文章目录
- 前言
-
- [1. 什么是Java集合体系?](#1. 什么是Java集合体系?)
- [2. 集合体系整体架构(含图解)](#2. 集合体系整体架构(含图解))
- [3. Collection体系详解](#3. Collection体系详解)
-
- [3.1 List:有序可重复集合](#3.1 List:有序可重复集合)
-
- [3.1.1 核心实现类对比](#3.1.1 核心实现类对比)
- [3.1.2 核心操作示例(ArrayList)](#3.1.2 核心操作示例(ArrayList))
- [3.1.3 底层结构图解(ArrayList)](#3.1.3 底层结构图解(ArrayList))
- [3.2 Set:无序唯一集合](#3.2 Set:无序唯一集合)
-
- [3.2.1 核心实现类对比](#3.2.1 核心实现类对比)
- [3.2.2 核心操作示例(HashSet)](#3.2.2 核心操作示例(HashSet))
- [3.3 Queue:先进先出队列](#3.3 Queue:先进先出队列)
-
- [3.3.1 核心实现类](#3.3.1 核心实现类)
- [3.3.2 底层结构图解(PriorityQueue)](#3.3.2 底层结构图解(PriorityQueue))
- [4. Map体系详解](#4. Map体系详解)
-
- [4.1 核心实现类对比(重点)](#4.1 核心实现类对比(重点))
- [4.2 核心操作示例(HashMap)](#4.2 核心操作示例(HashMap))
- [4.3 底层结构图解(HashMap JDK 8+)](#4.3 底层结构图解(HashMap JDK 8+))
- [5. 核心技术点:遍历、线程安全与排序](#5. 核心技术点:遍历、线程安全与排序)
-
- [5.1 集合遍历方式(3种常用)](#5.1 集合遍历方式(3种常用))
- [5.2 线程安全问题与解决方案](#5.2 线程安全问题与解决方案)
-
- [5.2.1 线程不安全的集合](#5.2.1 线程不安全的集合)
- [5.2.2 解决方案(3种)](#5.2.2 解决方案(3种))
- [5.3 集合排序:Comparable vs Comparator](#5.3 集合排序:Comparable vs Comparator)
- [6. 集合选型指南(实战表格)](#6. 集合选型指南(实战表格))
- [7. 总结](#7. 总结)
前言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在Java开发中,"存储与操作多个数据"是高频需求,数组虽能存储数据,但存在"长度固定、仅支持下标访问"的局限性。Java集合体系通过标准化接口与多样化实现,提供了灵活、高效的数据存储方案,覆盖"线性存储、无序唯一、键值映射"等场景。本文将从整体架构到核心实现,拆解Java集合的设计逻辑与实战要点(基于JDK 8+)
。
1. 什么是Java集合体系?
Java集合体系是用于存储、操作多个对象的工具类集合 ,位于java.util包下,核心目标是解决"数组灵活性不足"的问题,具备以下特性:
- 动态扩容:无需预先指定长度,自动适配数据量变化;
- 丰富操作:内置增删改查、排序、筛选等方法;
- 多场景适配:支持有序/无序、重复/唯一、键值映射等不同需求;
- 接口标准化:通过
Collection/Map等顶层接口统一API,降低使用成本。
注意:集合仅存储对象引用 (基本类型需用包装类,如
Integer替代int),且Collection存储"单个对象",Map存储"键值对(Key-Value)",两者是独立体系。
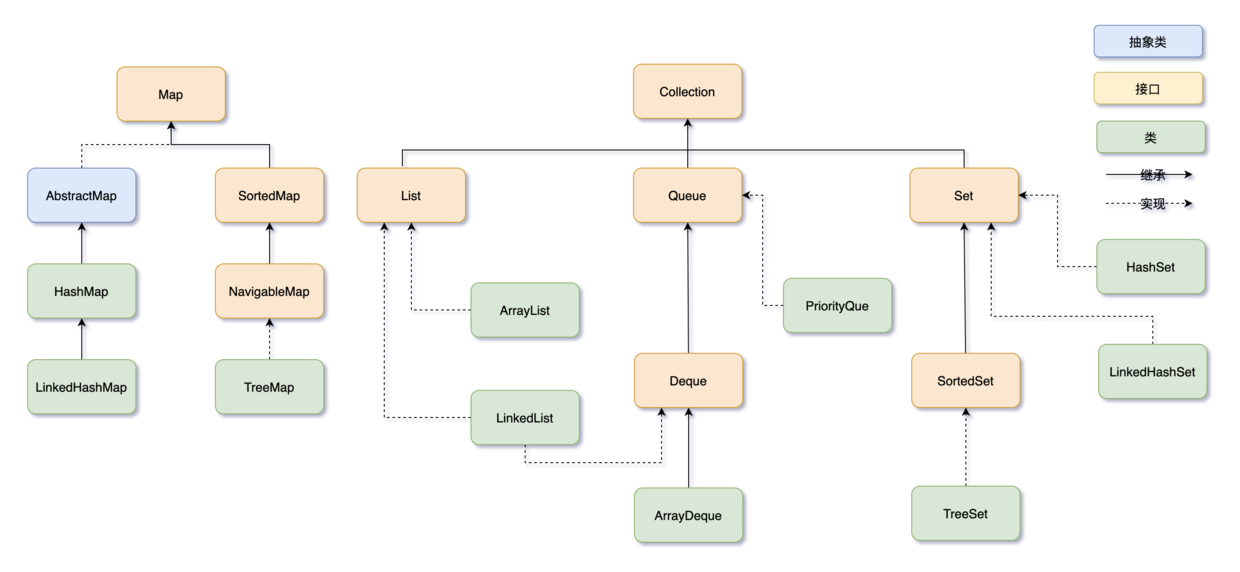
2. 集合体系整体架构(含图解)
Java集合体系以两大顶层接口为核心,衍生出多个子接口与实现类,整体结构如下:
关键说明:
- 标"旧"的实现类(Vector/Hashtable)因性能问题,仅兼容旧代码,新开发优先用线程安全替代类(如ConcurrentHashMap);
- 所有实现类均实现
Serializable(可序列化)与Cloneable(可克隆)接口,支持对象持久化与复制。
3. Collection体系详解
Collection是所有"单个对象存储集合"的顶层接口,定义了通用方法(add()/remove()/size()/iterator()等),核心子接口为List/Set/Queue。
3.1 List:有序可重复集合
List接口的核心特性是**"有序(插入顺序)、可重复、支持下标访问"**,适合需按顺序存储且允许重复数据的场景(如购物车、任务列表)。
3.1.1 核心实现类对比
| 实现类 | 底层结构 | 线程安全 | 随机访问效率 | 插入/删除效率(中间) | 扩容机制 | 适用场景 |
|---|---|---|---|---|---|---|
| ArrayList | 动态数组 | 否 | 高(O(1)) | 低(O(n),需移动元素) | 初始容量10,满后扩容1.5倍 | 频繁随机访问、少插入删除的场景 |
| LinkedList | 双向链表 | 否 | 低(O(n)) | 高(O(1),仅改指针) | 无需扩容(链表动态增长) | 频繁插入删除、少随机访问的场景 |
| Vector | 动态数组 | 是(synchronized) | 高(O(1)) | 低(O(n)) | 初始容量10,满后扩容2倍 | 旧代码兼容,新场景用ConcurrentHashMap+ArrayList替代 |
3.1.2 核心操作示例(ArrayList)
java
public class ListDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 1. 添加元素
list.add("Apple");
list.add("Banana");
list.add(1, "Orange"); // 指定下标插入
// 2. 访问元素(下标)
System.out.println(list.get(1)); // 输出:Orange
// 3. 修改元素
list.set(2, "Grape");
// 4. 删除元素
list.remove(0); // 下标删除
list.remove("Grape"); // 元素删除
// 5. 遍历(增强for)
for (String fruit : list) {
System.out.println(fruit); // 输出:Banana
}
}
}3.1.3 底层结构图解(ArrayList)
3.2 Set:无序唯一集合
Set接口的核心特性是**"无序(插入顺序不保证)、唯一(无重复元素)"**,适合需去重的场景(如用户ID集合、标签集合)。其"唯一性"通过equals()与hashCode()保证(同HashMap的Key)。
3.2.1 核心实现类对比
| 实现类 | 底层结构 | 线程安全 | 有序性(遍历顺序) | 查找效率 | 去重原理 | 适用场景 |
|---|---|---|---|---|---|---|
| HashSet | 哈希表(HashMap底层) | 否 | 无序(哈希顺序) | O(1) | 依赖Key的hashCode()与equals() | 普通去重,无需保证顺序 |
| LinkedHashSet | 哈希表+双向链表 | 否 | 有序(插入顺序) | O(1) | 继承HashSet,额外用链表维护顺序 | 去重且需保留插入顺序 |
| TreeSet | 红黑树(TreeMap底层) | 否 | 有序(键自然排序) | O(logn) | 依赖Comparable/Comparator排序去重 | 去重且需按键排序(如按数字大小) |
3.2.2 核心操作示例(HashSet)
java
public class SetDemo {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
// 1. 添加元素(重复元素自动去重)
set.add("Java");
set.add("Python");
set.add("Java"); // 重复,不生效
// 2. 判断元素是否存在
System.out.println(set.contains("Python")); // 输出:true
// 3. 删除元素
set.remove("Python");
// 4. 遍历(迭代器)
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next()); // 输出:Java
}
}
}3.3 Queue:先进先出队列
Queue接口遵循**"先进先出(FIFO)"** 原则,部分实现支持"优先级排序",适合任务排队、消息传递等场景。核心方法:offer()(入队)、poll()(出队,空时返回null)、peek()(查看队首,不删除)。
3.3.1 核心实现类
| 实现类 | 底层结构 | 线程安全 | 核心特性 | 适用场景 |
|---|---|---|---|---|
| LinkedList | 双向链表 | 否 | 普通FIFO队列,也实现List接口 | 简单队列场景(如任务临时排队) |
| PriorityQueue | 二叉堆(数组) | 否 | 优先级队列(默认自然升序) | 按优先级处理任务(如高优先级任务先执行) |
| ArrayBlockingQueue | 数组 | 是 | 有界阻塞队列(线程安全) | 多线程并发场景(如生产者-消费者) |
3.3.2 底层结构图解(PriorityQueue)
4. Map体系详解
Map接口是"键值对(Key-Value)"存储的顶层接口,核心特性:Key唯一(重复覆盖)、Value可重复、Key与Value一一对应,适合通过Key快速查找Value的场景(如用户信息缓存、配置存储)。
4.1 核心实现类对比(重点)
| 实现类 | 底层结构 | 线程安全 | 有序性(遍历顺序) | 查找效率 | Key允许null | 适用场景 |
|---|---|---|---|---|---|---|
| HashMap | 数组+链表/红黑树 | 否 | 无序(哈希顺序) | O(1) | 允许1个null | 普通键值对存储,高并发外首选 |
| LinkedHashMap | 数组+链表/红黑树+双向链表 | 否 | 有序(插入/访问顺序) | O(1) | 允许1个null | 需保留Key顺序(如最近访问缓存) |
| TreeMap | 红黑树 | 否 | 有序(Key自然排序) | O(logn) | 不允许null | 需按Key排序(如按时间戳排序日志) |
| Hashtable | 数组+链表 | 是(synchronized) | 无序 | O(1) | 不允许null | 旧代码兼容,新场景用ConcurrentHashMap替代 |
| ConcurrentHashMap | 数组+链表/红黑树(CAS+synchronized) | 是 | 无序 | O(1) | 不允许null | 高并发场景(如分布式系统缓存) |
4.2 核心操作示例(HashMap)
java
public class MapDemo {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
// 1. 添加键值对(重复Key覆盖)
map.put("Apple", 5);
map.put("Banana", 3);
map.put("Apple", 7); // 覆盖,值变为7
// 2. 通过Key查找Value
System.out.println(map.get("Banana")); // 输出:3
// 3. 遍历(键值对)
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 4. 删除键值对
map.remove("Banana");
// 5. 判断Key是否存在
System.out.println(map.containsKey("Apple")); // 输出:true
}
}4.3 底层结构图解(HashMap JDK 8+)
5. 核心技术点:遍历、线程安全与排序
5.1 集合遍历方式(3种常用)
| 遍历方式 | 适用场景 | 优点 | 缺点 | 代码示例(ArrayList) |
|---|---|---|---|---|
| 迭代器(Iterator) | 所有Collection集合 | 支持边遍历边删除(remove()) | 语法稍繁琐 | Iterator<String> it = list.iterator(); while(it.hasNext()) { it.next(); } |
| 增强for循环 | 仅遍历,不删除 | 语法简洁 | 无法边遍历边删除(会抛异常) | for (String s : list) { System.out.println(s); } |
| 普通for循环 | List集合(需下标访问) | 可控制遍历顺序,支持修改元素 | 仅适用于List,不适用于Set/Map | for (int i=0; i<list.size(); i++) { list.get(i); } |
Map遍历特殊:需通过
entrySet()(键值对)、keySet()(仅Key)、values()(仅Value)遍历,如map.entrySet()。
5.2 线程安全问题与解决方案
5.2.1 线程不安全的集合
ArrayList/HashMap/HashSet等默认实现类均为线程不安全,多线程并发修改(如同时add())会导致数据错乱 或**ConcurrentModificationException**。
5.2.2 解决方案(3种)
| 方案 | 实现方式 | 性能 | 适用场景 |
|---|---|---|---|
| 使用线程安全实现类 | ConcurrentHashMap、CopyOnWriteArrayList | 高 | 高并发读写场景 |
| Collections工具类包装 | Collections.synchronizedList(list)、Collections.synchronizedMap(map) | 低(全局锁) | 低并发场景,兼容性优先 |
| 手动加锁 | synchronized或Lock包裹集合操作 | 可控 | 需自定义锁粒度的场景 |
5.3 集合排序:Comparable vs Comparator
Java集合排序依赖"比较器",核心有两种实现方式:
| 比较方式 | 实现位置 | 灵活性 | 适用场景 | 示例(按字符串长度排序) |
|---|---|---|---|---|
| Comparable(自然排序) | 被排序对象的类内部 | 低(固定排序规则) | 长期固定的排序规则(如User按ID排序) | class User implements Comparable<User> { public int compareTo(User o) { return this.id - o.id; } } |
| Comparator(定制排序) | 排序时传入外部比较器 | 高(动态切换规则) | 临时或多规则排序(如String按长度排序) | Collections.sort(list, (s1, s2) -> s1.length() - s2.length()); |
6. 集合选型指南(实战表格)
| 业务需求 | 推荐集合类 | 排除集合类 |
|---|---|---|
| 有序可重复,频繁随机访问 | ArrayList | LinkedList(随机访问慢) |
| 有序可重复,频繁插入删除 | LinkedList | ArrayList(插入删除慢) |
| 无序唯一,无需保证顺序 | HashSet | TreeSet(排序开销) |
| 无序唯一,需保留插入顺序 | LinkedHashSet | HashSet(无序) |
| 键值对存储,高并发场景 | ConcurrentHashMap | HashMap(线程不安全)、Hashtable(性能低) |
| 键值对存储,需按Key排序 | TreeMap | HashMap(无序) |
| 队列操作,FIFO规则 | LinkedList | PriorityQueue(优先级无序) |
| 队列操作,按优先级处理 | PriorityQueue | LinkedList(无优先级) |
7. 总结
Java集合体系是Java开发的"数据容器基石",核心可总结为:
- 两大体系 :
Collection(单个对象)与Map(键值对),接口标准化,实现多样化; - 核心选择 :有序选
List,唯一选Set,键值对选Map,排队选Queue; - 性能关键:数组实现(如ArrayList)适合随机访问,链表实现(如LinkedList)适合插入删除,红黑树实现(如TreeMap)适合排序;
- 线程安全 :高并发用
ConcurrentHashMap/CopyOnWriteArrayList,低并发用Collections包装。
掌握集合的底层原理与选型规则,能显著提升代码效率与稳定性,是Java工程师的核心技能之一。
这篇博客覆盖了Java集合体系的核心架构、实现类细节、实战技术点与选型指南,图解与表格可帮助快速理解关键逻辑。若你需要补充某类集合(如CopyOnWriteArrayList)的深度原理,或增加特定场景的代码示例,可随时告知我进一步优化。