文章结尾部分有CSDN官方提供的学长 联系方式名片
B站up账号: 麦麦大数据
关注B站,有好处!
编号: F024 CNN
视频
CNN 深度学习Vue电影推荐可视化系统 python flask mysql 超高端 echarts
1 系统简介
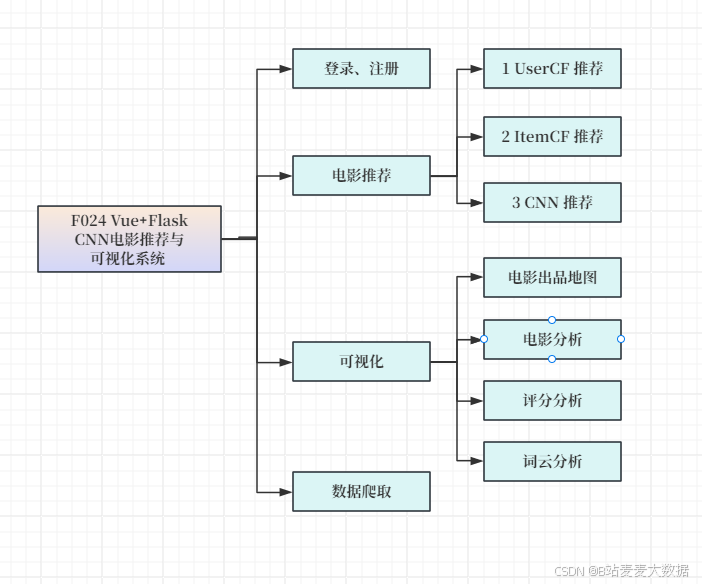
系统简介:本系统是一个基于Vue+Flask构建的电影智能推荐系统,集推荐算法(包括基于用户协同过滤UserCF、基于物品协同过滤ItemCF以及基于卷积神经网络CNN的推荐模型)和多维度数据分析于一体。系统的核心功能包括:首页展示(系统导航与推荐入口)、电影信息浏览、推荐算法模块(支持多种推荐模型的切换与对比)、电影数据可视化分析(如导演-演员网络、类型热度趋势图、评分分布直方图等),以及用户管理功能。系统通过直观的可视化图表(使用Echarts构建)帮助用户了解电影趋势与热门题材动态。同时,系统结合多种推荐模型,为用户个性化推荐感兴趣的影片,提升浏览与观影体验。用户可在系统中注册、登录,管理个人资料,查看推荐列表,并对电影进行评分和反馈,提升算法精度与系统互动性。
2 功能设计
系统采用B/S(浏览器/服务器)架构模式,用户通过浏览器访问由Vue.js构建的前端界面。前端的核心技术栈包括:Vue.js、Vuex(状态管理)、Vue Router(路由管理)以及ECharts(数据可视化)。前端通过RESTful API与Flask后端交互,完成用户请求的处理与数据返回。Flask后端负责核心业务逻辑的处理,包括推荐算法的运行、用户行为分析、后端接口服务的提供等。后端使用SQLAlchemy连接MySQL数据库,实现用户信息、电影元数据、评分数据和推荐结果的持久化存储与查询。推荐模块中,基于CNN的推荐模型通过卷积神经网络分析电影的视觉特征(如海报、预告片等),生成电影嵌入向量,并结合用户历史行为数据进行个性化推荐。系统还支持传统的协同过滤算法,用户和物品的协同推荐结果可与CNN推荐结果进行对比分析,以提升推荐的多样性和准确性。
2.1系统架构图
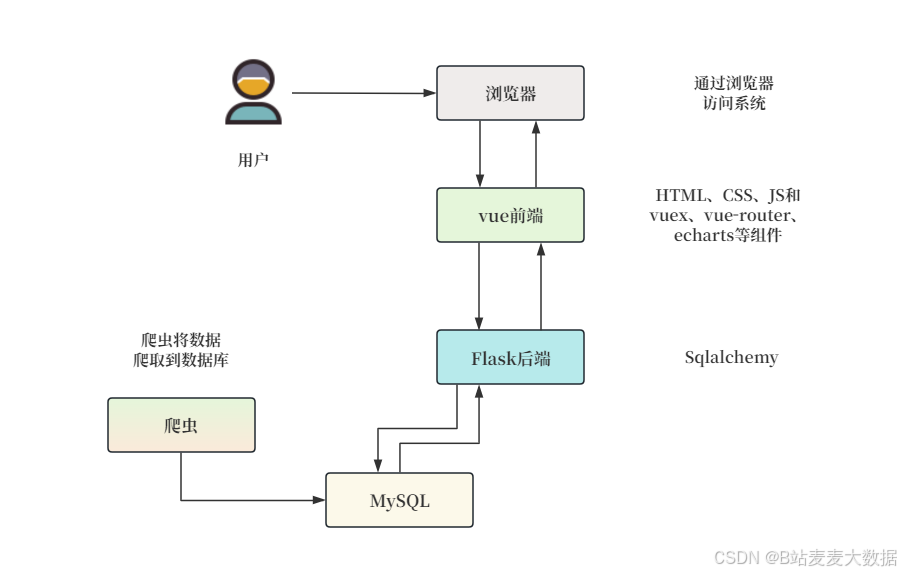
1. 用户前端
用户通过浏览器访问系统,前端采用了基于 Vue.js 的技术栈来构建。
- 浏览器:作为用户与系统交互的媒介,用户通过浏览器进行各种操作,如浏览图书、获取推荐等。
- Vue 前端:使用 Vue.js 框架搭建前端界面,包含 HTML、CSS、JavaScript,以及 Vuex(用于状态管理),vue-router(用于路由管理),和 Echarts(用于数据可视化)等组件。前端向后端发送请求并接收响应,展示处理后的数据。
2. 后端服务
后端服务采用 Flask 框架,负责处理前端请求,执行业务逻辑,并与数据库进行交互。
- Flask 后端:使用 Python 编写,借助 Flask 框架处理 HTTP 请求。通过 SQLAlchemy 与 MySQL 进行交互,通过 py2neo 与 Neo4j 进行交互。后端主要负责业务逻辑处理、 数据查询、数据分析以及推荐算法的实现。
3. 数据库
系统使用了两种数据库:关系型数据库 MySQL 和图数据库 Neo4j。
- MySQL:存储从网络爬取的基本数据。数据爬取程序从外部数据源获取数据,并将其存储在 MySQL 中。MySQL 主要用于存储和管理结构化数据。
- Neo4j:存储图谱数据,特别是用户、图书及其关系(如阅读、写、出版等)。通过利用 py2neo 库将 MySQL 中的数据结构化为图节点和关系,再通过图谱生成程序(可能是一个 Python 脚本)将其导入到 Neo4j 中。
4. 数据爬取与处理
数据通过爬虫从外部数据源获取,并存储在 MySQL 数据库中,然后将数据转换为图结构并存储在 Neo4j 中。
- 爬虫:实现数据采集,从网络数据源抓取相关信息。爬取的数据首先存储在 MySQL 数据库中。
- 图谱生成程序:利用 py2neo 将爬取到的结构化数据(如电影、演员和导演,以及它们之间的关系)从 MySQL 导入到 Neo4j 中。通过构建图谱数据,使得后端能够进行复杂的图查询和推荐计算。
3 功能展示
3.1 功能模块图
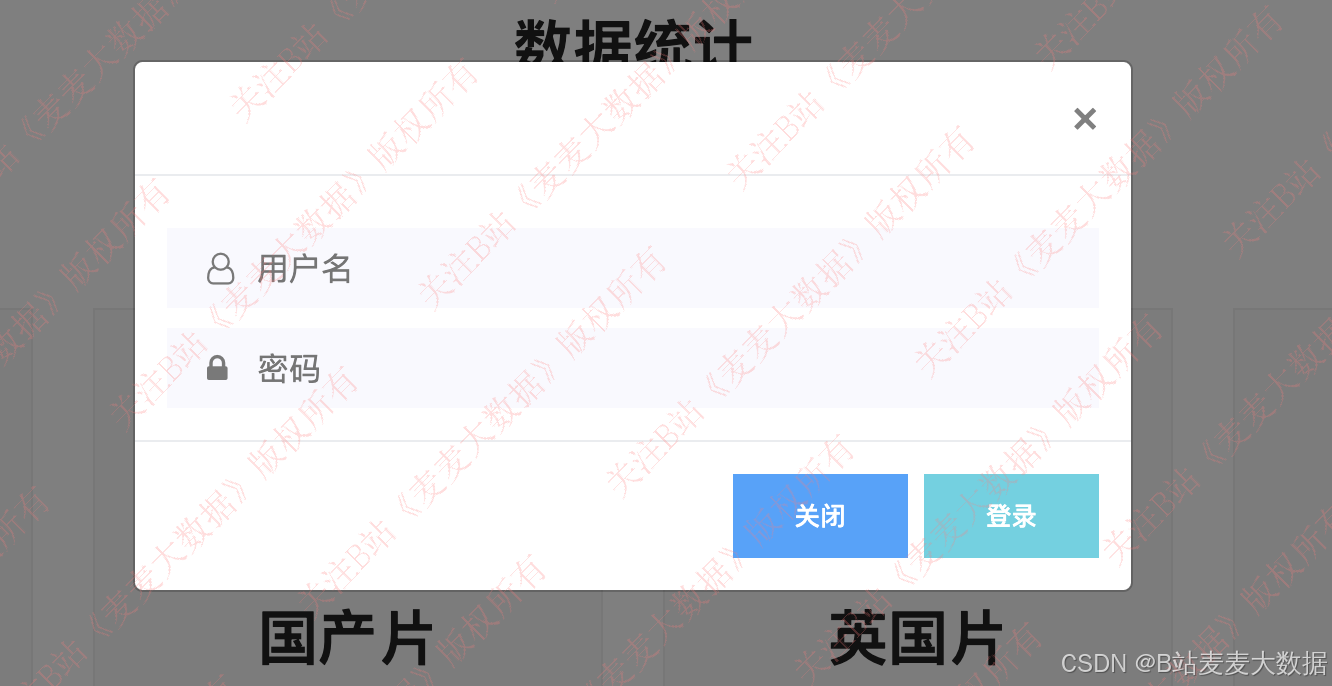
3.2 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。
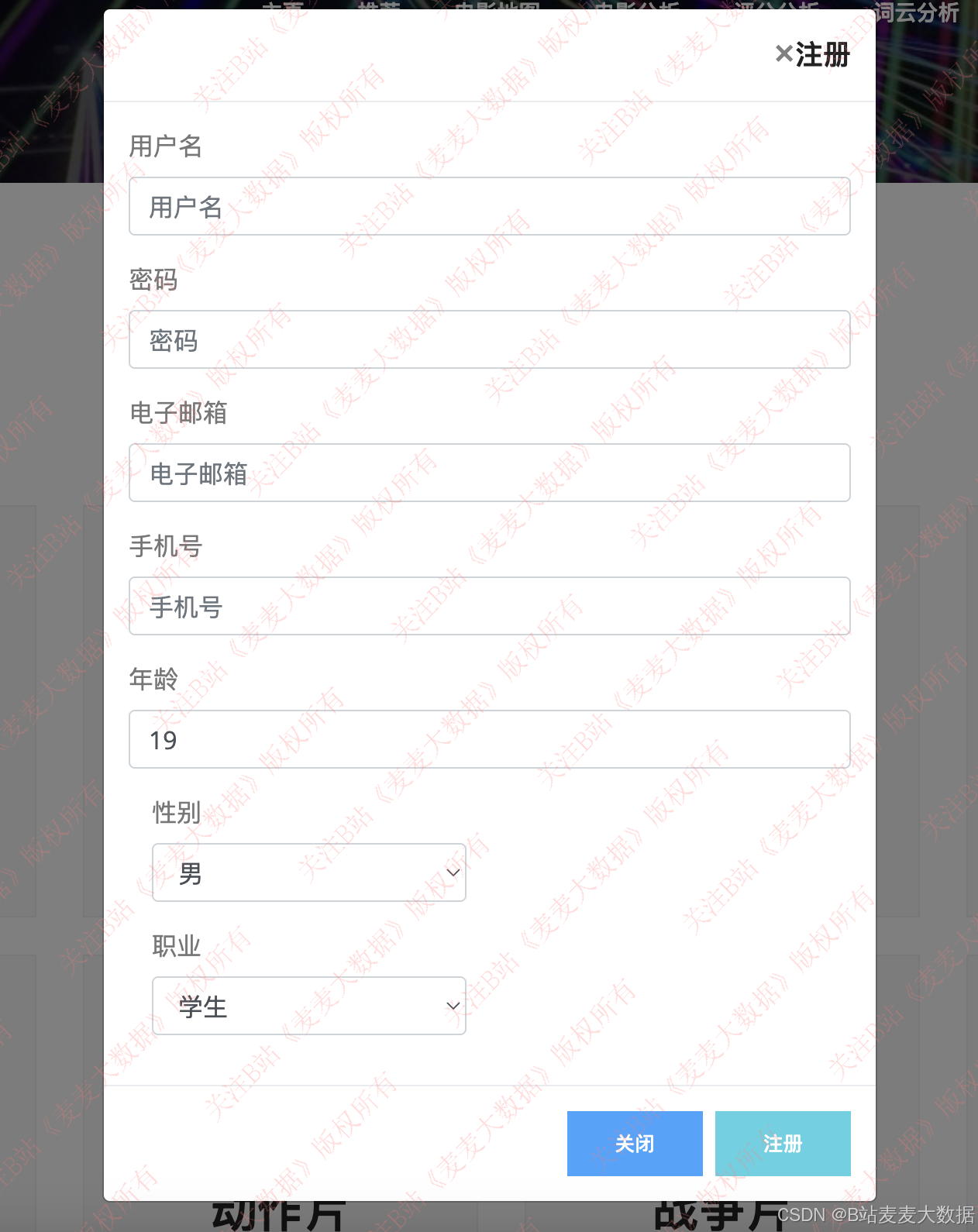
注册需要验证用户名是否存在 ,如果错误会有提示。
3.3 主页
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
数据统计包含了系统内各种类型的电影还有各个国家电影的统计情况:

3.4 推荐算法
算法一 UserCF :

算法二 ItemCF :

CNN 推荐
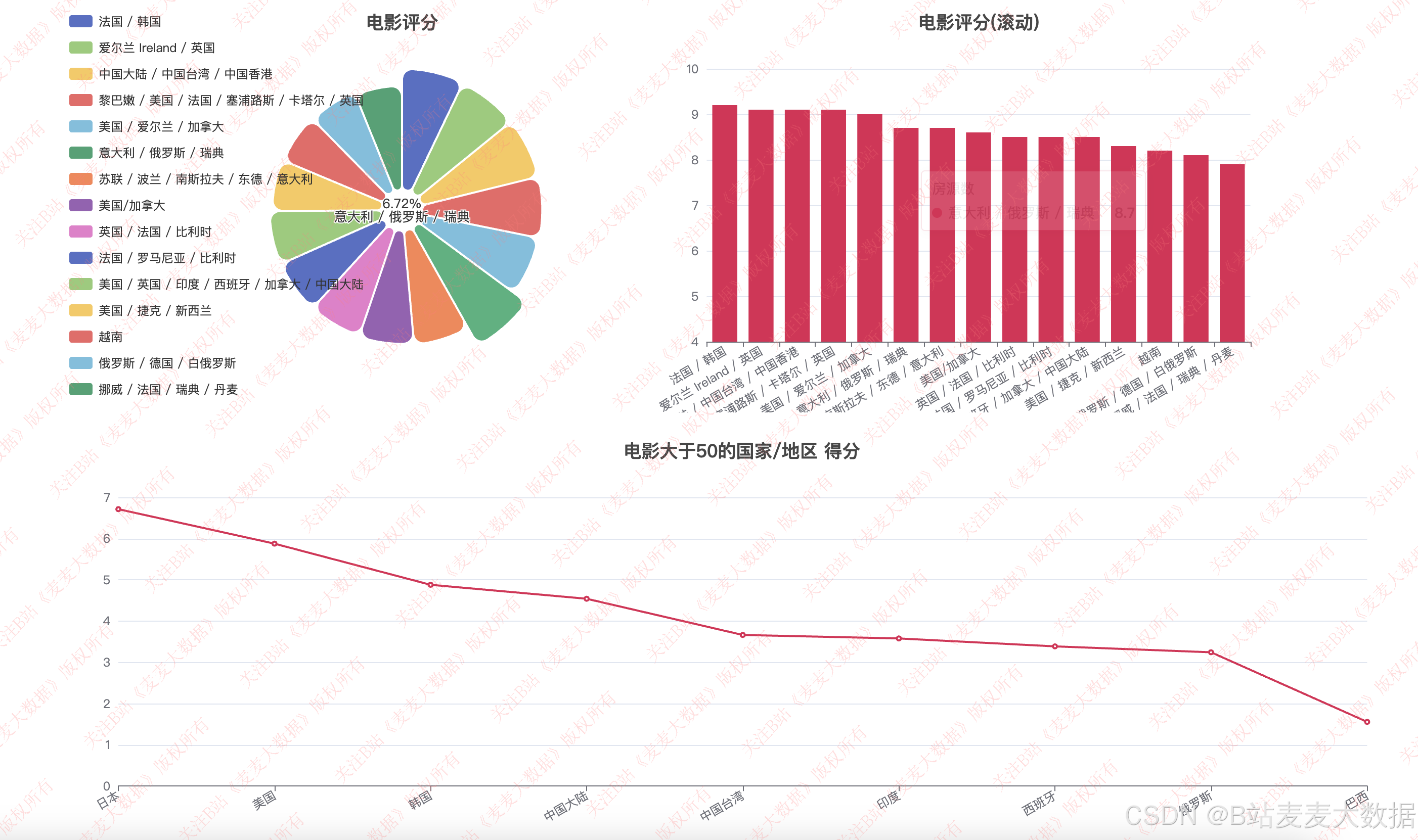
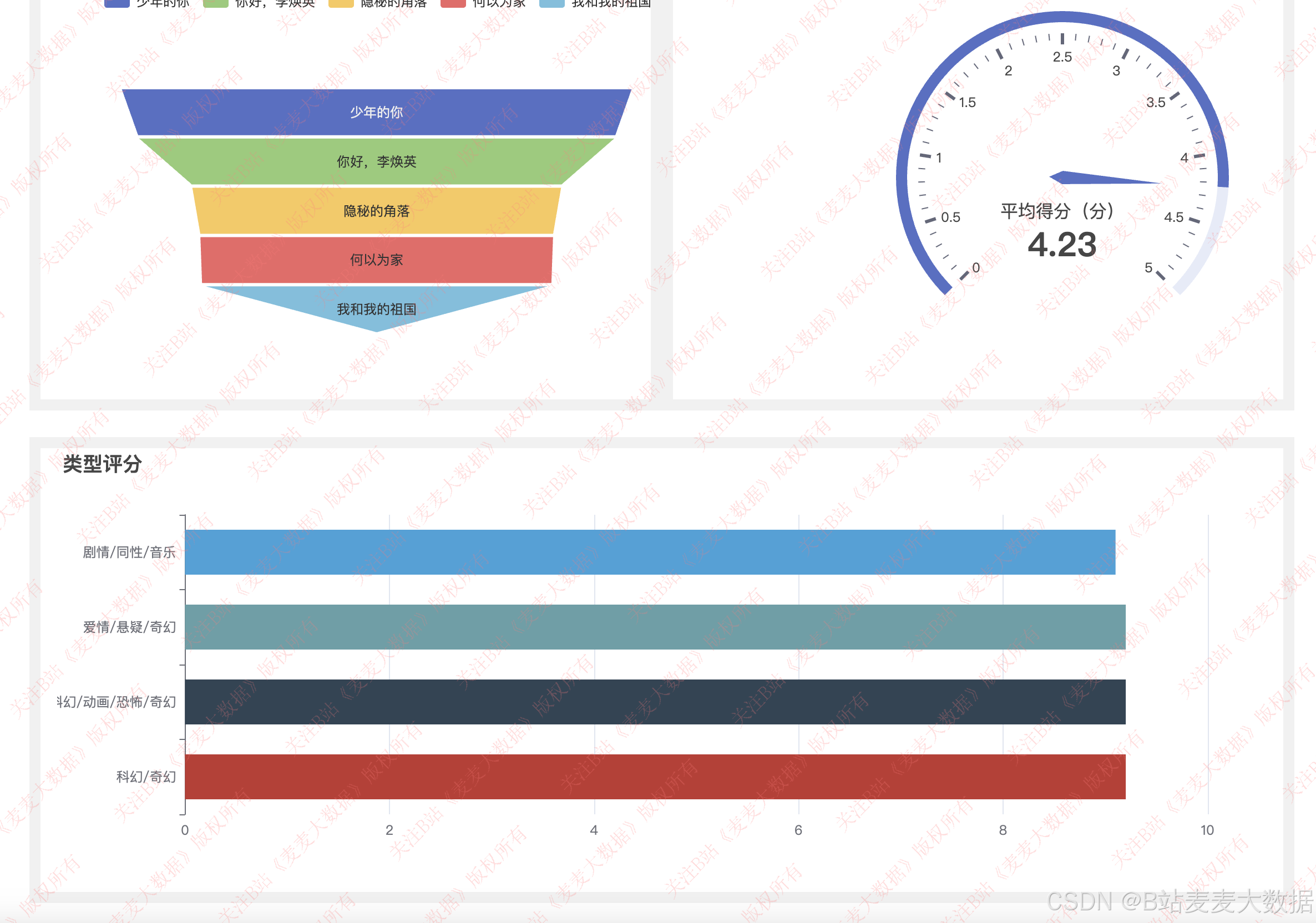
3.5 数据分析
电影分析:
评分分析:
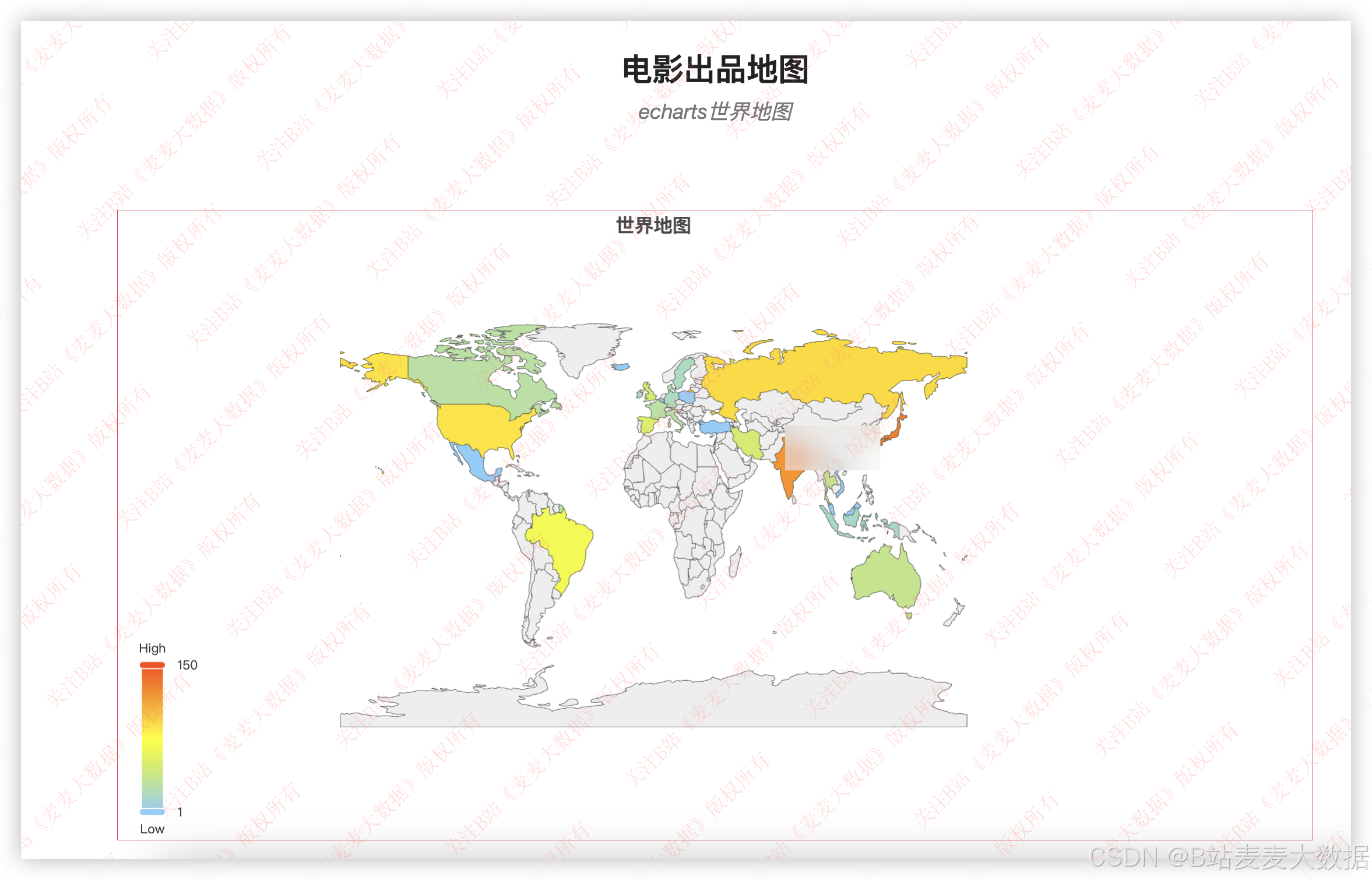
电影地图:
词云分析:

3.7 登录和注册
4程序代码
4.1 代码说明
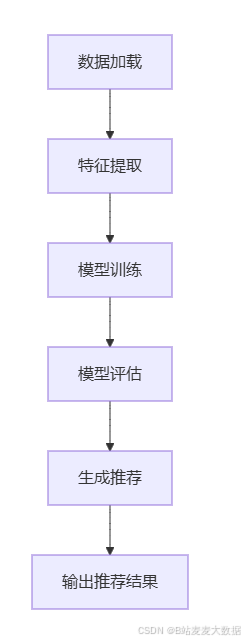
代码介绍:数据加载与预处理:从CSV文件加载电影和用户数据,并提取电影海报的视觉特征。
特征提取:使用预训练的ResNet50模型提取电影海报的视觉特征。
模型构建:构建一个双输入的神经网络模型,分别嵌入用户和电影特征,并通过全连接层预测评分。
推荐生成:通过余弦相似度计算用户行为的相似性,生成个性化推荐。。
4.2 流程图
4.3 代码实例
python
# 基于CNN的电影推荐算法
import pandas as pd
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, Embedding, Input, concatenate
from tensorflow.keras.models import Model
from sklearn.metrics.pairwise import cosine_similarity
# 数据加载与预处理
def load_data(movie_path, user_path):
movies = pd.read_csv(movie_path)
users = pd.read_csv(user_path)
return movies, users
# 特征提取(基于ResNet50)
def extract_features(movie_id):
img = load_img(f"movie_posters/{movie_id}.jpg", target_size=(224, 224))
model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
features = model.predict(img)
return features.flatten()
# 构建推荐模型
def build_model(num_users, num_movies, embedding_size=64):
user_input = Input(shape=(1,), name='user_id')
movie_input = Input(shape=(1,), name='movie_id')
user_embedding = Embedding(num_users, embedding_size)(user_input)
movie_embedding = Embedding(num_movies, embedding_size)(movie_input)
x = concatenate([user_embedding, movie_embedding])
x = Dense(64, activation='relu')(x)
output = Dense(1, activation='sigmoid')(x)
model = Model(inputs=[user_input, movie_input], outputs=output)
model.compile(optimizer='adam', loss='mse')
return model
# 生成推荐
def generate_recommendations(model, user_id, num_recs=5):
# 获取用户观看过的电影
watched_movies = users[users['user_id'] == user_id]['movie_id'].tolist()
# 计算相似性
sims = cosine_similarity(model.predict([user_id]*num_movies), model.predict([user_id]*num_movies))
# 生成推荐
recommendations = []
for i in range(num_recs):
recommendations.append(movies.iloc[sims.argsort()[0][-(i+1)]]['title'])
return recommendations