PyTorch实战------基于文本引导的图像生成技术与Stable Diffusion实践
-
- [0. 前言](#0. 前言)
- [1. 基于扩散模型的文本生成图像](#1. 基于扩散模型的文本生成图像)
- [2. 将文本输入编码为嵌入向量](#2. 将文本输入编码为嵌入向量)
- [3. 条件 UNet 模型中的文本数据融合机制](#3. 条件 UNet 模型中的文本数据融合机制)
- [4. 使用 Stable Diffusion 模型生成图像](#4. 使用 Stable Diffusion 模型生成图像)
- 相关链接
0. 前言
在本节中,我们将为扩散模型添加文本控制能力。学习如何通过文字描述来引导图像生成过程,实现从"纯噪声+文本"生成图像,而不仅是从纯噪声生成。
1. 基于扩散模型的文本生成图像
在扩散模型的 UNet 模型训练流程中,我们仅训练模型从含噪图像中预测噪声。为实现文生图功能,需使用以下架构,将文本作为额外输入注入 UNet 模型:
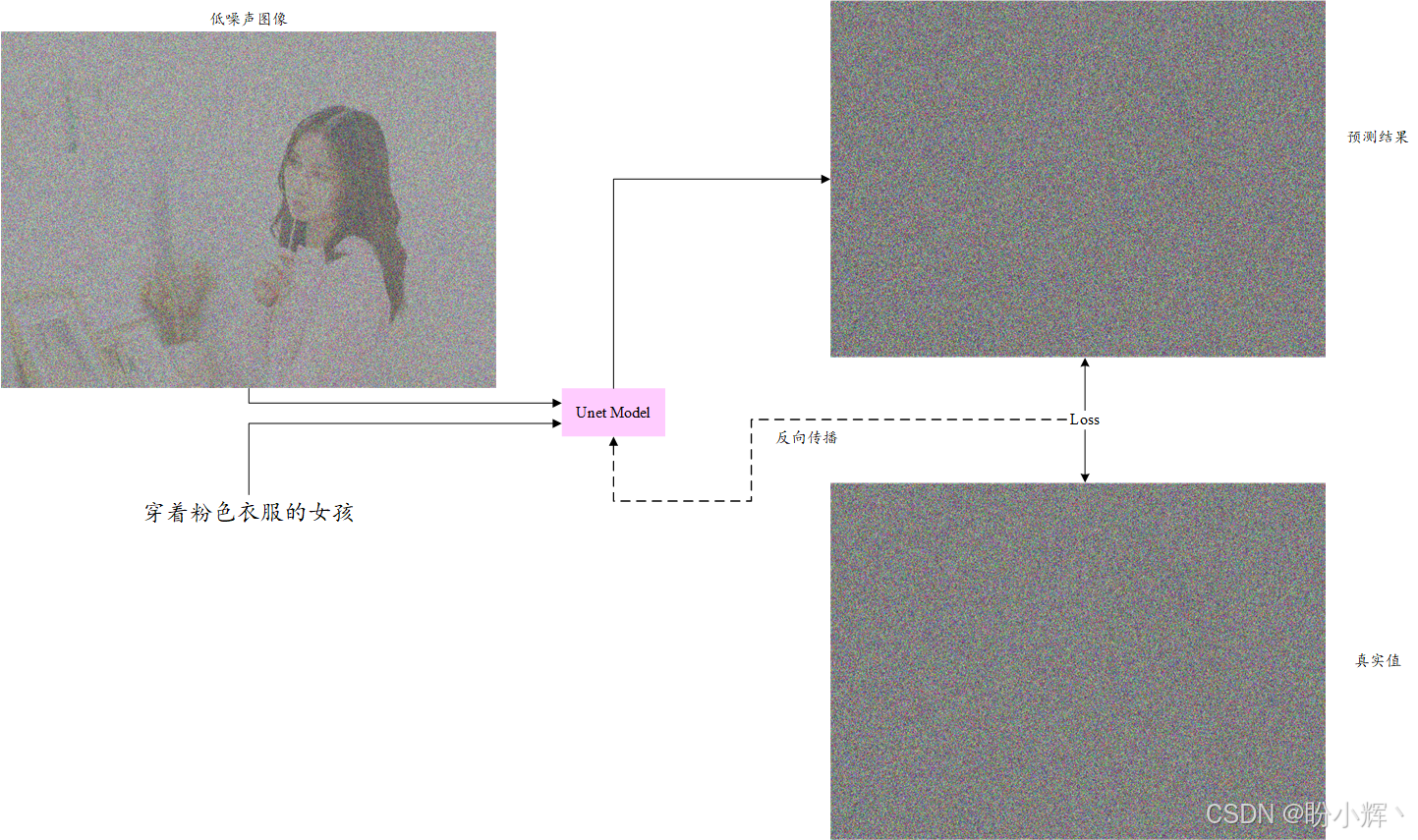
这样的 UNet 模型称为条件 UNet 模型 ,或者更精确地说,是文本条件 UNet 模型,因为该模型会根据输入文本来生成图像。为了训练此类模型,首先我们需要将输入文本编码成一个可以输入 UNet 模型的嵌入向量。然后,我们需要对 UNet 模型稍作修改,以适配嵌入文本形式的额外输入数据(除了图像之外)。接下来,首先介绍文本编码。
2. 将文本输入编码为嵌入向量
我们需要一个单独的模型,它能够接收输入文本并输出对应的 n 维向量。同时,我们希望这个向量能直观地反映文本所描述的视觉内容。这一点至关重要,因为最终我们要在 UNet 模型中利用这些向量进行条件式图像生成。
对比语言-图像预训练 (Contrastive Language-Image Pre-Training, CLIP) 模型正是能提供此类嵌入向量的解决方案。该模型通过海量网络图像及其对应标注文本进行训练,包含两个核心组件------图像编码器和文本编码器,我们重点关注后者。下图展示了 CLIP 模型的训练原理:
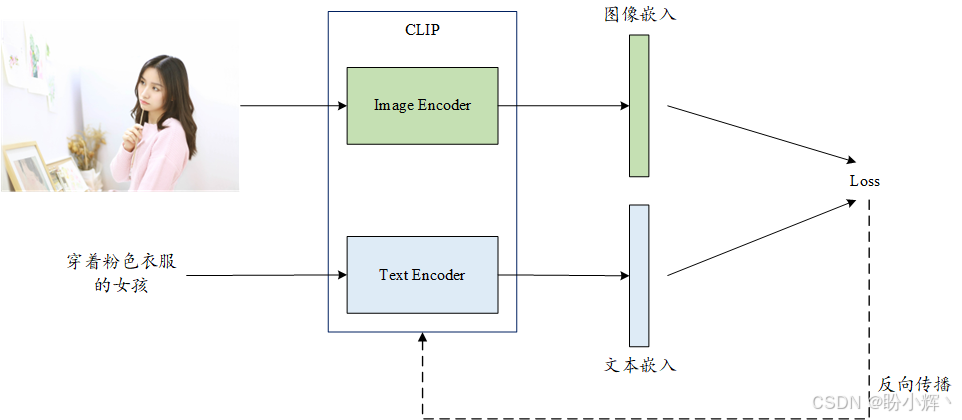
图像与标题文本对会被分别输入两个不同的编码器,生成对应的嵌入向量。这两个编码器经过训练后,能够为配对的图像-标题生成相似的嵌入表示。最终得到的文本编码器可以精准捕捉任意给定文本背后的视觉语义,因此非常适合作为 UNet 模型的前置文本编码器。
解决了文本编码问题后,接下来我们需要理解 UNet 模型如何适配这些额外的输入数据。
3. 条件 UNet 模型中的文本数据融合机制
传统 UNet 模型以图像作为输入,输出与输入尺寸相同的图像;而条件 UNet 模型则额外接收文本输入,将文本信息与图像输入协同处理,最终生成与输入图像同尺寸的输出图像。
在标准 UNet 架构中,模型通过下采样卷积层与上采样卷积层构成编解码结构,并配备跨层残差连接。而在条件 UNet 中,我们会在现有卷积层之间插入注意力层:
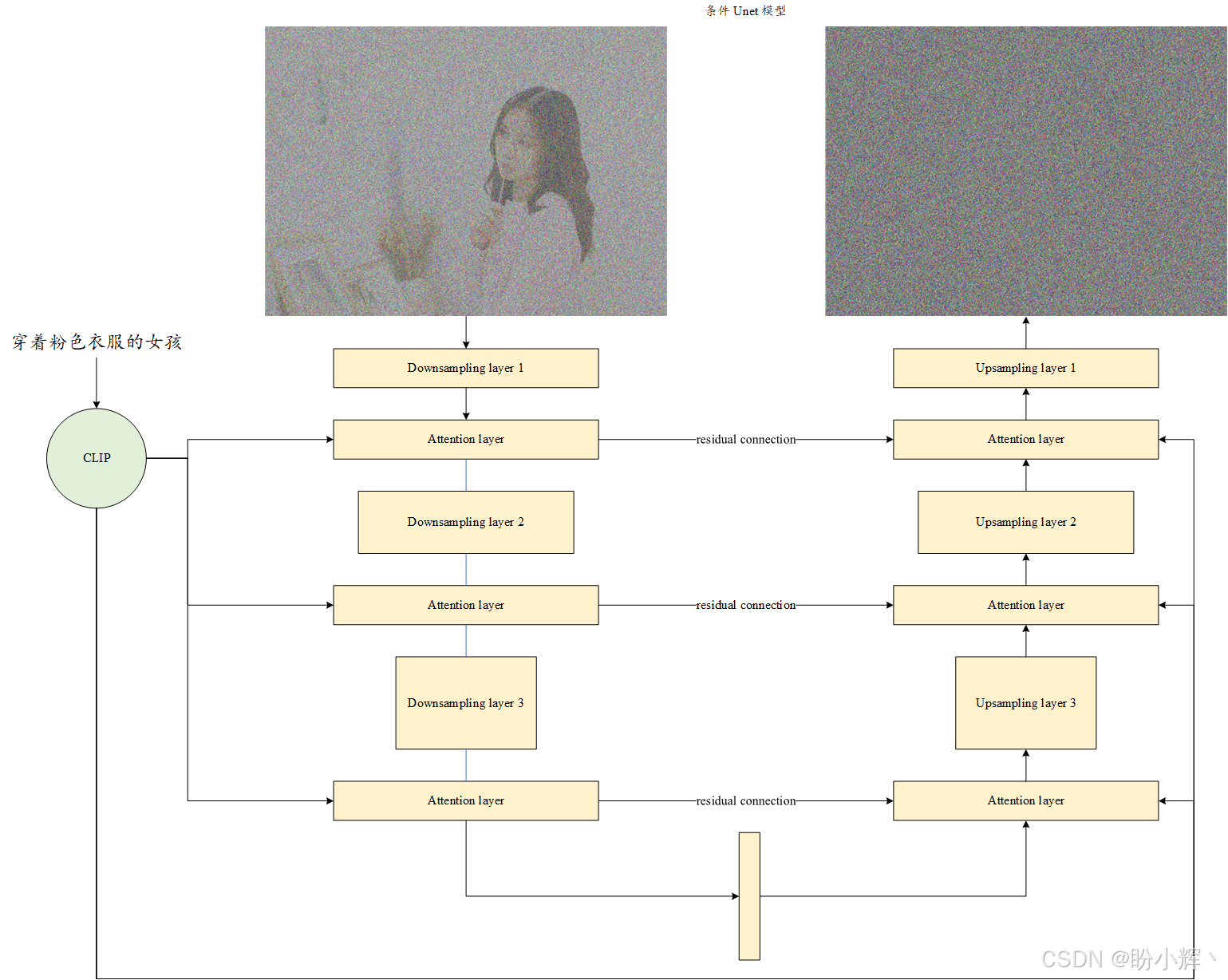
这些新增的注意力层专门用于处理输入文本(嵌入向量),使 UNet 能够学习模型输出像素与输入文本嵌入向量之间的关联性。如下图所示,条件 UNet 的高层架构在引入文本输入和注意力层后,形成了融合多模态数据的特殊结构。
训练好条件UNet模型后,图像生成的剩余流程与DDPM 过程相同。唯一区别在于:我们使用的是条件 UNet 而非普通 UNet,如下图所示,在每个时间步迭代时,我们同时将文本和图像作为输入传入模型。
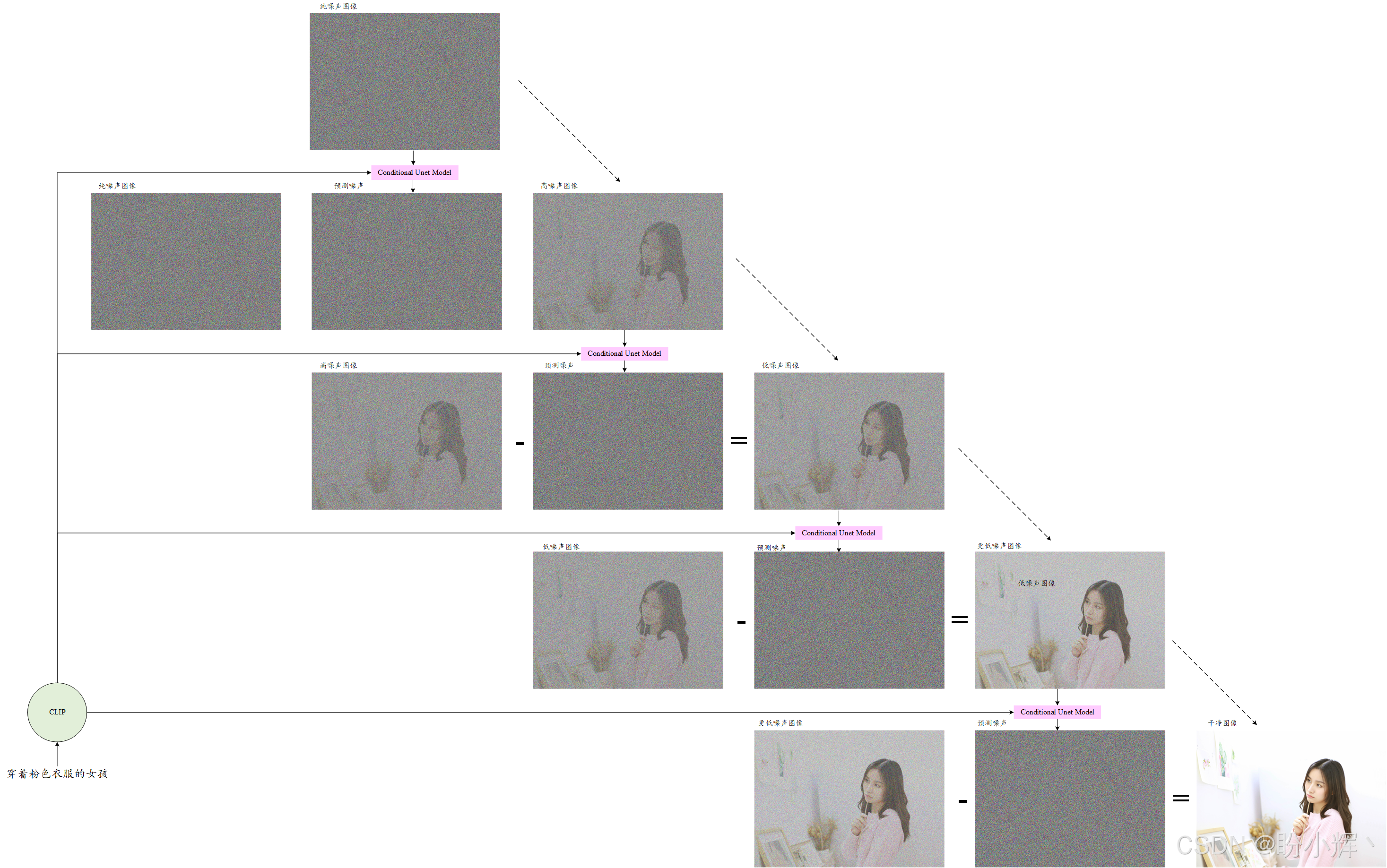
我们已经理解了 Stable Diffusion 的工作原理。这种文生图生成过程是计算机视觉领域大多数生成式人工智能模型的基础构建模块。掌握这些知识后,将能轻松理解 DALL-E、Imagen、Midjourney 等模型内部运作的细节。
我们已经理解了扩散模型文本生成图像的基本原理。下一节我们将实际运用基于 DDPM 的文生图流程,借助 Hugging Face 的 diffusers 库,使用预训练的 Stable Diffusion 模型来生成逼真图像。
4. 使用 Stable Diffusion 模型生成图像
diffusers 库提供了多个基于扩散模型的预训练文生图模型,其中包含 Stable Diffusion。本节我们将调用该模型生成高质量图像。
(1) 首先,加载 Stable Diffusion 模型:
python
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
)
pipeline = pipeline.to("cuda")以上代码定义了一个 DDPM 文本到图像流程。访问底层的条件 UNet 模型:
python
pipeline.unet输出结果如下所示:
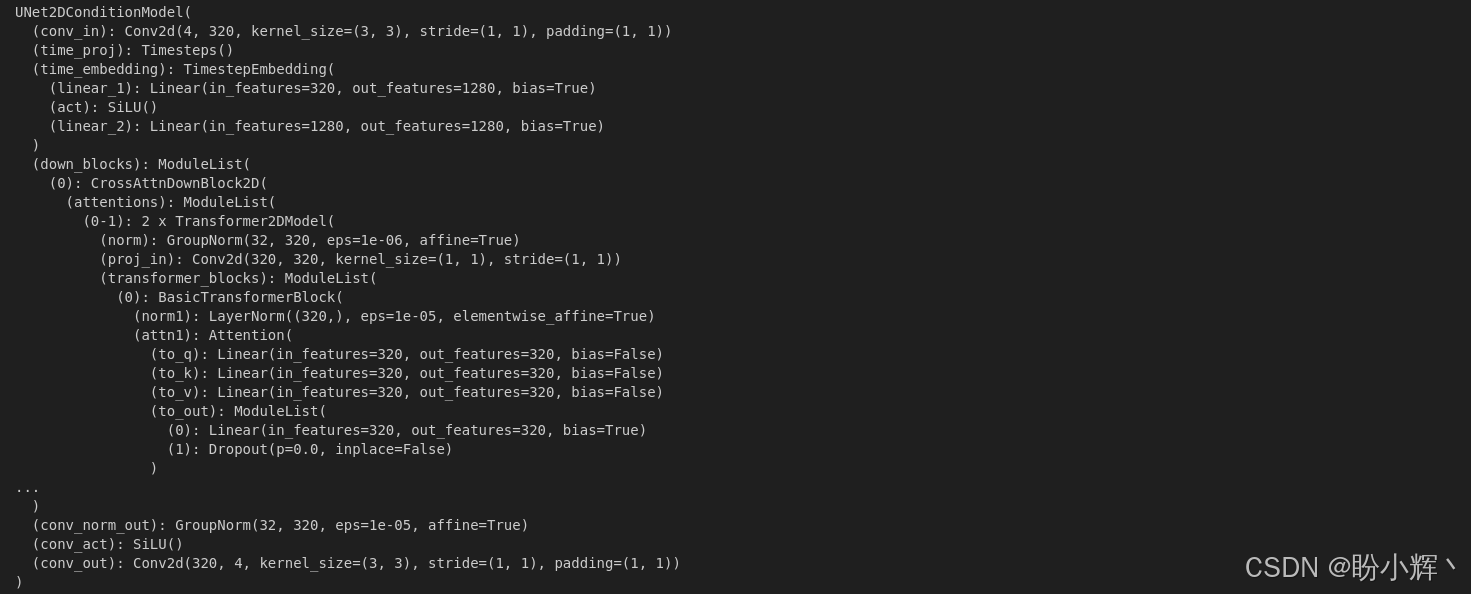
(2) 以上 UNet 模型就是条件 UNet 模型。接下来,我们将使用这个 DDPM 流程,通过输入文本(在生成式人工智能中也称为提示词,prompt )来生成高质量的逼真图像:
python
generator = [torch.Generator(device="cuda")]
image = pipeline(
"A bird is flying in sky.", generator=generator
).images[0]
image输出结果如下所示:

我们可以使用固定随机种子 (fixed seed) 来确保图像生成过程的可复现性。若移除生成器中的种子设置,每次运行都将产生不同的生成结果。
相关链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)