点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到: Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Flink 状态类型
- 案例1: Flink State 求平均值
- Flink State状态描述

广播状态
基本概念
所有并行任务实例(parallel task instances)会将这些状态数据(state data)作为一个持久化的内部状态来维护,而不是通过广播的方式发送给其他流处理器(stream processors)。这种设计使得每个实例都能独立处理状态数据,同时将这些状态与来自广播流(broadcast stream)的事件进行协同处理。
这种新型的广播状态(broadcast state)机制特别适用于以下两种典型场景:
- 需要将低吞吐量(low-throughput)数据流与高吞吐量(high-throughput)数据流进行关联处理的场景
- 需要动态调整处理逻辑(processing logic)的应用场景
为了更好地说明第二种应用场景,我们可以考虑一个具体的实现案例:假设我们正在构建一个实时欺诈检测系统。在这个系统中:
- 常规的交易数据流(transaction stream)作为高吞吐量主数据流
- 规则更新流(rule update stream)作为低吞吐量的广播流
- 处理引擎可以动态加载最新的欺诈检测规则,而无需停止或重启处理管道
在这种情况下,广播状态允许我们将更新后的检测规则实时分发到所有并行处理实例,这些实例可以立即应用新规则来处理后续的交易数据,从而实现业务逻辑的动态更新。
广播状态下的动态模式评估: 想象一下,一个电子商务网站将所有用户的交互捕获为用户操作流,运营该网站的公司有兴趣分析交互以增加收入,改善用户体验,以及监测和防止恶意行为。 该网站实现了一个流应用程序,用于检测用户事件流上的模式,但是,公司希望每次模式更改时都避免修改和重新部署应用程序。相反,应用程序从模式流接收新模式时摄取第二个模式流并更新其活动模式。 在上下文中,我们将逐步讨论此应用程序,并展示它如何利用ApacheFlink的广播状态功能。
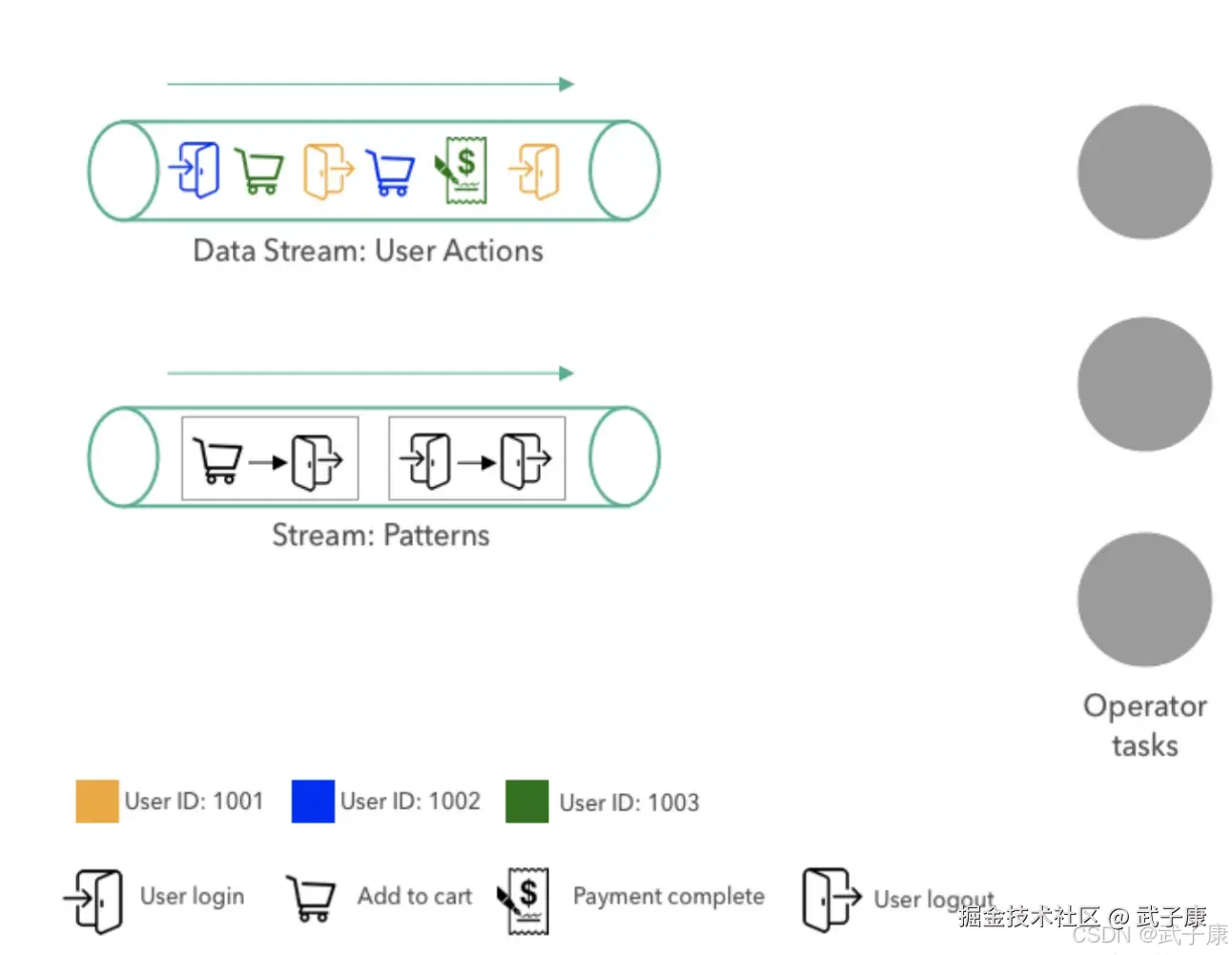 我们示例应用程序摄取两个数据流,第一个流在网站上提供用户操作,并在上图的左上方展示,用户交互事件包括操作的类型(用户登录、用户注销、添加购物车或者完成付款)和用户的ID,其由颜色编码。 图中所示的用户动作时间流包含用户1001的注销动作,其后是用户1003的支付完成事件,以及用户1002的添加购物车动作。 第二流提供应用将执行的动作模式,评估,模式由两个连续的动作组成。在上图上,模式流包含以下两个:
我们示例应用程序摄取两个数据流,第一个流在网站上提供用户操作,并在上图的左上方展示,用户交互事件包括操作的类型(用户登录、用户注销、添加购物车或者完成付款)和用户的ID,其由颜色编码。 图中所示的用户动作时间流包含用户1001的注销动作,其后是用户1003的支付完成事件,以及用户1002的添加购物车动作。 第二流提供应用将执行的动作模式,评估,模式由两个连续的动作组成。在上图上,模式流包含以下两个:
- 模式1:用户登录并立即注销而不无需浏览电子商务网站上的其他页面。
- 模式2:用户将商品添加到购物车并在不完成购买的情况下注销。
这些模式由助于企业更好的分析用户行为,检测恶意行为并改善网站体验。例如,如果项目被添加到购物车而没有后续购买,网站团队可以适当地采取措施来更好的了解用户未完成购买的原因,并启动特定的流程改善网站的转换(比如折扣、优惠卷等)。 在上图的右侧,该图显示了操作员的三个并行任务,即摄取模式和用户操作流,评估操作流上的模式,并在下游接收到新模式时,替换为当前活动模式。原则上,还可以实现运算符以同时评估更复杂的模式或多个模式,这些模式可以单独添加或者移除。
我们将描述模式匹配应用程序如何处理用户操作和模式流: 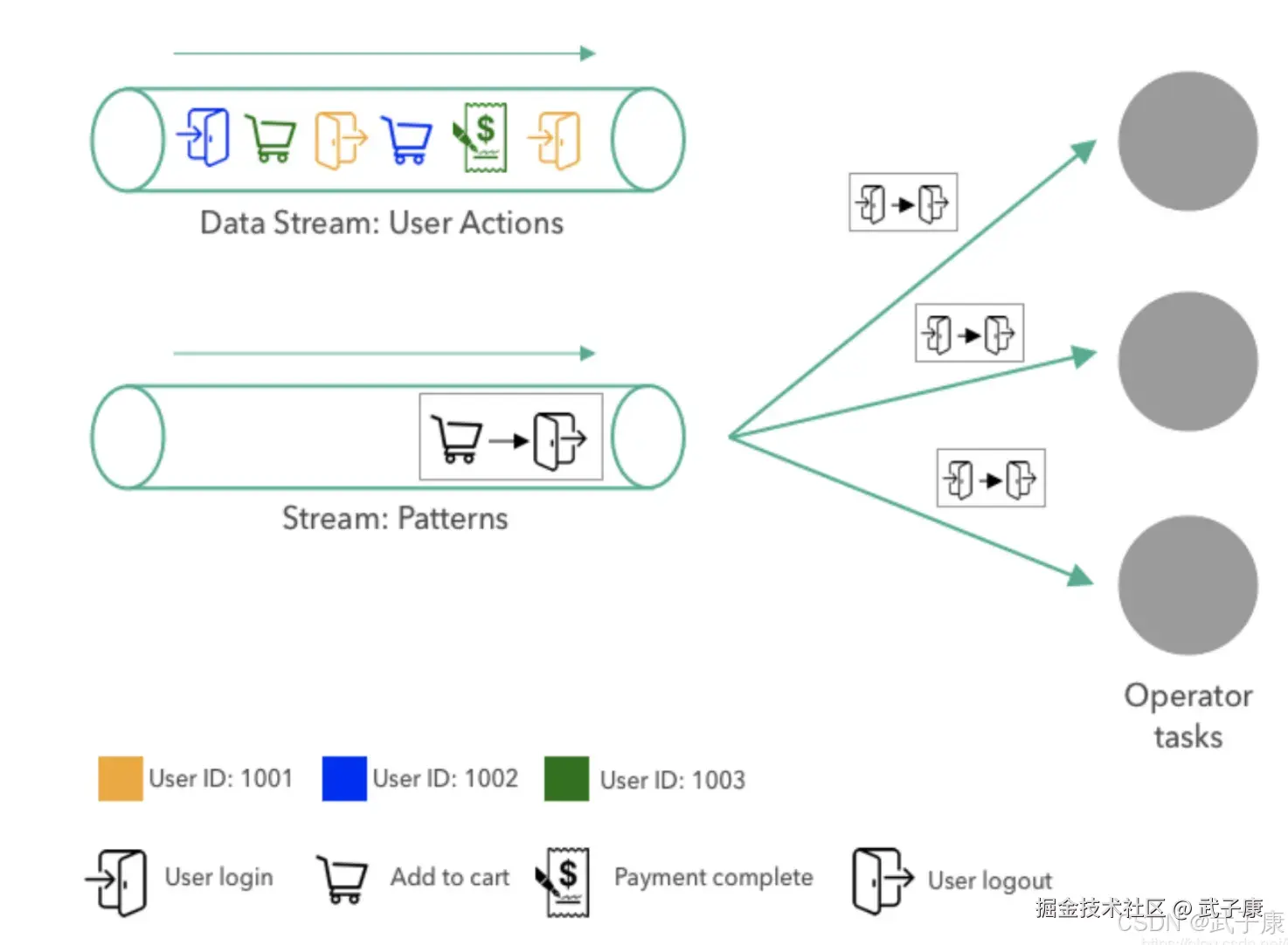 首先,将模式发送给操作员,该模式被广播到运营商的所有三个并行任务。任务将模式存储在其广播状态中,由于广播状态只应用使用广播数据进行更新,因此所有任务的状态始终预期相同。
首先,将模式发送给操作员,该模式被广播到运营商的所有三个并行任务。任务将模式存储在其广播状态中,由于广播状态只应用使用广播数据进行更新,因此所有任务的状态始终预期相同。
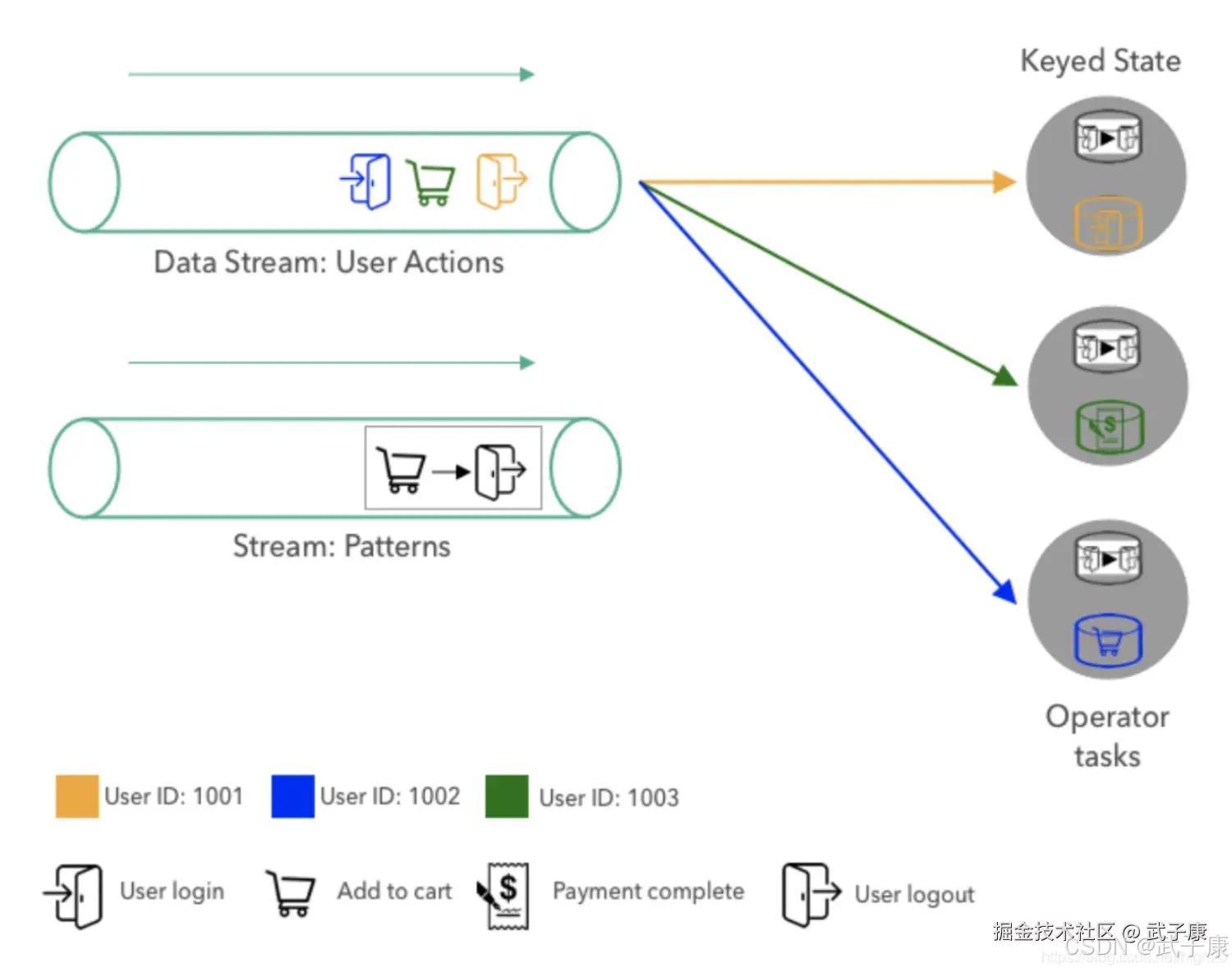 接下来,第一个用户操作按用户ID分区并发送到操作员任务,分区可确保同一用户的所有操作都由同一个任务处理,上图显示了操作员任务消耗第一个模式和前三个操作事件后应用程序的状态。 当任务收到新的用户操作时,它会通过查看用户的最新和先前操作来评估当前活动模式,对于每个用户,操作员先前的操作存储在键控状态。由于上图中的任务到目前为止仅为每个用户收到了一个操作(我们刚启动应用程序),因此不需要评估该模式。最后,用户键控状态中的先前操作被更新为最新动作,以便能够在同一用户的下一个动作到达时查找它。
接下来,第一个用户操作按用户ID分区并发送到操作员任务,分区可确保同一用户的所有操作都由同一个任务处理,上图显示了操作员任务消耗第一个模式和前三个操作事件后应用程序的状态。 当任务收到新的用户操作时,它会通过查看用户的最新和先前操作来评估当前活动模式,对于每个用户,操作员先前的操作存储在键控状态。由于上图中的任务到目前为止仅为每个用户收到了一个操作(我们刚启动应用程序),因此不需要评估该模式。最后,用户键控状态中的先前操作被更新为最新动作,以便能够在同一用户的下一个动作到达时查找它。
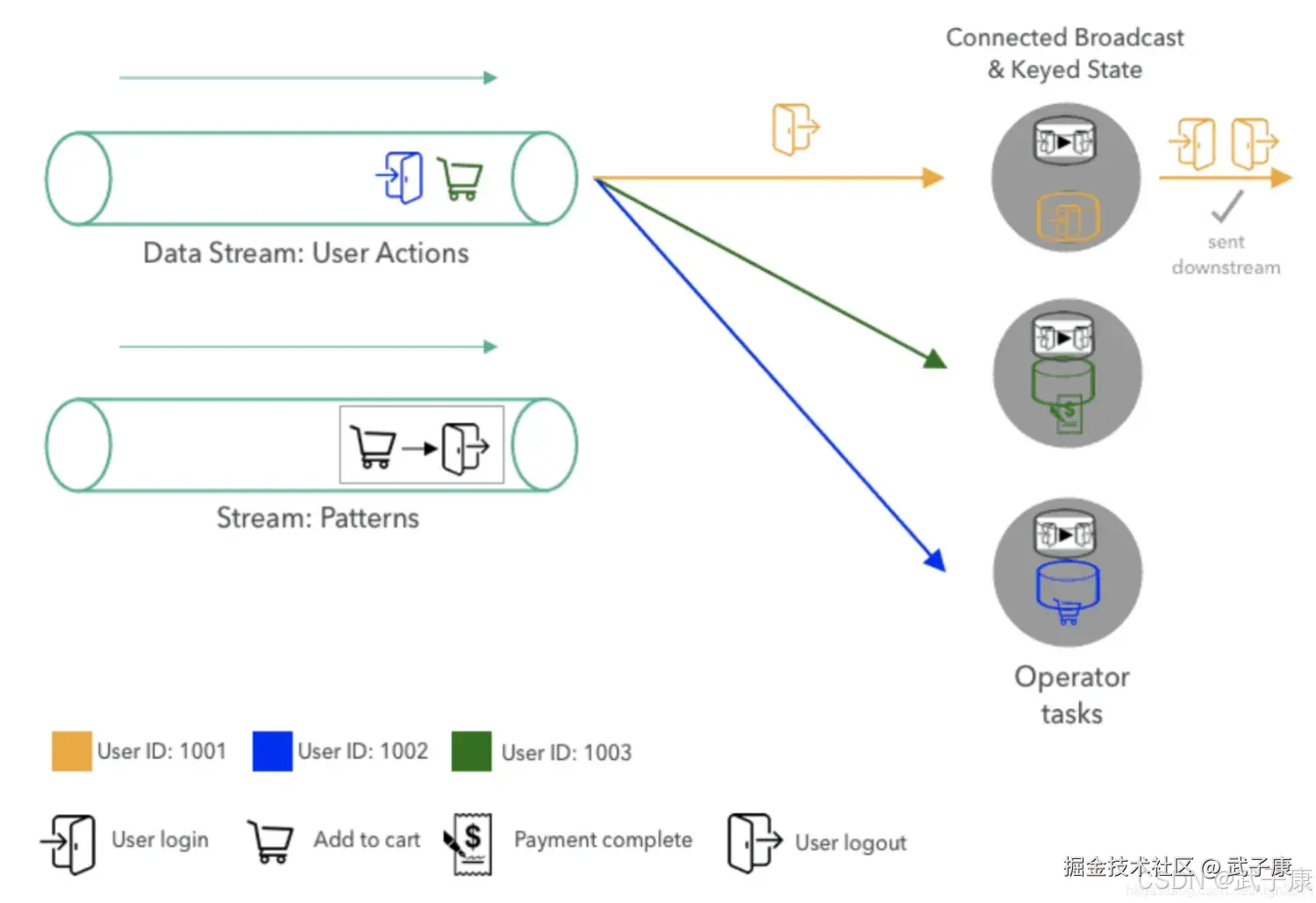 在处理前三个动作之后,下一个事件(用户1001的注销动作)被运送到处理用户1001的事件的任务,当任务接收到动作时,它从广播状态中查找到当前模式并且用户1001的先前操作。由于模式匹配的两个动作,因此任务发出模式匹配事件,最后,任务通过使用最新操作覆盖上一个事件来更新其键控状态。
在处理前三个动作之后,下一个事件(用户1001的注销动作)被运送到处理用户1001的事件的任务,当任务接收到动作时,它从广播状态中查找到当前模式并且用户1001的先前操作。由于模式匹配的两个动作,因此任务发出模式匹配事件,最后,任务通过使用最新操作覆盖上一个事件来更新其键控状态。
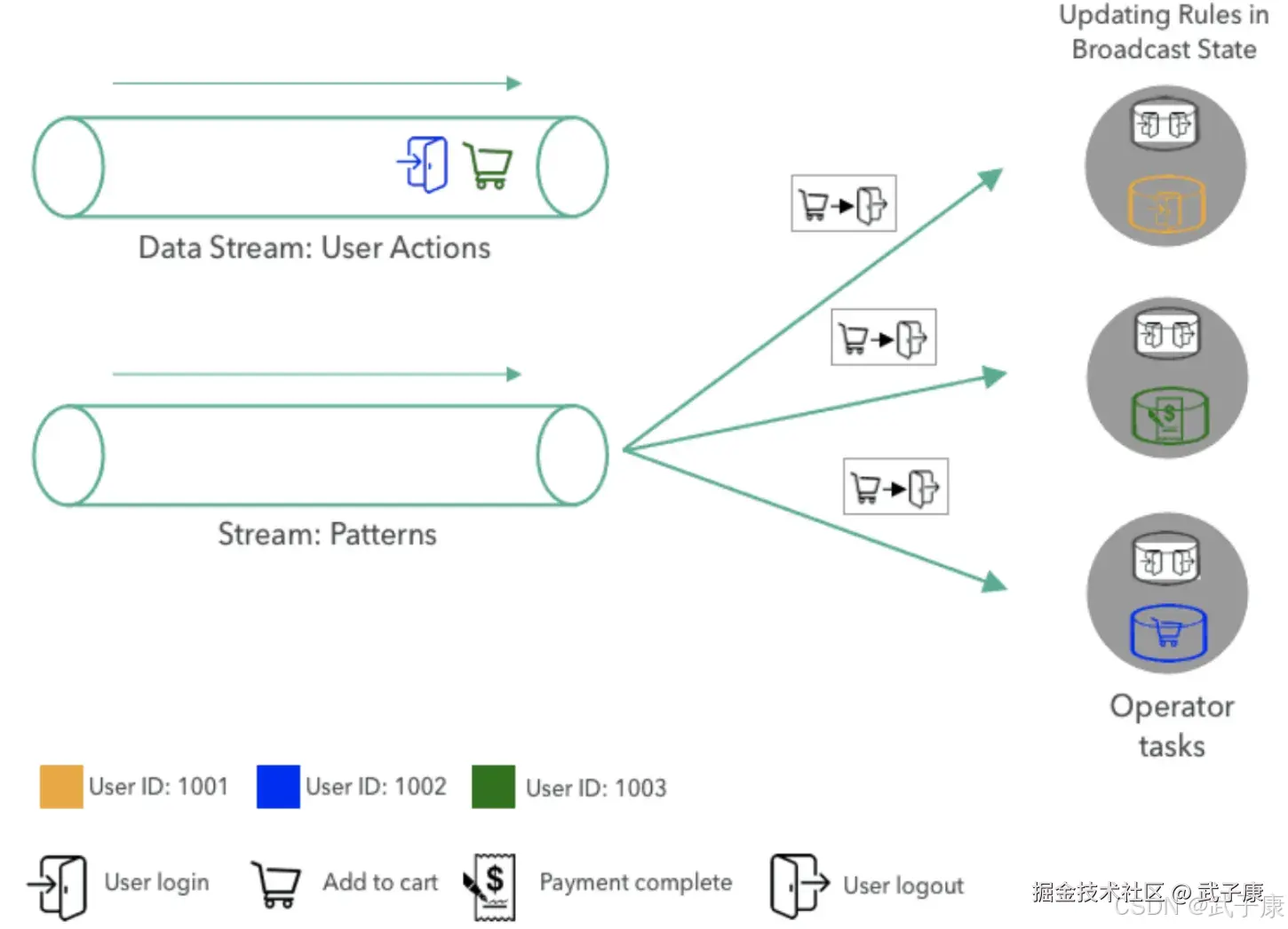 当新模式到达模式流时,它被广播到所有任务,并且每个任务通过新模式替换当前模式来更新广播状态。
当新模式到达模式流时,它被广播到所有任务,并且每个任务通过新模式替换当前模式来更新广播状态。 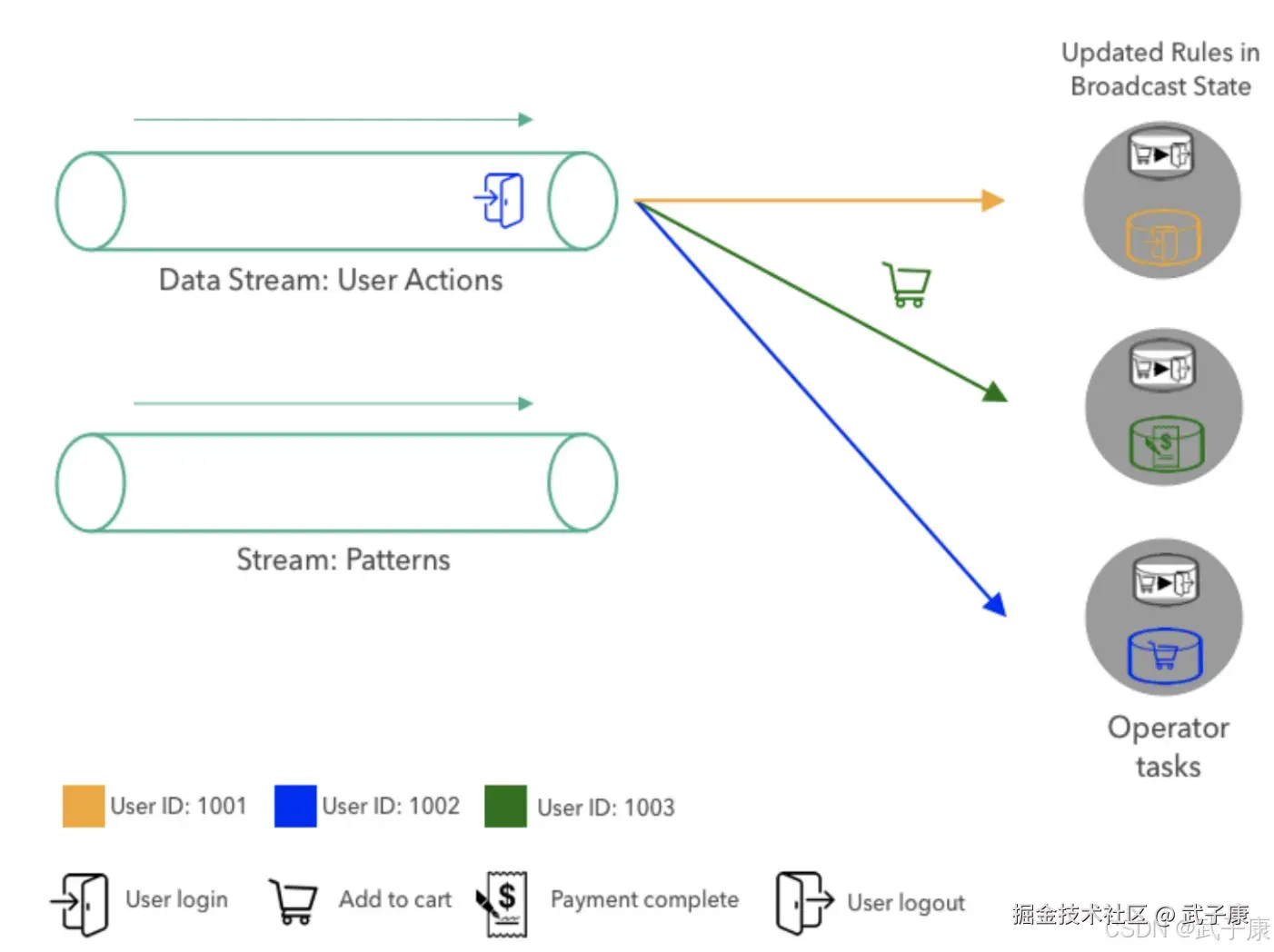 一旦用新模式更新广播状态,匹配逻辑就像之前一样继续,用户动作时间由密钥分区并负责任务评估。
一旦用新模式更新广播状态,匹配逻辑就像之前一样继续,用户动作时间由密钥分区并负责任务评估。
如何使用
那么如何使用广播状态实现应用程序? 到目前为止,概念上讨论了该应用程序并解释了它如何使用广播状态来评估事件流上的动态模式,接下来,我们将展示如何使用 Flink的DataStream API和广播状态功能实现示例应用程序。
让我们从应用程序的输入数据开始,我们有两个数据流,操作和模式,在这一点上,我们并不关心流来来何处。 这些流可以从ApacheKafka或者Kinesis或任何其他系统中摄取。并与两个字段的POJO:
java
DataStream<Action> actions = ???`
`DataStream<Pattern> patterns = ???
Action``Pattern- Action:Long userId,String action
- Pattern:String firstAction String secondAction
作为第一步,我们在属性上键入操作流。接下来,我们准备广播状态,广播状态始终为Flink提供的最通用的状态原语。由于我们的应用程序一次只评估和存储一个,我们将广播状态配置为具体有键类型和值类型。使用广播状态,我们在流上应用转换并接收,在我们获得了KeyedStream和广播流之后,我们都流式传输并应用了一个userId。
编写代码
java
package icu.wzk;
public class BroadCastDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// 两套数据流 1:用户行为 2:模式
UserAction user1 = new UserAction(1001L, "login");
UserAction user2 = new UserAction(1003L, "pay");
UserAction user3 = new UserAction(1002L, "car");
UserAction user4 = new UserAction(1001L, "logout");
UserAction user5 = new UserAction(1003L, "car");
UserAction user6 = new UserAction(1002L, "logout");
DataStreamSource<UserAction> actions = env.fromElements(user1, user2, user3, user4, user5, user6);
MyPattern myPattern1 = new MyPattern("login", "logout");
MyPattern myPattern2 = new MyPattern("car", "logout");
DataStreamSource<MyPattern> patterns = env.fromElements(myPattern1, myPattern2);
KeyedStream<UserAction, Long> keyed = actions
.keyBy(new KeySelector<UserAction, Long>() {
@Override
public Long getKey(UserAction value) throws Exception {
return value.getUserId();
}
});
// 将模式流广播到下游的所有算子
MapStateDescriptor<Void, MyPattern> broadcastStateDescriptor = new MapStateDescriptor<>(
"patterns", Types.VOID, Types.POJO(MyPattern.class));
BroadcastStream<MyPattern> broadcastPatterns = patterns.broadcast(broadcastStateDescriptor);
SingleOutputStreamOperator<Tuple2<Long, MyPattern>> process = keyed
.connect(broadcastPatterns)
.process(new PatternEvaluator());
// 匹配结果输出到控制台
process.print();
env.execute("BroadCastDemo");
}
// 用户行为类
public static class UserAction {
private Long userId;
private String userAction;
public UserAction(Long userId, String userAction) {
this.userId = userId;
this.userAction = userAction;
}
public Long getUserId() {
return userId;
}
public String getUserAction() {
return userAction;
}
}
// 模式类
public static class MyPattern {
private String firstAction;
private String secondAction;
// 无参构造函数
public MyPattern() {
}
public MyPattern(String firstAction, String secondAction) {
this.firstAction = firstAction;
this.secondAction = secondAction;
}
public String getFirstAction() {
return firstAction;
}
public void setFirstAction(String firstAction) {
this.firstAction = firstAction;
}
public String getSecondAction() {
return secondAction;
}
public void setSecondAction(String secondAction) {
this.secondAction = secondAction;
}
}
public static class PatternEvaluator extends KeyedBroadcastProcessFunction<Long, UserAction, MyPattern, Tuple2<Long, MyPattern>> {
private transient ValueState<String> prevActionState;
@Override
public void open(Configuration parameters) throws Exception {
prevActionState = getRuntimeContext()
.getState(new ValueStateDescriptor<>("lastAction", Types.STRING));
}
/**
* 每个一个Action数据,触发一次执行
* @author wzk
* @date 11:21 2024/7/29
**/
@Override
public void processElement(UserAction value, KeyedBroadcastProcessFunction<Long, UserAction, MyPattern, Tuple2<Long, MyPattern>>.ReadOnlyContext ctx, Collector<Tuple2<Long, MyPattern>> out) throws Exception {
// 把用户行为流和模式流中的模式进行匹配
ReadOnlyBroadcastState<Void, MyPattern> patterns = ctx
.getBroadcastState(new MapStateDescriptor<>("patterns", Types.VOID, Types.POJO(MyPattern.class)));
MyPattern myPattern = patterns.get(null);
String prevAction = prevActionState.value();
if (myPattern != null && prevAction != null) {
if (myPattern.getFirstAction().equals(prevAction) && myPattern.getSecondAction().equals(value.getUserAction())) {
// 匹配成功
System.out.println("匹配成功: " + ctx.getCurrentKey());
out.collect(new Tuple2<>(ctx.getCurrentKey(), myPattern));
} else {
// 匹配失败
System.out.println("匹配失败: " + ctx.getCurrentKey());
}
}
prevActionState.update(value.getUserAction());
}
/**
* 每次来一个模式 Pattern 的时候触发
* @author wzk
* @date 11:29 2024/7/29
**/
@Override
public void processBroadcastElement(MyPattern value, KeyedBroadcastProcessFunction<Long, UserAction, MyPattern, Tuple2<Long, MyPattern>>.Context ctx, Collector<Tuple2<Long, MyPattern>> out) throws Exception {
BroadcastState<Void, MyPattern> broadcastState = ctx
.getBroadcastState(new MapStateDescriptor<>("patterns", Types.VOID, Types.POJO(MyPattern.class)));
broadcastState.put(null, value);
}
}
}-
processBroadcastElement():为广播流的每个记录调用,该函数负责处理广播流中的更新数据(例如最新的模式规则)。在我们的实现中,我们使用键值对的方式将接收到的记录存储到广播状态中(注意:广播状态在所有并行实例中是共享的,但在这个特定场景中我们只存储单一的模式规则)。具体操作包括:
- 从广播流中提取模式规则
- 将模式规则以键值形式存入
BroadcastState - 确保每次更新都会覆盖之前的模式(因为我们只需要维护最新的模式)
该方法的实现类为PatternEvaluator,涉及的状态类型包括MapState用于存储模式规则,其中键为固定标识符(如"current_pattern"),值为具体的模式定义。
-
processElement():为键控流的每个记录调用,这是核心的处理逻辑所在。该函数具有以下特点:
- 只能读取广播状态(系统自动保证广播状态的只读访问,防止并行实例间状态不一致)
- 具体处理流程:
- 从广播状态获取当前生效的模式规则(通过预定义的键查询)
- 从键控状态(KeyedState)中获取该用户的历史行为记录
- 当两者都存在时,执行模式匹配检测:
- 对比用户历史行为与当前行为是否符合模式定义的序列
- 若匹配成功,向下游发送
PatternMatch事件
- 最终将用户当前行为更新到键控状态中,作为下次匹配的依据
- 该方法的实现类同样是
PatternEvaluator,典型应用场景包括:用户行为序列分析(如"浏览-加购-下单"的三步模式检测)。
-
onTimer():在预注册的定时器触发时调用。关键特性包括:
- 定时器可以在
processElement()或processBroadcastElement()中通过TimerService注册 - 主要用途:
- 延迟计算(如窗口关闭后的聚合操作)
- 状态清理(本示例未实现但重要的功能)
- 在用户行为分析场景中,典型的定时器应用是:
- 当用户每次操作时注册一个存活定时器(如30分钟有效期)
- 若定时器触发时用户无新操作,则自动清除该用户的键控状态
- 避免长期不活跃用户占用内存资源
- 注意:虽然示例中未实现此方法,但生产环境强烈建议添加状态清理逻辑。
- 定时器可以在
运行测试
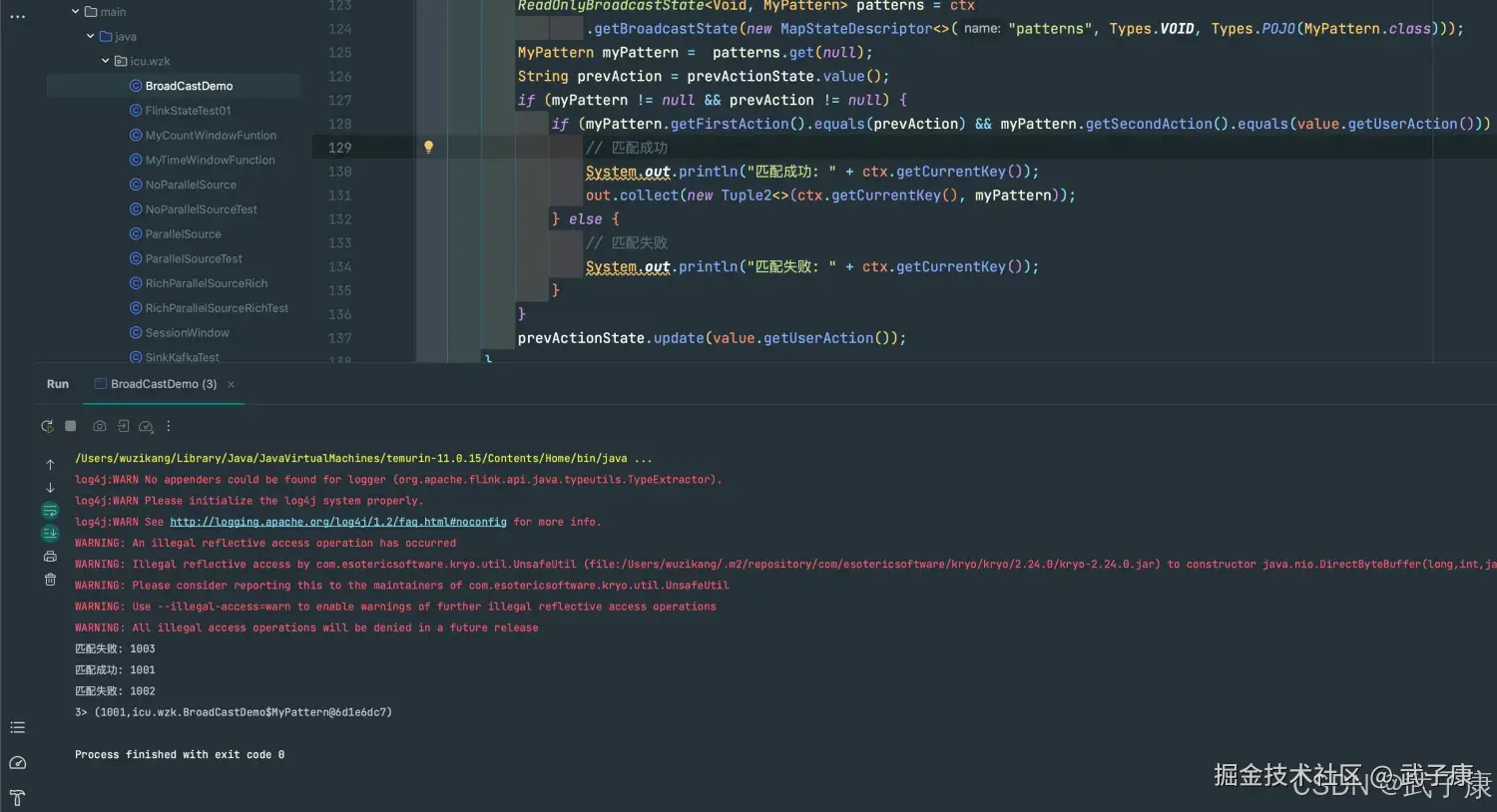
数据结果为:
shell
匹配失败: 1003
匹配成功: 1001
匹配失败: 1002
3> (1001,icu.wzk.BroadCastDemo$MyPattern@6d1e6dc7)控制台输出的结果为: