目录
-
- [1.1 RLHF 的概念框架](#1.1 RLHF 的概念框架)
- [1.2 三阶段 RLHF 流程:SFT、奖励建模与策略优化](#1.2 三阶段 RLHF 流程:SFT、奖励建模与策略优化)
- [1.3 DPO 的出现:偏好微调的范式转移](#1.3 DPO 的出现:偏好微调的范式转移)
-
- [2.1 PPO 算法:稳定策略更新的核心](#2.1 PPO 算法:稳定策略更新的核心)
- [2.2 架构组件:四个模型的协同工作](#2.2 架构组件:四个模型的协同工作)
- [2.3 RL 实践循环:部署、评估与优化](#2.3 RL 实践循环:部署、评估与优化)
- [2.4 优势与挑战:适应性与复杂性的权衡](#2.4 优势与挑战:适应性与复杂性的权衡)
-
- [3.1 核心原则:你的语言模型本身就是一个隐藏的奖励模型](#3.1 核心原则:你的语言模型本身就是一个隐藏的奖励模型)
- [3.2 解构 DPO 损失函数:一个隐式的奖励机制](#3.2 解构 DPO 损失函数:一个隐式的奖励机制)
- [3.3 架构的简洁性:双模型设置](#3.3 架构的简洁性:双模型设置)
- [3.4 优势与挑战:效率与数据分布敏感性的权衡](#3.4 优势与挑战:效率与数据分布敏感性的权衡)
-
- [4.1 正面对比:详细分解](#4.1 正面对比:详细分解)
- [4.2 决策因素:一个实用的决策框架](#4.2 决策因素:一个实用的决策框架)
-
[第5节:实践教程:使用 Hugging Face TRL 实现 PPO](#第5节:实践教程:使用 Hugging Face TRL 实现 PPO)
- [5.1 阶段一:准备偏好数据集](#5.1 阶段一:准备偏好数据集)
- [5.2 阶段二:训练奖励模型 (RM)](#5.2 阶段二:训练奖励模型 (RM))
- [5.3 阶段三:配置 PPOConfig 和 PPOTrainer](#5.3 阶段三:配置 PPOConfig 和 PPOTrainer)
- [5.4 阶段四:PPO 训练循环 - 代码分步详解](#5.4 阶段四:PPO 训练循环 - 代码分步详解)
- [5.5 PPO 训练的调试与监控](#5.5 PPO 训练的调试与监控)
-
[第6节:实践教程:使用 Hugging Face TRL 实现 DPO](#第6节:实践教程:使用 Hugging Face TRL 实现 DPO)
- [6.1 阶段一:策展偏好数据集](#6.1 阶段一:策展偏好数据集)
- [6.2 阶段二:配置 DPOConfig 和 DPOTrainer](#6.2 阶段二:配置 DPOConfig 和 DPOTrainer)
- [6.3 阶段三:DPO 训练过程 - 代码分步详解](#6.3 阶段三:DPO 训练过程 - 代码分步详解)
- [6.4 DPO 的高级技术与变体](#6.4 DPO 的高级技术与变体)
-
- [7.1 方法一:针对指令遵循能力的自动化基准测试](#7.1 方法一:针对指令遵循能力的自动化基准测试)
- [7.2 方法二:使用 LLM-as-a-Judge 进行定性评估](#7.2 方法二:使用 LLM-as-a-Judge 进行定性评估)
- [7.3 综合结果:创建整体性能记分卡](#7.3 综合结果:创建整体性能记分卡)
-
- [8.1 解读您的评估结果:指标背后的含义](#8.1 解读您的评估结果:指标背后的含义)
- [8.2 面向生产部署的决策框架](#8.2 面向生产部署的决策框架)
- [8.3 对齐的未来:迭代式在线RLHF及其他](#8.3 对齐的未来:迭代式在线RLHF及其他)
第1节:后SFT时代的对齐图景:从奖励建模到直接偏好优化
在完成监督微调(Supervised Fine-Tuning, SFT )之后,语言模型已经掌握了遵循特定指令格式的能力,但它本质上仍是一个"完成"任务的引擎,即根据给定的上下文预测下一个词。然而,一个高质量的语言助手不仅需要遵循指令,更需要理解人类偏好中那些难以量化和定义的细微差别,例如"有用性"、"无害性"和"诚实性"。为了弥合模型能力与人类价值观之间的差距,**模型对齐(Alignment)**成为了关键的下一步。从人类反馈中进行强化学习(Reinforcement Learning from Human Feedback, RLHF)正是实现这一目标的核心技术框架。它通过引入人类反馈作为奖励信号,引导模型学习那些主观的、符合人类期望的行为,其核心目标是"规定"模型应如何行动以达成理想结果,而非仅仅"预测"文本序列。
1.1 RLHF的概念框架
RLHF是一种机器学习技术,它利用人类的反馈来优化模型,使其决策和输出更贴近人类的目标、需求和价值观。传统的监督学习依赖于带有固定标签的数据集,而RLHF则允许模型通过试错和人类的直接指导进行学习。其核心思想是将人类偏好整合进模型的奖励函数中,从而使模型能够执行更符合人类意图的任务。例如,当被问及"时代广场在哪里?"时,模型可能回答"纽约"或"时代广场在纽约"。RLHF 的目标就是通过收集人类对这些不同回答的偏好,训练模型生成更自然、更受欢迎的回复。
1.2 三阶段 RLHF 流程:SFT、奖励建模与策略优化
传统的 RLHF 流程,以 OpenAI 的 InstructGPT 为代表,通常包含三个核心阶段。这个流程虽然强大,但也因其复杂性而闻名。
-
监督微调 (SFT):这是对齐流程的起点,其目的是使用高质量的"指令--回答"对来微调预训练模型,使其适应特定的交互格式(如对话或问答),而不是简单续写文本。SFT 为后续对齐步骤打下基础。
-
奖励模型 (RM) 训练:这是 RLHF 的核心环节。需要构建一个"偏好数据集":对一系列提示(prompts),让 SFT 模型生成多个不同回答;由人类标注员对这些回答排序,选出偏好与不偏好版本。利用包含 (提示, 偏好回答, 不偏好回答) 的三元组数据集,训练奖励模型(Reward Model, RM),该 RM 为任意"提示--回答"对打分,分数代表对人类偏好的预测。
-
强化学习策略优化 :在此阶段,SFT 模型被视为强化学习中的策略(Policy)。训练循环:策略模型生成回答 → 奖励模型评分(获得奖励)→ 通过强化学习算法(通常为 PPO)更新策略参数以最大化累积奖励。为防止"走火入魔",通常引入 **KL 散度(KL-divergence)**惩罚,确保更新后的策略与原始 SFT 模型不偏离太远。
1.3 DPO 的出现:偏好微调的范式转移
尽管基于 PPO 的 RLHF 流程取得了巨大成功,但其复杂性(需训练和维护多个模型、在线采样循环、敏感超参数)构成高门槛。为此,出现了更简单、更稳定的方法:直接偏好优化(Direct Preference Optimization, DPO)。DPO 的革命性在于证明了无需显式训练奖励模型,也无需复杂的在线 RL 循环,仅通过一个简单的分类损失即可直接在偏好数据集上优化语言模型,达到与传统 RLHF 相当甚至更好的效果。
这种范式转变反映了机器学习向更稳定、计算效率更高、以数据为中心的方法演进。对齐的核心问题从"如何管理复杂的在线 RL 系统"转向"如何高效利用静态离线偏好数据集"。DPO 极大降低了实施对齐的资源门槛,使更多研究者与机构能构建高度对齐的模型,推动领域民主化。
第2节:深度剖析:近端策略优化 (PPO)
近端策略优化(Proximal Policy Optimization, PPO)是 RLHF 框架中最常用的强化学习算法。理解其原理、架构组件与优缺点,是成功实施传统 RLHF 的关键。
2.1 PPO 算法:稳定策略更新的核心
PPO 的核心动机是:在当前数据基础上尽可能改进策略,同时避免单步更新过大导致性能崩溃。其前身 TRPO 使用复杂的二阶优化,而 PPO 采用更简单的一阶方法并在实践中表现优秀。
PPO 的关键机制是截断代理目标函数(Clipped Surrogate Objective) 。每次更新计算新旧策略对动作的概率比率,并将其截断在由超参数 ϵ \epsilon ϵ(在 TRL 库中通常表示为 cliprange)定义的区间 1 − ϵ , 1 + ϵ 1-\\epsilon, 1+\\epsilon 1−ϵ,1+ϵ。该机制防止一次更新使策略偏离过远,从而保证训练稳定性。在大型语言模型的巨大参数空间中,这种稳定性尤为重要,因为一次错误更新可能导致灾难性下降。
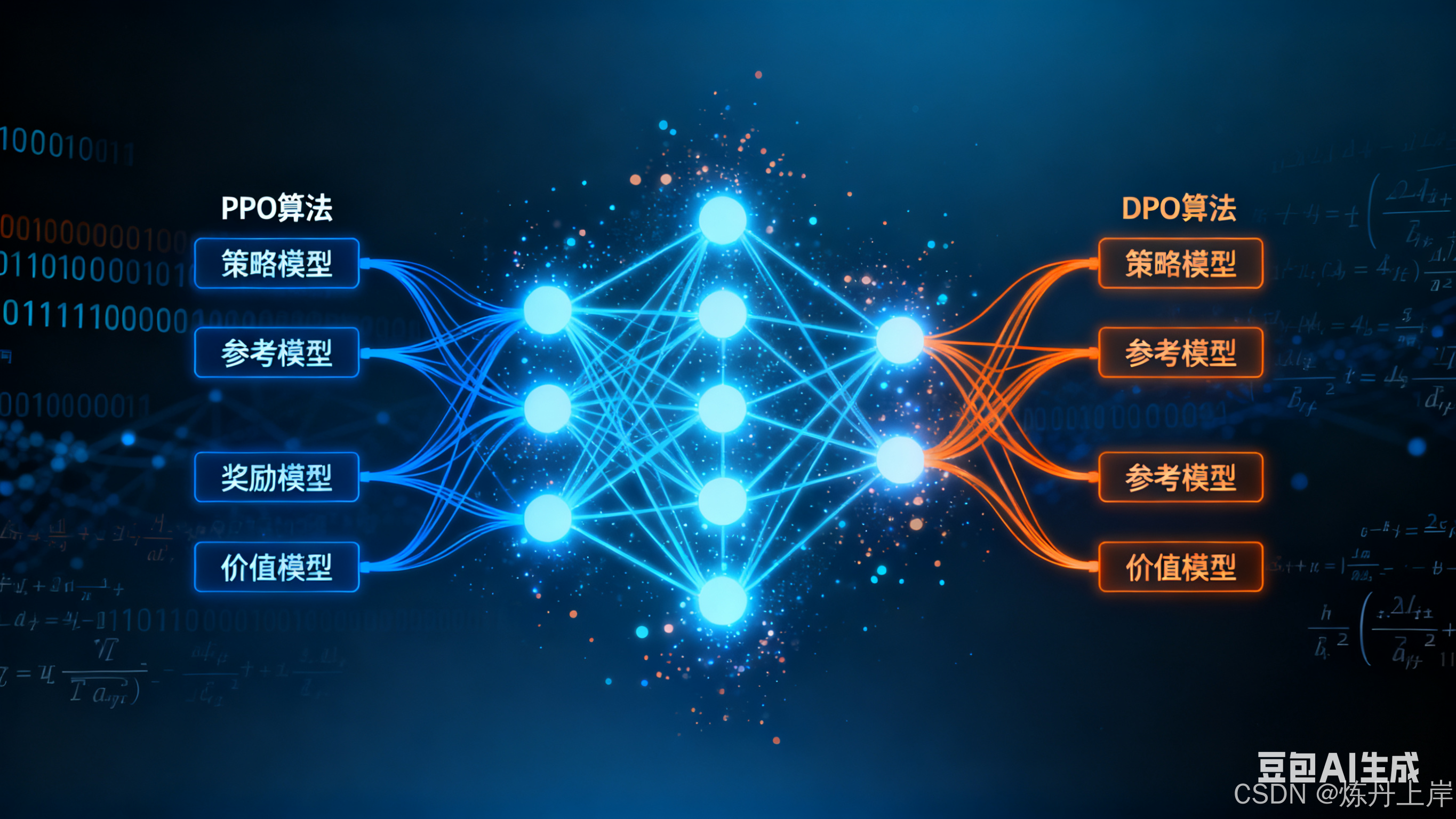
2.2 架构组件:四个模型的协同工作
PPO 的实现复杂且计算开销大,主要因为训练过程通常需要同时维护四个模型:
- 策略模型 (Policy Model):正在训练的语言模型,用于生成回答(动作)。
- 参考模型 (Reference Model):SFT 模型的冻结副本,用于计算 KL 散度惩罚,确保策略不偏离 SFT 分布。
- 奖励模型 (Reward Model, RM):预先训练的模型,为"提示--回答"对输出标量奖励,用作优化目标。
- 价值/评论家模型 (Value/Critic Model) :估计给定状态下未来期望总奖励。通常与策略模型集成(如 Hugging Face TRL 的
AutoModelForCausalLMWithValueHead)。价值模型用于计算优势(Advantage),有助于稳定训练并减少奖励方差。
同时管理四个模型对硬件提出巨大挑战,因此常使用参数高效微调(PEFT,如 LoRA)或分布式训练(DeepSpeed/FSDP)。
2.3 RL 实践循环:部署、评估与优化
PPO 训练通常遵循"部署--评估--优化"循环:
- 部署 (Rollout):策略模型接收批量提示并生成完整回答序列(采样)。
- 评估 (Evaluation):奖励模型为每个生成的"提示--回答"对评分,计算标量奖励;同时计算策略模型与参考模型生成该回答时的对数概率之间的 KL 散度,作为惩罚项。
- 优化 (Optimization):利用奖励与 KL 惩罚,PPO 更新策略与价值模型参数,目标是最大化奖励并受 KL 约束以保证稳定性。
PPO 属于on-policy算法,总是从最新策略采样以实现探索与利用的平衡。
2.4 优势与挑战:适应性与复杂性的权衡
优势:
- 高度适应性,对数据分布变化鲁棒。
- 在需要迭代探索的复杂任务(例如数学、代码生成)中表现强劲。精心调优的 PPO 有潜力超过离线方法如 DPO。
挑战:
- 极高复杂性:计算成本高、实现复杂、超参数敏感(学习率、cliprange、KL 系数等)。
- 需要协调奖励/价值模型的监督学习与策略的在线 RL,若两者不一致,可能出现奖励滥用(reward hacking)。因此偏好数据集与奖励模型质量是 PPO 成功的瓶颈。
第3节:深度剖析:直接偏好优化 (DPO)
直接偏好优化(DPO)是一种现代对齐方法,因其理论优雅与实现简洁而受到关注。本节解读 DPO 的核心原理、损失函数与架构优势。
3.1 核心原则:你的语言模型本身就是一个隐藏的奖励模型
DPO 的基石是:语言模型自身即可作为隐式奖励模型。DPO 证明标准 RLHF 的最终优化目标可以不经过显式奖励模型,而直接在偏好数据上进行优化。其隐式奖励由策略模型 π θ \pi_\theta πθ 与冻结的参考模型 π r e f \pi_{ref} πref 之间的对数概率差定义,将多阶段 RLHF 映射为更简单的监督目标。
3.2 解构 DPO 损失函数:一个隐式的奖励机制
DPO 的损失函数为:
\\mathcal{L}*{\\mathrm{DPO}} = -\\mathbb{E}* {(x, y_w, y_l) \\sim D} \\left\[ \\log \\sigma!\\left( \\beta \\log \\frac{\\pi_{\\theta}(y_w \\mid x)}{\\pi_{\\mathrm{ref}}(y_w \\mid x)} * \\beta \\log \\frac{\\pi_{\\theta}(y_l \\mid x)}{\\pi_{\\mathrm{ref}}(y_l \\mid x)} \\right) \\right\]
其中:
- ( x , y w , y l ) ∼ D (x, y_w, y_l) \sim D (x,yw,yl)∼D:偏好数据集的三元组(提示 x,偏好回答 y w y_w yw,不偏好回答 y l y_l yl)。
- π θ ( y ∣ x ) \pi_\theta(y\mid x) πθ(y∣x) 与 π r e f ( y ∣ x ) \pi_{\mathrm{ref}}(y\mid x) πref(y∣x):策略模型与参考模型对回答的条件概率。
- β \beta β:控制模型与参考模型偏离程度的超参数(类似于 PPO 的 KL 系数)。
- log σ ( ⋅ ) \log \sigma(\cdot) logσ(⋅):相当于二元交叉熵损失,目标是让被偏好回答相对于不被偏好回答在隐式奖励上更占优。
通过最小化该损失,模型被引导提高生成 y w y_w yw 的概率,同时降低生成 y l y_l yl 的概率(相对于参考模型),从而实现与人类偏好的对齐。
3.3 架构的简洁性:双模型设置
与 PPO 的四模型架构相比,DPO 在训练时只需两台模型:
- 策略模型 (Policy Model):正在训练的语言模型。
- 参考模型 (Reference Model):SFT 模型的冻结副本。
这一架构简化显著降低了实现门槛与硬件需求,使更多研究者能够应用对齐技术。
3.4 优势与挑战:效率与数据分布敏感性的权衡
优势:
- 实现更简单、训练更稳定、计算效率更高、训练更快。
- 在许多基准上与 PPO 持平或更优。
挑战:
- 作为离线方法,DPO 对偏好数据集质量和分布高度依赖。若训练数据与实际提示分布差异大,泛化能力可能受损,并可能放大训练数据中的偏见。
- 特别是"不被偏好(rejected)"样本的质量至关重要:若 rejected 回答质量极差或与 chosen 极为相似,学习信号会薄弱。最佳实践是让 rejected 为"合理但不如 chosen"的回答,例如通过从 SFT 模型采样多个候选、用奖励模型或 LLM-as-a-judge 选出 best / 2nd best 来构建高质量偏好对。
DPO 的成功将对齐研究重心从"算法调优"转向"数据策展",体现"以数据为中心的 AI"理念。
第4节:对比分析:选择你的对齐策略
本节给出 PPO 与 DPO 的直接对比,帮助根据项目需求和资源约束做出选择。
4.1 正面对比:详细分解
表 4.1:PPO 与 DPO --- 对比分析
| 标准 | PPO (近端策略优化) | DPO (直接偏好优化) |
|---|---|---|
| 核心机制 | 在线策略强化学习(On-policy Reinforcement Learning) | 离线直接偏好优化(Offline, direct preference optimization),本质为分类任务 |
| 所需组件 | 4 个模型:策略、参考、奖励、价值/评论家 | 2 个模型:策略、参考 |
| 计算成本 | 高(显存与训练时间均高) | 低 |
| 实现复杂度 | 高(管理 RL 循环、多模型、众多超参) | 低(类似监督微调流程) |
| 训练稳定性 | 相对不稳定;需调参(clip、KL) | 稳定性高;直接梯度优化不易崩溃 |
| 数据需求 | 偏好数据训练 RM + 在线采样数据(rollouts) | 仅需离线偏好对数据(prompt, chosen, rejected) |
| 性能特点 | 在复杂探索任务(如代码、推理)上强劲;精调可达到更高上限 | 在高质量偏好数据上表现出色,在许多基准与 PPO 持平或超越 |
| 主要弱点 | 复杂、高成本、可能出现奖励滥用 | 对离线偏好数据质量/分布高度敏感 |
4.2 决策因素:一个实用的决策框架
选择 PPO 的场景:
- 任务复杂度高(需要探索、创造性、多步推理)。
- 计算资源充足(足够 GPU/TPU 内存与训练时间)。
- 团队具备 RLHF 调试与调优经验。
选择 DPO 的场景:
- 已有高质量偏好数据或能构建高质量偏好对。
- 计算资源有限,希望快速、稳定地完成对齐。
- 更看重易用性、可维护性与快速迭代。
- 任务目标明确(风格/格式/可用性等局部对齐目标)。
两者并非截然对立:精心调优的 PPO 在某些场景可超越 DPO,但 DPO 提供了更低的门槛和更高的性价比。选择也是战略性的:大型实验室偏向追求极致性能(PPO),开源社区/中小团队往往优先可复现性与成本效益(DPO)。近期在 Zephyr、Mixtral 等模型上的 DPO 应用体现了这种实用主义需求。
第5节:实践教程:使用 Hugging Face TRL 实现 PPO
本节把理论转为实践,给出使用 trl 库实现 PPO 的分步指南与代码示例。
5.1 阶段一:准备偏好数据集
PPO 流程第一步是训练奖励模型,需要偏好数据集。每条通常包含提示(prompt)及两份模型生成回答:chosen(更好)与 rejected(更差)。
可以直接加载 Hugging Face Hub 上的现成数据集,例如 HuggingFaceH4/ultrafeedback-binarized。
python
from datasets import load_dataset
# 加载用于训练奖励模型的数据集
reward_dataset = load_dataset("HuggingFaceH4/ultrafeedback-binarized", split="train_prefs")
# 数据集通常需要被格式化为包含 'chosen' 和 'rejected' 键的字典列表
# Ultrafeedback 已经符合这个格式
print(reward_dataset)
# {'prompt': '...', 'chosen': [...], 'rejected': [...]}5.2 阶段二:训练奖励模型 (RM)
使用 trl 中的 RewardTrainer 将奖励建模视为二元排序/回归任务(给两条回答预测哪个更优或直接给分)。
python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments
from trl import RewardTrainer
# 1. 加载模型和分词器
rm_model_name = "microsoft/deberta-v3-base"
rm_model = AutoModelForSequenceClassification.from_pretrained(rm_model_name, num_labels=1, torch_dtype=torch.bfloat16)
rm_tokenizer = AutoTokenizer.from_pretrained(rm_model_name)
# 2. 定义训练参数
training_args = TrainingArguments(
output_dir="./reward_model",
per_device_train_batch_size=4,
num_train_epochs=1,
gradient_accumulation_steps=4,
learning_rate=1e-5,
logging_steps=10,
save_strategy="epoch",
report_to="tensorboard",
)
# 3. 预处理函数
def preprocess_function(examples):
tokenized_chosen = rm_tokenizer(examples["chosen"], truncation=True)
tokenized_rejected = rm_tokenizer(examples["rejected"], truncation=True)
examples["input_ids_chosen"] = tokenized_chosen["input_ids"]
examples["attention_mask_chosen"] = tokenized_chosen["attention_mask"]
examples["input_ids_rejected"] = tokenized_rejected["input_ids"]
examples["attention_mask_rejected"] = tokenized_rejected["attention_mask"]
return examples
# 4. 预处理数据集
processed_dataset = reward_dataset.map(preprocess_function, batched=True)
# 5. 初始化并开始训练
trainer = RewardTrainer(
model=rm_model,
tokenizer=rm_tokenizer,
args=training_args,
train_dataset=processed_dataset,
)
trainer.train()
trainer.save_model("./reward_model_final")5.3 阶段三:配置 PPOConfig 和 PPOTrainer
训练完奖励模型后,配置 PPO 并初始化训练器。
python
from trl import PPOConfig, PPOTrainer, AutoModelForCausalLMWithValueHead
# 1. PPO 配置
config = PPOConfig(
model_name="path/to/your/sft_model", # 指向已完成 SFT 的模型
learning_rate=1.41e-5,
log_with="tensorboard",
kl_penalty="kl",
kl_coef=0.05, # KL 散度惩罚系数
cliprange=0.2, # PPO 截断范围
vf_coef=0.1, # 价值函数损失系数
batch_size=64,
mini_batch_size=16,
gradient_accumulation_steps=4,
)
# 2. 加载策略模型和参考模型
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name, torch_dtype=torch.bfloat16)
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name, torch_dtype=torch.bfloat16)
# 3. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_token
# 4. 初始化 PPOTrainer
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer)5.4 阶段四:PPO 训练循环 --- 代码分步详解
PPO 为在线循环:模型生成回答 → 奖励模型打分 → PPO 更新。
python
from tqdm import tqdm
import torch
# 假设 reward_model 和 reward_tokenizer 已加载
reward_model = AutoModelForSequenceClassification.from_pretrained("./reward_model_final").to(ppo_trainer.device)
reward_tokenizer = AutoTokenizer.from_pretrained("./reward_model_final")
# 加载用于生成回答的提示数据集
query_dataset = load_dataset("HuggingFaceH4/cherry_picked_prompts", split="train")
# PPO 训练循环
for epoch in range(config.ppo_epochs):
for batch in tqdm(ppo_trainer.dataloader):
query_tensors = batch["input_ids"]
# 1. 从策略模型生成回答 (Rollout)
response_tensors = ppo_trainer.generate(query_tensors, return_prompt=False, length_sampler=output_length_sampler)
batch["response"] = tokenizer.batch_decode(response_tensors)
# 2. 计算奖励 (Evaluation)
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
reward_inputs = reward_tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(ppo_trainer.device)
with torch.no_grad():
rewards = reward_model(**reward_inputs).logits
# 3. PPO 优化步骤 (Optimization)
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)5.5 PPO 训练的调试与监控
PPO 训练可能不稳定,需密切监控关键指标:
objective/rlhf_reward:训练目标,应持续上升(若训练正常)。val/ratio:应在 1.0 附近波动;若非常大(如 2.0)或非常小(如 0.1),说明新旧策略更新幅度问题,可能需调整kl_coef。- 内存管理 :若显存不足,减小
per_device_train_batch_size或增加gradient_accumulation_steps;多 GPU 时使用 DeepSpeed Stage 3。 - EOS 技巧 :设置
missing_eos_penalty对未以 EOS 结束的生成施加惩罚,促进完整输出。
第6节:实践教程:使用 Hugging Face TRL 实现 DPO
DPO 的实现更接近监督微调,流程大幅简化。以下为基于 trl 的实践指南。
6.1 阶段一:策展偏好数据集
DPO 需要三列数据:prompt、chosen(被偏好回答)、rejected(不被偏好回答)。可以使用现成数据集 trl-lib/ultrafeedback_binarized 或自行构建。
python
from datasets import load_dataset
# DPO 需要的数据集格式
dpo_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# 检查格式
print(dpo_dataset)
# {'prompt': '...', 'chosen': '...', 'rejected': '...'}高级数据策展技术:
- 拒绝采样 (Rejection Sampling):用 SFT 模型为每个提示生成多候选(4--8),用奖励模型或 LLM-as-a-judge 打分,取最高与最低构成 (chosen, rejected) 对,信号更强。
- 利用现有高质量回答 :用外部高质量回答作为
chosen,用 SFT 模型生成的回答作为rejected,假设外部数据质量更高。
6.2 阶段二:配置 DPOConfig 和 DPOTrainer
DPO 配置更简单,关键超参数为 beta。
python
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from trl import DPOTrainer, DPOConfig
# 1. 加载 SFT 模型和分词器
model_name = "path/to/your/sft_model"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
# 参考模型可不显式加载,DPOTrainer 会自动创建副本
ref_model = None
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 2. DPO 训练参数配置
training_args = DPOConfig(
output_dir="./dpo_model",
beta=0.1, # DPO 损失中的正则化参数
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=5e-6,
num_train_epochs=1,
logging_steps=10,
save_strategy="epoch",
report_to="tensorboard",
max_prompt_length=512, # 提示最大长度
max_length=1024, # 提示+回答最大长度
)
# 3. 初始化 DPOTrainer
dpo_trainer = DPOTrainer(
model,
ref_model,
args=training_args,
train_dataset=dpo_dataset,
tokenizer=tokenizer,
)6.3 阶段三:DPO 训练过程 --- 代码分步详解
DPO 训练较直接,初始化 DPOTrainer 后直接 .train()。
python
# 开始训练
dpo_trainer.train()
# 保存模型
dpo_trainer.save_model("./dpo_model_final")
# (可选) 推送到 Hugging Face Hub
# from huggingface_hub import notebook_login
# notebook_login()
# dpo_trainer.push_to_hub("your-username/your-dpo-model-name")6.4 DPO 的高级技术与变体
DPO 的成功催生多个变体/改进方法(部分已集成至 trl):
- IPO (Identity Preference Optimisation):在 DPO 损失中添加正则化项,增强训练鲁棒性,减少对早停的依赖。
- KTO (Kahneman-Tversky Optimisation):无需成对偏好数据,可用单样本的"好/坏"标签训练,便于某些数据采集流程。
- ORPO (Odds-Ratio Policy Optimization):将 SFT 的负对数似然损失与基于偏好的几率比损失结合,能在单阶段中同时完成 SFT 与偏好对齐,无需先单独 SFT。
这些前沿技术为在 DPO 基础上继续提升对齐效果提供路径。
第7节:多维度模型评估框架
完成 PPO 与 DPO 训练后,评估是关键。需要结合自动化基准与定性分析来全面了解模型能力。
7.1 方法一:针对指令遵循能力的自动化基准测试
常见基准:
- AlpacaEval :快速、低成本的自动化评估工具。用强大 LLM(如 GPT-4)作为裁判,比较你模型与基准(如
davinci-003)在 AlpacaFarm 指令集上的回答,输出胜率。与人类偏好有较好相关性,但可能偏向较长答案。 - MT-Bench:更具挑战性,评估多轮对话能力(写作、推理、编码等),由强大 LLM 作为裁判,对 80 个高质量多轮对话评分。
实践指南:
- 部署模型 API(兼容 OpenAI 接口)。工具如
vLLM可高效部署。 - 生成回答并保存。
- 运行评估脚本,将回答与基准发送给裁判 LLM(如 GPT-4o),生成报告。
7.2 方法二:使用 LLM-as-a-Judge 进行定性评估
自动化基准无法捕捉特定场景细微差异,使用 LLM 作为裁判可以进行定制化定性评估。
实践指南:
-
定义评估标准:明确"更好"含义(准确性、简洁性、语气、可行性等)。
-
准备评估数据集:小而多样化,贴近实际场景。为每个提示收集 PPO 与 DPO 的回答。
-
设计裁判提示(Judge Prompt),包含:
- 用户原始提示
- 来自两个模型的回复(随机打乱顺序以避免位置偏见)
- 详细评估标准
- 指示裁判先给出推理(chain-of-thought),再做判定(A 更好 / B 更好 / 两者相当)
-
执行与分析:运行裁判 LLM,统计胜率并深入分析裁判提供的推理,提取定性洞见。
可用工具:deepeval、llm-comparator 等以简化与可视化比较过程。
7.3 综合结果:创建整体性能记分卡
单一指标不足以全面反映模型优劣。建议构建一份综合记分卡,汇总定量和定性评估结果。
表 7.1:模型性能记分卡
| 评估指标 | PPO 调优模型 | DPO 调优模型 | 分析与备注 |
|---|---|---|---|
| AlpacaEval 2.0 胜率 (%) | 填写分数 | 填写分数 | 衡量通用单轮指令遵循能力 |
| MT-Bench 总分 | 填写分数 | 填写分数 | 衡量多轮对话综合能力 |
| MT-Bench(写作能力) | 填写分数 | 填写分数 | 创意/正式写作表现 |
| MT-Bench(推理能力) | 填写分数 | 填写分数 | 逻辑推理表现 |
| LLM-as-a-Judge 胜率 (%) | 填写分数 | 填写分数 | 自定义任务的对齐度 |
| 定性总结 | 填写文本 | 填写文本 | 例如:倾向更长/更创造性,但偶尔偏离主题 |
第8节:最终综合与战略建议
在完成评估后,如何解读结果并做出生产部署决策至关重要。本节提供解读与决策框架。
8.1 解读您的评估结果:指标背后的含义
性能记分卡是决策核心。解读时关注趋势而非孤立数字。例如:
- 若 PPO 在 MT-Bench 的推理子项得分更高,说明其在复杂推理任务上具备优势。
- 若 DPO 在 LLM-as-a-judge 的自定义评估上胜率更高,说明其更贴合具体业务需求。
重点是寻找模式:一个模型是否在创造性任务上常胜,而另一个在事实准确性上更可靠?从裁判 LLM 的推理中提取的定性洞察通常比微小的数值差异更有价值。
8.2 面向生产部署的决策框架
选择生产模型,应综合考虑:
- 性能:哪个模型在关键指标上表现更好?是通用能力(MT-Bench)重要,还是特定领域的对齐度(LLM-as-a-Judge)更关键?
- 成本与延迟:推理成本与响应时间是否在可接受范围内?一个性能稍优但成本过高的模型可能不适合生产。
- 可维护性与迭代:后续更新的便利性如何?DPO 的简洁流程可能更适合长期迭代与持续改进。
最终"最佳"模型是与产品需求、预算与技术栈最匹配的那个,而非单纯学术基准上的最高分者。
8.3 对齐的未来:迭代式在线 RLHF 及其他
所构建的 PPO 或 DPO 流程是更高级对齐系统的基石。对齐是持续过程,未来趋势包括迭代式在线 RLHF:在生产中持续收集用户偏好(如点赞/点踩),并以此定期更新模型。你现在掌握的技能将是构建下一代自适应、持续学习系统的基础。