
1、LLM训练:一场昂贵的"计算游戏"
- 现状: 训练SOTA级别的LLM需要巨大的计算资源(算力、时间、电力)。
- 瓶颈: 训练效率是制约模型发展的核心瓶颈之一。
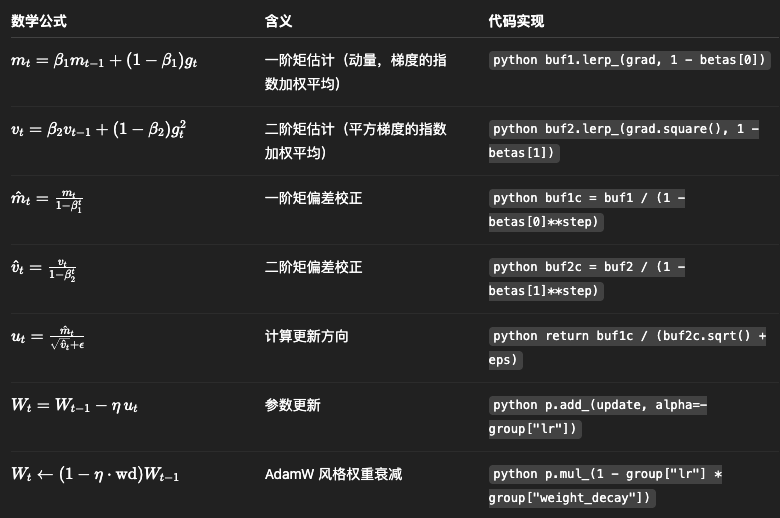
- 优化器的角色:
- 优化器决定了模型参数更新的"路径"和"步长"。
- 一个好的优化器能用更少的计算(FLOPs)达到更好的模型性能。
- AdamW 是当前大规模训练的"黄金标准",但并非没有提升空间。
问题:我们能否找到比AdamW更高效的优化器?
2、Muon优化器 - 潜力与挑战
- 什么是Muon?
- 一种基于矩阵正交化思想的优化器。
- 核心理念:将梯度动量矩阵正交化后再用于更新权重,防止权重更新过于集中在少数几个"主方向"上,鼓励模型从更多样化的维度进行学习。
- adam
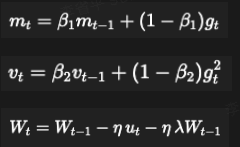
- muon
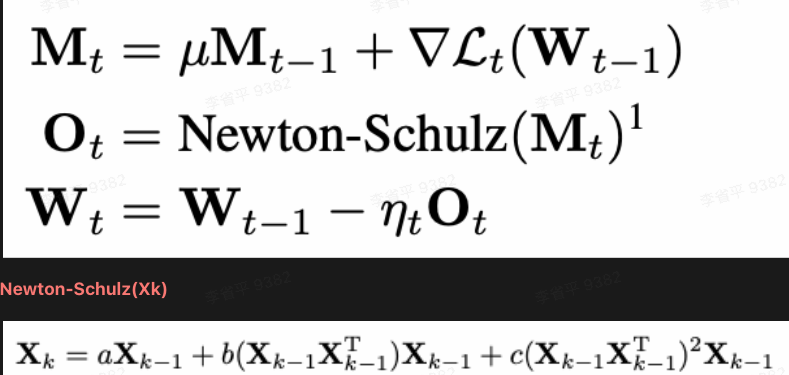
- 已证实: 在小规模模型上,Muon展现出比AdamW更快的收敛速度。
- 未证实的核心挑战: 它能扩展到万亿token、数十亿参数的大规模训练吗?
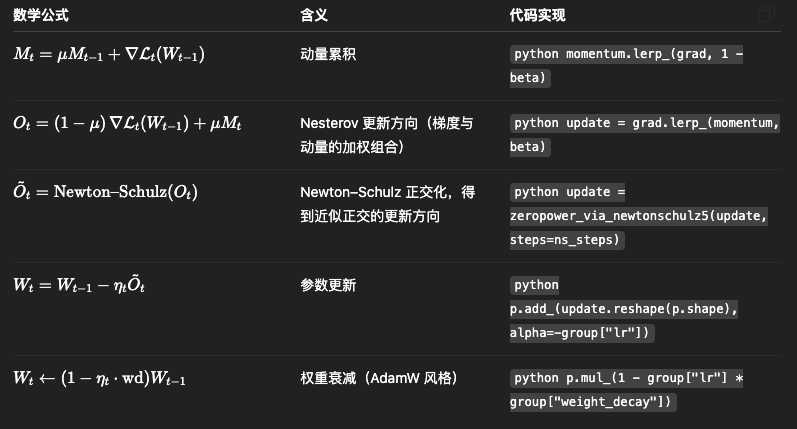
3、扩展Muon的两大关键技术
论文发现,直接扩展Muon会遇到两个核心问题,并提出了解决方案:
问题一:训练不稳定,权重持续增大
解决方案: 引入权重衰减,像AdamW一样,对权重进行正则化,有效控制其大小,保证了长序列、大规模训练的稳定性。
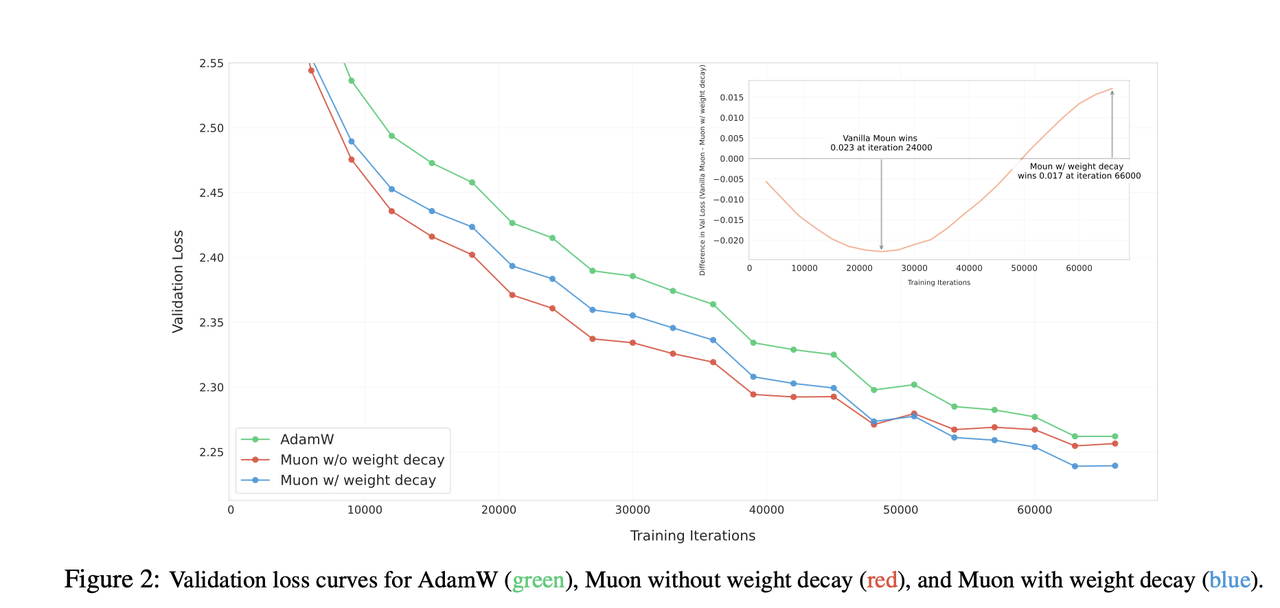
问题二:不同参数的更新幅度不一致
- 解决方案: 精细调整逐参数更新尺度 (Per-parameter Update Scale)
- 证明了Muon的更新幅度与参数矩阵的形状有关。我们通过一个缩放因子,使得所有参数的更新幅度都与AdamW对齐,从而让训练更均衡、更稳定。
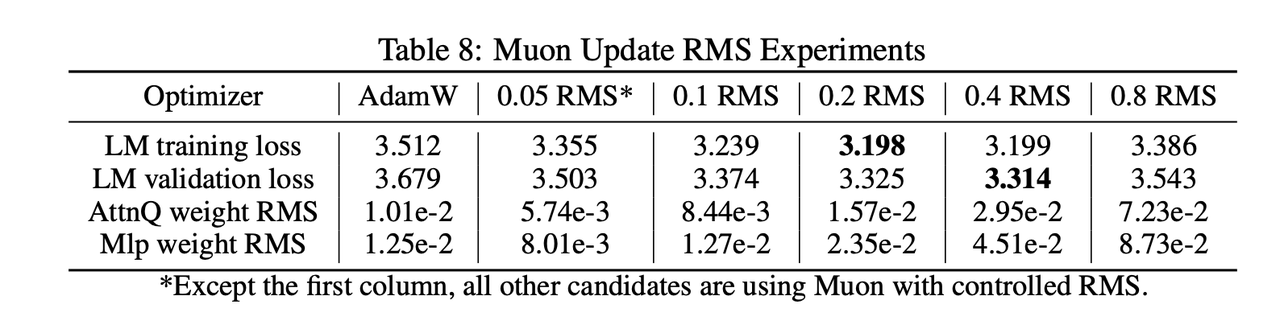
缩放因子取为0.2~0.4之间
4、实验结果 (1) - Scaling Law:效率翻倍!
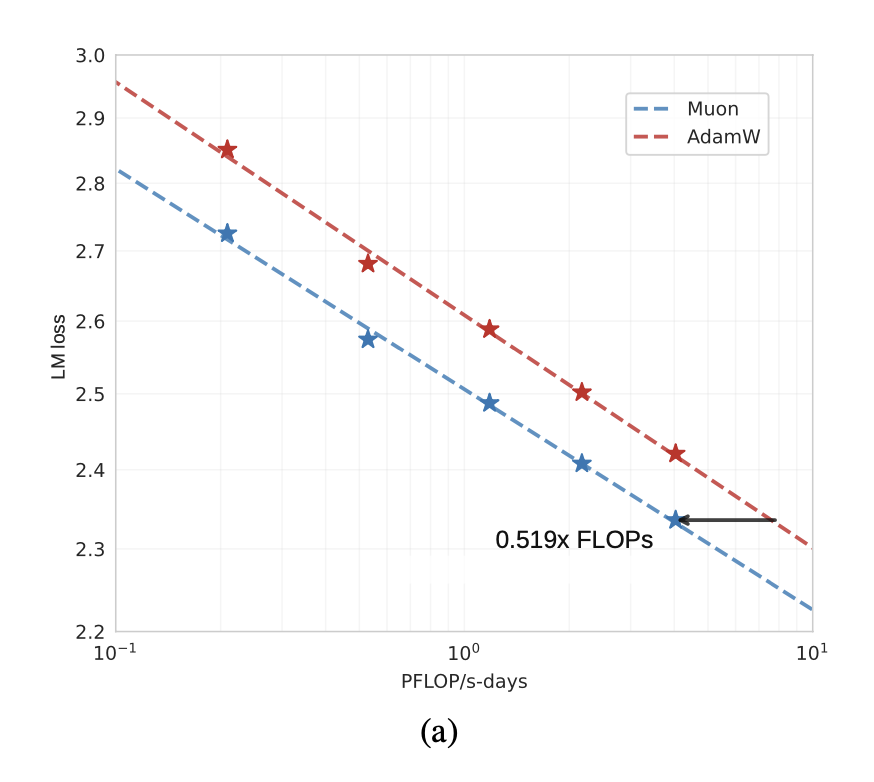
论文进行了一系列严格的Scaling Law实验,对比Muon和AdamW。
- 结论: 在同等计算资源下,Muon的Loss下降得更快、更低。
- 量化结果: 要达到相同的模型性能(Loss),Muon平均只需要AdamW约52%的训练计算量(FLOPs)。
5、实验结果 (2) - 旗舰模型 Moonlight
基于改进后的Muon,论文从头训练了一个名为Moonlight的旗舰模型。
- 模型规模: 3B激活参数 / 16B总参数的MoE模型
- 训练数据: 5.7万亿 (5.7T) tokens
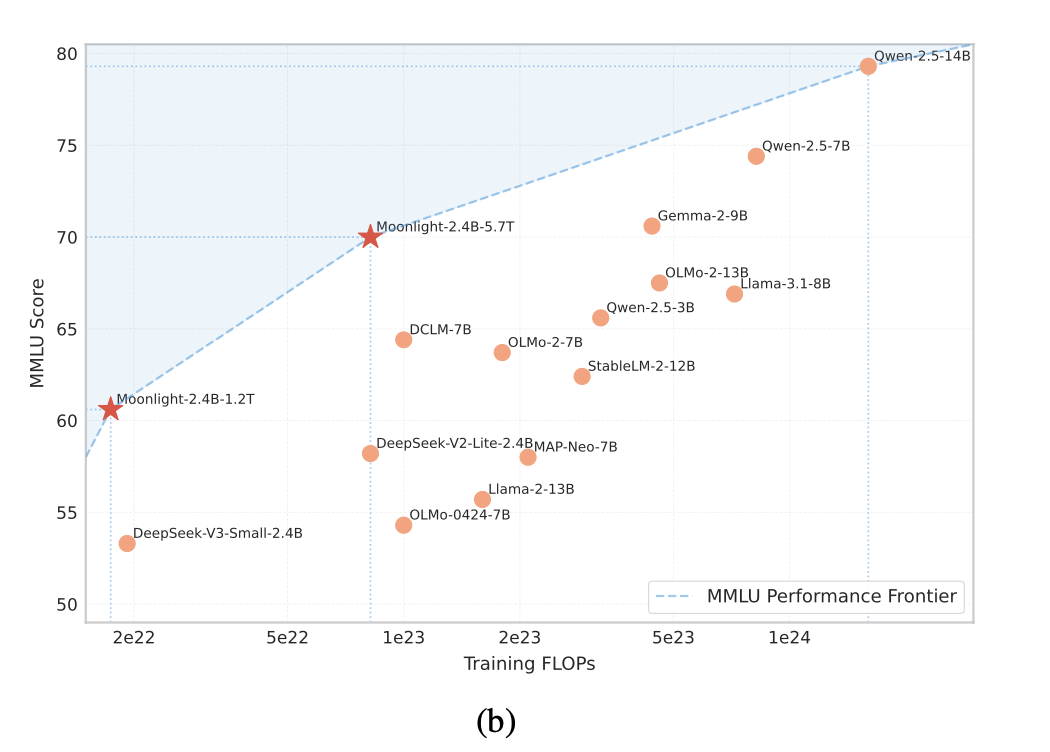
6、实验结果 (3) - Moonlight 性能SOTA
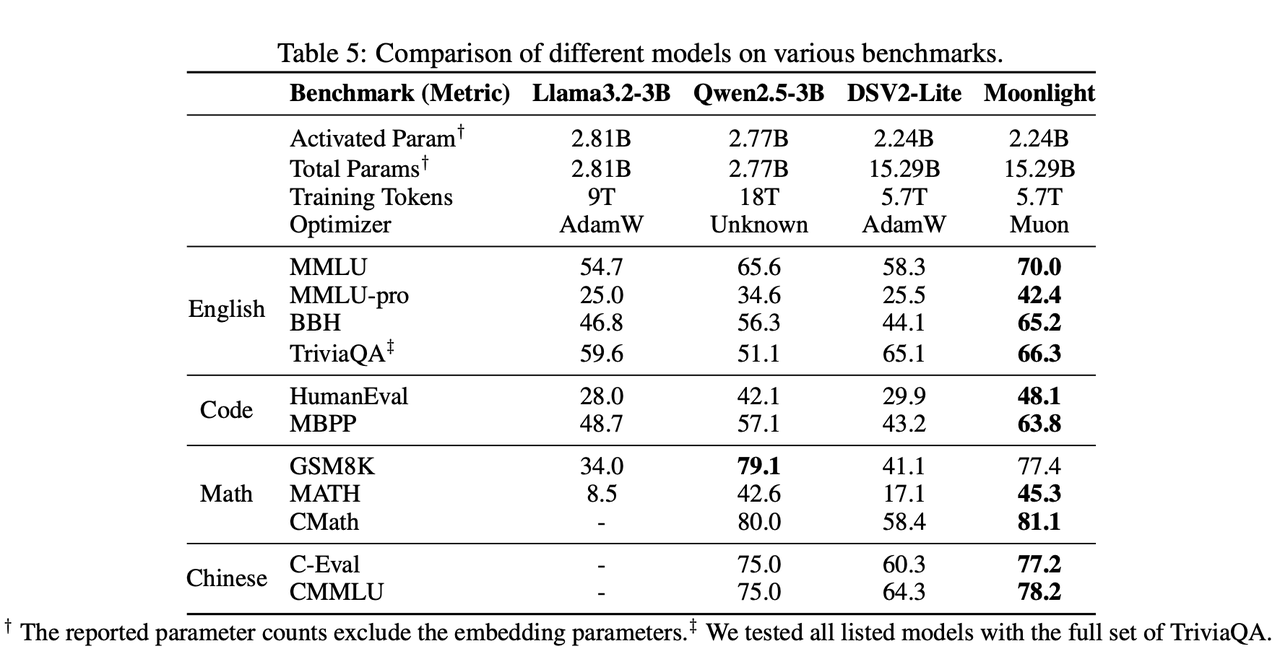
- 结论: 在同等训练量下,Moonlight的性能远超使用AdamW训练的同类模型。
- 特别是在代码和数学推理能力上,提升尤为显著。
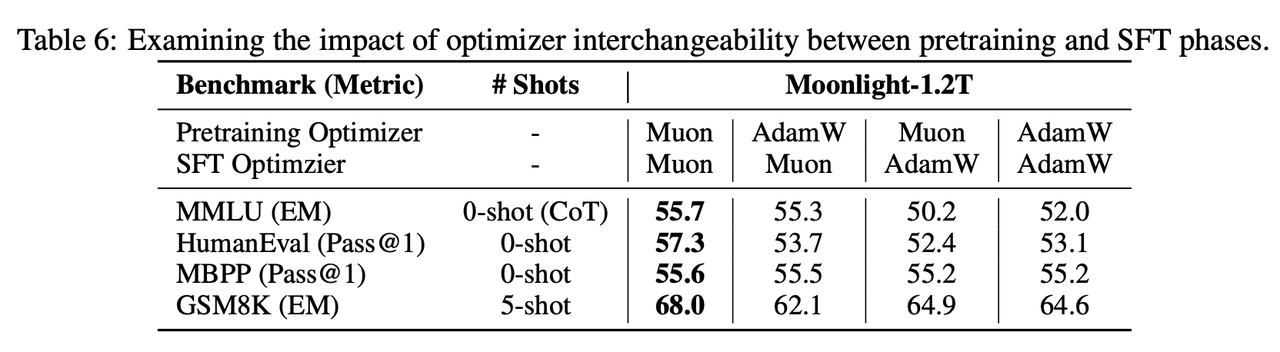
7、实验结果 (4) - SFT
结论:sft和预训练优化器应该保持一致
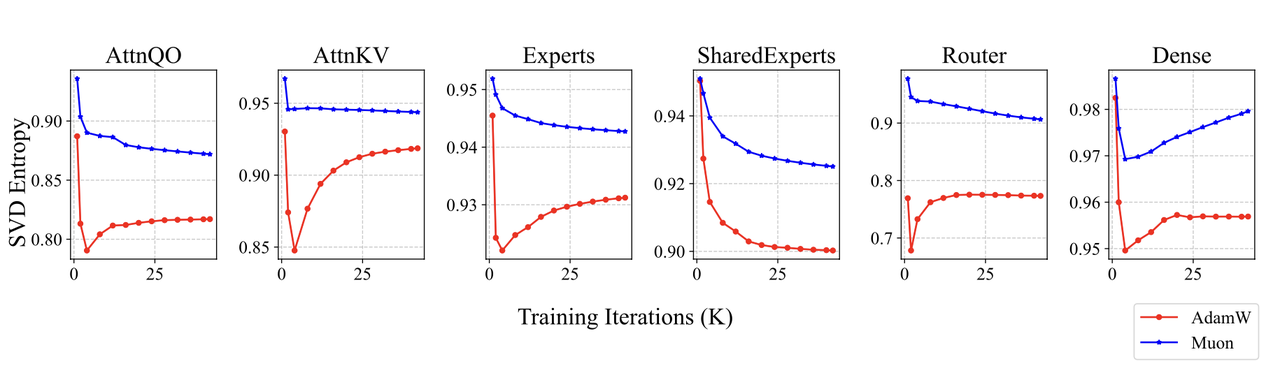
深入分析 - Muon为何如此高效?
论文通过分析模型权重矩阵的**奇异值谱(SVD Entropy)**来探究其工作原理。
- 发现:
- 由Muon训练的权重矩阵,其SVD熵显著高于AdamW。
- 直观解释:
- 高熵意味着奇异值分布更"平坦",权重矩阵的能量没有集中在少数几个方向上。
- 这印证了Muon的初衷:它能从更多样化的方向更新权重,探索更广阔、更优质的解空间,从而避免陷入局部最优。
7、总结与展望
- 总结:
- 成功识别并解决了Muon优化器的两大扩展性挑战:引入权重衰减和实现一致性更新尺度。
- 实验证明,改进后的Muon计算效率约为AdamW的2倍。
- 基于Muon训练的Moonlight模型在同等计算预算下,性能达到SOTA水平。
- 我们开源了代码、模型和 checkpoints,希望能推动社区发展。
- 未来展望:
- 将所有参数(如Embedding层)都纳入Muon的优化框架。
- 解决预训练(AdamW)和微调(Muon)优化器不匹配的问题。