
2025
1.摘要
background
视频大语言模型(VLLMs)因其强大的视频理解能力而备受关注,但其高昂的推理成本是一个巨大障碍。视频输入会产生数以万计的视觉token,而Transformer模型的注意力机制具有平方复杂度,这导致了严重的推理延迟和显存占用。现有的token压缩方法通常采用"一次性"静态剪枝策略,即在推理开始前(预填充阶段)就根据某种标准(如注意力分数)丢弃一部分token。然而,本文作者通过实验观察发现一个关键问题:与处理静态图像不同,在解码(生成答案)的不同阶段,模型对视频不同帧、不同区域的注意力是动态变化的。静态剪枝很可能会在早期就错误地丢弃掉在后续推理中至关重要的token。
innovation
本文的核心洞察是,token的重要性在视频推理过程中是动态变化的,因此剪枝策略也必须是动态的 。基于此,论文提出了一个名为DyCoke (Dynamic Compression of Tokens) 的、无需训练的即插即用token压缩框架。
1. 两阶段压缩策略: DyCoke将压缩分为两个阶段,分别处理视频的时间冗余 和空间冗余。
阶段一:视觉token时间合并 (Visual Token Temporal Merging, TTM): 在预填充阶段,通过合并跨帧的相似token来减少时间冗余。这是一种粗粒度的、静态的预处理。
阶段二:KV缓存动态剪枝 (KV Cache Dynamic Pruning): 这是本文最核心的创新。在解码阶段的每一步,模型都会重新评估当前所有视觉token的重要性(基于注意力分数),然后只保留最重要的top-p%的token在KV缓存中用于下一步的计算。
2. 动态剪枝缓存 (Dynamic Pruning Cache): 为了避免永久丢弃token,被剪枝的token并不会被彻底删除,而是被存放在一个"剪枝缓存"中。在后续的解码步骤中,如果某个被剪枝的token的注意力分数重新升高,它会被动态地"召回"到活跃的KV缓存中。
好处与对比: 相比于基线模型(不压缩),DyCoke在提升性能的同时,实现了1.5倍的推理加速和1.4倍的显存节省。相比于其他SOTA的静态剪枝方法(如LLaVA-PruMerge, FastV),DyCoke的性能更强、效率更高,因为它通过动态剪枝机制,更智能、更安全地移除了冗余token,避免了"误删"关键信息。最重要的是,DyCoke是完全无需训练的。
- 方法 Method
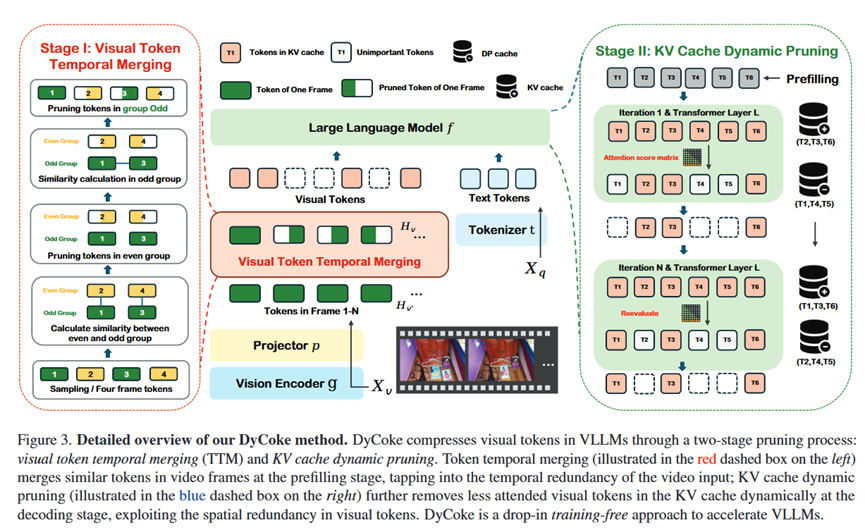
总体 Pipeline:
DyCoke是一个两阶段、无需训练的token压缩框架,它在VLLM的推理过程中即插即用地执行。
输入: 一个视频(多帧)和文本指令。
输出: 文本回答。
各部分详解:
1.阶段一:视觉Token时间合并 (TTM) - 预填充阶段:
目标: 减少时间冗余。
过程:
采用一个滑动窗口(如4帧)遍历所有视频帧的视觉token。
在窗口内,将帧分为奇数帧组和偶数帧组。
首先,合并偶数帧组中与奇数帧组对应位置相似度高的token。
然后,在剩下的奇数帧组内部,进一步合并相似的token。
通过这种方式,在进入LLM之前,就预先合并了大量跨帧的冗余token。
输出: 数量减少了k%的视觉token H_v'。
2.阶段二:KV缓存动态剪枝 - 解码阶段:
目标: 减少空间冗余,并动态调整保留的token。
过程: 在生成每一个回答token的解码步骤 t 中:
计算重要性: 计算当前预测token对所有视觉token的注意力分数。
选择关键Token: 找出注意力分数最高的 top-p% 的视觉token,将其索引记为 I_p。
更新活跃KV缓存: 仅保留 I_p 对应的token在活跃的KV缓存中,用于下一步的注意力计算。
更新剪枝缓存 (DP Cache): 将不在 I_p 中的token移入或保留在剪枝缓存中。
动态召回: 在下一个解码步骤 t+1 开始前,模型会评估剪枝缓存中的token,如果它们的注意力分数重新变得重要,就会被移回到活跃KV缓存中。
输出: 循环此过程,直到生成完整的回答。
- 实验 Experimental Results
实验数据集:
评测: 在多个公认的视频问答和视频描述基准上进行评估,包括 ActivityNet-QA, NeXT-QA, PerceptionTest, VideoMME, VideoDetailCaption (VideoDC), MVBench。
每个实验的结论:
1.性能与效率对比 (Table 1): 在所有基准和不同大小的模型(0.5B, 7B, 72B)上,DyCoke在达到与基线模型相当甚至更高性能的同时,显著降低了计算量(FLOPs)。例如,在7B模型上,仅用43%的计算量就超越了基线性能。
2.优于静态剪枝方法 (Table 1, 2): DyCoke的性能全面优于FastV和PruMerge。特别是在MVBench这种需要细粒度理解的多选QA任务上,静态剪枝方法性能下降明显,而DyCoke能保持甚至提升性能,证明了动态剪枝的优越性。
3.推理速度和显存 (Figure 1, Table 3): 实际测试表明,DyCoke带来了显著的推理加速(最高1.54倍)和显存节省,且视频越长,优势越明显。
4.消融研究 (Table 5):
证明了动态剪枝(DP)是核心:如果去掉DP,只做一次性剪枝,性能会大幅下降。
证明了TTM的有效性:如果第一阶段使用随机剪枝代替基于相似度的合并,性能也会下降。
5.定性分析 (Figure 4): 案例分析显示,静态剪枝方法FastV会导致模型出错(如将蓝色物体识别为灰色),而DyCoke能保持正确答案。更有趣的是,在某些情况下,DyCoke甚至能"纠正"原始未压缩模型的错误,可能是因为剪枝帮助模型排除了干扰信息,更专注于关键内容。
- 总结 Conclusion
本文的核心信息是,视频理解过程中的注意力焦点是动态变化的,因此高效的VLLM推理需要动态的token管理策略。通过一个无需训练、即插即用的两阶段动态压缩框架DyCoke,可以在大幅提升推理速度、降低显存占用的同时,保持甚至超越原始模型的性能,为实现快速、高效的视频大语言模型提供了切实可行的vv