训练阶段,如下图所示。
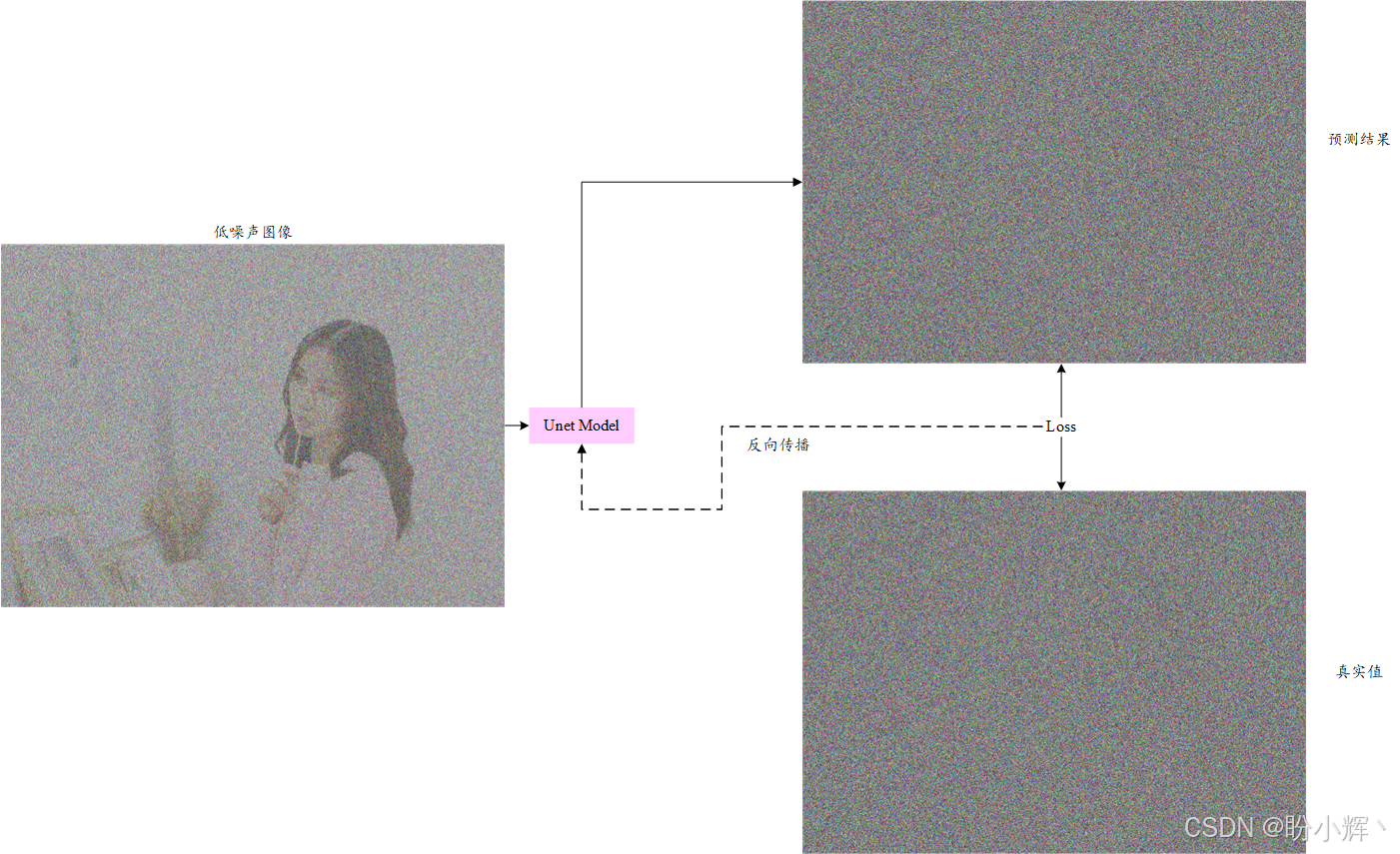
接下来,我们将使用 PyTorch 训练这个模型,解决与UNet相关的第二个问题,即利用这个模型生成逼真图像。
1.3 执行逆向扩散(去噪)
为了生成逼真图像,则需要执行去噪(即逆向扩散)处理。具体而言,我们利用训练好的 UNet 模型预测高噪声图像中包含的噪声信号,然后将预测出的噪声从原图中减去,从而得到噪声较少的图像------这一过程如下图所示。

若从纯噪声出发,并重复足够次数的逆向扩散步骤,最终就能生成高质量逼真图像。整个过程通过渐进式微调实现:原始噪声图像本质上是有效内容与极端噪声的叠加,视觉效果近乎纯噪声。而经过训练的 UNet 模型能够精确提取其中的纯净噪声成分,这正是模型被训练优化的核心目标。
通过从原始高噪声图像中减去 UNet 提取的噪声成分,即可得到噪声较少的图像。当这一过程重复数百至数千次后,最终将生成几乎不含噪声的图像------此时留存下来的就是具有完整语义的图像内容。
在下图中,我们仅通过四次去噪步骤实现从噪声到逼真图像的转换;而实际应用中需要执行更多步骤(例如采用 50 步去噪)才能获得高质量图像。下图展示的从噪声生成逼真图像的完整流程,正是去噪扩散概率模型 (Denoising Diffusion Probabilistic Model, DDPM) 的核心机制。在下一小节中,我们将基于 PyTorch 从零实现 DDPM,构建一个能够从噪声生成图像的完整扩散模型。
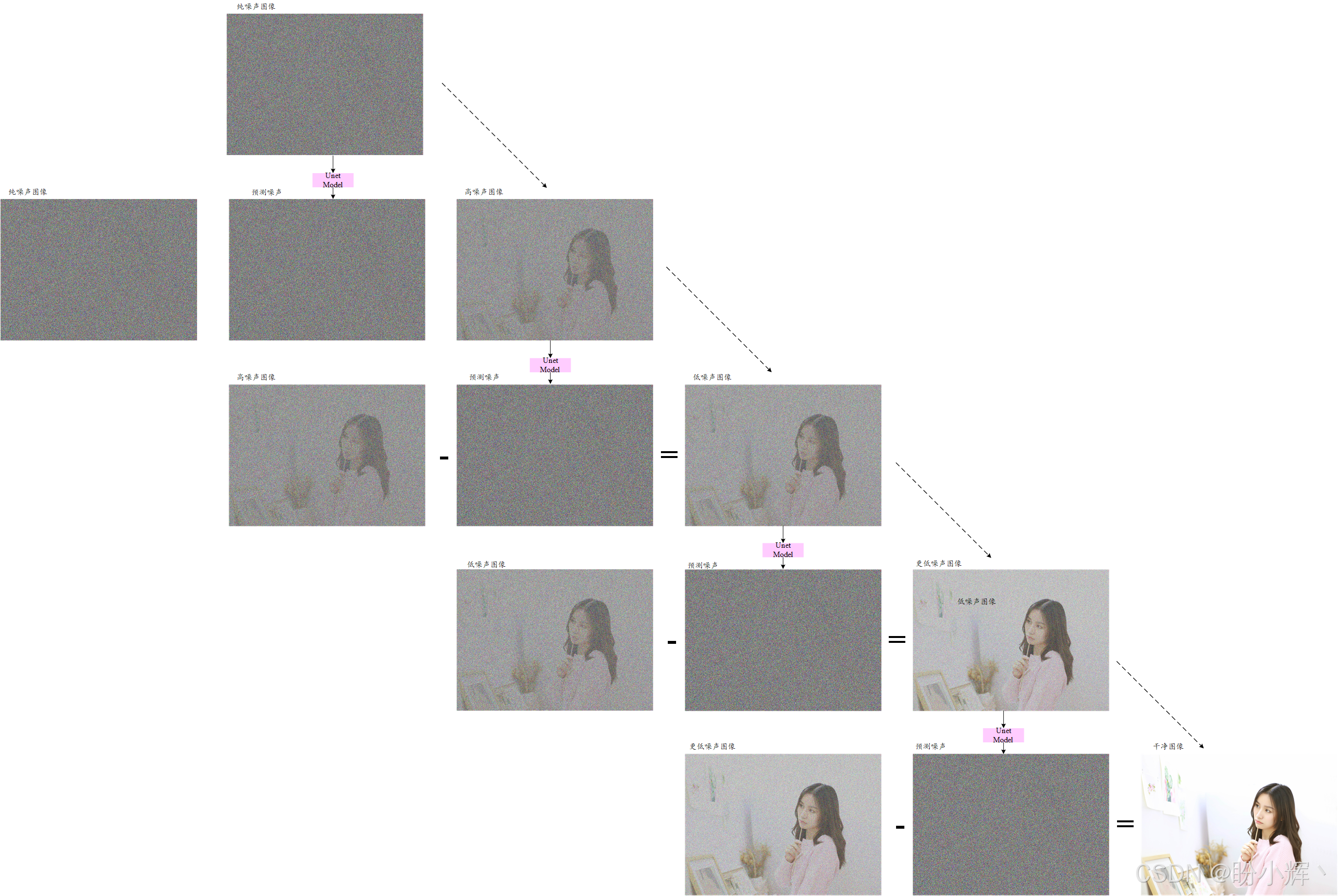
2. 使用 PyTorch 构建扩散模型
在本节中,我们将使用 PyTorch 从零开始实现一个扩散模型,该模型最终能够生成逼真的高质量图像。除了 PyTorch,我们还将使用 Hugging Face 加载图像数据集。除了数据集,还将使用 Hugging Face 的 diffusers 库,它提供了诸如 UNet 和 DDPM 等模型的实现,以及 Hugging Face 的 accelerate 库,通过利用图形处理单元 (Graphics Processing Unit, GPU) 加速扩散训练过程。首先,安装以下库:
shell
pip install torch, torchvision, numpy, pillow, diffusers, datasets, accelerate2.1 使用 Hugging Face 加载数据集
(1) 首先加载数据集,使用 Hugging Face 加载名为 se/fie2anime 的动漫人脸数据集。该数据集原本用于训练真人面部图像转动漫面部图像的模型,但本节仅使用其中的动漫图像部分(我们也可选择使用真人图像部分):
python
from datasets import load_dataset
dataset = load_dataset("huggan/selfie2anime", split="train")(2) 打印数据集对象,输出结果如下所示:
python
Dataset({
features: ['imageA', 'imageB'],
num_rows: 3400
})这表明该数据集总共有 3400 张图像。我们也可以通过 Hugging Face 网站查看数据集,如下图所示:
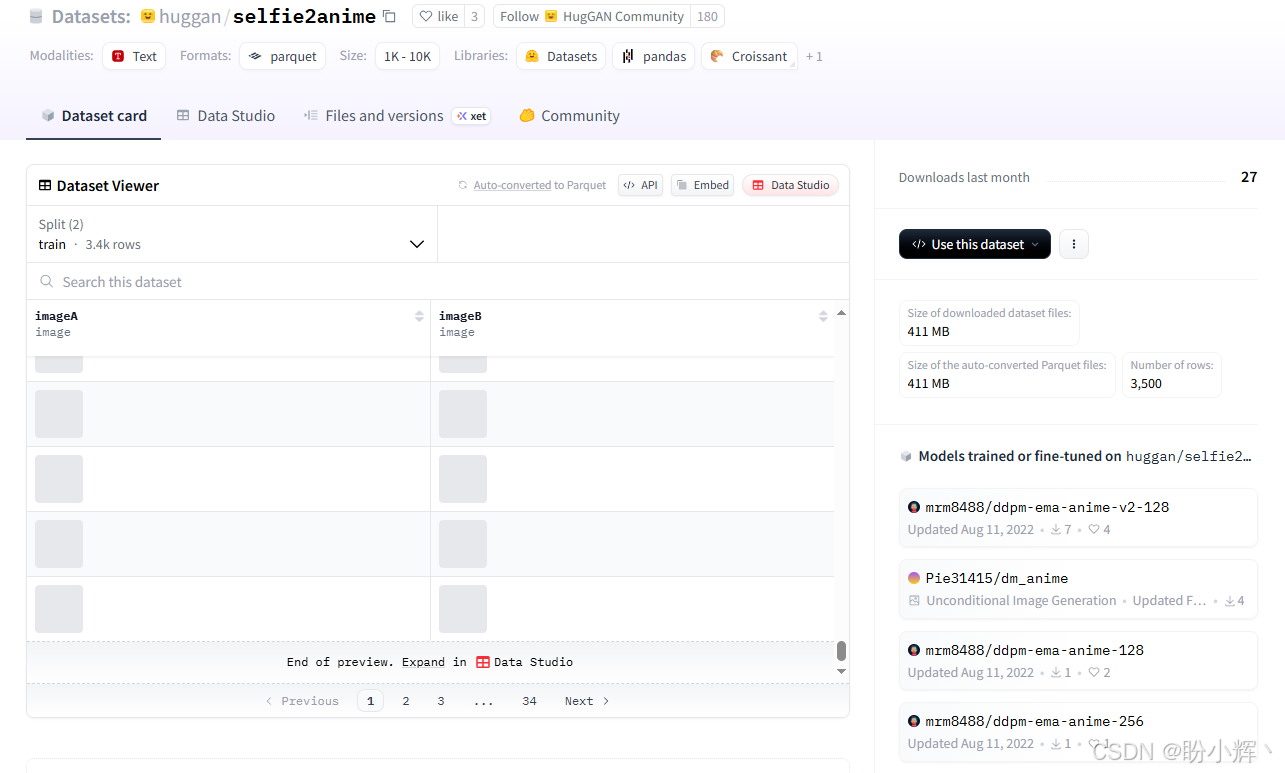
(3) imageB 对应的是我们所需的动漫图像。从数据集对象中提取这些图像:
python
dataset["imageB"]输出结果如下所示:
shell
Column([<PIL.PngImagePlugin.PngImageFile image mode=RGB size=256x256 at 0x72A072F71E20>, ...])该数据集本质上是由 PIL.Image 对象组成的列表,每张图像尺寸为 256 x 256 x 3 (3 表示 RGB 通道)。查看列表中的图像样本:
python
img = dataset["imageB"][0]
img借助 diffusers 库中的实用函数,可以显示一个包含 4 x 4 图像的网格:
python
from diffusers.utils import make_image_grid
make_image_grid(dataset["imageB"][:16], rows=4, cols=4)输出结果如下所示:

加载数据集后,实现从纯噪声生成逼真动漫人脸。在定义和训练扩散模型之前,需要先对数据集进行预处理。
2.2 使用 torchvision 处理数据集
(1) 对动漫图像数据集进行预处理,使其适用于 UNet 模型训练:
python
from torchvision import transforms
IMAGE_SIZE = 128
preprocess = transforms.Compose(
[
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform(examples):
images = [preprocess(image) for image in examples["imageB"]]
return {"images": images}
dataset.set_transform(transform)使用 torchvision.transforms API 对动漫图像进行预处理。首先,将 256 x 256 x 3 的图像调整为 128 x 128 x 3,以便能够使用更短的时间训练扩散模型。接着,执行数据增强技术,随机水平翻转动漫图像,因为水平翻转后的图像仍然能够保留面部结构和方向特征,又能生成与原始图像不同的新样本。然后,将 PIL.Image 对象转换为 PyTorch 张量,并使用均值 0.5 和标准差 0.5 对像素值进行归一化。这这些转换操作通过 set_transform 方法内部调用的 transform 函数,应用于数据集对象的每张图像。设定的均值与标准差确保了归一化后的像素值均被约束在均值 0.5 与标准差 0.5 范围内,这有助于提升模型训练的稳定性。
(2) 将 PIL 图像转换为 PyTorch 张量后,创建训练数据加载器 (dataloader):
python
import torch
BSIZE = 16
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=BSIZE, shuffle=True)设定批大小为 16,借助 Hugging Face的datasets 库,可以快速将创建的数据集对象转换为 PyTorch 数据加载器。现在所有动漫图像均已转换为 PyTorch 标准格式,接下来我们将为这些图像添加噪声,以生成用于 UNet 模型的训练样本。
2.3 使用 diffusers 添加噪声
(1) Hugging Face 的 diffusers 库提供了基于扩散过程的生成式AI模型工具与预构建模型。本节我们将使用该工具包中的功能,通过向动漫图像添加噪声来实现前向扩散过程。我们会为不同图像添加不同强度的噪声。为此,需要创建一个噪声调度器 (noise scheduler):
python
from diffusers import DDPMScheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)(2) 时间步数 (timestep) 表示我们想要将噪声与原始动漫图像混合的层级或程度。时间步数越大,意味着我们会在图像上迭代叠加更多噪声:
python
clean_images = next(iter(train_dataloader))["images"]
noise = torch.randn(clean_images.shape, device=clean_images.device)
bs = clean_images.shape[0]
timesteps = torch.arange(10, 161, 10, dtype=torch.int)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)首先,我们获取一批已转换为张量格式的动漫图像。接着初始化一个与动漫图像张量维度相同的随机噪声信号。随后为不同的图像分别定义从 10 到 160 不等的 16 个时间步数。
这组图像的噪声信号始终保持不变,变化的仅是噪声添加的强度。通过在不同批次中使用不同的噪声分布,可以帮助模型学习各类噪声模式。
(3) 随后,我们按照各自的时间步长为图像分别添加噪声:第一张图像迭代添加 10 个时间步长的噪声,第二张添加 20 个时间步长的噪声。最后可视化原始图像张量与添加噪声后的图像张量:
python
make_image_grid([transforms.ToPILImage()(clean_image) for clean_image in clean_images], rows=4, cols=4)
make_image_grid([transforms.ToPILImage()(noisy_image) for noisy_image in noisy_images], rows=4, cols=4)运行以上代码,输出结果如下所示:

(4) 在实际训练中,我们会为每批图像随机生成 1 到 1000 之间的不同时间步长来施加不同强度的噪声:
python
clean_images = next(iter(train_dataloader))["images"]
noise = torch.randn(clean_images.shape, device=clean_images.device)
bs = clean_images.shape[0]
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bs,), device=clean_images.device,
dtype=torch.int64
)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)我们已构建了模型训练循环中的训练数据,接下来创建 UNet 模型。
2.4 定义 UNet 模型
(1) 使用 Hugging Face 的 diffusers 库定义 UNet 模型:
python
from diffusers import UNet2DModel
model = UNet2DModel(
sample_size=IMAGE_SIZE, # the target image resolution
in_channels=3, # the number of input channels, 3 for RGB images
out_channels=3, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(128, 128, 256, 256, 512, 512), # the number of output channels for each UNet block
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"DownBlock2D",
),
up_block_types=(
"UpBlock2D", # a regular ResNet upsampling block
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)代码指定了输入和输出的维度,在本节中两者保持相同,因为我们需要生成与输入形状一致的输出。代码同时指定了降采样与上采样块的数量,以及每个块中的特征图(或称通道)数量。
模型和训练数据集准备完毕后,接下来训练模型。
3. 模型训练
本节首先配置 UNet 模型训练所需的组件,包括优化器和学习率等。随后引入 Hugging Face 的 accelerate 库以加速训练过程。最终执行模型训练循环。
3.1 定义优化器和学习调度
(1) 在进入模型训练循环之前,需要定义优化器和学习率调度来训练 UNet 模型:
python
from diffusers.optimization import get_cosine_schedule_with_warmup
NUM_EPOCHS = 20
LR = 1e-4
LR_WARMUP_STEPS = 500
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=LR_WARMUP_STEPS,
num_training_steps=(len(train_dataloader) * NUM_EPOCHS),
)在以上代码中,我们定义了训练 UNet 模型的迭代轮次 (epoch),并且定义了一种特定的学习调度,称为带预热的余弦调度 (cosine schedule with warmup)。该调度器可直接从 diffusers 库调用,其工作原理是:在前 500 个预热步骤 (warmup steps) 中,学习率从 0 开始线性增长至设定值 (LR=1e-4);随后从第 501 步到 4250步 (4250=213×20,其中 213 是训练数据加载器的批次数,即总样本量 3400 除以批大小 16,20 为 epoch 总数),学习率按照余弦曲线从 1e-4 衰减至 0。本节后续训练时,我们将在 TensorBoard 上观察该学习率的变化曲线。
除了学习率调度,还定义了模型的优化器为 Adamw,它是 Adam 优化器的一个变体,增加了用于衰减权重的方法。接下来,需要配置模型训练加速器。
3.2 使用 Hugging Face Accelerate 加速训练
(1) 为了在合理的时间内训练模型,我们需要使用 GPU。为了利用 GPU 训练 UNet 模型,我们采用 Hugging Face 的 Accelerate 库,该库能让 PyTorch 训练代码最大化利用现有硬件资源(包括单/多 CPU、GPU 或 TPU)。设置加速器对象:
python
import os
from accelerate import Accelerator
MODEL_SAVE_DIR = "anime-128"
accelerator = Accelerator(
mixed_precision="fp16",
log_with="tensorboard",
project_dir=os.path.join(MODEL_SAVE_DIR, "logs"),
)(2) accelerate 库还提供了其他功能,如混合精度和 TensorBoard 集成。接下来,创建模型保存目录,并将模型和数据集分配到已定义的加速器上:
python
if accelerator.is_main_process:
if MODEL_SAVE_DIR is not None:
os.makedirs(MODEL_SAVE_DIR, exist_ok=True)
accelerator.init_trackers("train_example")
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler
)设置了加速器对象后,接下来训练 UNet 模型。
3.3 运行模型训练循环
(1) 接下来,运行模型训练循环:
python
from tqdm import tqdm
import torch.nn.functional as F
from diffusers import DDPMPipeline
global_step = 0
SAVE_ARTIFACT_EPOCHS = 1
RANDOM_SEED = 42
for epoch in range(NUM_EPOCHS):
progress_bar = tqdm(total=len(train_dataloader), disable=not accelerator.is_local_main_process)
progress_bar.set_description(f"Epoch {epoch}")
for step, batch in enumerate(train_dataloader):
clean_images = batch["images"]
# Sample noise to add to the images
noise = torch.randn(clean_images.shape, device=clean_images.device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bs,), device=clean_images.device,
dtype=torch.int64
)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps).to(clean_images.device)
with accelerator.accumulate(model):
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
accelerator.backward(loss)
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
global_step += 1模型训练循环的核心环节始于噪声残差预测部分。我们使用 UNet 模型从训练批次的 16 张含噪动漫图像中预测噪声信号,随后计算预测噪声与实际添加噪声之间的均方误差损失,并通过反向传播更新 UNet 模型参数。执行代码输出结果如下所示:

(2) 在终端窗口执行以下命令启动 TensorBoard:
python
tensorboard --logdir anime-128/logs/输出结果如下所示:

打开网页浏览器,输入 http://localhost:6006,TensorBoard 页面如下所示:
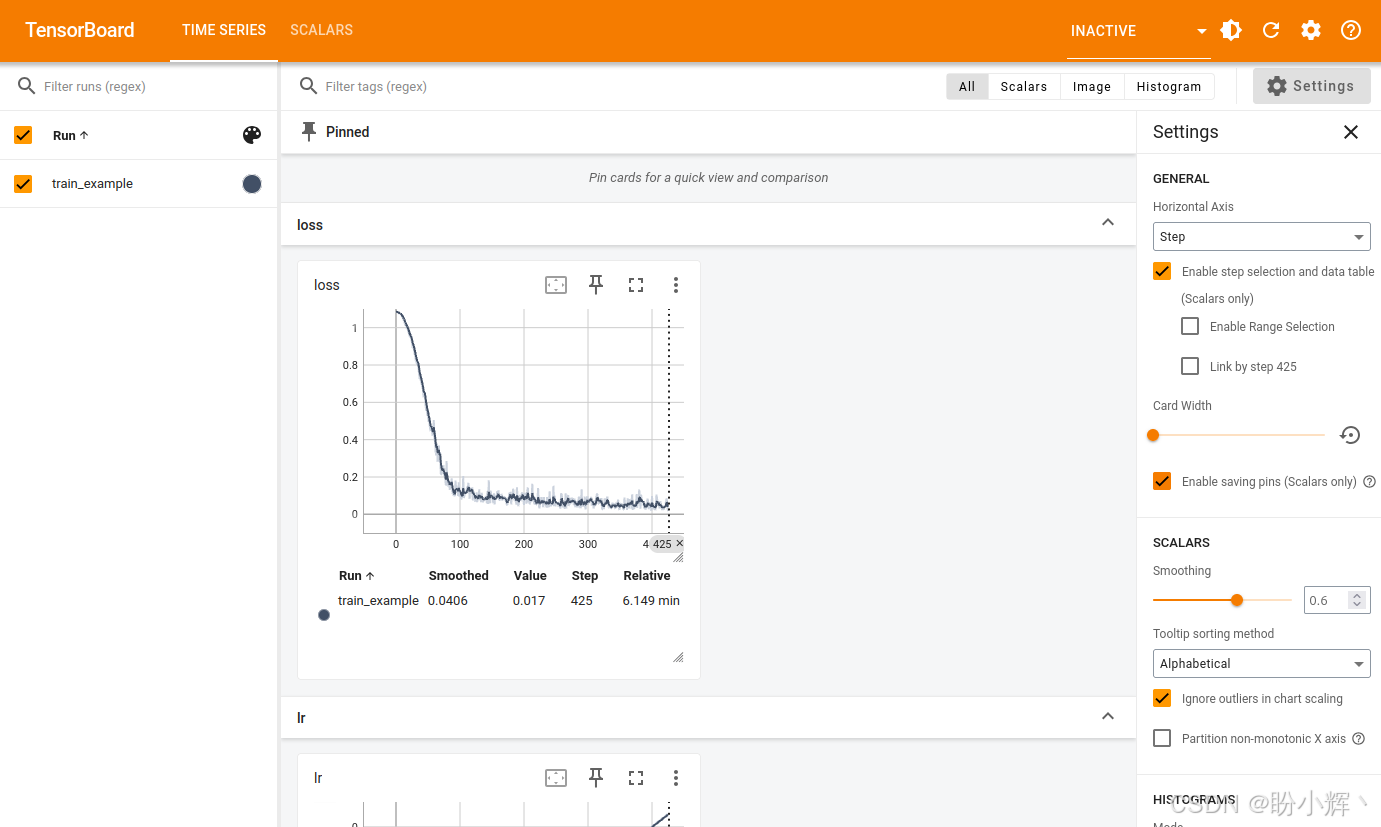
可以看到,我们采用的带预热余弦学习率调度策略的有效性------学习率首先线性上升至设定值 (1e-4),随后遵循余弦曲线衰减至 0。同时可见训练损失显著下降,这表明UNet模型确实在持续学习从含噪图像中预测噪声信号的能力。
扩散模型最后的关键环节,是能够利用训练好的 UNet 模型从纯噪声生成逼真(动漫)图像。
4. 使用(反向)扩散生成逼真图像
(1) Hugging Face 的 diffusers 库提供的 DDPMPipeline API,能够利用训练好的 UNet 模型构建所需去噪流程。在模型训练循环中,我们在每个 epoch 结束时执行以下代码,使用当前训练进度的 UNet 模型生成逼真动漫图像:
python
if accelerator.is_main_process:
pipeline = DDPMPipeline(unet=accelerator.unwrap_model(model), scheduler=noise_scheduler)
if (epoch + 1) % SAVE_ARTIFACT_EPOCHS == 0 or epoch == NUM_EPOCHS - 1:
images = pipeline(
batch_size=BSIZE,
generator=torch.manual_seed(RANDOM_SEED),
).images
# Make a grid out of the images
image_grid = make_image_grid(images, rows=4, cols=4)
# Save the images
test_dir = os.path.join(MODEL_SAVE_DIR, "samples")
os.makedirs(test_dir, exist_ok=True)
image_grid.save(f"{test_dir}/{epoch:04d}.png")
pipeline.save_pretrained(MODEL_SAVE_DIR)上述代码通过 UNet 模型对初始纯噪点图像进行迭代检测和降噪处理,最终生成逼真动漫图像。我们在每个 epoch 结束时使用固定随机种子生成噪声,并保存 16 张生成图像。固定种子确保每轮 epoch 都生成相同的图像,从而便于比较不同 epoch 间的 DDPM 性能表现。下图展示了 UNet 与 DDPM 训练流程的演进过程:

在第 0 个训练 epoch 时,输出基本是纯噪声;经过 20 个 epoch 后,DDPM 流程已能生成高质量的动漫风格图像。
小结
扩散模型通过简单的噪声扩散过程,就能创造出高质量的超现实图像。在本节中,我们首先学习了扩散如何用于图像生成,了解了扩散模型的内部运作机制。随后基于动漫图像数据集,使用 PyTorch 和 Hugging Face 框架训练和运行自定义扩散模型,生成逼真动漫图像。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)